 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Good Robot!": Efficient Reinforcement Learning for Multi-Step Visual Tasks via Reward Shaping
Sep 25, 2019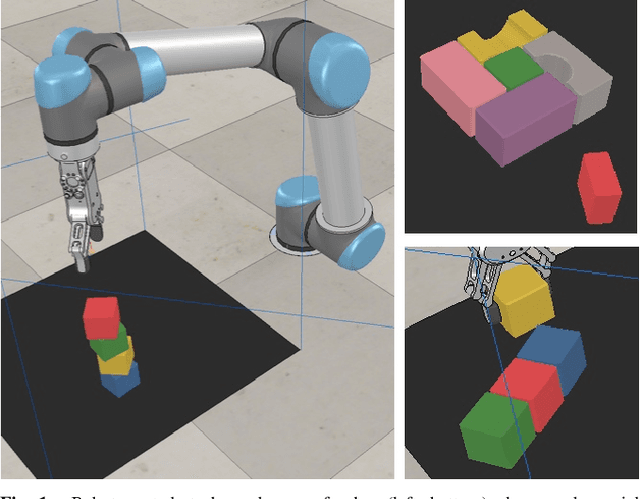
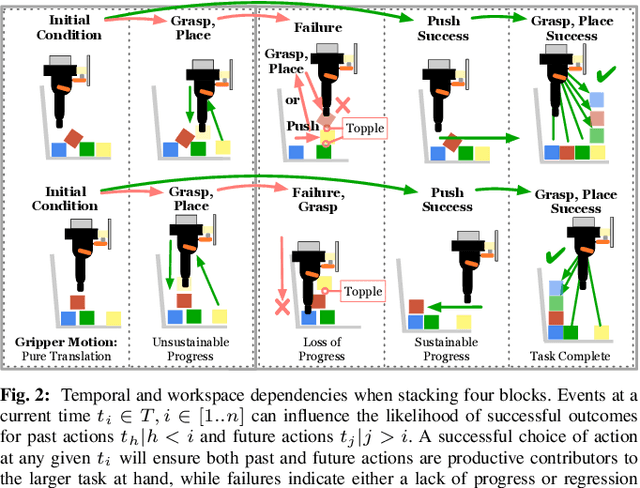
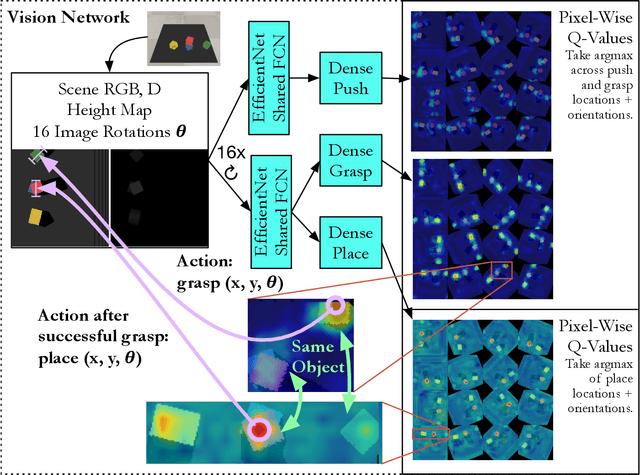
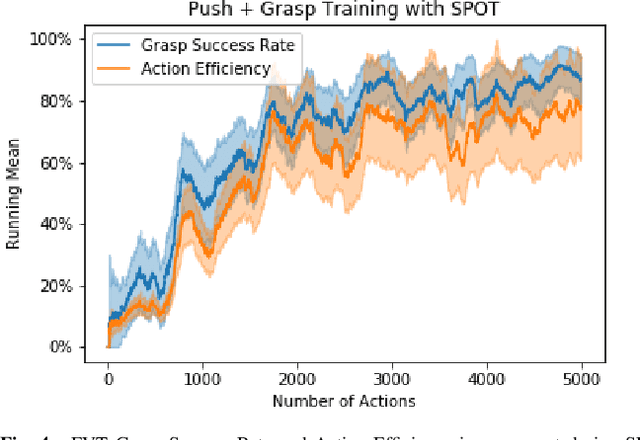
In order to learn effectively, robots must be able to extract the intangible context by which task progress and mistakes are defined. In the domain of reinforcement learning, much of this information is provided by the reward function. Hence, reward shaping is a necessary part of how we can achieve state-of-the-art results on complex, multi-step tasks. However, comparatively little work has examined how reward shaping should be done so that it captures task context, particularly in scenarios where the task is long-horizon and failure is highly consequential. Our Schedule for Positive Task (SPOT) reward trains our Efficient Visual Task (EVT) model to solve problems that require an understanding of both task context and workspace constraints of multi-step block arrangement tasks. In simulation EVT can completely clear adversarial arrangements of objects by pushing and grasping in 99% of cases vs an 82% baseline in prior work. For random arrangements EVT clears 100% of test cases at 86% action efficiency vs 61% efficiency in prior work. EVT + SPOT is also able to demonstrate context understanding and complete stacks in 74% of trials compared to a baseline of 5% with EVT alone. To our knowledge, this is the first instance of a Reinforcement Learning based algorithm successfully completing such a challenge. Code is available at https://github.com/jhu-lcsr/good_robot .
