 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAerial Scene Parsing: From Tile-level Scene Classification to Pixel-wise Semantic Labeling
Jan 09, 2022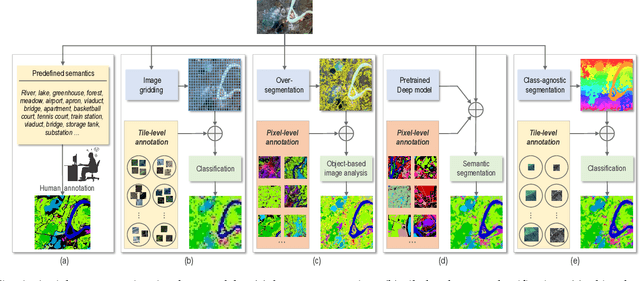
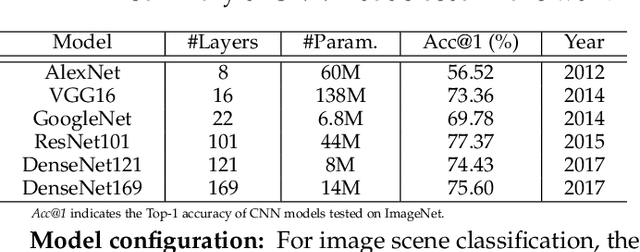
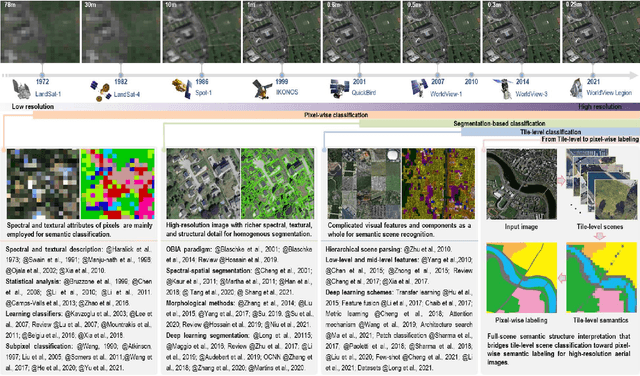

Given an aerial image, aerial scene parsing (ASP) targets to interpret the semantic structure of the image content, e.g., by assigning a semantic label to every pixel of the image. With the popularization of data-driven methods, the past decades have witnessed promising progress on ASP by approaching the problem with the schemes of tile-level scene classification or segmentation-based image analysis, when using high-resolution aerial images. However, the former scheme often produces results with tile-wise boundaries, while the latter one needs to handle the complex modeling process from pixels to semantics, which often requires large-scale and well-annotated image samples with pixel-wise semantic labels. In this paper, we address these issues in ASP, with perspectives from tile-level scene classification to pixel-wise semantic labeling. Specifically, we first revisit aerial image interpretation by a literature review. We then present a large-scale scene classification dataset that contains one million aerial images termed Million-AID. With the presented dataset, we also report benchmarking experiments using classical convolutional neural networks (CNNs). Finally, we perform ASP by unifying the tile-level scene classification and object-based image analysis to achieve pixel-wise semantic labeling. Intensive experiments show that Million-AID is a challenging yet useful dataset, which can serve as a benchmark for evaluating newly developed algorithms. When transferring knowledge from Million-AID, fine-tuning CNN models pretrained on Million-AID perform consistently better than those pretrained ImageNet for aerial scene classification. Moreover, our designed hierarchical multi-task learning method achieves the state-of-the-art pixel-wise classification on the challenging GID, bridging the tile-level scene classification toward pixel-wise semantic labeling for aerial image interpretation.
