 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoubly Reparameterized Gradient Estimators for Monte Carlo Objectives
Oct 09, 2018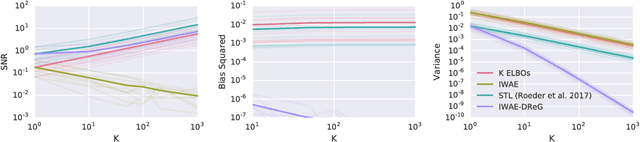
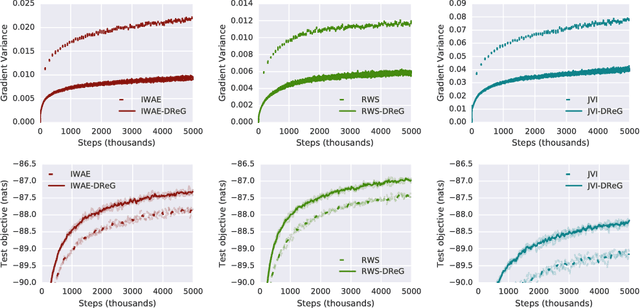
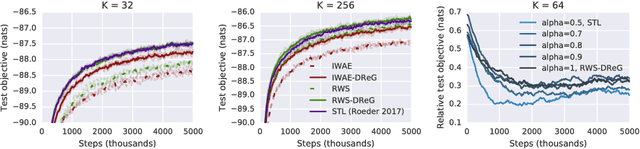
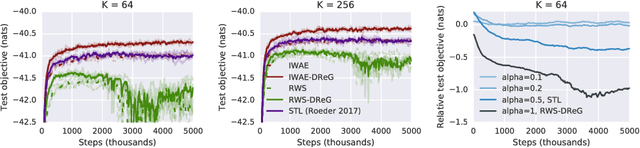
Deep latent variable models have become a popular model choice due to the scalable learning algorithms introduced by (Kingma & Welling, 2013; Rezende et al., 2014). These approaches maximize a variational lower bound on the intractable log likelihood of the observed data. Burda et al. (2015) introduced a multi-sample variational bound, IWAE, that is at least as tight as the standard variational lower bound and becomes increasingly tight as the number of samples increases. Counterintuitively, the typical inference network gradient estimator for the IWAE bound performs poorly as the number of samples increases (Rainforth et al., 2018; Le et al., 2018). Roeder et al. (2017) propose an improved gradient estimator, however, are unable to show it is unbiased. We show that it is in fact biased and that the bias can be estimated efficiently with a second application of the reparameterization trick. The doubly reparameterized gradient (DReG) estimator does not suffer as the number of samples increases, resolving the previously raised issues. The same idea can be used to improve many recently introduced training techniques for latent variable models. In particular, we show that this estimator reduces the variance of the IWAE gradient, the reweighted wake-sleep update (RWS) (Bornschein & Bengio, 2014), and the jackknife variational inference (JVI) gradient (Nowozin, 2018). Finally, we show that this computationally efficient, unbiased drop-in gradient estimator translates to improved performance for all three objectives on several modeling tasks.
Smoothed Action Value Functions for Learning Gaussian Policies
Jul 25, 2018
State-action value functions (i.e., Q-values) are ubiquitous in reinforcement learning (RL), giving rise to popular algorithms such as SARSA and Q-learning. We propose a new notion of action value defined by a Gaussian smoothed version of the expected Q-value. We show that such smoothed Q-values still satisfy a Bellman equation, making them learnable from experience sampled from an environment. Moreover, the gradients of expected reward with respect to the mean and covariance of a parameterized Gaussian policy can be recovered from the gradient and Hessian of the smoothed Q-value function. Based on these relationships, we develop new algorithms for training a Gaussian policy directly from a learned smoothed Q-value approximator. The approach is additionally amenable to proximal optimization by augmenting the objective with a penalty on KL-divergence from a previous policy. We find that the ability to learn both a mean and covariance during training leads to significantly improved results on standard continuous control benchmarks.