Self-supervised Dense 3D Reconstruction from Monocular Endoscopic Video
Sep 06, 2019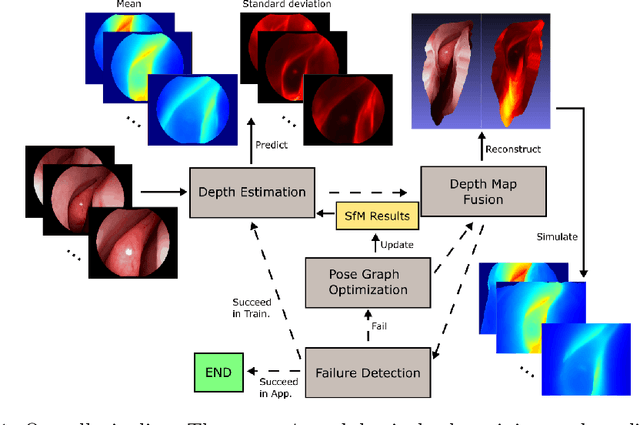
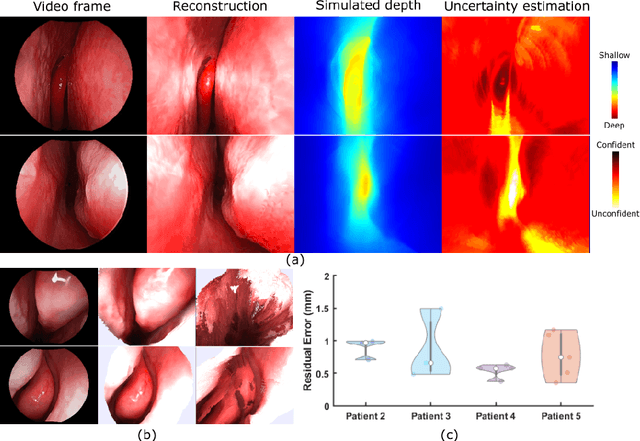
We present a self-supervised learning-based pipeline for dense 3D reconstruction from full-length monocular endoscopic videos without a priori modeling of anatomy or shading. Our method only relies on unlabeled monocular endoscopic videos and conventional multi-view stereo algorithms, and requires neither manual interaction nor patient CT in both training and application phases. In a cross-patient study using CT scans as groundtruth, we show that our method is able to produce photo-realistic dense 3D reconstructions with submillimeter mean residual errors from endoscopic videos from unseen patients and scopes.
Automated Surgical Activity Recognition with One Labeled Sequence
Jul 20, 2019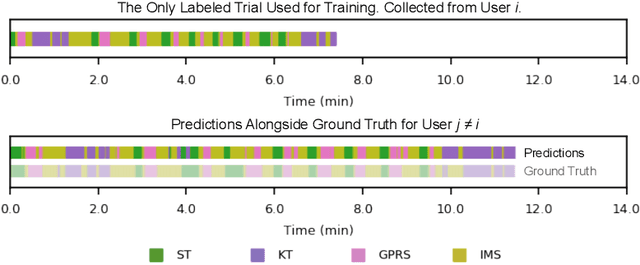
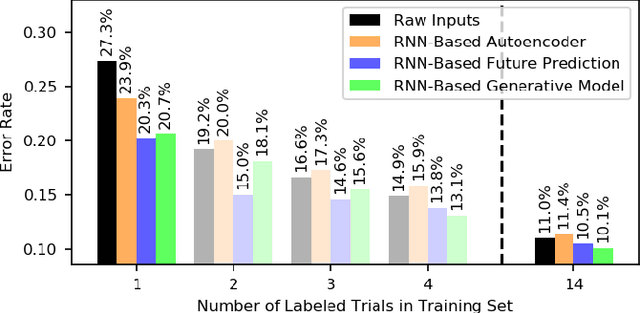
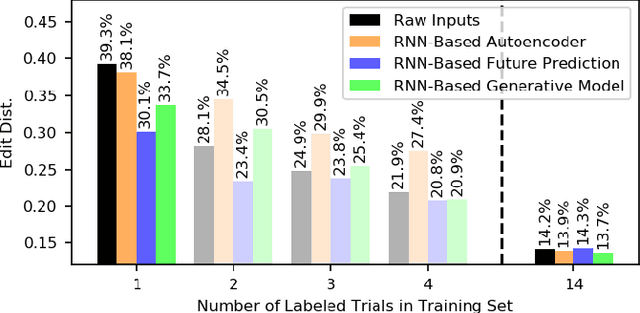
Prior work has demonstrated the feasibility of automated activity recognition in robot-assisted surgery from motion data. However, these efforts have assumed the availability of a large number of densely-annotated sequences, which must be provided manually by experts. This process is tedious, expensive, and error-prone. In this paper, we present the first analysis under the assumption of scarce annotations, where as little as one annotated sequence is available for training. We demonstrate feasibility of automated recognition in this challenging setting, and we show that learning representations in an unsupervised fashion, before the recognition phase, leads to significant gains in performance. In addition, our paper poses a new challenge to the community: how much further can we push performance in this important yet relatively unexplored regime?
