 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusER: Discrete Diffusion via Edit-based Reconstruction
Oct 30, 2022



In text generation, models that generate text from scratch one token at a time are currently the dominant paradigm. Despite being performant, these models lack the ability to revise existing text, which limits their usability in many practical scenarios. We look to address this, with DiffusER (Diffusion via Edit-based Reconstruction), a new edit-based generative model for text based on denoising diffusion models -- a class of models that use a Markov chain of denoising steps to incrementally generate data. DiffusER is not only a strong generative model in general, rivalling autoregressive models on several tasks spanning machine translation, summarization, and style transfer; it can also perform other varieties of generation that standard autoregressive models are not well-suited for. For instance, we demonstrate that DiffusER makes it possible for a user to condition generation on a prototype, or an incomplete sequence, and continue revising based on previous edit steps.
He Said, She Said: Style Transfer for Shifting the Perspective of Dialogues
Oct 27, 2022



In this work, we define a new style transfer task: perspective shift, which reframes a dialogue from informal first person to a formal third person rephrasing of the text. This task requires challenging coreference resolution, emotion attribution, and interpretation of informal text. We explore several baseline approaches and discuss further directions on this task when applied to short dialogues. As a sample application, we demonstrate that applying perspective shifting to a dialogue summarization dataset (SAMSum) substantially improves the zero-shot performance of extractive news summarization models on this data. Additionally, supervised extractive models perform better when trained on perspective shifted data than on the original dialogues. We release our code publicly.
A Multi-dimensional Evaluation of Tokenizer-free Multilingual Pretrained Models
Oct 13, 2022
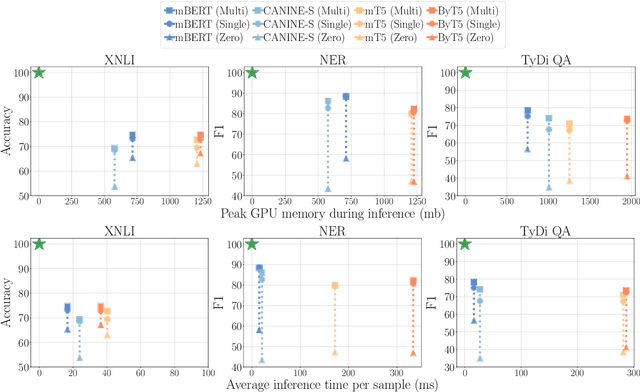
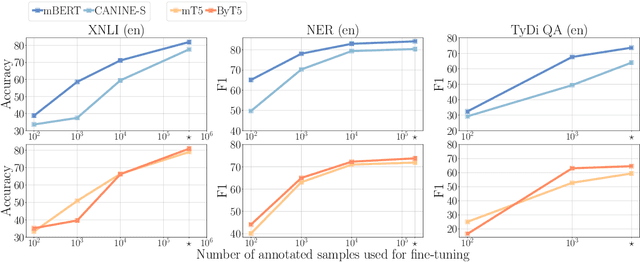
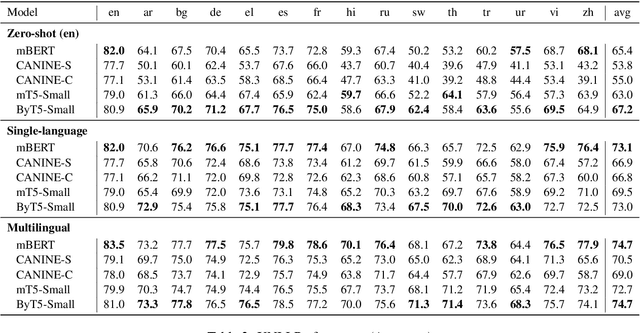
Recent work on tokenizer-free multilingual pretrained models show promising results in improving cross-lingual transfer and reducing engineering overhead (Clark et al., 2022; Xue et al., 2022). However, these works mainly focus on reporting accuracy on a limited set of tasks and data settings, placing less emphasis on other important factors when tuning and deploying the models in practice, such as memory usage, inference speed, and fine-tuning data robustness. We attempt to fill this gap by performing a comprehensive empirical comparison of multilingual tokenizer-free and subword-based models considering these various dimensions. Surprisingly, we find that subword-based models might still be the most practical choice in many settings, achieving better performance for lower inference latency and memory usage. Based on these results, we encourage future work in tokenizer-free methods to consider these factors when designing and evaluating new models.