Anchor-free Oriented Proposal Generator for Object Detection
Oct 05, 2021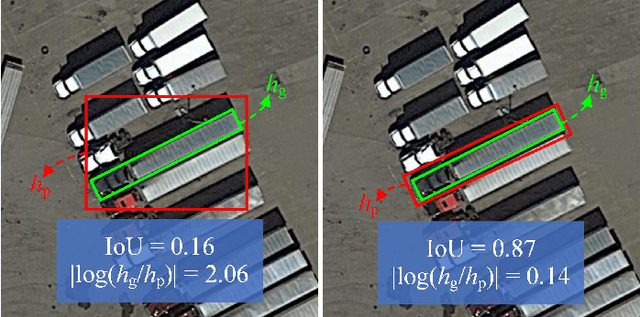

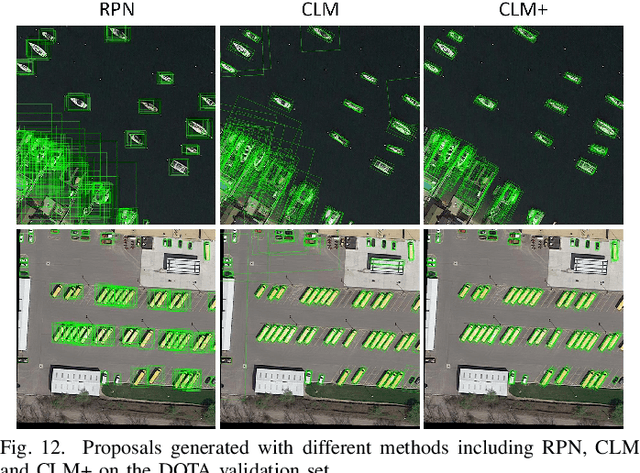
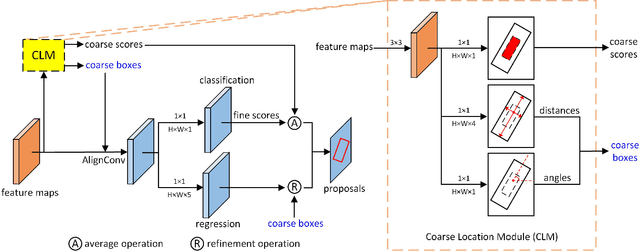
Oriented object detection is a practical and challenging task in remote sensing image interpretation. Nowadays, oriented detectors mostly use horizontal boxes as intermedium to derive oriented boxes from them. However, the horizontal boxes are inclined to get a small Intersection-over-Unions (IoUs) with ground truths, which may have some undesirable effects, such as introducing redundant noise, mismatching with ground truths, detracting from the robustness of detectors, etc. In this paper, we propose a novel Anchor-free Oriented Proposal Generator (AOPG) that abandons the horizontal boxes-related operations from the network architecture. AOPG first produces coarse oriented boxes by Coarse Location Module (CLM) in an anchor-free manner and then refines them into high-quality oriented proposals. After AOPG, we apply a Fast R-CNN head to produce the final detection results. Furthermore, the shortage of large-scale datasets is also a hindrance to the development of oriented object detection. To alleviate the data insufficiency, we release a new dataset on the basis of our DIOR dataset and name it DIOR-R. Massive experiments demonstrate the effectiveness of AOPG. Particularly, without bells and whistles, we achieve the highest accuracy of 64.41$\%$, 75.24$\%$ and 96.22$\%$ mAP on the DIOR-R, DOTA and HRSC2016 datasets respectively. Code and models are available at https://github.com/jbwang1997/AOPG.
When Retriever-Reader Meets Scenario-Based Multiple-Choice Questions
Sep 05, 2021

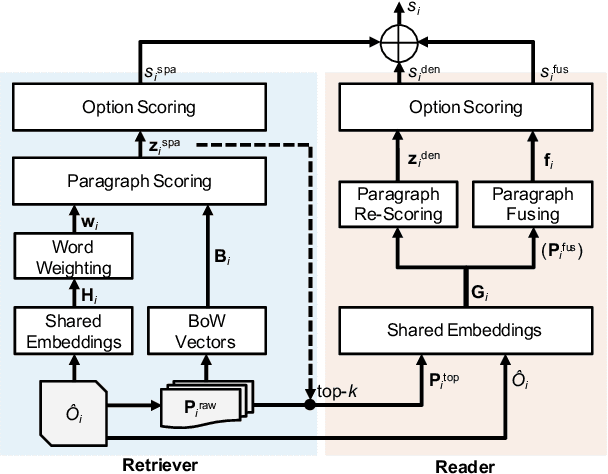
Scenario-based question answering (SQA) requires retrieving and reading paragraphs from a large corpus to answer a question which is contextualized by a long scenario description. Since a scenario contains both keyphrases for retrieval and much noise, retrieval for SQA is extremely difficult. Moreover, it can hardly be supervised due to the lack of relevance labels of paragraphs for SQA. To meet the challenge, in this paper we propose a joint retriever-reader model called JEEVES where the retriever is implicitly supervised only using QA labels via a novel word weighting mechanism. JEEVES significantly outperforms a variety of strong baselines on multiple-choice questions in three SQA datasets.
