 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExperts, Errors, and Context: A Large-Scale Study of Human Evaluation for Machine Translation
Apr 29, 2021

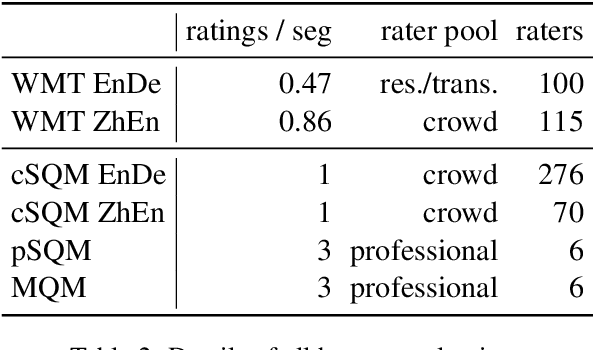

Human evaluation of modern high-quality machine translation systems is a difficult problem, and there is increasing evidence that inadequate evaluation procedures can lead to erroneous conclusions. While there has been considerable research on human evaluation, the field still lacks a commonly-accepted standard procedure. As a step toward this goal, we propose an evaluation methodology grounded in explicit error analysis, based on the Multidimensional Quality Metrics (MQM) framework. We carry out the largest MQM research study to date, scoring the outputs of top systems from the WMT 2020 shared task in two language pairs using annotations provided by professional translators with access to full document context. We analyze the resulting data extensively, finding among other results a substantially different ranking of evaluated systems from the one established by the WMT crowd workers, exhibiting a clear preference for human over machine output. Surprisingly, we also find that automatic metrics based on pre-trained embeddings can outperform human crowd workers. We make our corpus publicly available for further research.
Assessing Reference-Free Peer Evaluation for Machine Translation
Apr 12, 2021
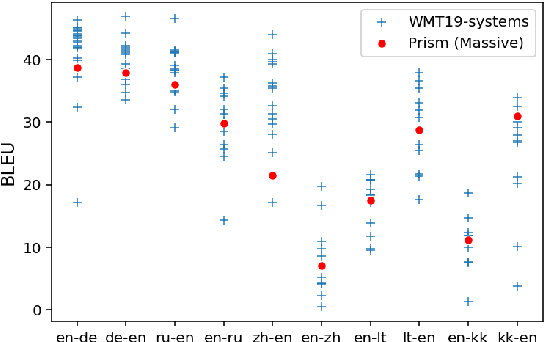
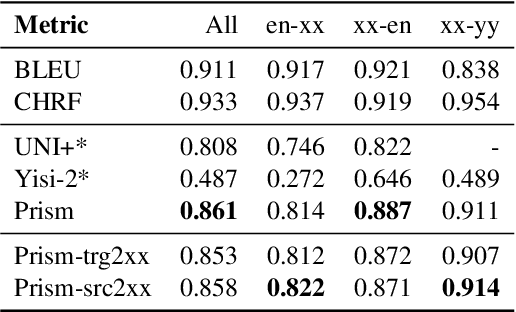
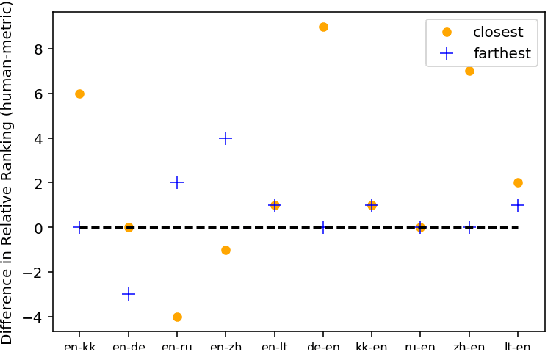
Reference-free evaluation has the potential to make machine translation evaluation substantially more scalable, allowing us to pivot easily to new languages or domains. It has been recently shown that the probabilities given by a large, multilingual model can achieve state of the art results when used as a reference-free metric. We experiment with various modifications to this model and demonstrate that by scaling it up we can match the performance of BLEU. We analyze various potential weaknesses of the approach and find that it is surprisingly robust and likely to offer reasonable performance across a broad spectrum of domains and different system qualities.
