 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-Informed Laplace Neural Operator for Solving Partial Differential Equations
Feb 13, 2026Neural operators have emerged as fast surrogate solvers for parametric partial differential equations (PDEs). However, purely data-driven models often require extensive training data and can generalize poorly, especially in small-data regimes and under unseen (out-of-distribution) input functions that are not represented in the training data. To address these limitations, we propose the Physics-Informed Laplace Neural Operator (PILNO), which enhances the Laplace Neural Operator (LNO) by embedding governing physics into training through PDE, boundary condition, and initial condition residuals. To improve expressivity, we first introduce an Advanced LNO (ALNO) backbone that retains a pole-residue transient representation while replacing the steady-state branch with an FNO-style Fourier multiplier. To make physics-informed training both data-efficient and robust, PILNO further leverages (i) virtual inputs: an unlabeled ensemble of input functions spanning a broad spectral range that provides abundant physics-only supervision and explicitly targets out-of-distribution (OOD) regimes; and (ii) temporal-causality weighting: a time-decaying reweighting of the physics residual that prioritizes early-time dynamics and stabilizes optimization for time-dependent PDEs. Across four representative benchmarks -- Burgers' equation, Darcy flow, a reaction-diffusion system, and a forced KdV equation -- PILNO consistently improves accuracy in small-data settings (e.g., N_train <= 27), reduces run-to-run variability across random seeds, and achieves stronger OOD generalization than purely data-driven baselines.
An AI-enabled tool for quantifying overlapping red blood cell sickling dynamics in microfluidic assays
Jan 25, 2026Understanding sickle cell dynamics requires accurate identification of morphological transitions under diverse biophysical conditions, particularly in densely packed and overlapping cell populations. Here, we present an automated deep learning framework that integrates AI-assisted annotation, segmentation, classification, and instance counting to quantify red blood cell (RBC) populations across varying density regimes in time-lapse microscopy data. Experimental images were annotated using the Roboflow platform to generate labeled dataset for training an nnU-Net segmentation model. The trained network enables prediction of the temporal evolution of the sickle cell fraction, while a watershed algorithm resolves overlapping cells to enhance quantification accuracy. Despite requiring only a limited amount of labeled data for training, the framework achieves high segmentation performance, effectively addressing challenges associated with scarce manual annotations and cell overlap. By quantitatively tracking dynamic changes in RBC morphology, this approach can more than double the experimental throughput via densely packed cell suspensions, capture drug-dependent sickling behavior, and reveal distinct mechanobiological signatures of cellular morphological evolution. Overall, this AI-driven framework establishes a scalable and reproducible computational platform for investigating cellular biomechanics and assessing therapeutic efficacy in microphysiological systems.
GIMLET: Generalizable and Interpretable Model Learning through Embedded Thermodynamics
Dec 22, 2025We develop a data-driven framework for discovering constitutive relations in models of fluid flow and scalar transport. Our approach infers unknown closure terms in the governing equations (gray-box discovery) under the assumption that the temporal derivative, convective transport, and pressure-gradient contributions are known. The formulation is rooted in a variational principle from nonequilibrium thermodynamics, where the dynamics is defined by a free-energy functional and a dissipation functional. The unknown constitutive terms arise as functional derivatives of these functionals with respect to the state variables. To enable a flexible and structured model discovery, the free-energy and dissipation functionals are parameterized using neural networks, while their functional derivatives are obtained via automatic differentiation. This construction enforces thermodynamic consistency by design, ensuring monotonic decay of the total free energy and non-negative entropy production. The resulting method, termed GIMLET (Generalizable and Interpretable Model Learning through Embedded Thermodynamics), avoids reliance on a predefined library of candidate functions, unlike sparse regression or symbolic identification approaches. The learned models are generalizable in that functionals identified from one dataset can be transferred to distinct datasets governed by the same underlying equations. Moreover, the inferred free-energy and dissipation functions provide direct physical interpretability of the learned dynamics. The framework is demonstrated on several benchmark systems, including the viscous Burgers equation, the Kuramoto--Sivashinsky equation, and the incompressible Navier--Stokes equations for both Newtonian and non-Newtonian fluids.
Probabilistic Predictions of Process-Induced Deformation in Carbon/Epoxy Composites Using a Deep Operator Network
Dec 18, 2025



Fiber reinforcement and polymer matrix respond differently to manufacturing conditions due to mismatch in coefficient of thermal expansion and matrix shrinkage during curing of thermosets. These heterogeneities generate residual stresses over multiple length scales, whose partial release leads to process-induced deformation (PID), requiring accurate prediction and mitigation via optimized non-isothermal cure cycles. This study considers a unidirectional AS4 carbon fiber/amine bi-functional epoxy prepreg and models PID using a two-mechanism framework that accounts for thermal expansion/shrinkage and cure shrinkage. The model is validated against manufacturing trials to identify initial and boundary conditions, then used to generate PID responses for a diverse set of non-isothermal cure cycles (time-temperature profiles). Building on this physics-based foundation, we develop a data-driven surrogate based on Deep Operator Networks (DeepONets). A DeepONet is trained on a dataset combining high-fidelity simulations with targeted experimental measurements of PID. We extend this to a Feature-wise Linear Modulation (FiLM) DeepONet, where branch-network features are modulated by external parameters, including the initial degree of cure, enabling prediction of time histories of degree of cure, viscosity, and deformation. Because experimental data are available only at limited time instances (for example, final deformation), we use transfer learning: simulation-trained trunk and branch networks are fixed and only the final layer is updated using measured final deformation. Finally, we augment the framework with Ensemble Kalman Inversion (EKI) to quantify uncertainty under experimental conditions and to support optimization of cure schedules for reduced PID in composites.
