 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge4-bit Quantization of LSTM-based Speech Recognition Models
Aug 27, 2021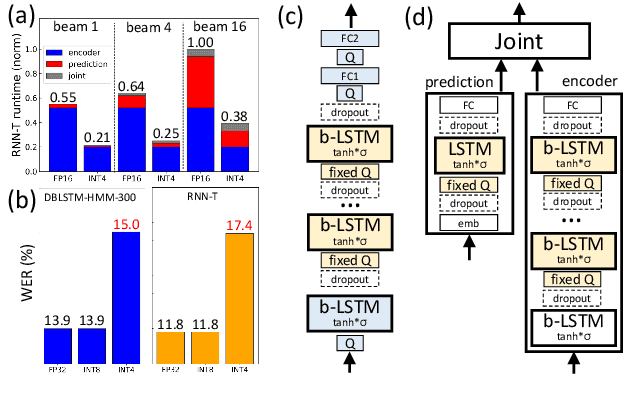
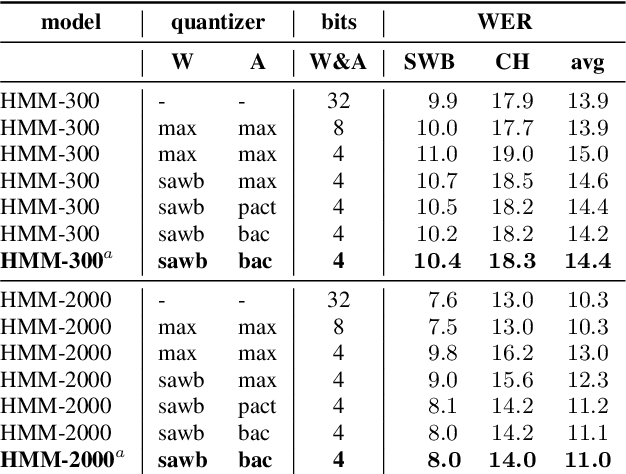
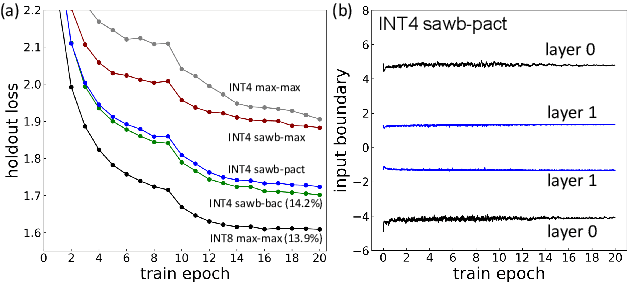
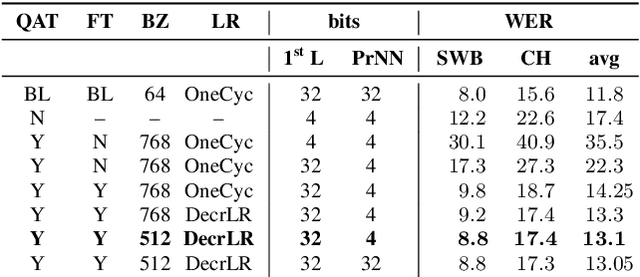
We investigate the impact of aggressive low-precision representations of weights and activations in two families of large LSTM-based architectures for Automatic Speech Recognition (ASR): hybrid Deep Bidirectional LSTM - Hidden Markov Models (DBLSTM-HMMs) and Recurrent Neural Network - Transducers (RNN-Ts). Using a 4-bit integer representation, a na\"ive quantization approach applied to the LSTM portion of these models results in significant Word Error Rate (WER) degradation. On the other hand, we show that minimal accuracy loss is achievable with an appropriate choice of quantizers and initializations. In particular, we customize quantization schemes depending on the local properties of the network, improving recognition performance while limiting computational time. We demonstrate our solution on the Switchboard (SWB) and CallHome (CH) test sets of the NIST Hub5-2000 evaluation. DBLSTM-HMMs trained with 300 or 2000 hours of SWB data achieves $<$0.5% and $<$1% average WER degradation, respectively. On the more challenging RNN-T models, our quantization strategy limits degradation in 4-bit inference to 1.3%.