Oriented R-CNN for Object Detection
Aug 12, 2021
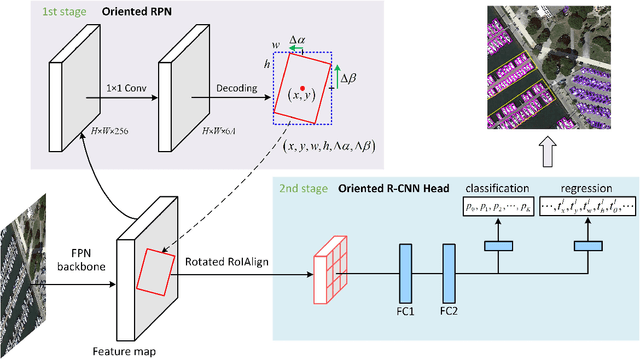
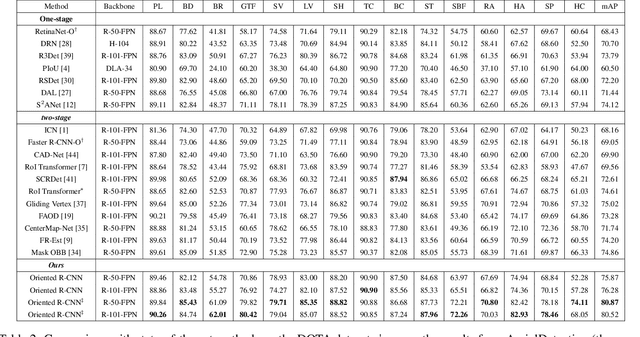
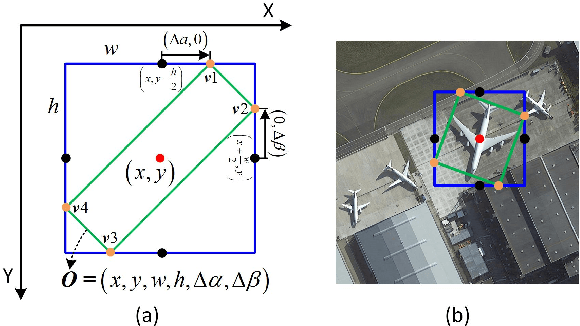
Current state-of-the-art two-stage detectors generate oriented proposals through time-consuming schemes. This diminishes the detectors' speed, thereby becoming the computational bottleneck in advanced oriented object detection systems. This work proposes an effective and simple oriented object detection framework, termed Oriented R-CNN, which is a general two-stage oriented detector with promising accuracy and efficiency. To be specific, in the first stage, we propose an oriented Region Proposal Network (oriented RPN) that directly generates high-quality oriented proposals in a nearly cost-free manner. The second stage is oriented R-CNN head for refining oriented Regions of Interest (oriented RoIs) and recognizing them. Without tricks, oriented R-CNN with ResNet50 achieves state-of-the-art detection accuracy on two commonly-used datasets for oriented object detection including DOTA (75.87% mAP) and HRSC2016 (96.50% mAP), while having a speed of 15.1 FPS with the image size of 1024$\times$1024 on a single RTX 2080Ti. We hope our work could inspire rethinking the design of oriented detectors and serve as a baseline for oriented object detection. Code is available at https://github.com/jbwang1997/OBBDetection.