Hybrid Iterative Solvers with Geometry-Aware Neural Preconditioners for Parametric PDEs
Dec 16, 2025

The convergence behavior of classical iterative solvers for parametric partial differential equations (PDEs) is often highly sensitive to the domain and specific discretization of PDEs. Previously, we introduced hybrid solvers by combining the classical solvers with neural operators for a specific geometry 1, but they tend to under-perform in geometries not encountered during training. To address this challenge, we introduce Geo-DeepONet, a geometry-aware deep operator network that incorporates domain information extracted from finite element discretizations. Geo-DeepONet enables accurate operator learning across arbitrary unstructured meshes without requiring retraining. Building on this, we develop a class of geometry-aware hybrid preconditioned iterative solvers by coupling Geo-DeepONet with traditional methods such as relaxation schemes and Krylov subspace algorithms. Through numerical experiments on parametric PDEs posed over diverse unstructured domains, we demonstrate the enhanced robustness and efficiency of the proposed hybrid solvers for multiple real-world applications.
Kinetic-Mamba: Mamba-Assisted Predictions of Stiff Chemical Kinetics
Dec 16, 2025Accurate chemical kinetics modeling is essential for combustion simulations, as it governs the evolution of complex reaction pathways and thermochemical states. In this work, we introduce Kinetic-Mamba, a Mamba-based neural operator framework that integrates the expressive power of neural operators with the efficient temporal modeling capabilities of Mamba architectures. The framework comprises three complementary models: (i) a standalone Mamba model that predicts the time evolution of thermochemical state variables from given initial conditions; (ii) a constrained Mamba model that enforces mass conservation while learning the state dynamics; and (iii) a regime-informed architecture employing two standalone Mamba models to capture dynamics across temperature-dependent regimes. We additionally develop a latent Kinetic-Mamba variant that evolves dynamics in a reduced latent space and reconstructs the full state on the physical manifold. We evaluate the accuracy and robustness of Kinetic-Mamba using both time-decomposition and recursive-prediction strategies. We further assess the extrapolation capabilities of the model on varied out-of-distribution datasets. Computational experiments on Syngas and GRI-Mech 3.0 reaction mechanisms demonstrate that our framework achieves high fidelity in predicting complex kinetic behavior using only the initial conditions of the state variables.
A Neural-Operator Preconditioned Newton Method for Accelerated Nonlinear Solvers
Nov 11, 2025



We propose a novel neural preconditioned Newton (NP-Newton) method for solving parametric nonlinear systems of equations. To overcome the stagnation or instability of Newton iterations caused by unbalanced nonlinearities, we introduce a fixed-point neural operator (FPNO) that learns the direct mapping from the current iterate to the solution by emulating fixed-point iterations. Unlike traditional line-search or trust-region algorithms, the proposed FPNO adaptively employs negative step sizes to effectively mitigate the effects of unbalanced nonlinearities. Through numerical experiments we demonstrate the computational efficiency and robustness of the proposed NP-Newton method across multiple real-world applications, especially for very strong nonlinearities.
From LIF to QIF: Toward Differentiable Spiking Neurons for Scientific Machine Learning
Nov 10, 2025Spiking neural networks (SNNs) offer biologically inspired computation but remain underexplored for continuous regression tasks in scientific machine learning. In this work, we introduce and systematically evaluate Quadratic Integrate-and-Fire (QIF) neurons as an alternative to the conventional Leaky Integrate-and-Fire (LIF) model in both directly trained SNNs and ANN-to-SNN conversion frameworks. The QIF neuron exhibits smooth and differentiable spiking dynamics, enabling gradient-based training and stable optimization within architectures such as multilayer perceptrons (MLPs), Deep Operator Networks (DeepONets), and Physics-Informed Neural Networks (PINNs). Across benchmarks on function approximation, operator learning, and partial differential equation (PDE) solving, QIF-based networks yield smoother, more accurate, and more stable predictions than their LIF counterparts, which suffer from discontinuous time-step responses and jagged activation surfaces. These results position the QIF neuron as a computational bridge between spiking and continuous-valued deep learning, advancing the integration of neuroscience-inspired dynamics into physics-informed and operator-learning frameworks.