sharpDARTS: Faster and More Accurate Differentiable Architecture Search
Mar 23, 2019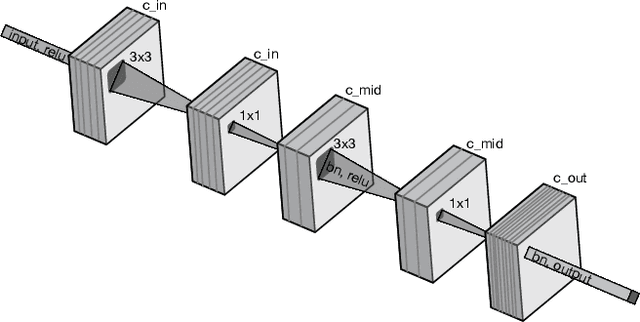
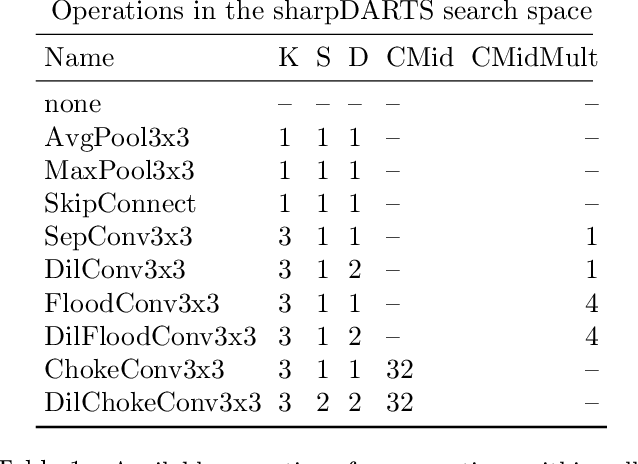
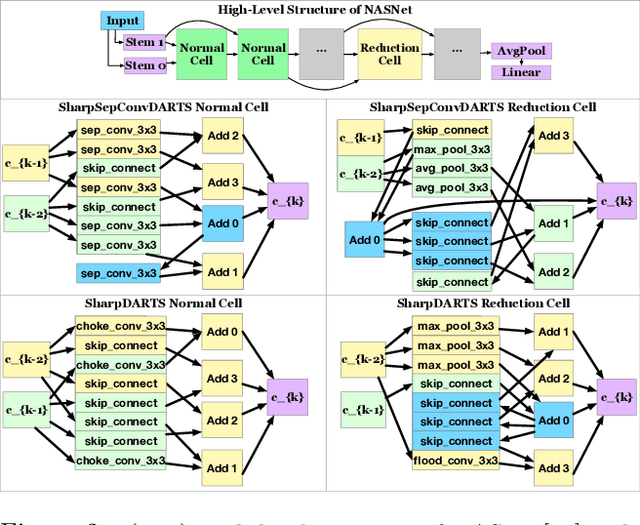
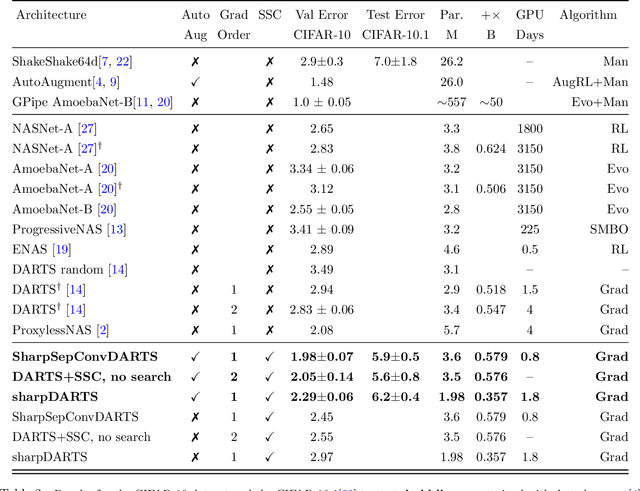
Neural Architecture Search (NAS) has been a source of dramatic improvements in neural network design, with recent results meeting or exceeding the performance of hand-tuned architectures. However, our understanding of how to represent the search space for neural net architectures and how to search that space efficiently are both still in their infancy. We have performed an in-depth analysis to identify limitations in a widely used search space and a recent architecture search method, Differentiable Architecture Search (DARTS). These findings led us to introduce novel network blocks with a more general, balanced, and consistent design; a better-optimized Cosine Power Annealing learning rate schedule; and other improvements. Our resulting sharpDARTS search is 50% faster with a 20-30% relative improvement in final model error on CIFAR-10 when compared to DARTS. Our best single model run has 1.93% (1.98+/-0.07) validation error on CIFAR-10 and 5.5% error (5.8+/-0.3) on the recently released CIFAR-10.1 test set. To our knowledge, both are state of the art for models of similar size. This model also generalizes competitively to ImageNet at 25.1% top-1 (7.8% top-5) error. We found improvements for existing search spaces but does DARTS generalize to new domains? We propose Differentiable Hyperparameter Grid Search and the HyperCuboid search space, which are representations designed to leverage DARTS for more general parameter optimization. Here we find that DARTS fails to generalize when compared against a human's one shot choice of models. We look back to the DARTS and sharpDARTS search spaces to understand why, and an ablation study reveals an unusual generalization gap. We finally propose Max-W regularization to solve this problem, which proves significantly better than the handmade design. Code will be made available.
