 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranscrib3D: 3D Referring Expression Resolution through Large Language Models
Apr 30, 2024



If robots are to work effectively alongside people, they must be able to interpret natural language references to objects in their 3D environment. Understanding 3D referring expressions is challenging -- it requires the ability to both parse the 3D structure of the scene and correctly ground free-form language in the presence of distraction and clutter. We introduce Transcrib3D, an approach that brings together 3D detection methods and the emergent reasoning capabilities of large language models (LLMs). Transcrib3D uses text as the unifying medium, which allows us to sidestep the need to learn shared representations connecting multi-modal inputs, which would require massive amounts of annotated 3D data. As a demonstration of its effectiveness, Transcrib3D achieves state-of-the-art results on 3D reference resolution benchmarks, with a great leap in performance from previous multi-modality baselines. To improve upon zero-shot performance and facilitate local deployment on edge computers and robots, we propose self-correction for fine-tuning that trains smaller models, resulting in performance close to that of large models. We show that our method enables a real robot to perform pick-and-place tasks given queries that contain challenging referring expressions. Project site is at https://ripl.github.io/Transcrib3D.
6-DoF Stability Field via Diffusion Models
Oct 26, 2023A core capability for robot manipulation is reasoning over where and how to stably place objects in cluttered environments. Traditionally, robots have relied on object-specific, hand-crafted heuristics in order to perform such reasoning, with limited generalizability beyond a small number of object instances and object interaction patterns. Recent approaches instead learn notions of physical interaction, namely motion prediction, but require supervision in the form of labeled object information or come at the cost of high sample complexity, and do not directly reason over stability or object placement. We present 6-DoFusion, a generative model capable of generating 3D poses of an object that produces a stable configuration of a given scene. Underlying 6-DoFusion is a diffusion model that incrementally refines a randomly initialized SE(3) pose to generate a sample from a learned, context-dependent distribution over stable poses. We evaluate our model on different object placement and stacking tasks, demonstrating its ability to construct stable scenes that involve novel object classes as well as to improve the accuracy of state-of-the-art 3D pose estimation methods.
Self-Supervised Video Transformers for Isolated Sign Language Recognition
Sep 02, 2023



This paper presents an in-depth analysis of various self-supervision methods for isolated sign language recognition (ISLR). We consider four recently introduced transformer-based approaches to self-supervised learning from videos, and four pre-training data regimes, and study all the combinations on the WLASL2000 dataset. Our findings reveal that MaskFeat achieves performance superior to pose-based and supervised video models, with a top-1 accuracy of 79.02% on gloss-based WLASL2000. Furthermore, we analyze these models' ability to produce representations of ASL signs using linear probing on diverse phonological features. This study underscores the value of architecture and pre-training task choices in ISLR. Specifically, our results on WLASL2000 highlight the power of masked reconstruction pre-training, and our linear probing results demonstrate the importance of hierarchical vision transformers for sign language representation.
NeRFuser: Large-Scale Scene Representation by NeRF Fusion
May 22, 2023A practical benefit of implicit visual representations like Neural Radiance Fields (NeRFs) is their memory efficiency: large scenes can be efficiently stored and shared as small neural nets instead of collections of images. However, operating on these implicit visual data structures requires extending classical image-based vision techniques (e.g., registration, blending) from image sets to neural fields. Towards this goal, we propose NeRFuser, a novel architecture for NeRF registration and blending that assumes only access to pre-generated NeRFs, and not the potentially large sets of images used to generate them. We propose registration from re-rendering, a technique to infer the transformation between NeRFs based on images synthesized from individual NeRFs. For blending, we propose sample-based inverse distance weighting to blend visual information at the ray-sample level. We evaluate NeRFuser on public benchmarks and a self-collected object-centric indoor dataset, showing the robustness of our method, including to views that are challenging to render from the individual source NeRFs.