Sample-Efficient Reinforcement Learning with Stochastic Ensemble Value Expansion
Jul 04, 2018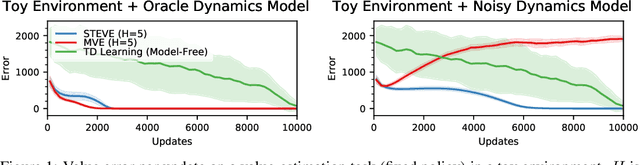
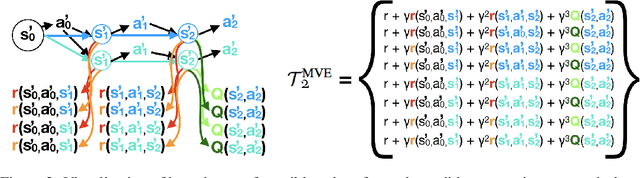
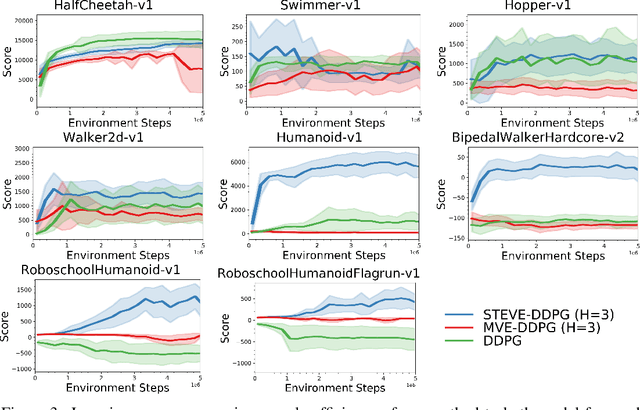
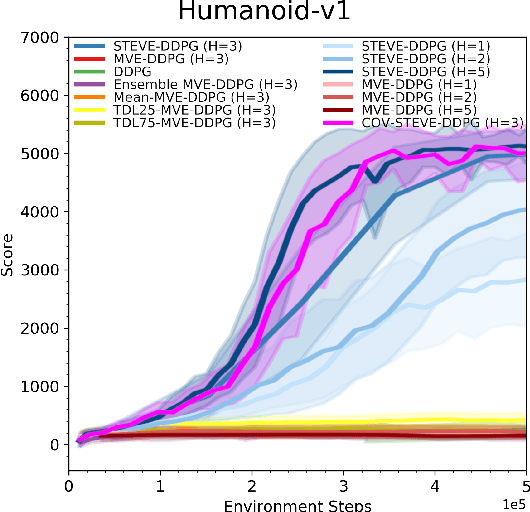
Integrating model-free and model-based approaches in reinforcement learning has the potential to achieve the high performance of model-free algorithms with low sample complexity. However, this is difficult because an imperfect dynamics model can degrade the performance of the learning algorithm, and in sufficiently complex environments, the dynamics model will almost always be imperfect. As a result, a key challenge is to combine model-based approaches with model-free learning in such a way that errors in the model do not degrade performance. We propose stochastic ensemble value expansion (STEVE), a novel model-based technique that addresses this issue. By dynamically interpolating between model rollouts of various horizon lengths for each individual example, STEVE ensures that the model is only utilized when doing so does not introduce significant errors. Our approach outperforms model-free baselines on challenging continuous control benchmarks with an order-of-magnitude increase in sample efficiency, and in contrast to previous model-based approaches, performance does not degrade in complex environments.
