 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrasp Any Region: Towards Precise, Contextual Pixel Understanding for Multimodal LLMs
Oct 22, 2025While Multimodal Large Language Models (MLLMs) excel at holistic understanding, they struggle in capturing the dense world with complex scenes, requiring fine-grained analysis of intricate details and object inter-relationships. Region-level MLLMs have been a promising step. However, previous attempts are generally optimized to understand given regions in isolation, neglecting crucial global contexts. To address this, we introduce Grasp Any Region (GAR) for comprehen- sive region-level visual understanding. Empowered by an effective RoI-aligned feature replay technique, GAR supports (1) precise perception by leveraging necessary global contexts, and (2) modeling interactions between multiple prompts. Together, it then naturally achieves (3) advanced compositional reasoning to answer specific free-form questions about any region, shifting the paradigm from passive description to active dialogue. Moreover, we construct GAR-Bench, which not only provides a more accurate evaluation of single-region comprehension, but also, more importantly, measures interactions and complex reasoning across multiple regions. Extensive experiments have demonstrated that GAR-1B not only maintains the state-of-the-art captioning capabilities, e.g., outperforming DAM-3B +4.5 on DLC-Bench, but also excels at modeling relationships between multiple prompts with advanced comprehension capabilities, even surpassing InternVL3-78B on GAR-Bench-VQA. More importantly, our zero-shot GAR-8B even outperforms in-domain VideoRefer-7B on VideoRefer-BenchQ, indicating its strong capabilities can be easily transferred to videos.
On the Reconstruction of Face Images from Deep Face Templates
Apr 29, 2018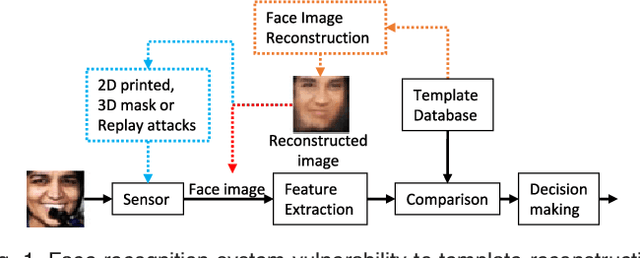


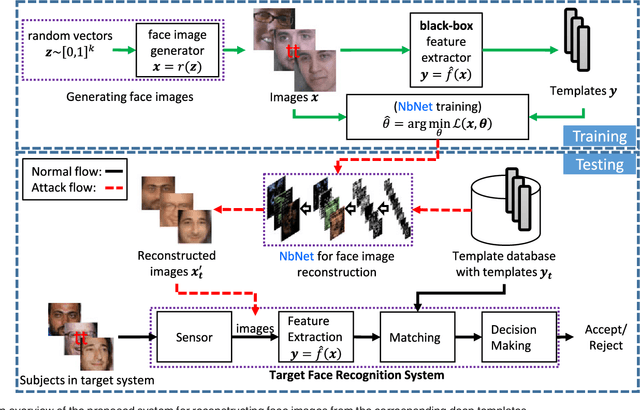
State-of-the-art face recognition systems are based on deep (convolutional) neural networks. Therefore, it is imperative to determine to what extent face templates derived from deep networks can be inverted to obtain the original face image. In this paper, we study the vulnerabilities of a state-of-the-art face recognition system based on template reconstruction attack. We propose a neighborly de-convolutional neural network (\textit{NbNet}) to reconstruct face images from their deep templates. In our experiments, we assumed that no knowledge about the target subject and the deep network are available. To train the \textit{NbNet} reconstruction models, we augmented two benchmark face datasets (VGG-Face and Multi-PIE) with a large collection of images synthesized using a face generator. The proposed reconstruction was evaluated using type-I (comparing the reconstructed images against the original face images used to generate the deep template) and type-II (comparing the reconstructed images against a different face image of the same subject) attacks. Given the images reconstructed from \textit{NbNets}, we show that for verification, we achieve TAR of 95.20\% (58.05\%) on LFW under type-I (type-II) attacks @ FAR of 0.1\%. Besides, 96.58\% (92.84\%) of the images reconstruction from templates of partition \textit{fa} (\textit{fb}) can be identified from partition \textit{fa} in color FERET. Our study demonstrates the need to secure deep templates in face recognition systems.