Classification Confidence Estimation with Test-Time Data-Augmentation
Jun 30, 2020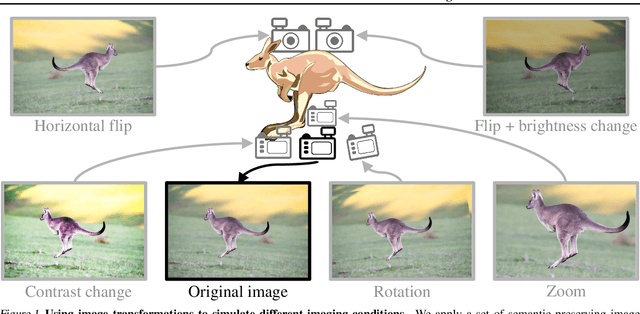
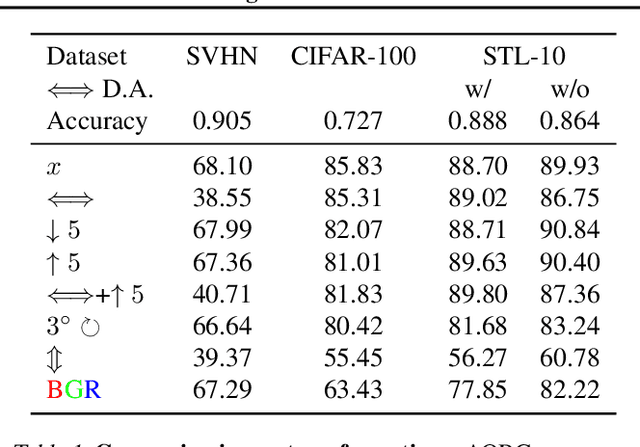
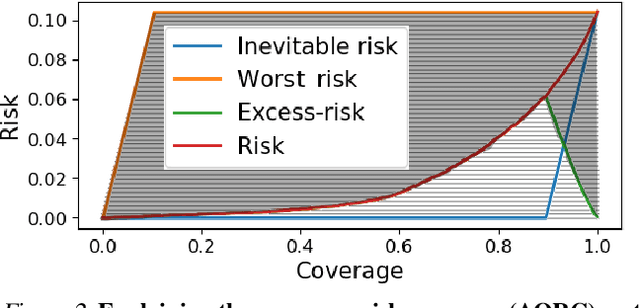
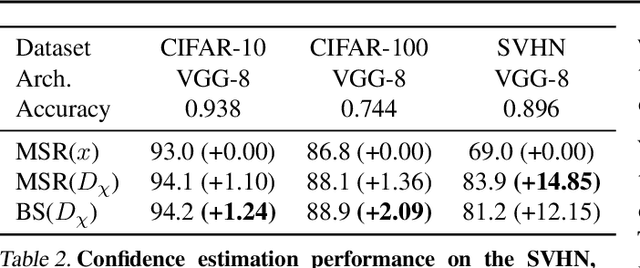
Machine learning plays an increasingly significant role in many aspects of our lives (including medicine, transportation, security, justice and other domains), making the potential consequences of false predictions increasingly devastating. These consequences may be mitigated if we can automatically flag such false predictions and potentially assign them to alternative, more reliable mechanisms, that are possibly more costly and involve human attention. This suggests the task of detecting errors, which we tackle in this paper for the case of visual classification. To this end, we propose a novel approach for classification confidence estimation. We apply a set of semantics-preserving image transformations to the input image, and show how the resulting image sets can be used to estimate confidence in the classifier's prediction. We demonstrate the potential of our approach by extensively evaluating it on a wide variety of classifier architectures and datasets, including ResNext/ImageNet, achieving state of the art performance. This paper constitutes a significant revision of our earlier work in this direction (Bahat & Shakhnarovich, 2018).
Deformable Style Transfer
Mar 24, 2020



Geometry and shape are fundamental aspects of visual style. Existing style transfer methods focus on texture-like components of style, ignoring geometry. We propose deformable style transfer (DST), an optimization-based approach that integrates texture and geometry style transfer. Our method is the first to allow geometry-aware stylization not restricted to any domain and not requiring training sets of matching style/content pairs. We demonstrate our method on a diverse set of content and style images including portraits, animals, objects, scenes, and paintings.
