 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Training-Free Multi-Token Prediction via Embedding-Space Probing
Mar 18, 2026Large language models (LLMs) exhibit latent multi-token prediction (MTP) capabilities despite being trained solely for next-token generation. We propose a simple, training-free MTP approach that probes an LLM using on-the-fly mask tokens drawn from its embedding space, enabling parallel prediction of future tokens without modifying model weights or relying on auxiliary draft models. Our method constructs a speculative token tree by sampling top-K candidates from mask-token logits and applies a lightweight pruning strategy to retain high-probability continuations. During decoding, candidate predictions are verified in parallel, resulting in lossless generation while substantially reducing the number of model calls and improving token throughput. Across benchmarks, our probing-based MTP consistently outperforms existing training-free baselines, increasing acceptance length by approximately 12\% on LLaMA3 and 8--12\% on Qwen3, and achieving throughput gains of up to 15--19\%. Finally, we provide theoretical insights and empirical evidence showing that decoder layers naturally align mask-token representations with next-token states, enabling accurate multi-step prediction without retraining or auxiliary models.
QUOKA: Query-Oriented KV Selection For Efficient LLM Prefill
Feb 09, 2026We present QUOKA: Query-oriented KV selection for efficient attention, a training-free and hardware agnostic sparse attention algorithm for accelerating transformer inference under chunked prefill. While many queries focus on a smaller group of keys in the attention operator, we observe that queries with low cosine similarity with respect to the mean query interact more strongly with more keys and have the greatest contribution to final attention logits. By prioritizing these low cosine similarity queries, the behavior of full attention during the prefill stage can be closely approximated. QUOKA leverages this observation, accelerating attention by (1) first retaining a small set of representative queries and (2) then subselectin the keys most aligned with those queries. Through experiments on Needle-In-A-Haystack, LongBench, RULER, and Math500, we show that, while realizing a 3x reduction in time-to-first-token, 5x speedup in attention on Nvidia GPUs and up to nearly a 7x speedup on Intel Xeon CPUs, QUOKA achieves near-baseline accuracy, utilizing 88% fewer key-value pairs per attention evaluation.
KeyDiff: Key Similarity-Based KV Cache Eviction for Long-Context LLM Inference in Resource-Constrained Environments
Apr 23, 2025In this work, we demonstrate that distinctive keys during LLM inference tend to have high attention scores. We explore this phenomenon and propose KeyDiff, a training-free KV cache eviction method based on key similarity. This method facilitates the deployment of LLM-based application requiring long input prompts in resource-constrained environments with limited memory and compute budgets. Unlike other KV cache eviction methods, KeyDiff can process arbitrarily long prompts within strict resource constraints and efficiently generate responses. We demonstrate that KeyDiff computes the optimal solution to a KV cache selection problem that maximizes key diversity, providing a theoretical understanding of KeyDiff. Notably,KeyDiff does not rely on attention scores, allowing the use of optimized attention mechanisms like FlashAttention. We demonstrate the effectiveness of KeyDiff across diverse tasks and models, illustrating a performance gap of less than 0.04\% with 8K cache budget ($\sim$ 23\% KV cache reduction) from the non-evicting baseline on the LongBench benchmark for Llama 3.1-8B and Llama 3.2-3B.
KeDiff: Key Similarity-Based KV Cache Eviction for Long-Context LLM Inference in Resource-Constrained Environments
Apr 21, 2025In this work, we demonstrate that distinctive keys during LLM inference tend to have high attention scores. We explore this phenomenon and propose KeyDiff, a training-free KV cache eviction method based on key similarity. This method facilitates the deployment of LLM-based application requiring long input prompts in resource-constrained environments with limited memory and compute budgets. Unlike other KV cache eviction methods, KeyDiff can process arbitrarily long prompts within strict resource constraints and efficiently generate responses. We demonstrate that KeyDiff computes the optimal solution to a KV cache selection problem that maximizes key diversity, providing a theoretical understanding of KeyDiff. Notably,KeyDiff does not rely on attention scores, allowing the use of optimized attention mechanisms like FlashAttention. We demonstrate the effectiveness of KeyDiff across diverse tasks and models, illustrating a performance gap of less than 0.04\% with 8K cache budget ($\sim$ 23\% KV cache reduction) from the non-evicting baseline on the LongBench benchmark for Llama 3.1-8B and Llama 3.2-3B.