Reducing Exposure Bias in Training Recurrent Neural Network Transducers
Aug 24, 2021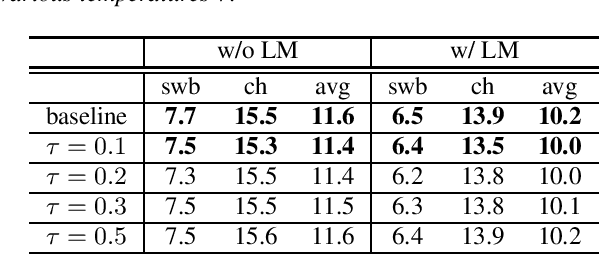
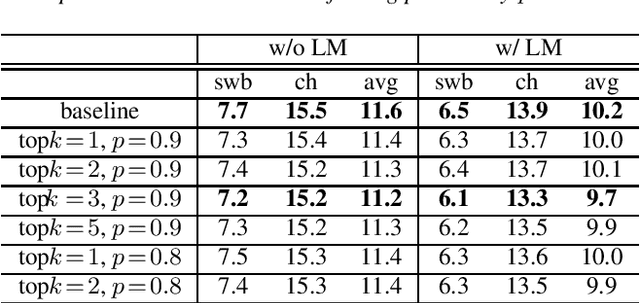
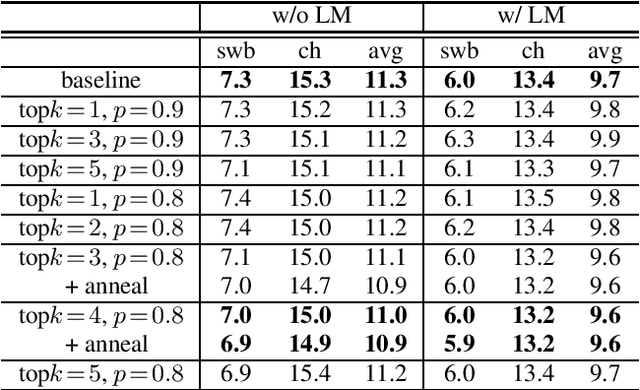
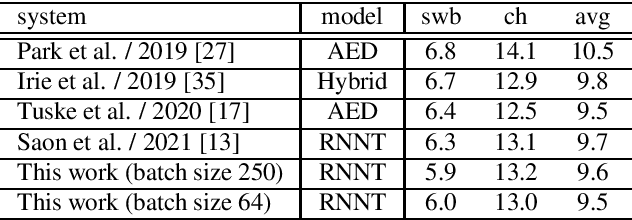
When recurrent neural network transducers (RNNTs) are trained using the typical maximum likelihood criterion, the prediction network is trained only on ground truth label sequences. This leads to a mismatch during inference, known as exposure bias, when the model must deal with label sequences containing errors. In this paper we investigate approaches to reducing exposure bias in training to improve the generalization of RNNT models for automatic speech recognition (ASR). A label-preserving input perturbation to the prediction network is introduced. The input token sequences are perturbed using SwitchOut and scheduled sampling based on an additional token language model. Experiments conducted on the 300-hour Switchboard dataset demonstrate their effectiveness. By reducing the exposure bias, we show that we can further improve the accuracy of a high-performance RNNT ASR model and obtain state-of-the-art results on the 300-hour Switchboard dataset.