Analysis of diversity-accuracy tradeoff in image captioning
Feb 27, 2020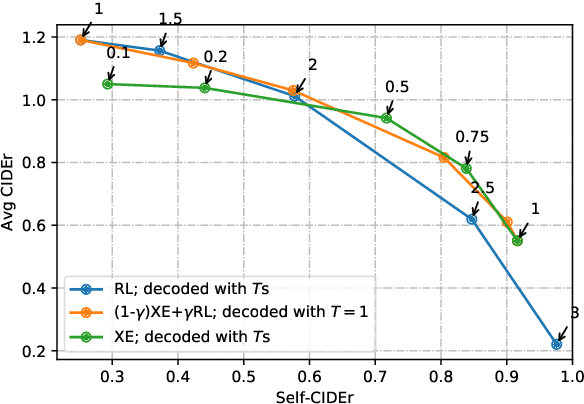

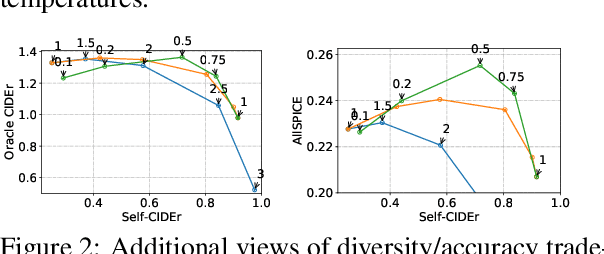
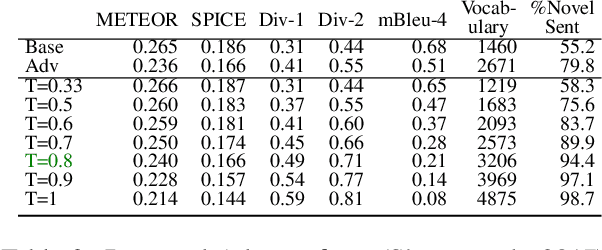
We investigate the effect of different model architectures, training objectives, hyperparameter settings and decoding procedures on the diversity of automatically generated image captions. Our results show that 1) simple decoding by naive sampling, coupled with low temperature is a competitive and fast method to produce diverse and accurate caption sets; 2) training with CIDEr-based reward using Reinforcement learning harms the diversity properties of the resulting generator, which cannot be mitigated by manipulating decoding parameters. In addition, we propose a new metric AllSPICE for evaluating both accuracy and diversity of a set of captions by a single value.
DIODE: A Dense Indoor and Outdoor DEpth Dataset
Aug 29, 2019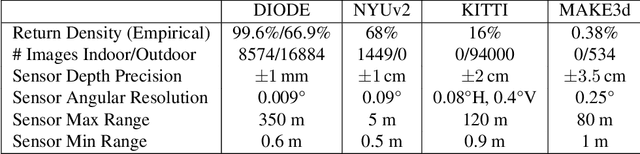
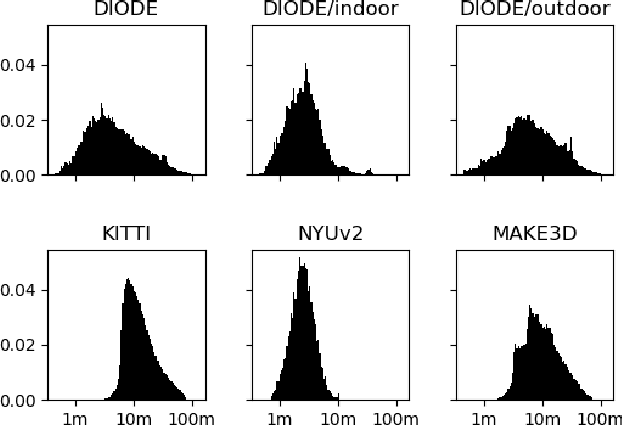
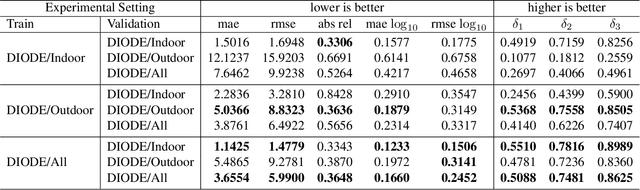
We introduce DIODE, a dataset that contains thousands of diverse high resolution color images with accurate, dense, long-range depth measurements. DIODE (Dense Indoor/Outdoor DEpth) is the first public dataset to include RGBD images of indoor and outdoor scenes obtained with one sensor suite. This is in contrast to existing datasets that focus on just one domain/scene type and employ different sensors, making generalization across domains difficult. The dataset is available for download at http://diode-dataset.org