Guided evolutionary strategies: escaping the curse of dimensionality in random search
Jun 28, 2018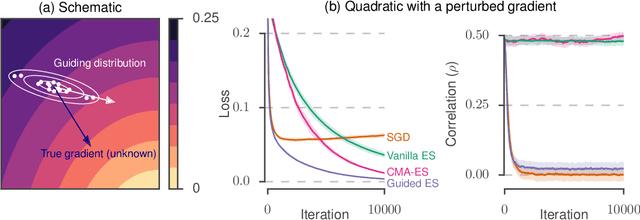
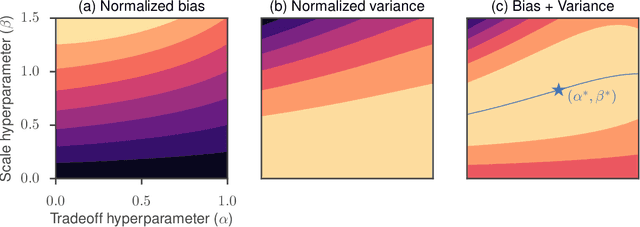
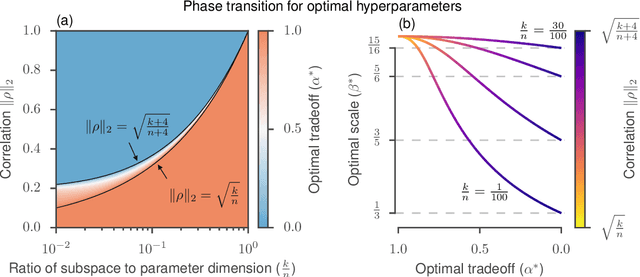
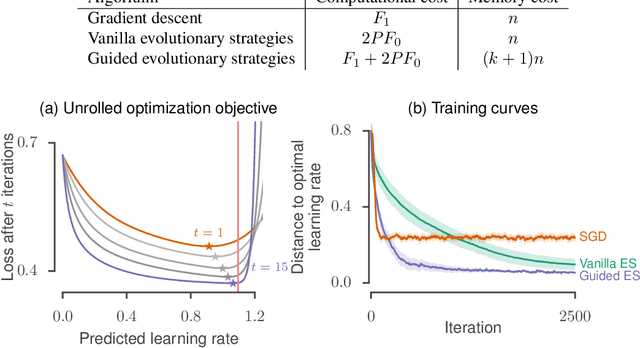
Many applications in machine learning require optimizing a function whose true gradient is unknown, but where surrogate gradient information (directions that may be correlated with, but not necessarily identical to, the true gradient) is available instead. This arises when an approximate gradient is easier to compute than the full gradient (e.g. in meta-learning or unrolled optimization), or when a true gradient is intractable and is replaced with a surrogate (e.g. in certain reinforcement learning applications, or when using synthetic gradients). We propose Guided Evolutionary Strategies, a method for optimally using surrogate gradient directions along with random search. We define a search distribution for evolutionary strategies that is elongated along a guiding subspace spanned by the surrogate gradients. This allows us to estimate a descent direction which can then be passed to a first-order optimizer. We analytically and numerically characterize the tradeoffs that result from tuning how strongly the search distribution is stretched along the guiding subspace, and we use this to derive a setting of the hyperparameters that works well across problems. Finally, we apply our method to example problems including truncated unrolled optimization and a synthetic gradient problem, demonstrating improvement over both standard evolutionary strategies and first-order methods that directly follow the surrogate gradient. We provide a demo of Guided ES at https://github.com/brain-research/guided-evolutionary-strategies
The Mirage of Action-Dependent Baselines in Reinforcement Learning