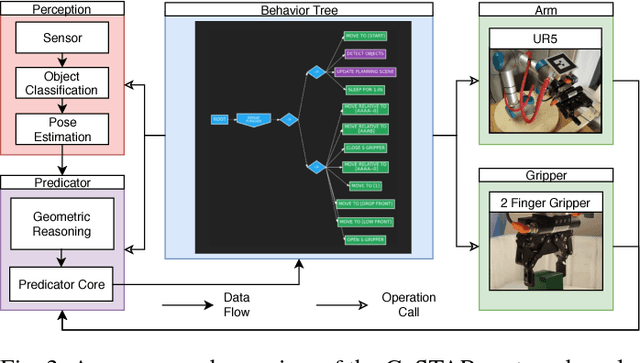
The CoSTAR Block Stacking Dataset: Learning with Workspace Constraints
Mar 12, 2019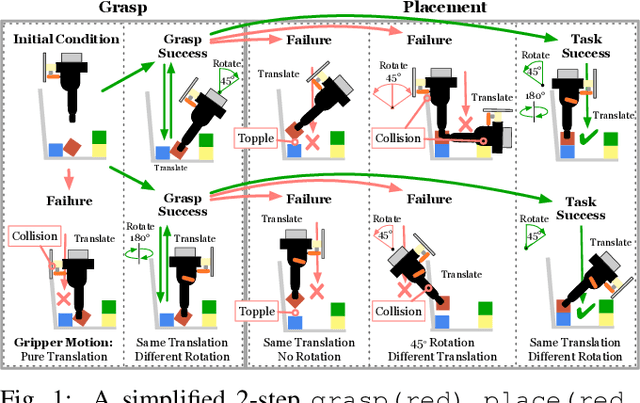

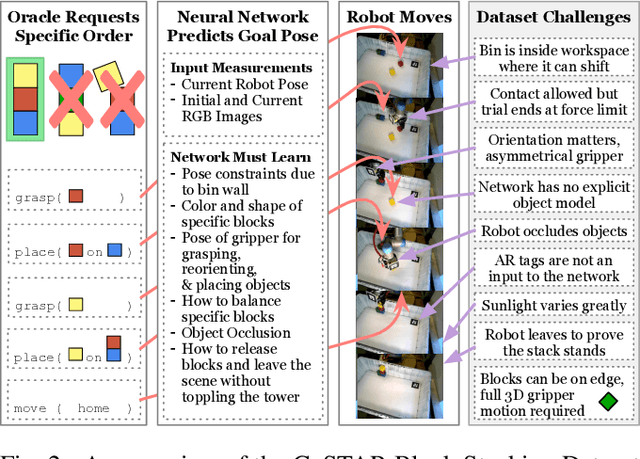

A robot can now grasp an object more effectively than ever before, but once it has the object what happens next? We show that a mild relaxation of the task and workspace constraints implicit in existing object grasping datasets can cause neural network based grasping algorithms to fail on even a simple block stacking task when executed under more realistic circumstances. To address this, we introduce the JHU CoSTAR Block Stacking Dataset (BSD), where a robot interacts with 5.1 cm colored blocks to complete an order-fulfillment style block stacking task. It contains dynamic scenes and real time-series data in a less constrained environment than comparable datasets. There are nearly 12,000 stacking attempts and over 2 million frames of real data. We discuss the ways in which this dataset provides a valuable resource for a broad range of other topics of investigation. We find that hand-designed neural networks that work on prior datasets do not generalize to this task. Thus, to establish a baseline for this dataset, we demonstrate an automated search of neural network based models using a novel multiple-input HyperTree MetaModel, and find a final model which makes reasonable 3D pose predictions for grasping and stacking on our dataset. The CoSTAR BSD, code, and instructions are available at https://sites.google.com/site/costardataset.