Inference Strategies for Machine Translation with Conditional Masking
Oct 20, 2020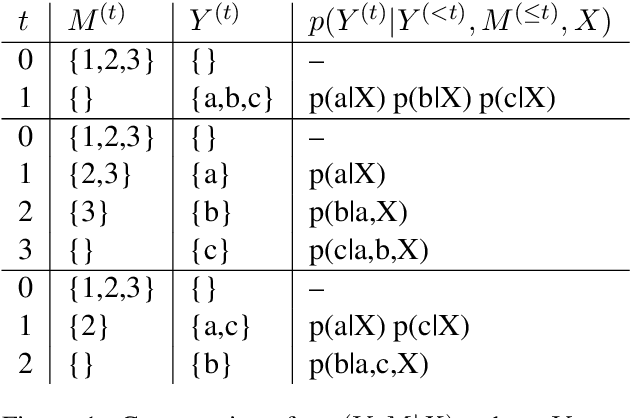
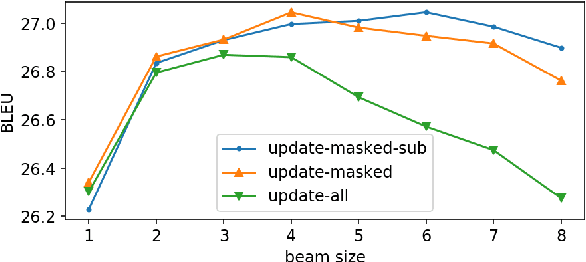
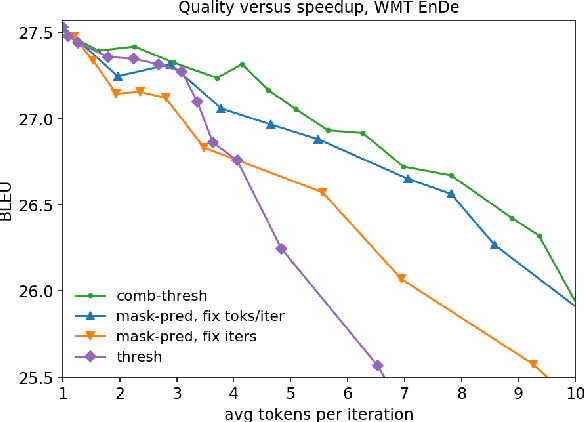
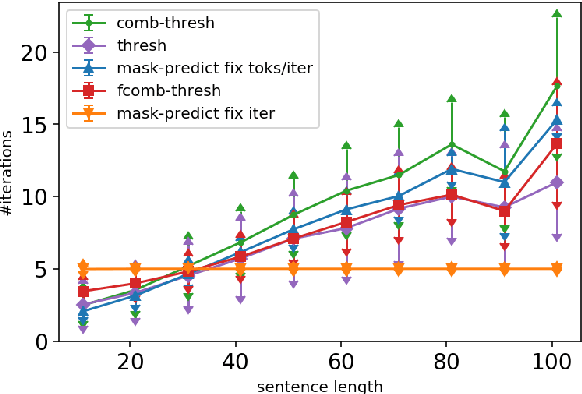
Conditional masked language model (CMLM) training has proven successful for non-autoregressive and semi-autoregressive sequence generation tasks, such as machine translation. Given a trained CMLM, however, it is not clear what the best inference strategy is. We formulate masked inference as a factorization of conditional probabilities of partial sequences, show that this does not harm performance, and investigate a number of simple heuristics motivated by this perspective. We identify a thresholding strategy that has advantages over the standard "mask-predict" algorithm, and provide analyses of its behavior on machine translation tasks.