Apr 06, 2018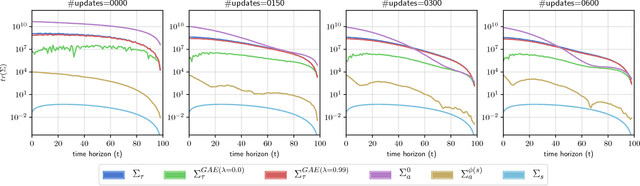
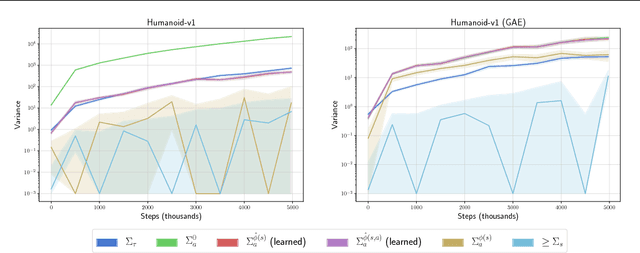
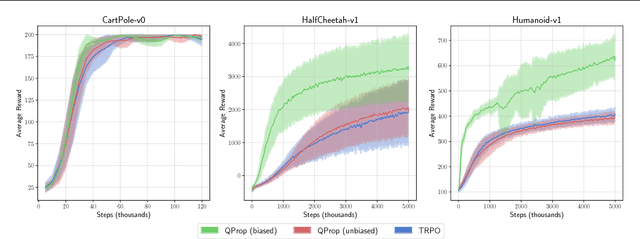
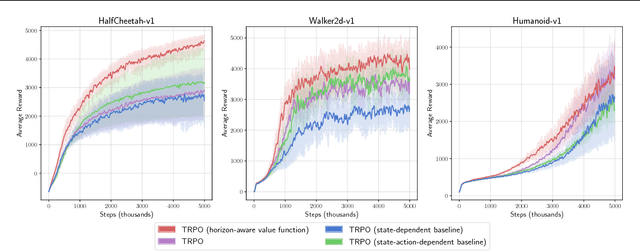
Policy gradient methods are a widely used class of model-free reinforcement learning algorithms where a state-dependent baseline is used to reduce gradient estimator variance. Several recent papers extend the baseline to depend on both the state and action and suggest that this significantly reduces variance and improves sample efficiency without introducing bias into the gradient estimates. To better understand this development, we decompose the variance of the policy gradient estimator and numerically show that learned state-action-dependent baselines do not in fact reduce variance over a state-dependent baseline in commonly tested benchmark domains. We confirm this unexpected result by reviewing the open-source code accompanying these prior papers, and show that subtle implementation decisions cause deviations from the methods presented in the papers and explain the source of the previously observed empirical gains. Furthermore, the variance decomposition highlights areas for improvement, which we demonstrate by illustrating a simple change to the typical value function parameterization that can significantly improve performance.
Deep Bayesian Bandits Showdown: An Empirical Comparison of Bayesian Deep Networks for Thompson Sampling
Feb 26, 2018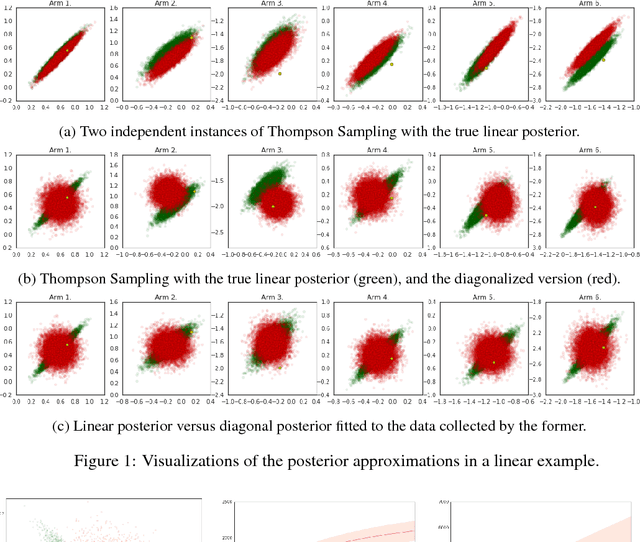
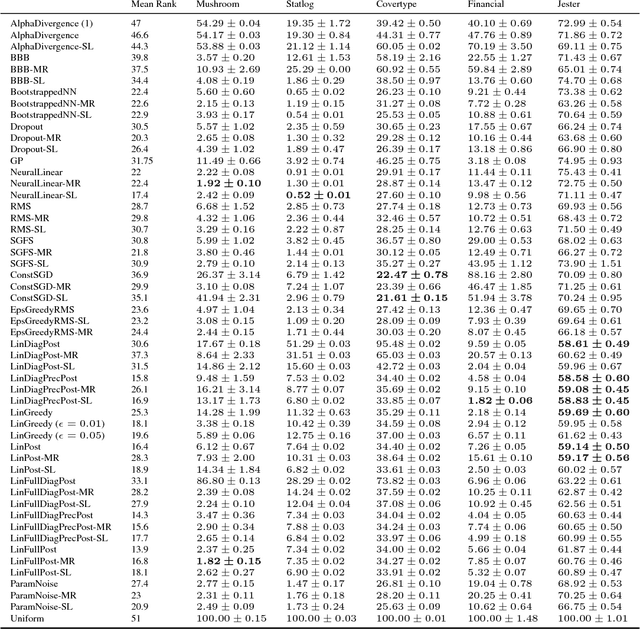
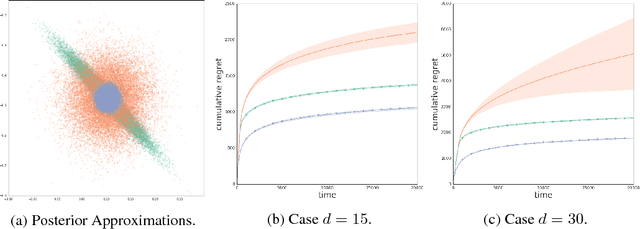

Recent advances in deep reinforcement learning have made significant strides in performance on applications such as Go and Atari games. However, developing practical methods to balance exploration and exploitation in complex domains remains largely unsolved. Thompson Sampling and its extension to reinforcement learning provide an elegant approach