Weakly Supervised Object Localization and Detection: A Survey
Apr 16, 2021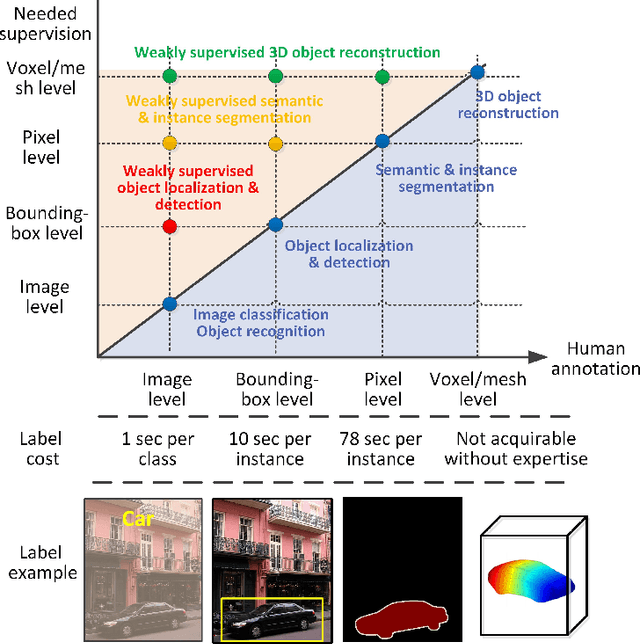

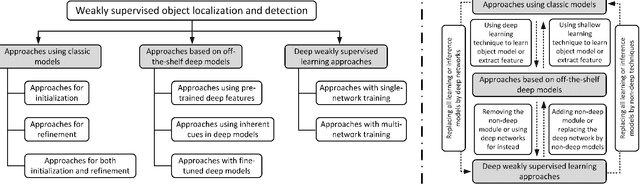
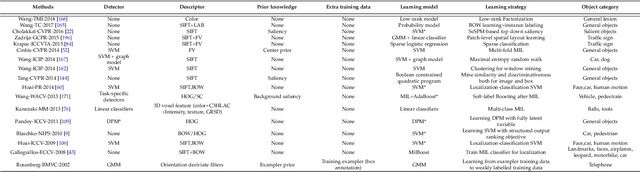
As an emerging and challenging problem in the computer vision community, weakly supervised object localization and detection plays an important role for developing new generation computer vision systems and has received significant attention in the past decade. As methods have been proposed, a comprehensive survey of these topics is of great importance. In this work, we review (1) classic models, (2) approaches with feature representations from off-the-shelf deep networks, (3) approaches solely based on deep learning, and (4) publicly available datasets and standard evaluation metrics that are widely used in this field. We also discuss the key challenges in this field, development history of this field, advantages/disadvantages of the methods in each category, the relationships between methods in different categories, applications of the weakly supervised object localization and detection methods, and potential future directions to further promote the development of this research field.