Language Models of Code are Few-Shot Commonsense Learners
Oct 13, 2022
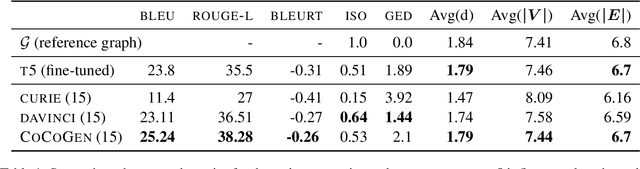

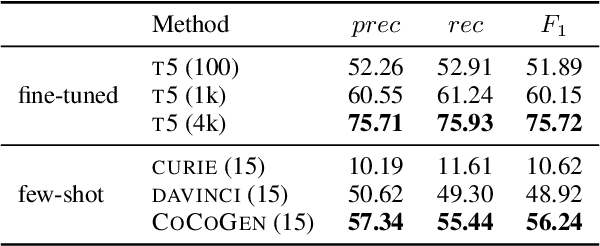
We address the general task of structured commonsense reasoning: given a natural language input, the goal is to generate a graph such as an event -- or a reasoning-graph. To employ large language models (LMs) for this task, existing approaches ``serialize'' the output graph as a flat list of nodes and edges. Although feasible, these serialized graphs strongly deviate from the natural language corpora that LMs were pre-trained on, hindering LMs from generating them correctly. In this paper, we show that when we instead frame structured commonsense reasoning tasks as code generation tasks, pre-trained LMs of code are better structured commonsense reasoners than LMs of natural language, even when the downstream task does not involve source code at all. We demonstrate our approach across three diverse structured commonsense reasoning tasks. In all these natural language tasks, we show that using our approach, a code generation LM (CODEX) outperforms natural-LMs that are fine-tuned on the target task (e.g., T5) and other strong LMs such as GPT-3 in the few-shot setting.
CTC Alignments Improve Autoregressive Translation
Oct 11, 2022
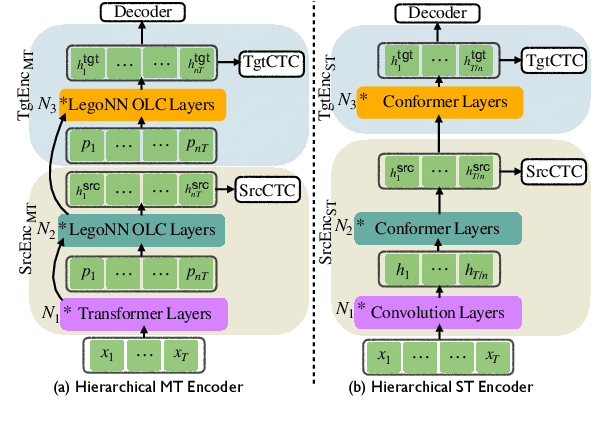

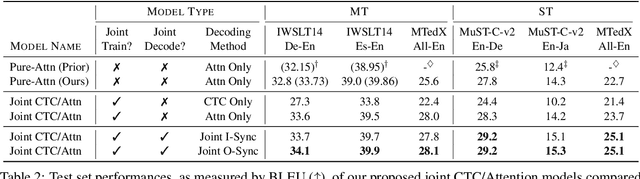
Connectionist Temporal Classification (CTC) is a widely used approach for automatic speech recognition (ASR) that performs conditionally independent monotonic alignment. However for translation, CTC exhibits clear limitations due to the contextual and non-monotonic nature of the task and thus lags behind attentional decoder approaches in terms of translation quality. In this work, we argue that CTC does in fact make sense for translation if applied in a joint CTC/attention framework wherein CTC's core properties can counteract several key weaknesses of pure-attention models during training and decoding. To validate this conjecture, we modify the Hybrid CTC/Attention model originally proposed for ASR to support text-to-text translation (MT) and speech-to-text translation (ST). Our proposed joint CTC/attention models outperform pure-attention baselines across six benchmark translation tasks.