CAOTE: KV Caching through Attention Output Error based Token Eviction
Apr 18, 2025While long context support of large language models has extended their abilities, it also incurs challenges in memory and compute which becomes crucial bottlenecks in resource-restricted devices. Token eviction, a widely adopted post-training methodology designed to alleviate the bottlenecks by evicting less important tokens from the cache, typically uses attention scores as proxy metrics for token importance. However, one major limitation of attention score as a token-wise importance metrics is that it lacks the information about contribution of tokens to the attention output. In this paper, we propose a simple eviction criterion based on the contribution of cached tokens to attention outputs. Our method, CAOTE, optimizes for eviction error due to token eviction, by seamlessly integrating attention scores and value vectors. This is the first method which uses value vector information on top of attention-based eviction scores. Additionally, CAOTE can act as a meta-heuristic method with flexible usage with any token eviction method. We show that CAOTE, when combined with the state-of-the-art attention score-based methods, always improves accuracies on the downstream task, indicating the importance of leveraging information from values during token eviction process.
Distilling Optimal Neural Networks: Rapid Search in Diverse Spaces
Dec 16, 2020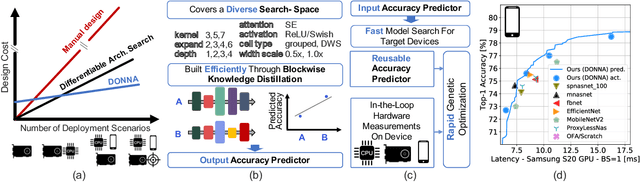



This work presents DONNA (Distilling Optimal Neural Network Architectures), a novel pipeline for rapid neural architecture search and search space exploration, targeting multiple different hardware platforms and user scenarios. In DONNA, a search consists of three phases. First, an accuracy predictor is built for a diverse search space using blockwise knowledge distillation. This predictor enables searching across diverse macro-architectural network parameters such as layer types, attention mechanisms, and channel widths, as well as across micro-architectural parameters such as block repeats, kernel sizes, and expansion rates. Second, a rapid evolutionary search phase finds a Pareto-optimal set of architectures in terms of accuracy and latency for any scenario using the predictor and on-device measurements. Third, Pareto-optimal models can be quickly finetuned to full accuracy. With this approach, DONNA finds architectures that outperform the state of the art. In ImageNet classification, architectures found by DONNA are 20% faster than EfficientNet-B0 and MobileNetV2 on a Nvidia V100 GPU at similar accuracy and 10% faster with 0.5% higher accuracy than MobileNetV2-1.4x on a Samsung S20 smartphone. In addition to neural architecture search, DONNA is used for search-space exploration and hardware-aware model compression.
Automatic Grammar Augmentation for Robust Voice Command Recognition
Nov 14, 2018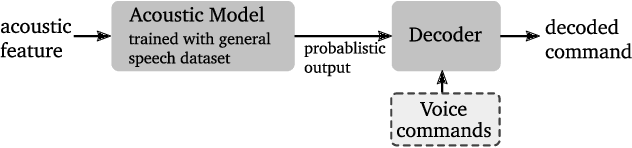


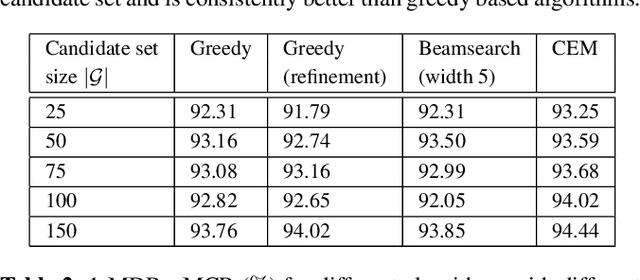
This paper proposes a novel pipeline for automatic grammar augmentation that provides a significant improvement in the voice command recognition accuracy for systems with small footprint acoustic model (AM). The improvement is achieved by augmenting the user-defined voice command set, also called grammar set, with alternate grammar expressions. For a given grammar set, a set of potential grammar expressions (candidate set) for augmentation is constructed from an AM-specific statistical pronunciation dictionary that captures the consistent patterns and errors in the decoding of AM induced by variations in pronunciation, pitch, tempo, accent, ambiguous spellings, and noise conditions. Using this candidate set, greedy optimization based and cross-entropy-method (CEM) based algorithms are considered to search for an augmented grammar set with improved recognition accuracy utilizing a command-specific dataset. Our experiments show that the proposed pipeline along with algorithms considered in this paper significantly reduce the mis-detection and mis-classification rate without increasing the false-alarm rate. Experiments also demonstrate the consistent superior performance of CEM method over greedy-based algorithms.