A Variational Framework for Residual-Based Adaptivity in Neural PDE Solvers and Operator Learning
Sep 17, 2025Residual-based adaptive strategies are widely used in scientific machine learning but remain largely heuristic. We introduce a unifying variational framework that formalizes these methods by integrating convex transformations of the residual. Different transformations correspond to distinct objective functionals: exponential weights target the minimization of uniform error, while linear weights recover the minimization of quadratic error. Within this perspective, adaptive weighting is equivalent to selecting sampling distributions that optimize the primal objective, thereby linking discretization choices directly to error metrics. This principled approach yields three benefits: (1) it enables systematic design of adaptive schemes across norms, (2) reduces discretization error through variance reduction of the loss estimator, and (3) enhances learning dynamics by improving the gradient signal-to-noise ratio. Extending the framework to operator learning, we demonstrate substantial performance gains across optimizers and architectures. Our results provide a theoretical justification of residual-based adaptivity and establish a foundation for principled discretization and training strategies.
Learning Turbulent Flows with Generative Models: Super-resolution, Forecasting, and Sparse Flow Reconstruction
Sep 10, 2025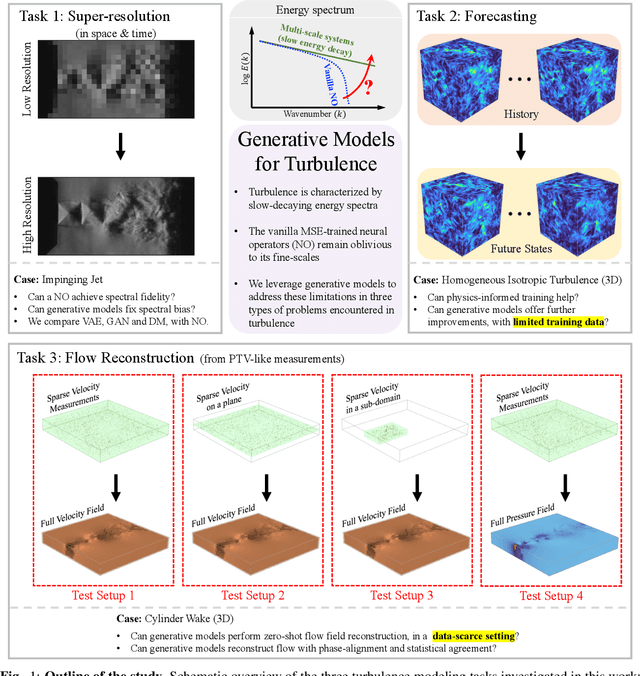
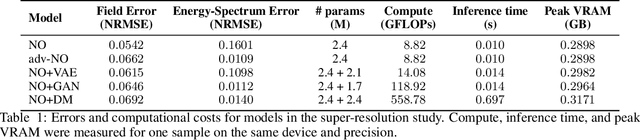
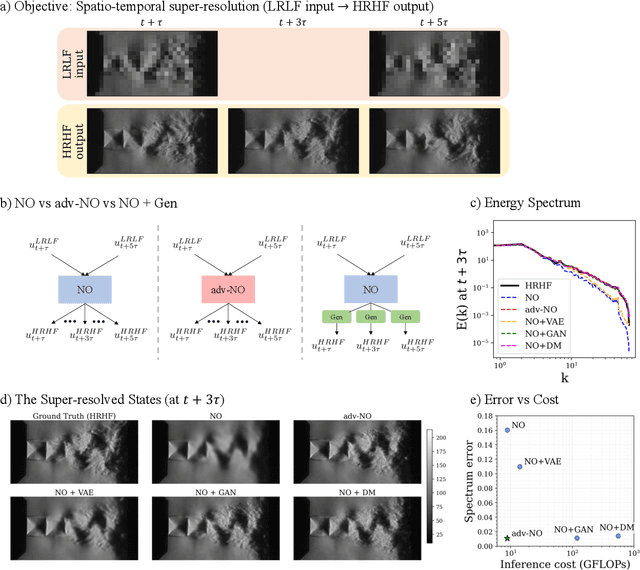

Neural operators are promising surrogates for dynamical systems but when trained with standard L2 losses they tend to oversmooth fine-scale turbulent structures. Here, we show that combining operator learning with generative modeling overcomes this limitation. We consider three practical turbulent-flow challenges where conventional neural operators fail: spatio-temporal super-resolution, forecasting, and sparse flow reconstruction. For Schlieren jet super-resolution, an adversarially trained neural operator (adv-NO) reduces the energy-spectrum error by 15x while preserving sharp gradients at neural operator-like inference cost. For 3D homogeneous isotropic turbulence, adv-NO trained on only 160 timesteps from a single trajectory forecasts accurately for five eddy-turnover times and offers 114x wall-clock speed-up at inference than the baseline diffusion-based forecasters, enabling near-real-time rollouts. For reconstructing cylinder wake flows from highly sparse Particle Tracking Velocimetry-like inputs, a conditional generative model infers full 3D velocity and pressure fields with correct phase alignment and statistics. These advances enable accurate reconstruction and forecasting at low compute cost, bringing near-real-time analysis and control within reach in experimental and computational fluid mechanics. See our project page: https://vivekoommen.github.io/Gen4Turb/