 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Medical Image-based Cancer Detection via Text-guided Supervision from Reports
May 23, 2024



The absence of adequately sufficient expert-level tumor annotations hinders the effectiveness of supervised learning based opportunistic cancer screening on medical imaging. Clinical reports (that are rich in descriptive textual details) can offer a "free lunch'' supervision information and provide tumor location as a type of weak label to cope with screening tasks, thus saving human labeling workloads, if properly leveraged. However, predicting cancer only using such weak labels can be very changeling since tumors are usually presented in small anatomical regions compared to the whole 3D medical scans. Weakly semi-supervised learning (WSSL) utilizes a limited set of voxel-level tumor annotations and incorporates alongside a substantial number of medical images that have only off-the-shelf clinical reports, which may strike a good balance between minimizing expert annotation workload and optimizing screening efficacy. In this paper, we propose a novel text-guided learning method to achieve highly accurate cancer detection results. Through integrating diagnostic and tumor location text prompts into the text encoder of a vision-language model (VLM), optimization of weakly supervised learning can be effectively performed in the latent space of VLM, thereby enhancing the stability of training. Our approach can leverage clinical knowledge by large-scale pre-trained VLM to enhance generalization ability, and produce reliable pseudo tumor masks to improve cancer detection. Our extensive quantitative experimental results on a large-scale cancer dataset, including 1,651 unique patients, validate that our approach can reduce human annotation efforts by at least 70% while maintaining comparable cancer detection accuracy to competing fully supervised methods (AUC value 0.961 versus 0.966).
Pixel Distillation: A New Knowledge Distillation Scheme for Low-Resolution Image Recognition
Dec 17, 2021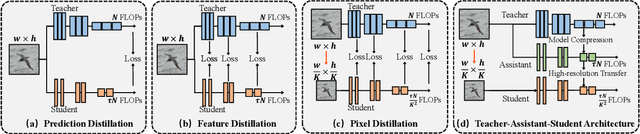
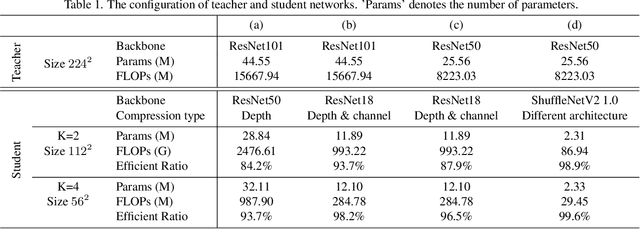
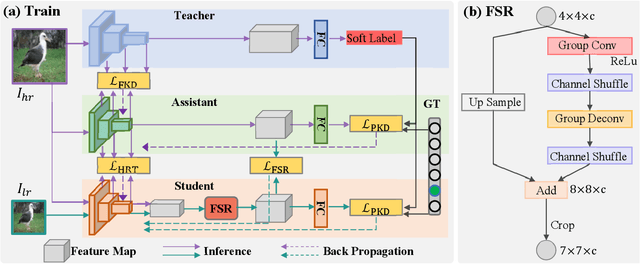
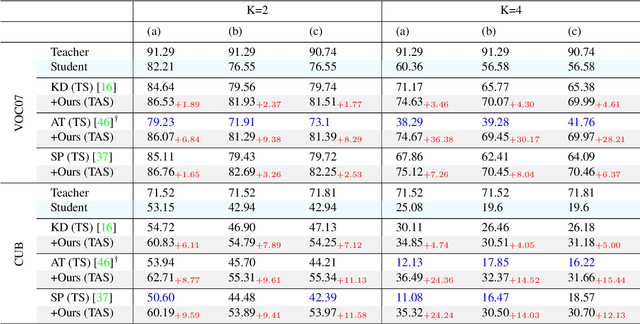
The great success of deep learning is mainly due to the large-scale network architecture and the high-quality training data. However, it is still challenging to deploy recent deep models on portable devices with limited memory and imaging ability. Some existing works have engaged to compress the model via knowledge distillation. Unfortunately, these methods cannot deal with images with reduced image quality, such as the low-resolution (LR) images. To this end, we make a pioneering effort to distill helpful knowledge from a heavy network model learned from high-resolution (HR) images to a compact network model that will handle LR images, thus advancing the current knowledge distillation technique with the novel pixel distillation. To achieve this goal, we propose a Teacher-Assistant-Student (TAS) framework, which disentangles knowledge distillation into the model compression stage and the high resolution representation transfer stage. By equipping a novel Feature Super Resolution (FSR) module, our approach can learn lightweight network model that can achieve similar accuracy as the heavy teacher model but with much fewer parameters, faster inference speed, and lower-resolution inputs. Comprehensive experiments on three widely-used benchmarks, \ie, CUB-200-2011, PASCAL VOC 2007, and ImageNetSub, demonstrate the effectiveness of our approach.