Self-supervised Learning for Dense Depth Estimation in Monocular Endoscopy
Feb 20, 2019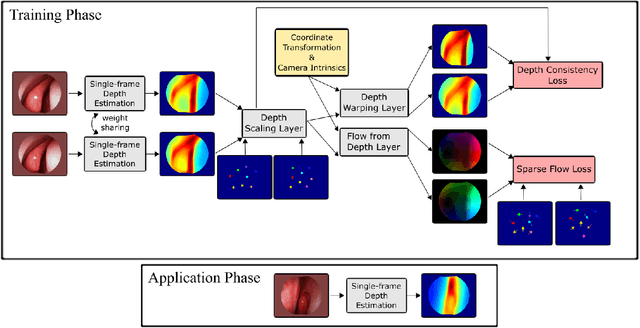
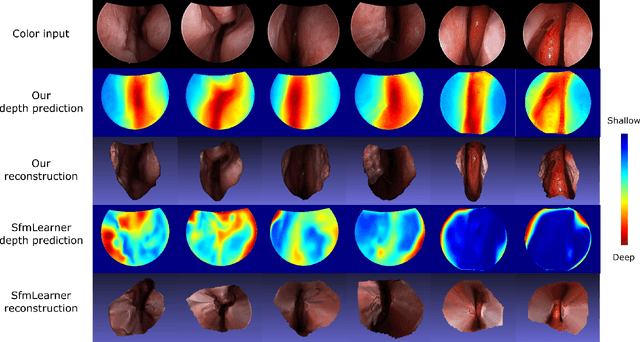
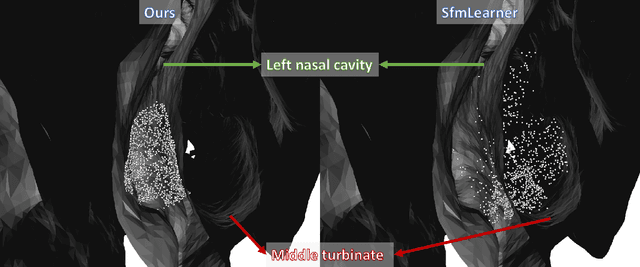
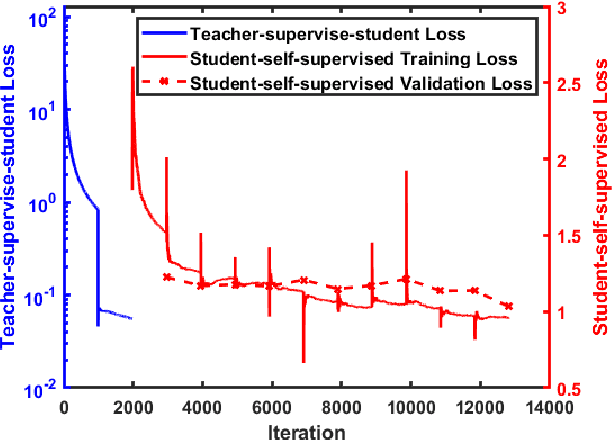
We present a self-supervised approach to training convolutional neural networks for dense depth estimation from monocular endoscopy data without a priori modeling of anatomy or shading. Our method only requires monocular endoscopic video and a multi-view stereo method, e.g. structure from motion, to supervise learning in a sparse manner. Consequently, our method requires neither manual labeling nor patient computed tomography (CT) scan in the training and application phases. In a cross-patient experiment using CT scans as groundtruth, the proposed method achieved submillimeter root mean squared error. In a comparison study to a recent self-supervised depth estimation method designed for natural video on in vivo sinus endoscopy data, we demonstrate that the proposed approach outperforms the previous method by a large margin. The source code for this work is publicly available online at https://github.com/lppllppl920/EndoscopyDepthEstimation-Pytorch.