to exploration that only requires access to posterior samples of the model. At the same time, advances in approximate Bayesian methods have made posterior approximation for flexible neural network models practical. Thus, it is attractive to consider approximate Bayesian neural networks in a Thompson Sampling framework. To understand the impact of using an approximate posterior on Thompson Sampling, we benchmark well-established and recently developed methods for approximate posterior sampling combined with Thompson Sampling over a series of contextual bandit problems. We found that many approaches that have been successful in the supervised learning setting underperformed in the sequential decision-making scenario. In particular, we highlight the challenge of adapting slowly converging uncertainty estimates to the online setting.
Filtering Variational Objectives
Nov 12, 2017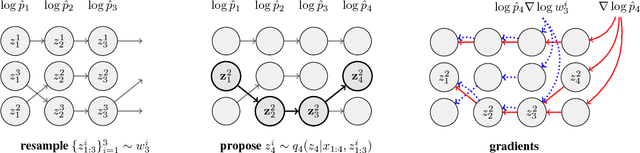
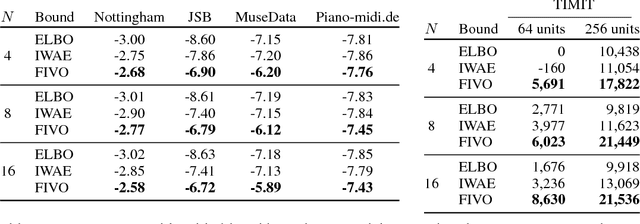
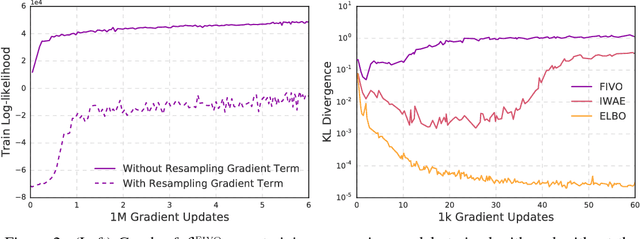
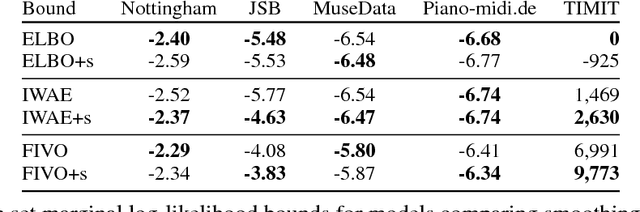
When used as a surrogate objective for maximum likelihood estimation in latent variable models, the evidence lower bound (ELBO) produces state-of-the-art results. Inspired by this, we consider the extension of the ELBO to a family of lower bounds defined by a particle filter's estimator of the marginal likelihood, the filtering variational objectives (FIVOs). FIVOs take the same arguments as the ELBO, but can exploit a model's sequential structure to form tighter bounds. We present results that relate the tightness of FIVO's bound to the variance of the particle filter's estimator by considering the generic case of bounds defined as log-transformed likelihood estimators. Experimentally, we show that training with FIVO results in substantial improvements over training the same model architecture with the ELBO on sequential data.