Human-Paraphrased References Improve Neural Machine Translation
Oct 20, 2020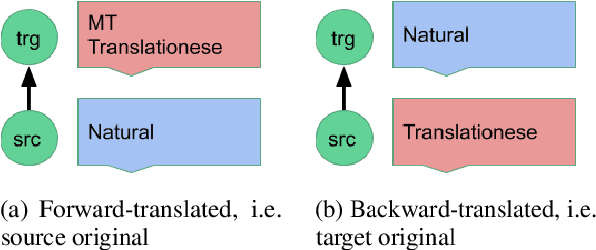
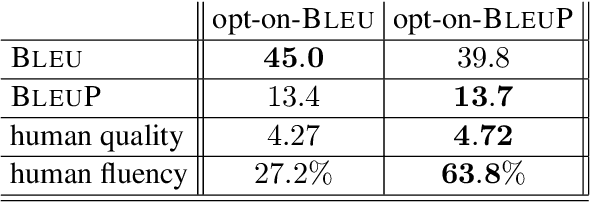
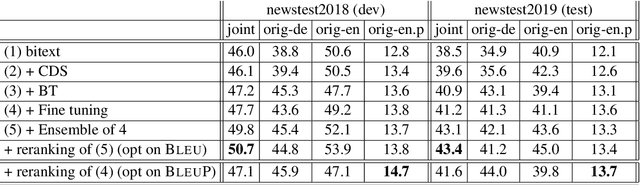
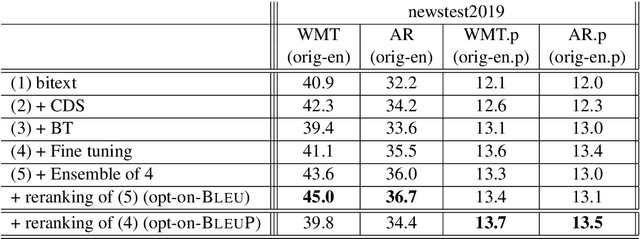
Automatic evaluation comparing candidate translations to human-generated paraphrases of reference translations has recently been proposed by Freitag et al. When used in place of original references, the paraphrased versions produce metric scores that correlate better with human judgment. This effect holds for a variety of different automatic metrics, and tends to favor natural formulations over more literal (translationese) ones. In this paper we compare the results of performing end-to-end system development using standard and paraphrased references. With state-of-the-art English-German NMT components, we show that tuning to paraphrased references produces a system that is significantly better according to human judgment, but 5 BLEU points worse when tested on standard references. Our work confirms the finding that paraphrased references yield metric scores that correlate better with human judgment, and demonstrates for the first time that using these scores for system development can lead to significant improvements.
Re-translation versus Streaming for Simultaneous Translation
Apr 14, 2020
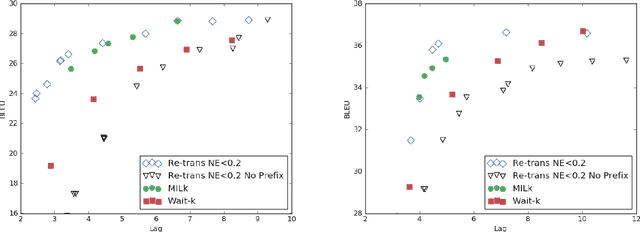

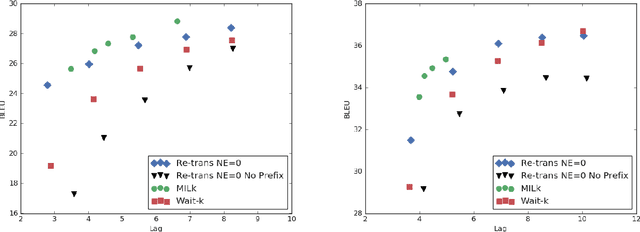
There has been great progress in improving streaming machine translation, a simultaneous paradigm where the system appends to a growing hypothesis as more source content becomes available. We study a related problem in which revisions to the hypothesis beyond strictly appending words are permitted. This is suitable for applications such as live captioning an audio feed. In this setting, we compare custom streaming approaches to re-translation, a straightforward strategy where each new source token triggers a distinct translation from scratch. We find re-translation to be as good or better than state-of-the-art streaming systems, even when operating under constraints that allow very few revisions. We attribute much of this success to a previously proposed data-augmentation technique that adds prefix-pairs to the training data, which alongside wait-k inference forms a strong baseline for streaming translation. We also highlight re-translation's ability to wrap arbitrarily powerful MT systems with an experiment showing large improvements from an upgrade to its base model.