Natural and Adversarial Error Detection using Invariance to Image Transformations
Feb 01, 2019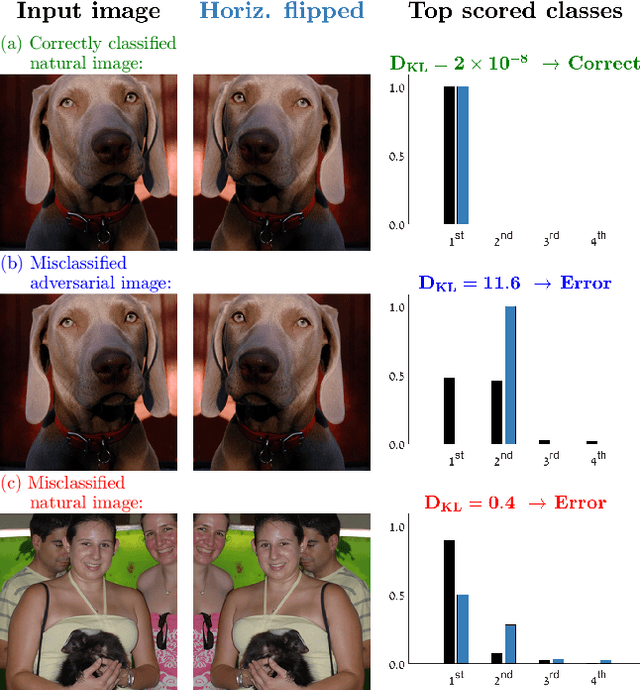
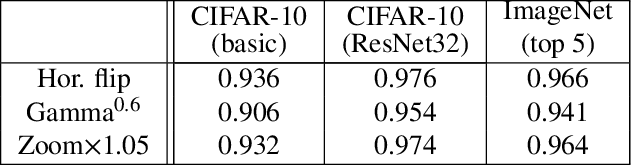

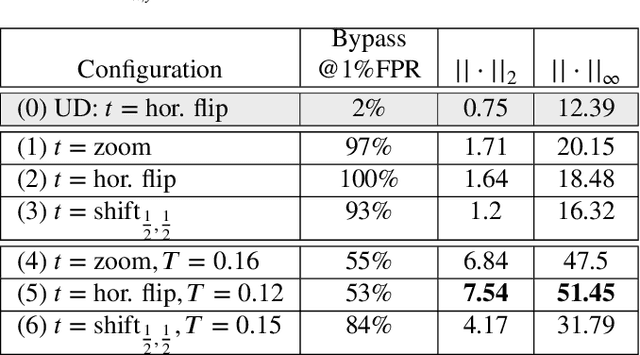
We propose an approach to distinguish between correct and incorrect image classifications. Our approach can detect misclassifications which either occur $\it{unintentionally}$ ("natural errors"), or due to $\it{intentional~adversarial~attacks}$ ("adversarial errors"), both in a single $\it{unified~framework}$. Our approach is based on the observation that correctly classified images tend to exhibit robust and consistent classifications under certain image transformations (e.g., horizontal flip, small image translation, etc.). In contrast, incorrectly classified images (whether due to adversarial errors or natural errors) tend to exhibit large variations in classification results under such transformations. Our approach does not require any modifications or retraining of the classifier, hence can be applied to any pre-trained classifier. We further use state of the art targeted adversarial attacks to demonstrate that even when the adversary has full knowledge of our method, the adversarial distortion needed for bypassing our detector is $\it{no~longer~imperceptible~to~the~human~eye}$. Our approach obtains state-of-the-art results compared to previous adversarial detection methods, surpassing them by a large margin.