Weakly Supervised Semantic Segmentation via Alternative Self-Dual Teaching
Dec 17, 2021
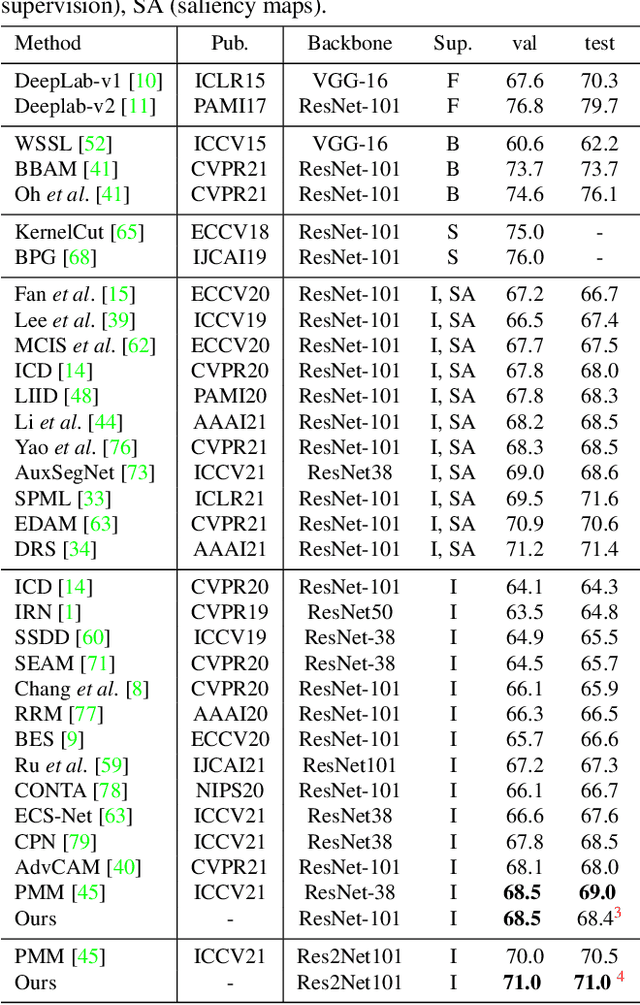
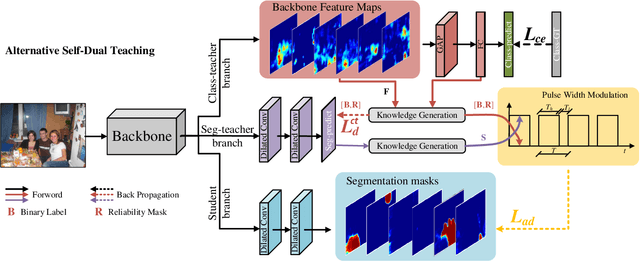

Current weakly supervised semantic segmentation (WSSS) frameworks usually contain the separated mask-refinement model and the main semantic region mining model. These approaches would contain redundant feature extraction backbones and biased learning objectives, making them computational complex yet sub-optimal to addressing the WSSS task. To solve this problem, this paper establishes a compact learning framework that embeds the classification and mask-refinement components into a unified deep model. With the shared feature extraction backbone, our model is able to facilitate knowledge sharing between the two components while preserving a low computational complexity. To encourage high-quality knowledge interaction, we propose a novel alternative self-dual teaching (ASDT) mechanism. Unlike the conventional distillation strategy, the knowledge of the two teacher branches in our model is alternatively distilled to the student branch by a Pulse Width Modulation (PWM), which generates PW wave-like selection signal to guide the knowledge distillation process. In this way, the student branch can help prevent the model from falling into local minimum solutions caused by the imperfect knowledge provided of either teacher branch. Comprehensive experiments on the PASCAL VOC 2012 and COCO-Stuff 10K demonstrate the effectiveness of the proposed alternative self-dual teaching mechanism as well as the new state-of-the-art performance of our approach.