Re-Translation Strategies For Long Form, Simultaneous, Spoken Language Translation
Dec 06, 2019
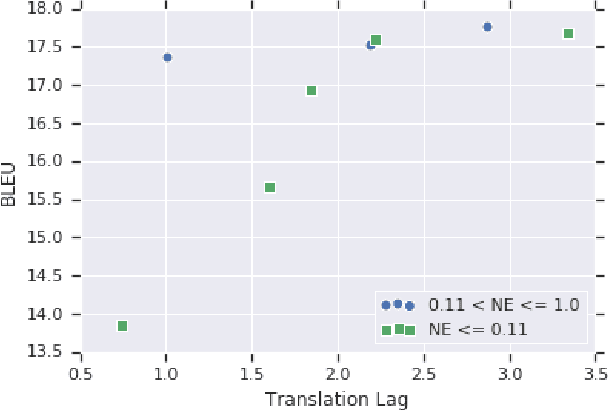
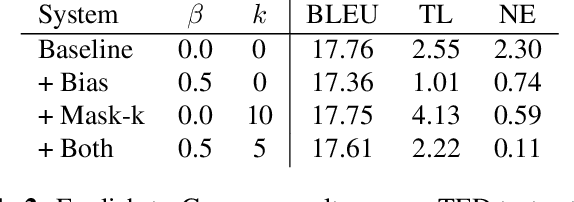
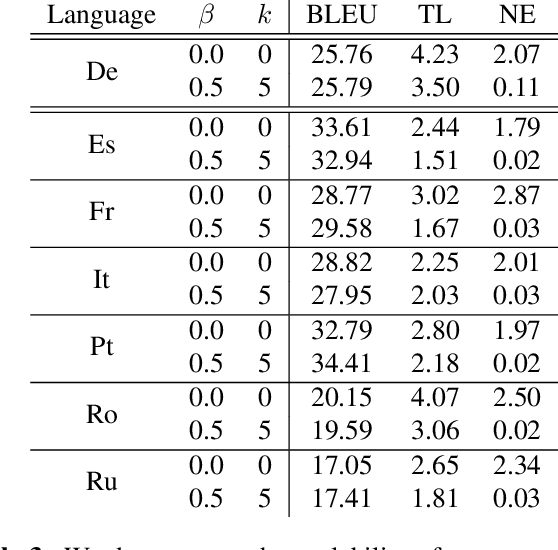
We investigate the problem of simultaneous machine translation of long-form speech content. We target a continuous speech-to-text scenario, generating translated captions for a live audio feed, such as a lecture or play-by-play commentary. As this scenario allows for revisions to our incremental translations, we adopt a re-translation approach to simultaneous translation, where the source is repeatedly translated from scratch as it grows. This approach naturally exhibits very low latency and high final quality, but at the cost of incremental instability as the output is continuously refined. We experiment with a pipeline of industry-grade speech recognition and translation tools, augmented with simple inference heuristics to improve stability. We use TED Talks as a source of multilingual test data, developing our techniques on English-to-German spoken language translation. Our minimalist approach to simultaneous translation allows us to easily scale our final evaluation to six more target languages, dramatically improving incremental stability for all of them.
Massively Multilingual Neural Machine Translation in the Wild: Findings and Challenges
Jul 11, 2019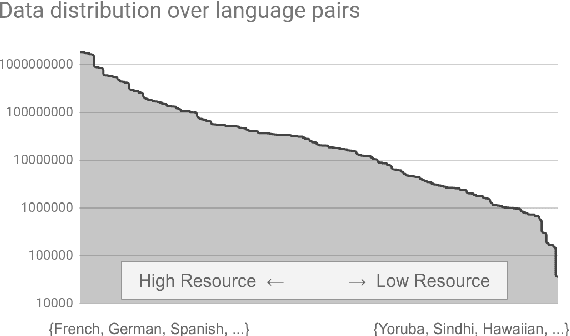
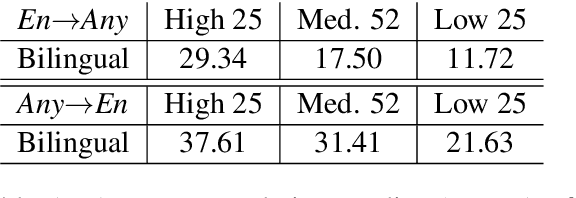
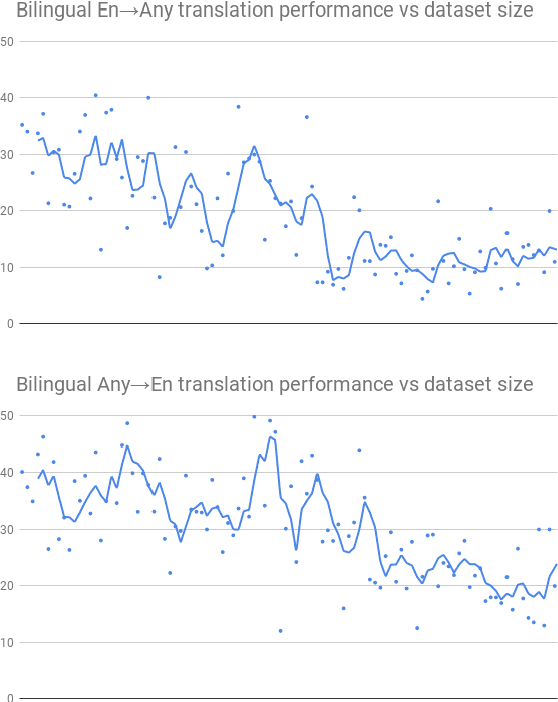
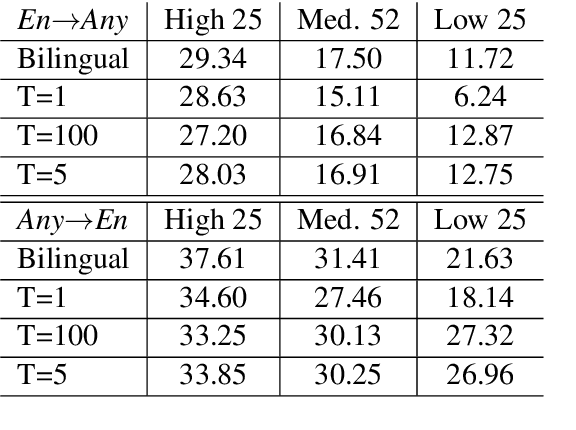