Integrating Dialog History into End-to-End Spoken Language Understanding Systems
Aug 18, 2021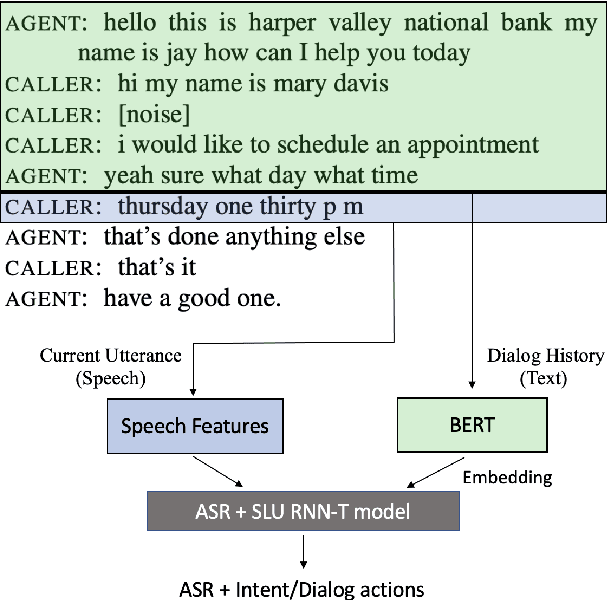

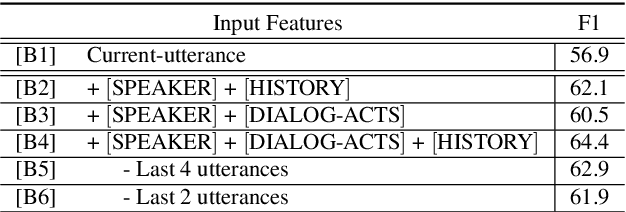
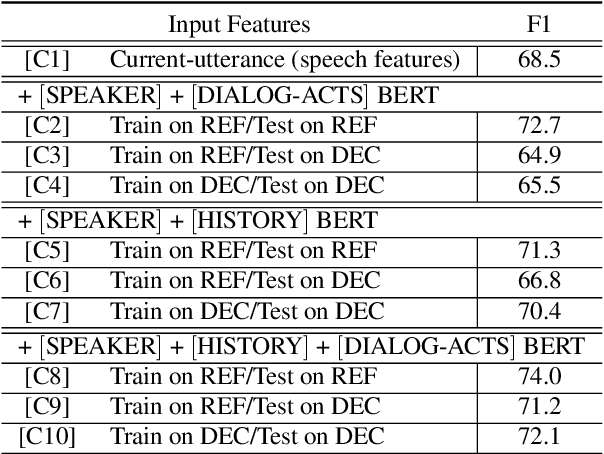
End-to-end spoken language understanding (SLU) systems that process human-human or human-computer interactions are often context independent and process each turn of a conversation independently. Spoken conversations on the other hand, are very much context dependent, and dialog history contains useful information that can improve the processing of each conversational turn. In this paper, we investigate the importance of dialog history and how it can be effectively integrated into end-to-end SLU systems. While processing a spoken utterance, our proposed RNN transducer (RNN-T) based SLU model has access to its dialog history in the form of decoded transcripts and SLU labels of previous turns. We encode the dialog history as BERT embeddings, and use them as an additional input to the SLU model along with the speech features for the current utterance. We evaluate our approach on a recently released spoken dialog data set, the HarperValleyBank corpus. We observe significant improvements: 8% for dialog action and 30% for caller intent recognition tasks, in comparison to a competitive context independent end-to-end baseline system.