TSQA: Tabular Scenario Based Question Answering
Jan 14, 2021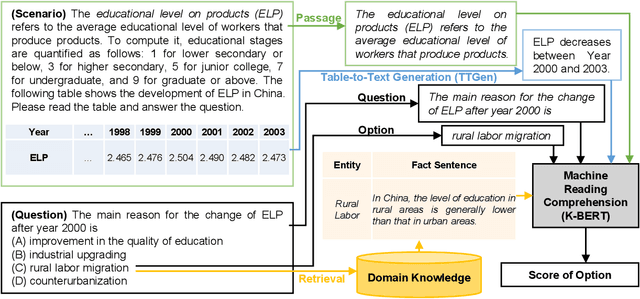

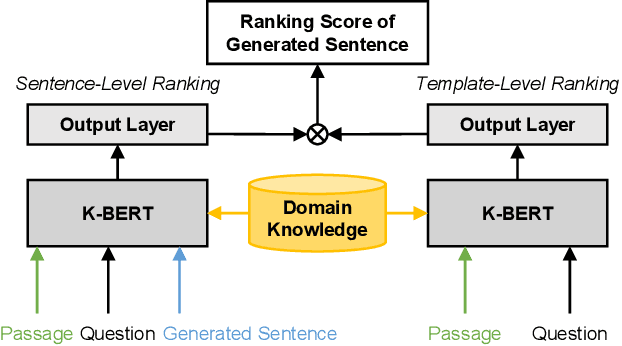
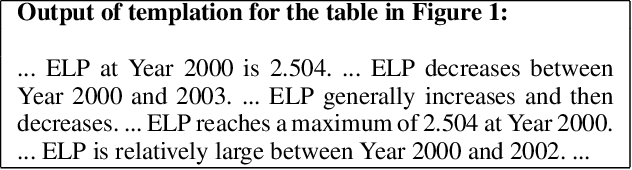
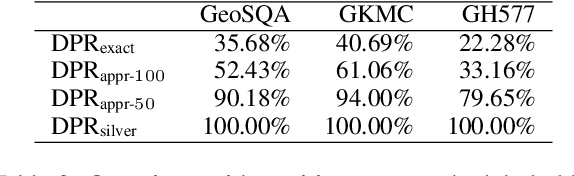
Scenario-based question answering (SQA) has attracted an increasing research interest. Compared with the well-studied machine reading comprehension (MRC), SQA is a more challenging task: a scenario may contain not only a textual passage to read but also structured data like tables, i.e., tabular scenario based question answering (TSQA). AI applications of TSQA such as answering multiple-choice questions in high-school exams require synthesizing data in multiple cells and combining tables with texts and domain knowledge to infer answers. To support the study of this task, we construct GeoTSQA. This dataset contains 1k real questions contextualized by tabular scenarios in the geography domain. To solve the task, we extend state-of-the-art MRC methods with TTGen, a novel table-to-text generator. It generates sentences from variously synthesized tabular data and feeds the downstream MRC method with the most useful sentences. Its sentence ranking model fuses the information in the scenario, question, and domain knowledge. Our approach outperforms a variety of strong baseline methods on GeoTSQA.
Neural Entity Summarization with Joint Encoding and Weak Supervision
May 10, 2020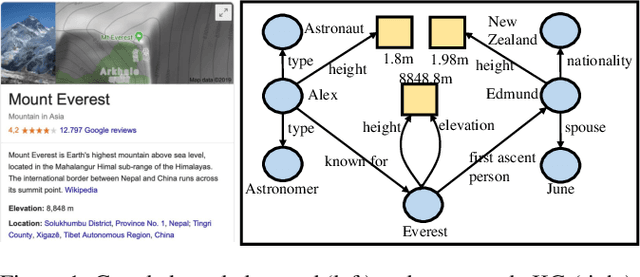

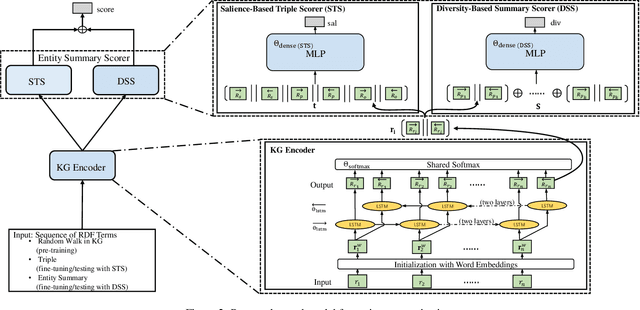
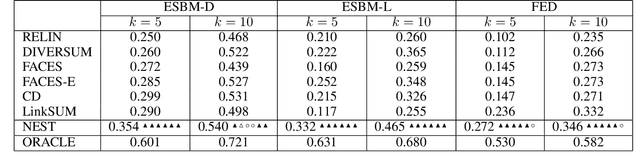
In a large-scale knowledge graph (KG), an entity is often described by a large number of triple-structured facts. Many applications require abridged versions of entity descriptions, called entity summaries. Existing solutions to entity summarization are mainly unsupervised. In this paper, we present a supervised approach NEST that is based on our novel neural model to jointly encode graph structure and text in KGs and generate high-quality diversified summaries. Since it is costly to obtain manually labeled summaries for training, our supervision is weak as we train with programmatically labeled data which may contain noise but is free of manual work. Evaluation results show that our approach significantly outperforms the state of the art on two public benchmarks.