We introduce our efforts towards building a universal neural machine translation (NMT) system capable of translating between any language pair. We set a milestone towards this goal by building a single massively multilingual NMT model handling 103 languages trained on over 25 billion examples. Our system demonstrates effective transfer learning ability, significantly improving translation quality of low-resource languages, while keeping high-resource language translation quality on-par with competitive bilingual baselines. We provide in-depth analysis of various aspects of model building that are crucial to achieving quality and practicality in universal NMT. While we prototype a high-quality universal translation system, our extensive empirical analysis exposes issues that need to be further addressed, and we suggest directions for future research.
Thinking Slow about Latency Evaluation for Simultaneous Machine Translation
May 31, 2019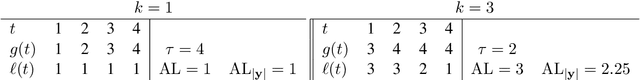
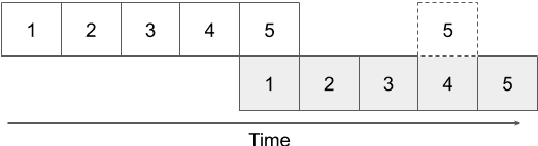
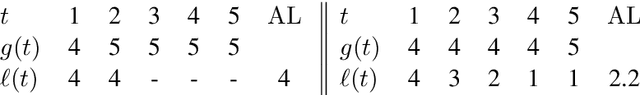
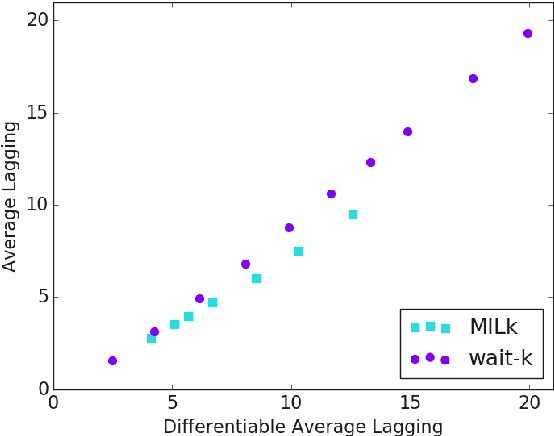
Simultaneous machine translation attempts to translate a source sentence before it is finished being spoken, with applications to translation of spoken language for live streaming and conversation. Since simultaneous systems trade quality to reduce latency, having an effective and interpretable latency metric is crucial. We introduce a variant of the recently proposed Average Lagging (AL) metric, which we call Differentiable Average Lagging (DAL). It distinguishes itself by being differentiable and internally consistent to its underlying mathematical model.