Evaluating Methods for End-User Creation of Robot Task Plans
Nov 06, 2018
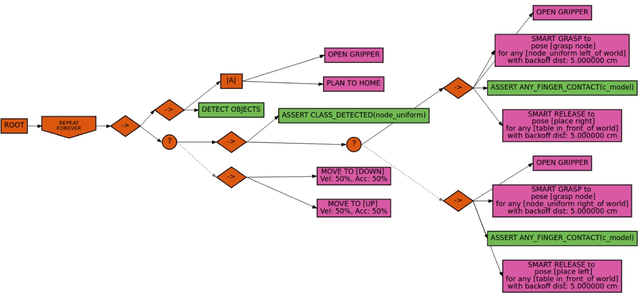

How can we enable users to create effective, perception-driven task plans for collaborative robots? We conducted a 35-person user study with the Behavior Tree-based CoSTAR system to determine which strategies for end user creation of generalizable robot task plans are most usable and effective. CoSTAR allows domain experts to author complex, perceptually grounded task plans for collaborative robots. As a part of CoSTAR's wide range of capabilities, it allows users to specify SmartMoves: abstract goals such as "pick up component A from the right side of the table." Users were asked to perform pick-and-place assembly tasks with either SmartMoves or one of three simpler baseline versions of CoSTAR. Overall, participants found CoSTAR to be highly usable, with an average System Usability Scale score of 73.4 out of 100. SmartMove also helped users perform tasks faster and more effectively; all SmartMove users completed the first two tasks, while not all users completed the tasks using the other strategies. SmartMove users showed better performance for incorporating perception across all three tasks.
* 7 pages; IROS 2018
A Unified Framework for Multi-View Multi-Class Object Pose Estimation
Oct 06, 2018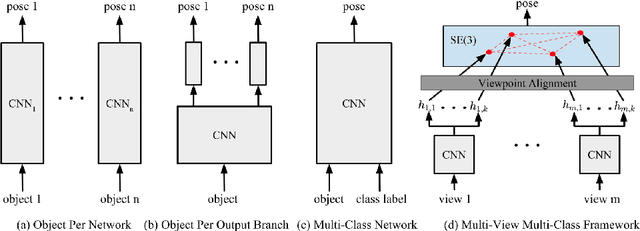
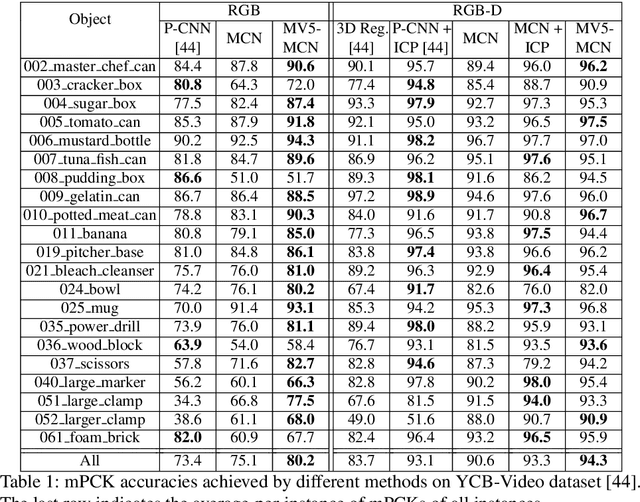
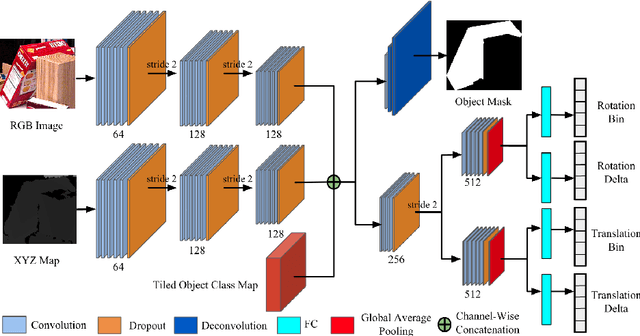
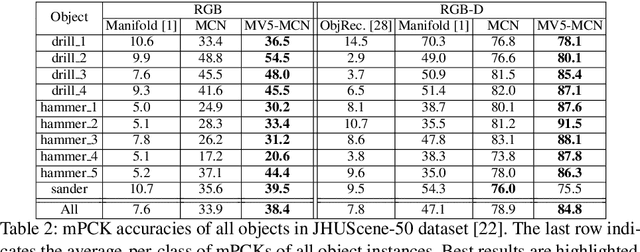
One core challenge in object pose estimation is to ensure accurate and robust performance for large numbers of diverse foreground objects amidst complex background clutter. In this work, we present a scalable framework for accurately inferring six Degree-of-Freedom (6-DoF) pose for a large number of object classes from single or multiple views. To learn discriminative pose features, we integrate three new capabilities into a deep Convolutional Neural Network (CNN): an inference scheme that combines both classification and pose regression based on a uniform tessellation of the Special Euclidean group in three dimensions (SE(3)), the fusion of class priors into the training process via a tiled class map, and an additional regularization using deep supervision with an object mask. Further, an efficient multi-view framework is formulated to address single-view ambiguity. We show that this framework consistently improves the performance of the single-view network. We evaluate our method on three large-scale benchmarks: YCB-Video, JHUScene-50 and ObjectNet-3D. Our approach achieves competitive or superior performance over the current state-of-the-art methods.