On the limit of English conversational speech recognition
May 03, 2021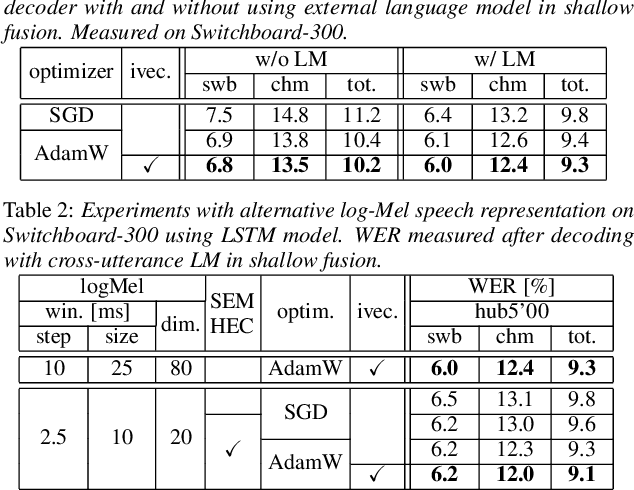
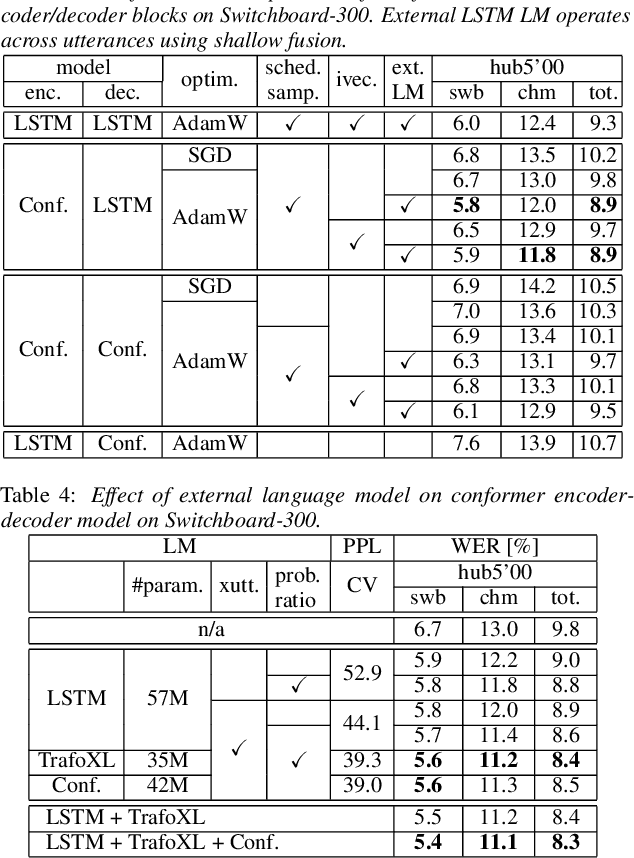
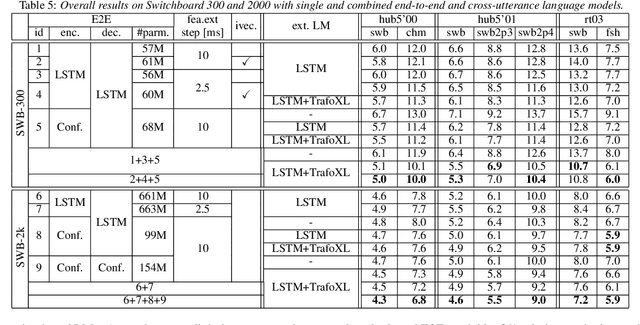
In our previous work we demonstrated that a single headed attention encoder-decoder model is able to reach state-of-the-art results in conversational speech recognition. In this paper, we further improve the results for both Switchboard 300 and 2000. Through use of an improved optimizer, speaker vector embeddings, and alternative speech representations we reduce the recognition errors of our LSTM system on Switchboard-300 by 4% relative. Compensation of the decoder model with the probability ratio approach allows more efficient integration of an external language model, and we report 5.9% and 11.5% WER on the SWB and CHM parts of Hub5'00 with very simple LSTM models. Our study also considers the recently proposed conformer, and more advanced self-attention based language models. Overall, the conformer shows similar performance to the LSTM; nevertheless, their combination and decoding with an improved LM reaches a new record on Switchboard-300, 5.0% and 10.0% WER on SWB and CHM. Our findings are also confirmed on Switchboard-2000, and a new state of the art is reported, practically reaching the limit of the benchmark.