REBAR: Low-variance, unbiased gradient estimates for discrete latent variable models
Nov 06, 2017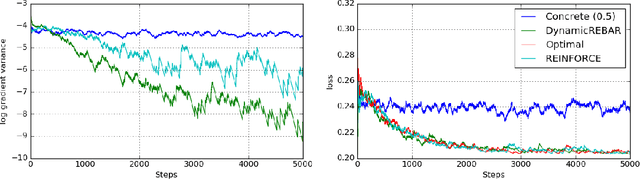
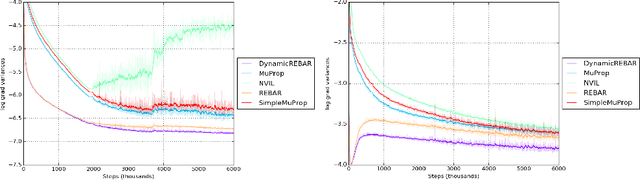
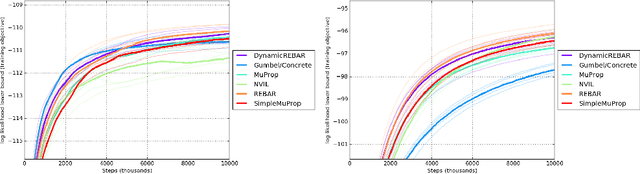
Learning in models with discrete latent variables is challenging due to high variance gradient estimators. Generally, approaches have relied on control variates to reduce the variance of the REINFORCE estimator. Recent work (Jang et al. 2016, Maddison et al. 2016) has taken a different approach, introducing a continuous relaxation of discrete variables to produce low-variance, but biased, gradient estimates. In this work, we combine the two approaches through a novel control variate that produces low-variance, \emph{unbiased} gradient estimates. Then, we introduce a modification to the continuous relaxation and show that the tightness of the relaxation can be adapted online, removing it as a hyperparameter. We show state-of-the-art variance reduction on several benchmark generative modeling tasks, generally leading to faster convergence to a better final log-likelihood.
Learning Hard Alignments with Variational Inference
Nov 01, 2017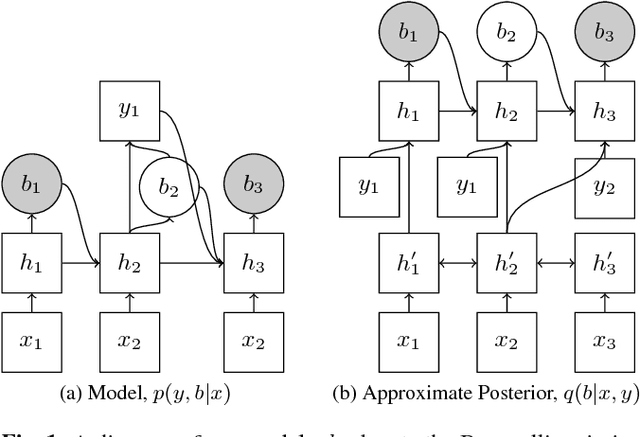
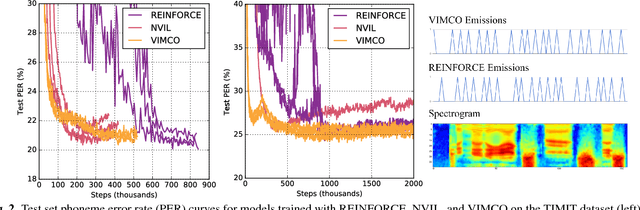
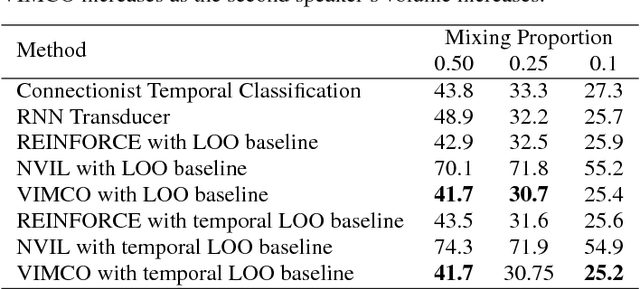
There has recently been significant interest in hard attention models for tasks such as object recognition, visual captioning and speech recognition. Hard attention can offer benefits over soft attention such as decreased computational cost, but training hard attention models can be difficult because of the discrete latent variables they introduce. Previous work used REINFORCE and Q-learning to approach these issues, but those methods can provide high-variance gradient estimates and be slow to train. In this paper, we tackle the problem of learning hard attention for a sequential task using variational inference methods, specifically the recently introduced VIMCO and NVIL. Furthermore, we propose a novel baseline that adapts VIMCO to this setting. We demonstrate our method on a phoneme recognition task in clean and noisy environments and show that our method outperforms REINFORCE, with the difference being greater for a more complicated task.