Deep Supervision with Intermediate Concepts
Jul 20, 2018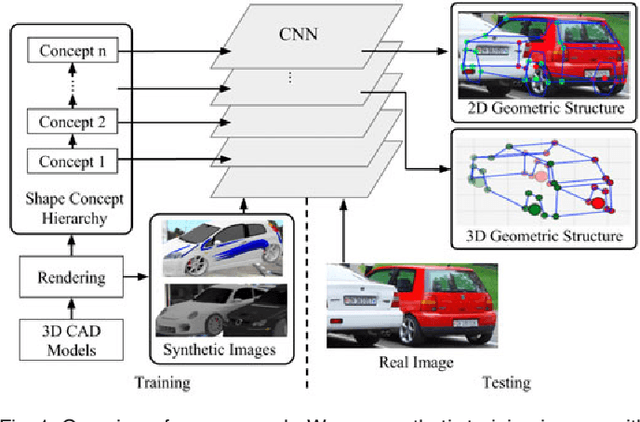
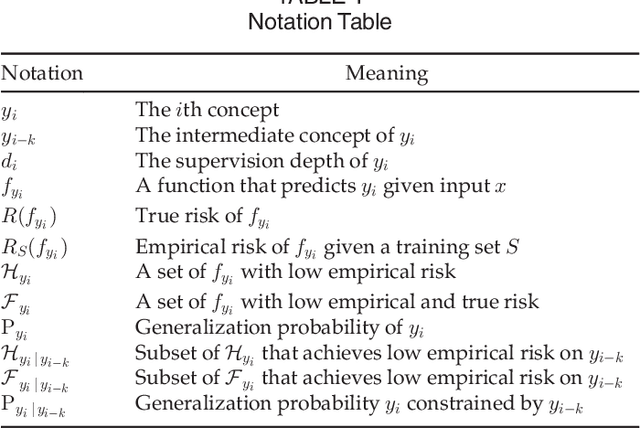
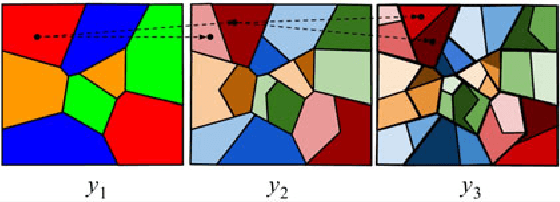

Recent data-driven approaches to scene interpretation predominantly pose inference as an end-to-end black-box mapping, commonly performed by a Convolutional Neural Network (CNN). However, decades of work on perceptual organization in both human and machine vision suggests that there are often intermediate representations that are intrinsic to an inference task, and which provide essential structure to improve generalization. In this work, we explore an approach for injecting prior domain structure into neural network training by supervising hidden layers of a CNN with intermediate concepts that normally are not observed in practice. We formulate a probabilistic framework which formalizes these notions and predicts improved generalization via this deep supervision method. One advantage of this approach is that we are able to train only from synthetic CAD renderings of cluttered scenes, where concept values can be extracted, but apply the results to real images. Our implementation achieves the state-of-the-art performance of 2D/3D keypoint localization and image classification on real image benchmarks, including KITTI, PASCAL VOC, PASCAL3D+, IKEA, and CIFAR100. We provide additional evidence that our approach outperforms alternative forms of supervision, such as multi-task networks.