Understanding and Improving Zero-shot Multi-hop Reasoning in Generative Question Answering
Oct 09, 2022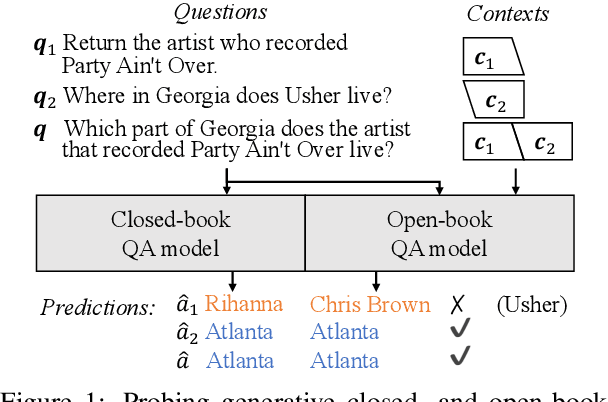

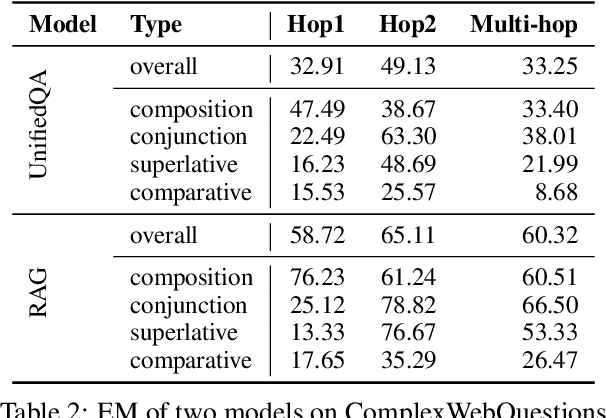
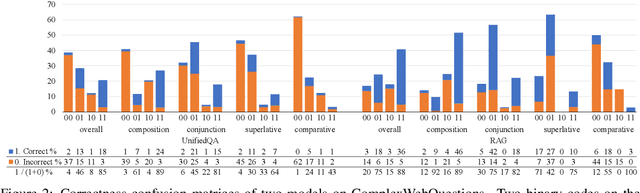
Generative question answering (QA) models generate answers to questions either solely based on the parameters of the model (the closed-book setting) or additionally retrieving relevant evidence (the open-book setting). Generative QA models can answer some relatively complex questions, but the mechanism through which they do so is still poorly understood. We perform several studies aimed at better understanding the multi-hop reasoning capabilities of generative QA models. First, we decompose multi-hop questions into multiple corresponding single-hop questions, and find marked inconsistency in QA models' answers on these pairs of ostensibly identical question chains. Second, we find that models lack zero-shot multi-hop reasoning ability: when trained only on single-hop questions, models generalize poorly to multi-hop questions. Finally, we demonstrate that it is possible to improve models' zero-shot multi-hop reasoning capacity through two methods that approximate real multi-hop natural language (NL) questions by training on either concatenation of single-hop questions or logical forms (SPARQL). In sum, these results demonstrate that multi-hop reasoning does not emerge naturally in generative QA models, but can be encouraged by advances in training or modeling techniques.
Are Representations Built from the Ground Up? An Empirical Examination of Local Composition in Language Models
Oct 07, 2022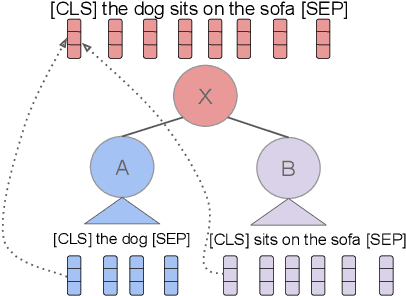

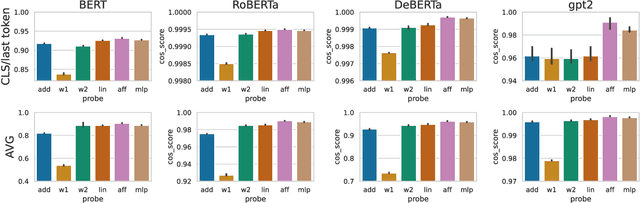

Compositionality, the phenomenon where the meaning of a phrase can be derived from its constituent parts, is a hallmark of human language. At the same time, many phrases are non-compositional, carrying a meaning beyond that of each part in isolation. Representing both of these types of phrases is critical for language understanding, but it is an open question whether modern language models (LMs) learn to do so; in this work we examine this question. We first formulate a problem of predicting the LM-internal representations of longer phrases given those of their constituents. We find that the representation of a parent phrase can be predicted with some accuracy given an affine transformation of its children. While we would expect the predictive accuracy to correlate with human judgments of semantic compositionality, we find this is largely not the case, indicating that LMs may not accurately distinguish between compositional and non-compositional phrases. We perform a variety of analyses, shedding light on when different varieties of LMs do and do not generate compositional representations, and discuss implications for future modeling work.