Semantic speech retrieval with a visually grounded model of untranscribed speech
Oct 31, 2018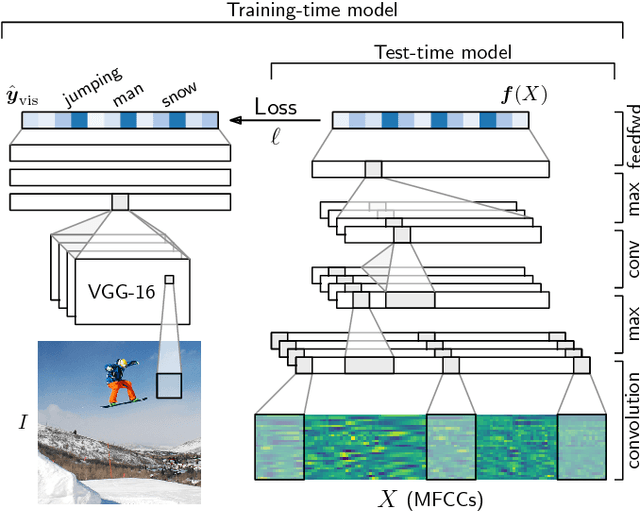
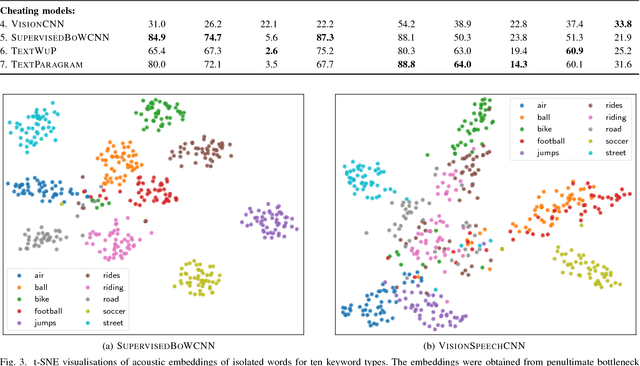

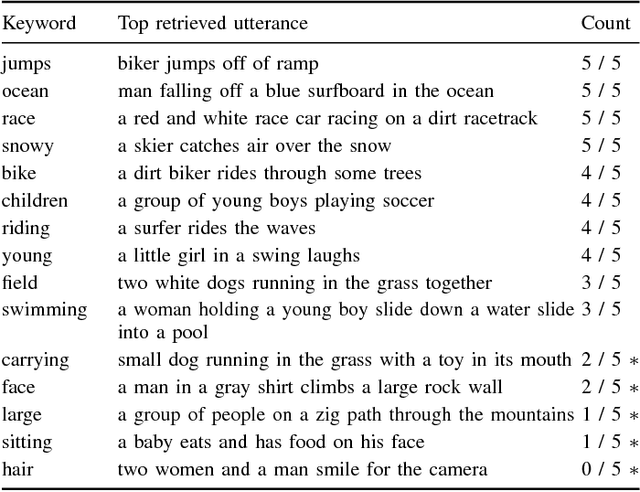
There is growing interest in models that can learn from unlabelled speech paired with visual context. This setting is relevant for low-resource speech processing, robotics, and human language acquisition research. Here we study how a visually grounded speech model, trained on images of scenes paired with spoken captions, captures aspects of semantics. We use an external image tagger to generate soft text labels from images, which serve as targets for a neural model that maps untranscribed speech to (semantic) keyword labels. We introduce a newly collected data set of human semantic relevance judgements and an associated task, semantic speech retrieval, where the goal is to search for spoken utterances that are semantically relevant to a given text query. Without seeing any text, the model trained on parallel speech and images achieves a precision of almost 60% on its top ten semantic retrievals. Compared to a supervised model trained on transcriptions, our model matches human judgements better by some measures, especially in retrieving non-verbatim semantic matches. We perform an extensive analysis of the model and its resulting representations.
* 10 pages, 3 figures, 5 tables; accepted to the IEEE/ACM Transactions on Audio, Speech and Language Processing