Enriching Documents with Compact, Representative, Relevant Knowledge Graphs
May 10, 2020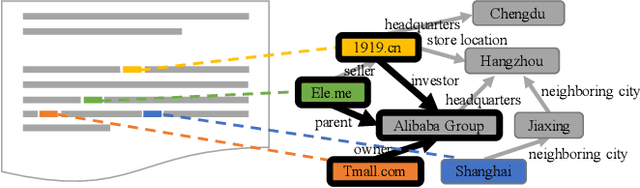

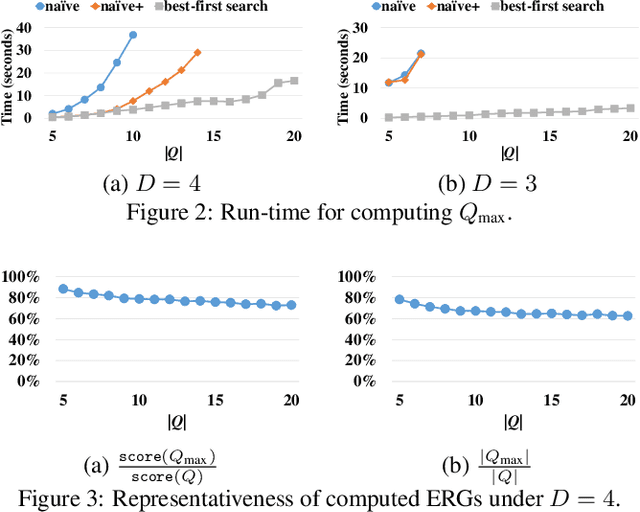
A prominent application of knowledge graph (KG) is document enrichment. Existing methods identify mentions of entities in a background KG and enrich documents with entity types and direct relations. We compute an entity relation subgraph (ERG) that can more expressively represent indirect relations among a set of mentioned entities. To find compact, representative, and relevant ERGs for effective enrichment, we propose an efficient best-first search algorithm to solve a new combinatorial optimization problem that achieves a trade-off between representativeness and compactness, and then we exploit ontological knowledge to rank ERGs by entity-based document-KG and intra-KG relevance. Extensive experiments and user studies show the promising performance of our approach.
Remote Sensing Image Scene Classification Meets Deep Learning: Challenges, Methods, Benchmarks, and Opportunities
May 03, 2020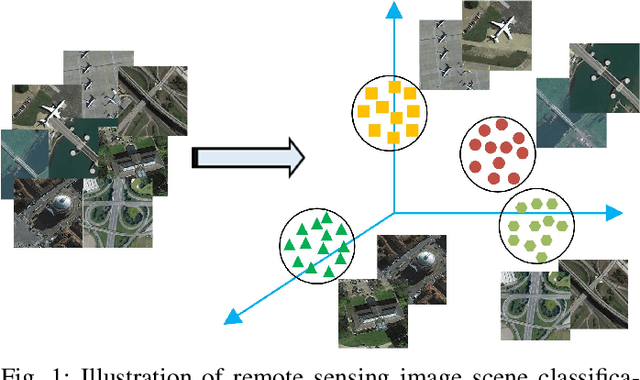
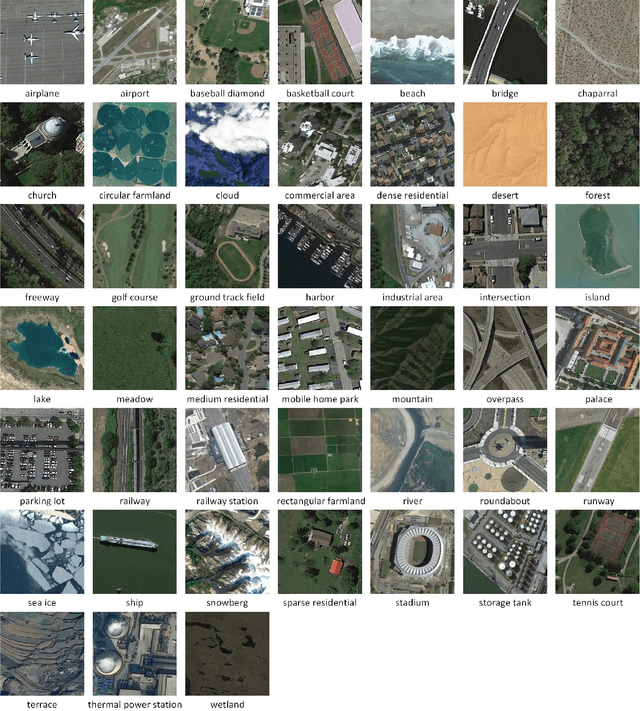
Remote sensing image scene classification, which aims at labeling remote sensing images with a set of semantic categories based on their contents, has broad applications in a range of fields. Propelled by the powerful feature learning capabilities of deep neural networks, remote sensing image scene classification driven by deep learning has drawn remarkable attention and achieved significant breakthroughs. However, to the best of our knowledge, a comprehensive review of recent achievements regarding deep learning for scene classification of remote sensing images is