RNN Transducer Models For Spoken Language Understanding
Apr 08, 2021
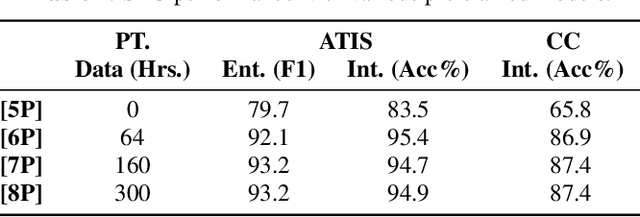


We present a comprehensive study on building and adapting RNN transducer (RNN-T) models for spoken language understanding(SLU). These end-to-end (E2E) models are constructed in three practical settings: a case where verbatim transcripts are available, a constrained case where the only available annotations are SLU labels and their values, and a more restrictive case where transcripts are available but not corresponding audio. We show how RNN-T SLU models can be developed starting from pre-trained automatic speech recognition (ASR) systems, followed by an SLU adaptation step. In settings where real audio data is not available, artificially synthesized speech is used to successfully adapt various SLU models. When evaluated on two SLU data sets, the ATIS corpus and a customer call center data set, the proposed models closely track the performance of other E2E models and achieve state-of-the-art results.
Advancing RNN Transducer Technology for Speech Recognition
Mar 17, 2021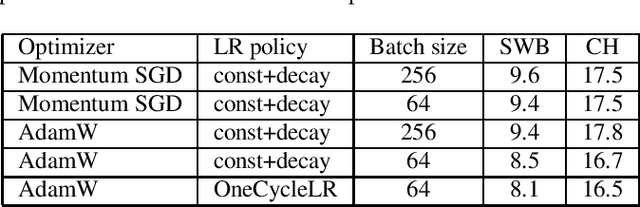
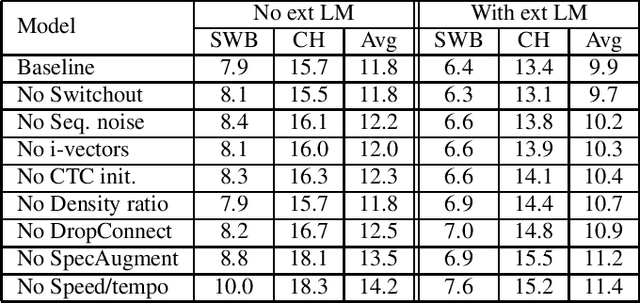
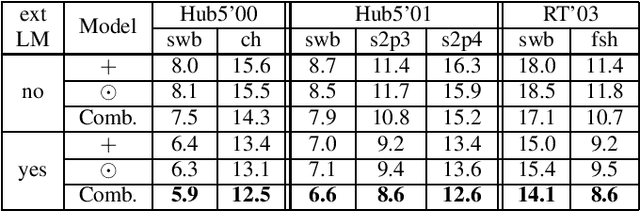
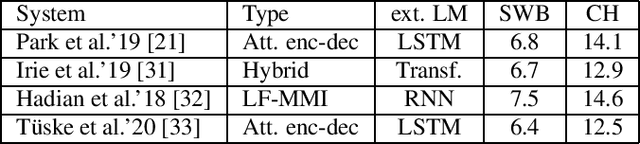
We investigate a set of techniques for RNN Transducers (RNN-Ts) that were instrumental in lowering the word error rate on three different tasks (Switchboard 300 hours, conversational Spanish 780 hours and conversational Italian 900 hours). The techniques pertain to architectural changes, speaker adaptation, language model fusion, model combination and general training recipe. First, we introduce a novel multiplicative integration of the encoder and prediction network vectors in the joint network (as opposed to additive). Second, we discuss the applicability of i-vector speaker adaptation to RNN-Ts in conjunction with data perturbation. Third, we explore the effectiveness of the recently proposed density ratio language model fusion for these tasks. Last but not least, we describe the other components of our training recipe and their effect on recognition performance. We report a 5.9% and 12.5% word error rate on the Switchboard and CallHome test sets of the NIST Hub5 2000 evaluation and a 12.7% WER on the Mozilla CommonVoice Italian test set.