Mega: Moving Average Equipped Gated Attention
Sep 26, 2022
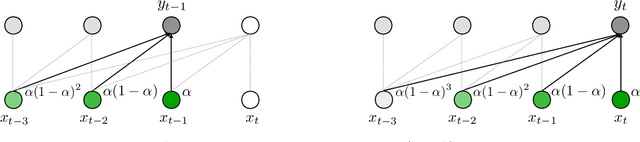
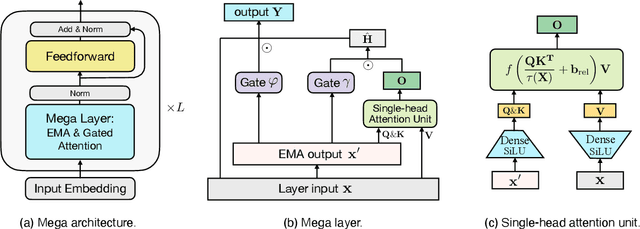
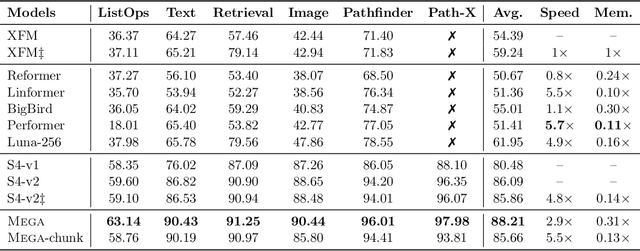
The design choices in the Transformer attention mechanism, including weak inductive bias and quadratic computational complexity, have limited its application for modeling long sequences. In this paper, we introduce Mega, a simple, theoretically grounded, single-head gated attention mechanism equipped with (exponential) moving average to incorporate inductive bias of position-aware local dependencies into the position-agnostic attention mechanism. We further propose a variant of Mega that offers linear time and space complexity yet yields only minimal quality loss, by efficiently splitting the whole sequence into multiple chunks with fixed length. Extensive experiments on a wide range of sequence modeling benchmarks, including the Long Range Arena, neural machine translation, auto-regressive language modeling, and image and speech classification, show that Mega achieves significant improvements over other sequence models, including variants of Transformers and recent state space models.
KGxBoard: Explainable and Interactive Leaderboard for Evaluation of Knowledge Graph Completion Models
Aug 23, 2022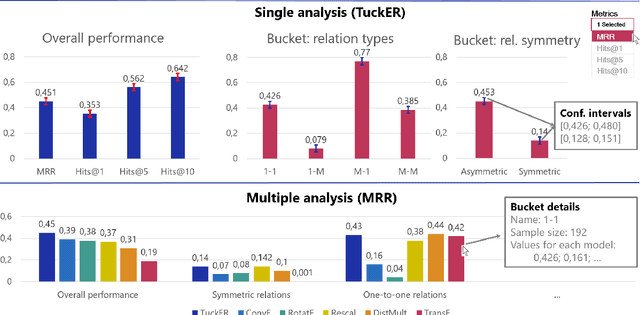
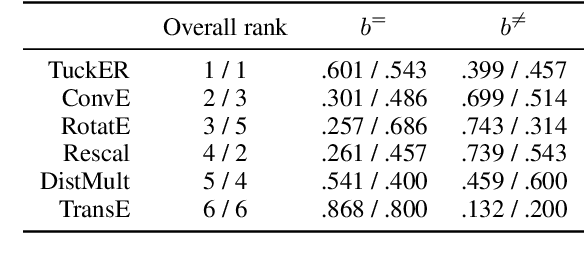

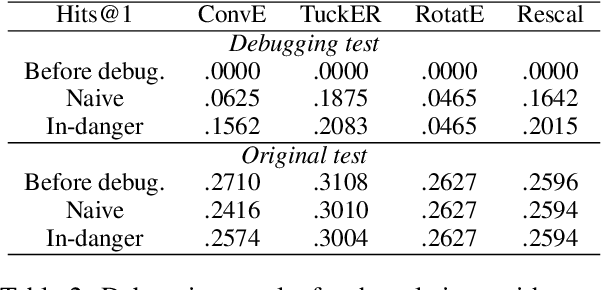
Knowledge Graphs (KGs) store information in the form of (head, predicate, tail)-triples. To augment KGs with new knowledge, researchers proposed models for KG Completion (KGC) tasks such as link prediction; i.e., answering (h; p; ?) or (?; p; t) queries. Such models are usually evaluated with averaged metrics on a held-out test set. While useful for tracking progress, averaged single-score metrics cannot reveal what exactly a model has learned -- or failed to learn. To address this issue, we propose KGxBoard: an interactive framework for performing fine-grained evaluation on meaningful subsets of the data, each of which tests individual and interpretable capabilities of a KGC model. In our experiments, we highlight the findings that we discovered with the use of KGxBoard, which would have been impossible to detect with standard averaged single-score metrics.