An online sequence-to-sequence model for noisy speech recognition
Jun 16, 2017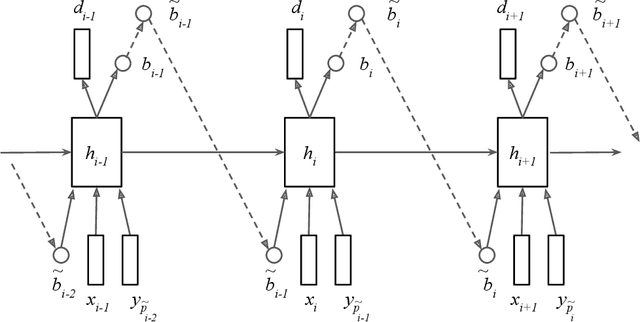
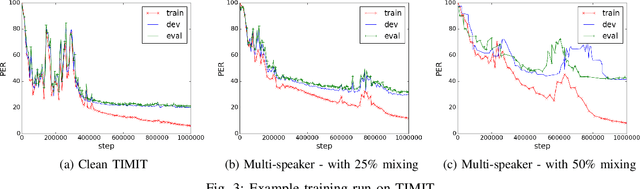
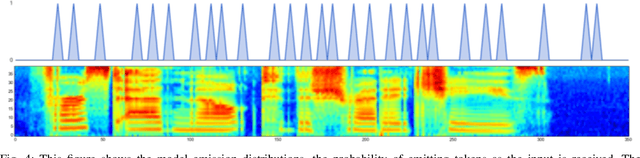
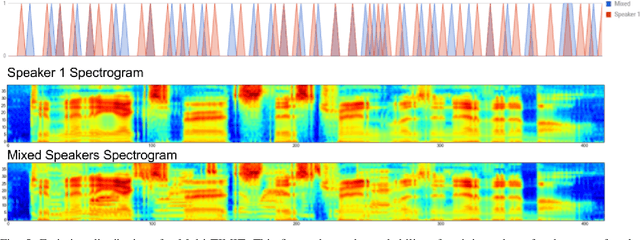
Generative models have long been the dominant approach for speech recognition. The success of these models however relies on the use of sophisticated recipes and complicated machinery that is not easily accessible to non-practitioners. Recent innovations in Deep Learning have given rise to an alternative - discriminative models called Sequence-to-Sequence models, that can almost match the accuracy of state of the art generative models. While these models are easy to train as they can be trained end-to-end in a single step, they have a practical limitation that they can only be used for offline recognition. This is because the models require that the entirety of the input sequence be available at the beginning of inference, an assumption that is not valid for instantaneous speech recognition. To address this problem, online sequence-to-sequence models were recently introduced. These models are able to start producing outputs as data arrives, and the model feels confident enough to output partial transcripts. These models, like sequence-to-sequence are causal - the output produced by the model until any time, $t$, affects the features that are computed subsequently. This makes the model inherently more powerful than generative models that are unable to change features that are computed from the data. This paper highlights two main contributions - an improvement to online sequence-to-sequence model training, and its application to noisy settings with mixed speech from two speakers.