Distributed Training of Deep Neural Network Acoustic Models for Automatic Speech Recognition
Feb 24, 2020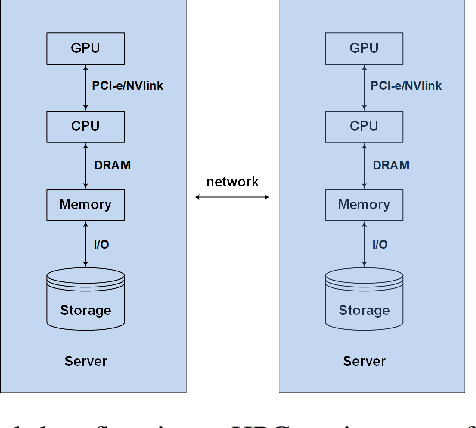
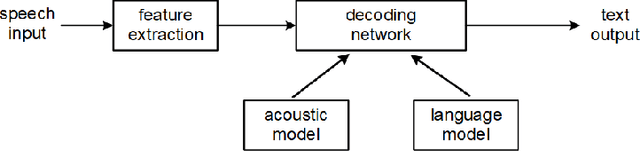
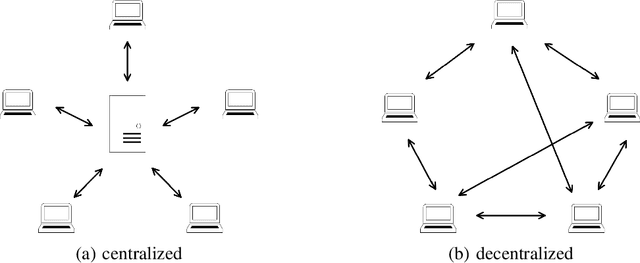
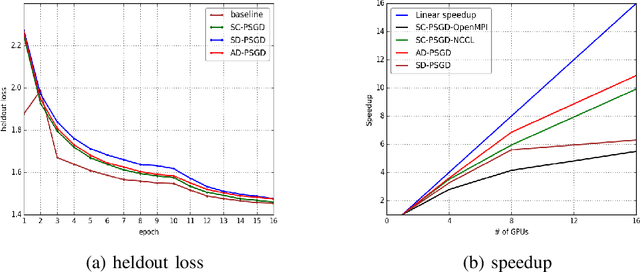
The past decade has witnessed great progress in Automatic Speech Recognition (ASR) due to advances in deep learning. The improvements in performance can be attributed to both improved models and large-scale training data. Key to training such models is the employment of efficient distributed learning techniques. In this article, we provide an overview of distributed training techniques for deep neural network acoustic models for ASR. Starting with the fundamentals of data parallel stochastic gradient descent (SGD) and ASR acoustic modeling, we will investigate various distributed training strategies and their realizations in high performance computing (HPC) environments with an emphasis on striking the balance between communication and computation. Experiments are carried out on a popular public benchmark to study the convergence, speedup and recognition performance of the investigated strategies.
Improving Efficiency in Large-Scale Decentralized Distributed Training
Feb 04, 2020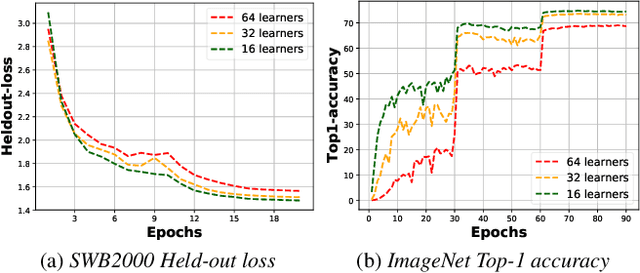
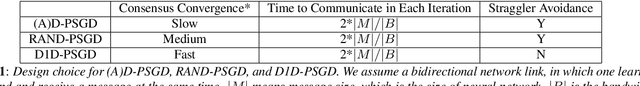
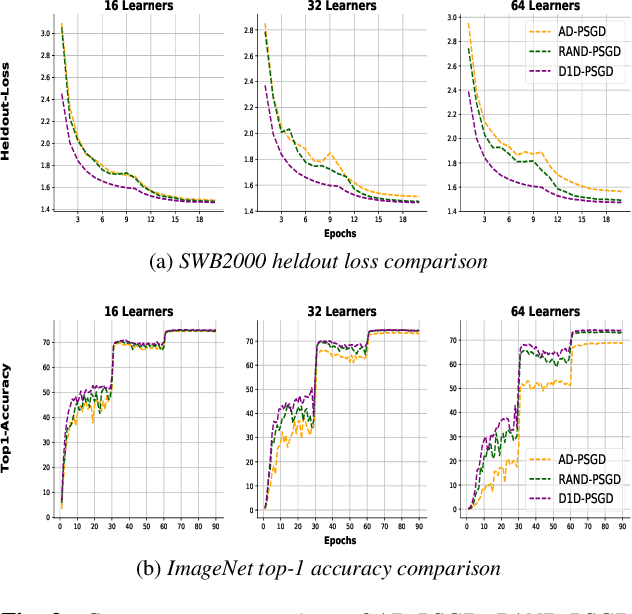

Decentralized Parallel SGD (D-PSGD) and its asynchronous variant Asynchronous Parallel SGD (AD-PSGD) is a family of distributed learning algorithms that have been demonstrated to perform well for large-scale deep learning tasks. One drawback of (A)D-PSGD is that the spectral