DocCoder: Generating Code by Retrieving and Reading Docs
Jul 13, 2022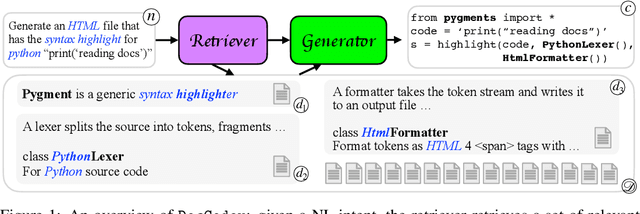
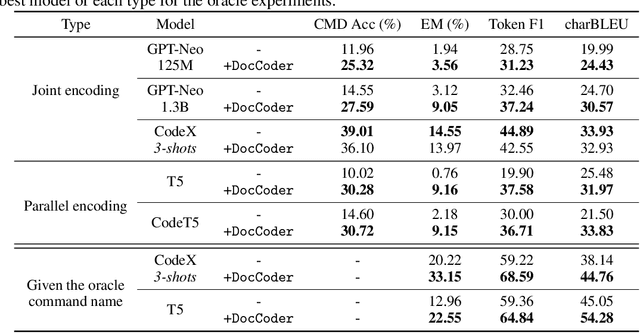
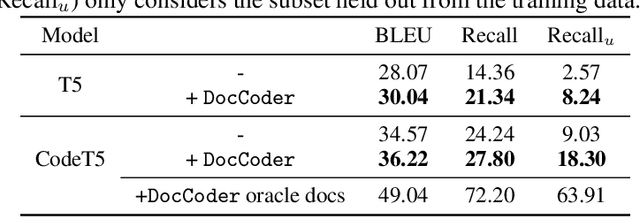
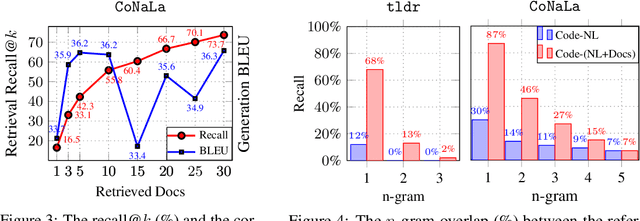
Natural-language-to-code models learn to generate a code snippet given a natural language (NL) intent. However, the rapid growth of both publicly available and proprietary libraries and functions makes it impossible to cover all APIs using training examples, as new libraries and functions are introduced daily. Thus, existing models inherently cannot generalize to using unseen functions and libraries merely through incorporating them into the training data. In contrast, when human programmers write programs, they frequently refer to textual resources such as code manuals, documentation, and tutorials, to explore and understand available library functionality. Inspired by this observation, we introduce DocCoder: an approach that explicitly leverages code manuals and documentation by (1) retrieving the relevant documentation given the NL intent, and (2) generating the code based on the NL intent and the retrieved documentation. Our approach is general, can be applied to any programming language, and is agnostic to the underlying neural model. We demonstrate that DocCoder consistently improves NL-to-code models: DocCoder achieves 11x higher exact match accuracy than strong baselines on a new Bash dataset tldr; on the popular Python CoNaLa benchmark, DocCoder improves over strong baselines by 1.65 BLEU.