Reinforcement Learning based Curriculum Optimization for Neural Machine Translation
Feb 28, 2019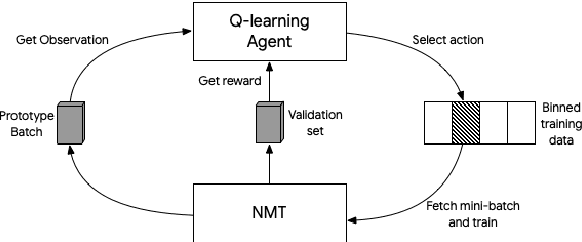
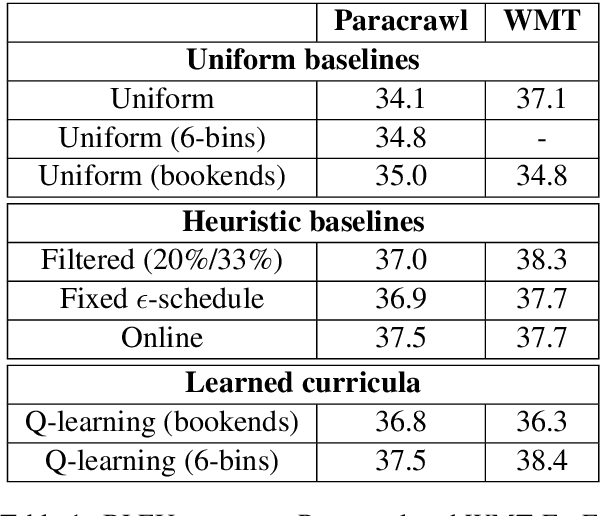
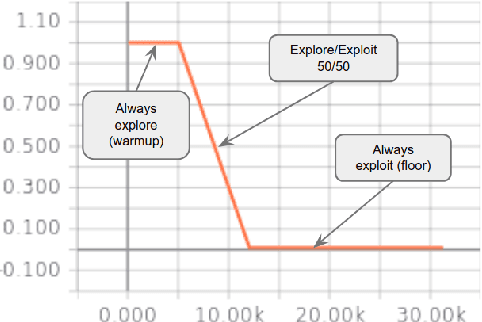
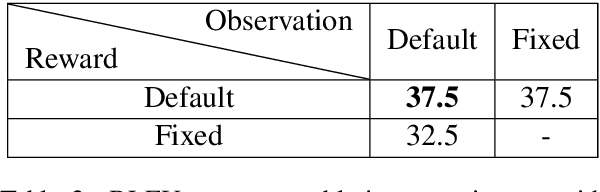
We consider the problem of making efficient use of heterogeneous training data in neural machine translation (NMT). Specifically, given a training dataset with a sentence-level feature such as noise, we seek an optimal curriculum, or order for presenting examples to the system during training. Our curriculum framework allows examples to appear an arbitrary number of times, and thus generalizes data weighting, filtering, and fine-tuning schemes. Rather than relying on prior knowledge to design a curriculum, we use reinforcement learning to learn one automatically, jointly with the NMT system, in the course of a single training run. We show that this approach can beat uniform and filtering baselines on Paracrawl and WMT English-to-French datasets by up to +3.4 BLEU, and match the performance of a hand-designed, state-of-the-art curriculum.
Lingvo: a Modular and Scalable Framework for Sequence-to-Sequence Modeling
Feb 21, 2019


Lingvo is a Tensorflow framework offering a complete solution for collaborative deep learning research, with a particular focus towards sequence-to-sequence models. Lingvo models are composed of modular building blocks that are flexible and easily extensible, and experiment configurations are centralized and highly customizable. Distributed training and quantized inference are supported directly within the framework, and it contains existing implementations of a large number of utilities, helper functions, and the newest research ideas. Lingvo has been used in collaboration by dozens of researchers in more than 20 papers over the last two years. This document outlines the underlying design of Lingvo and serves as an introduction to the various pieces of the framework, while also offering examples of advanced features that showcase the capabilities of the framework.