gap of the mixing matrix decreases when the number of learners in the system increases, which hampers convergence. In this paper, we investigate techniques to accelerate (A)D-PSGD based training by improving the spectral gap while minimizing the communication cost. We demonstrate the effectiveness of our proposed techniques by running experiments on the 2000-hour Switchboard speech recognition task and the ImageNet computer vision task. On an IBM P9 supercomputer, our system is able to train an LSTM acoustic model in 2.28 hours with 7.5% WER on the Hub5-2000 Switchboard (SWB) test set and 13.3% WER on the CallHome (CH) test set using 64 V100 GPUs and in 1.98 hours with 7.7% WER on SWB and 13.3% WER on CH using 128 V100 GPUs, the fastest training time reported to date.
Single headed attention based sequence-to-sequence model for state-of-the-art results on Switchboard-300
Jan 20, 2020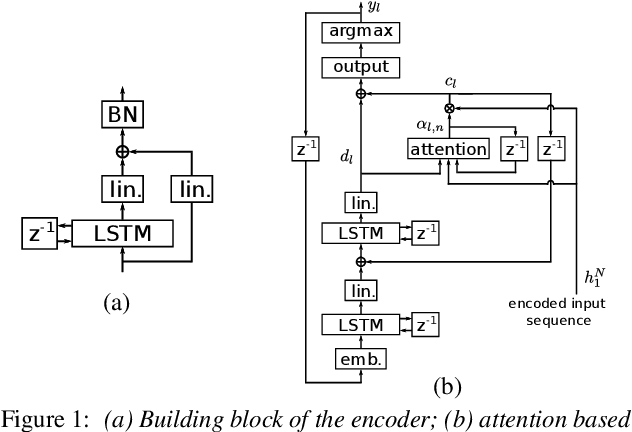
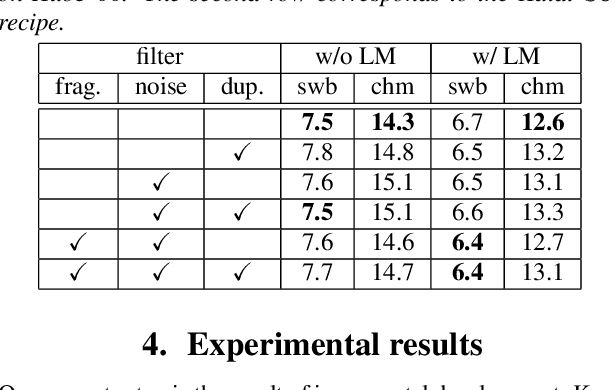
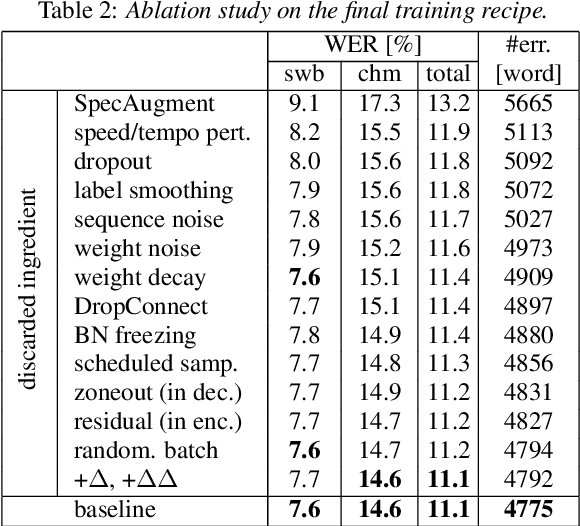
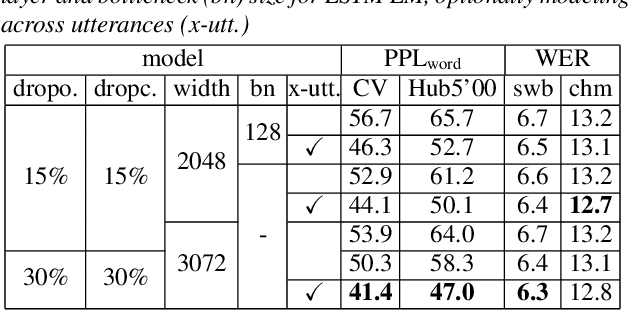
It is generally believed that direct sequence-to-sequence (seq2seq) speech recognition models are competitive with hybrid models only when a large amount of data, at least a thousand hours, is available for training. In this paper, we show that state-of-the-art recognition performance can be achieved on the Switchboard-300 database using a single headed attention, LSTM based model. Using a cross-utterance language model, our single-pass speaker independent system reaches 6.4% and 12.5% word error rate (WER) on the Switchboard and CallHome subsets of Hub5'00, without a pronunciation lexicon. While careful regularization and data augmentation are crucial in achieving this level of performance, experiments on Switchboard-2000 show that nothing is more useful than more data.