Towards automatic initialization of registration algorithms using simulated endoscopy images
Jun 28, 2018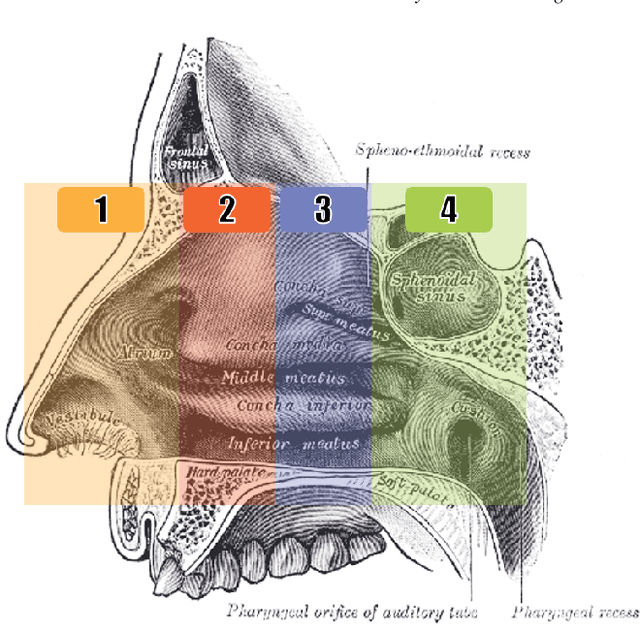
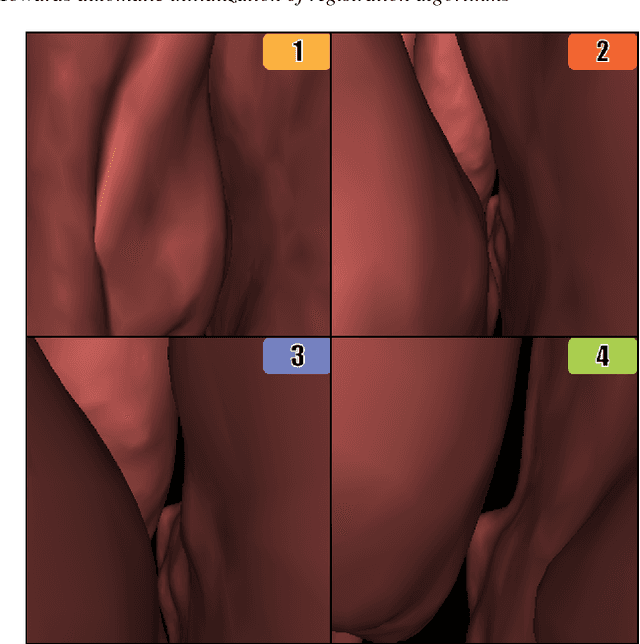
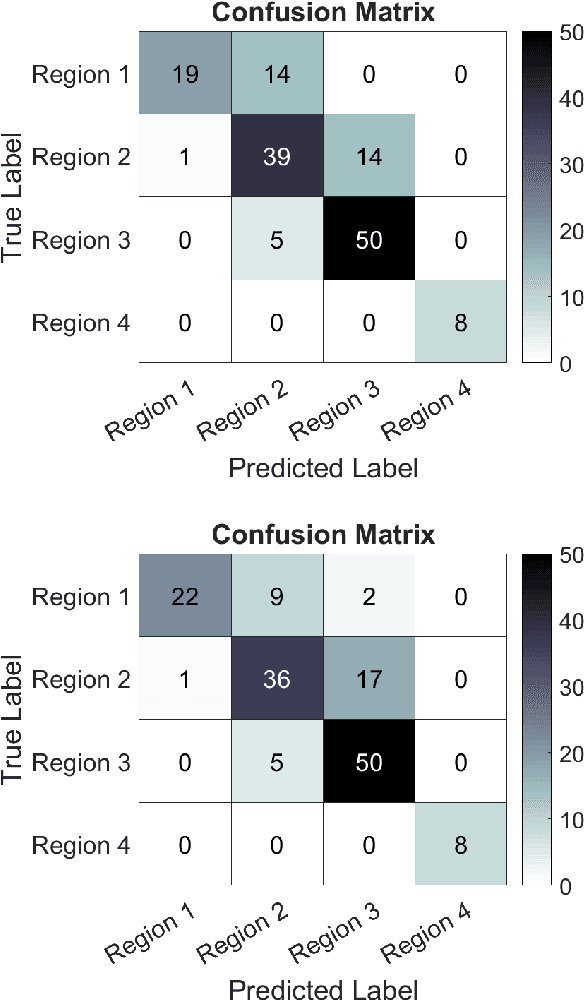
Registering images from different modalities is an active area of research in computer aided medical interventions. Several registration algorithms have been developed, many of which achieve high accuracy. However, these results are dependent on many factors, including the quality of the extracted features or segmentations being registered as well as the initial alignment. Although several methods have been developed towards improving segmentation algorithms and automating the segmentation process, few automatic initialization algorithms have been explored. In many cases, the initial alignment from which a registration is initiated is performed manually, which interferes with the clinical workflow. Our aim is to use scene classification in endoscopic procedures to achieve coarse alignment of the endoscope and a preoperative image of the anatomy. In this paper, we show using simulated scenes that a neural network can predict the region of anatomy (with respect to a preoperative image) that the endoscope is located in by observing a single endoscopic video frame. With limited training and without any hyperparameter tuning, our method achieves an accuracy of 76.53 (+/-1.19)%. There are several avenues for improvement, making this a promising direction of research. Code is available at https://github.com/AyushiSinha/AutoInitialization.