still lacking. Considering the rapid evolution of this field, this paper provides a systematic survey of deep learning methods for remote sensing image scene classification by covering more than 140 papers. To be specific, we discuss the main challenges of scene classification and survey (1) Autoencoder-based scene classification methods, (2) Convolutional Neural Network-based scene classification methods, and (3) Generative Adversarial Network-based scene classification methods. In addition, we introduce the benchmarks used for scene classification and summarize the performance of more than two dozens of representative algorithms on three commonly-used benchmark data sets. Finally, we discuss the promising opportunities for further research.
SPARQA: Skeleton-based Semantic Parsing for Complex Questions over Knowledge Bases
Mar 31, 2020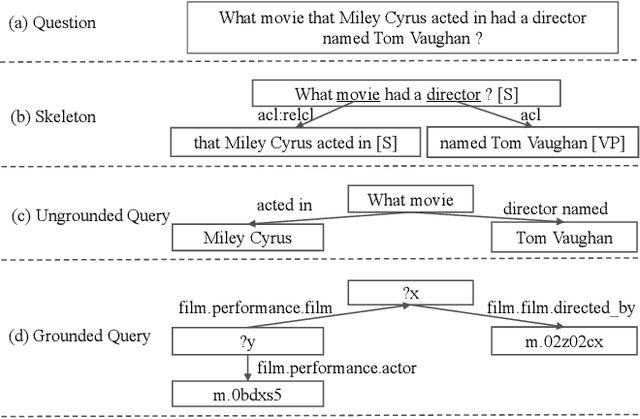
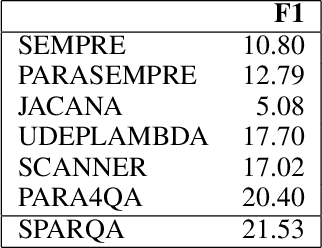
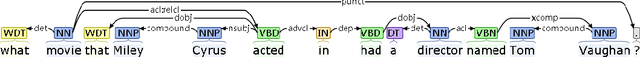

Semantic parsing transforms a natural language question into a formal query over a knowledge base. Many existing methods rely on syntactic parsing like dependencies. However, the accuracy of producing such expressive formalisms is not satisfying on long complex questions. In this paper, we propose a novel skeleton grammar to represent the high-level structure of a complex question. This dedicated coarse-grained formalism with a BERT-based parsing algorithm helps to improve the accuracy of the downstream fine-grained semantic parsing. Besides, to align the structure of a question with the structure of a knowledge base, our multi-strategy method combines sentence-level and word-level semantics. Our approach shows promising performance on several datasets.