Challenging the Boundaries of Speech Recognition: The MALACH Corpus
Aug 09, 2019
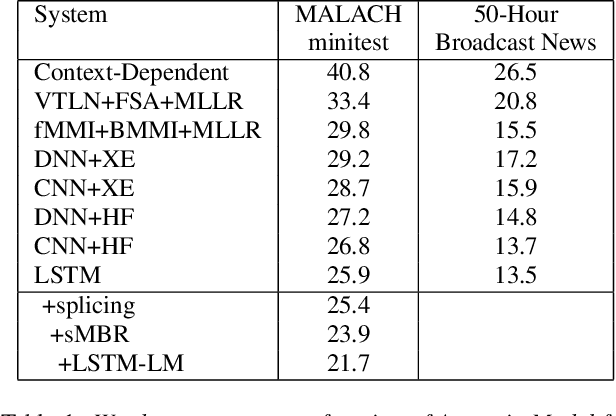
There has been huge progress in speech recognition over the last several years. Tasks once thought extremely difficult, such as SWITCHBOARD, now approach levels of human performance. The MALACH corpus (LDC catalog LDC2012S05), a 375-Hour subset of a large archive of Holocaust testimonies collected by the Survivors of the Shoah Visual History Foundation, presents significant challenges to the speech community. The collection consists of unconstrained, natural speech filled with disfluencies, heavy accents, age-related coarticulations, un-cued speaker and language switching, and emotional speech - all still open problems for speech recognition systems. Transcription is challenging even for skilled human annotators. This paper proposes that the community place focus on the MALACH corpus to develop speech recognition systems that are more robust with respect to accents, disfluencies and emotional speech. To reduce the barrier for entry, a lexicon and training and testing setups have been created and baseline results using current deep learning technologies are presented. The metadata has just been released by LDC (LDC2019S11). It is hoped that this resource will enable the community to build on top of these baselines so that the extremely important information in these and related oral histories becomes accessible to a wider audience.