 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Graph Neural Networks on Real Processing-In-Memory Systems
Feb 26, 2024



Graph Neural Networks (GNNs) are emerging ML models to analyze graph-structure data. Graph Neural Network (GNN) execution involves both compute-intensive and memory-intensive kernels, the latter dominates the total time, being significantly bottlenecked by data movement between memory and processors. Processing-In-Memory (PIM) systems can alleviate this data movement bottleneck by placing simple processors near or inside to memory arrays. In this work, we introduce PyGim, an efficient ML framework that accelerates GNNs on real PIM systems. We propose intelligent parallelization techniques for memory-intensive kernels of GNNs tailored for real PIM systems, and develop handy Python API for them. We provide hybrid GNN execution, in which the compute-intensive and memory-intensive kernels are executed in processor-centric and memory-centric computing systems, respectively, to match their algorithmic nature. We extensively evaluate PyGim on a real-world PIM system with 1992 PIM cores using emerging GNN models, and demonstrate that it outperforms its state-of-the-art CPU counterpart on Intel Xeon by on average 3.04x, and achieves higher resource utilization than CPU and GPU systems. Our work provides useful recommendations for software, system and hardware designers. PyGim will be open-sourced to enable the widespread use of PIM systems in GNNs.
The Synergy of Speculative Decoding and Batching in Serving Large Language Models
Oct 28, 2023



Large Language Models (LLMs) like GPT are state-of-the-art text generation models that provide significant assistance in daily routines. However, LLM execution is inherently sequential, since they only produce one token at a time, thus incurring low hardware utilization on modern GPUs. Batching and speculative decoding are two techniques to improve GPU hardware utilization in LLM inference. To study their synergy, we implement a prototype implementation and perform an extensive characterization analysis on various LLM models and GPU architectures. We observe that the optimal speculation length depends on the batch size used. We analyze the key observation and build a quantitative model to explain it. Based on our analysis, we propose a new adaptive speculative decoding strategy that chooses the optimal speculation length for different batch sizes. Our evaluations show that our proposed method can achieve equal or better performance than the state-of-the-art speculation decoding schemes with fixed speculation length.
Speeding up Fourier Neural Operators via Mixed Precision
Jul 27, 2023



The Fourier neural operator (FNO) is a powerful technique for learning surrogate maps for partial differential equation (PDE) solution operators. For many real-world applications, which often require high-resolution data points, training time and memory usage are significant bottlenecks. While there are mixed-precision training techniques for standard neural networks, those work for real-valued datatypes on finite dimensions and therefore cannot be directly applied to FNO, which crucially operates in the (complex-valued) Fourier domain and in function spaces. On the other hand, since the Fourier transform is already an approximation (due to discretization error), we do not need to perform the operation at full precision. In this work, we (i) profile memory and runtime for FNO with full and mixed-precision training, (ii) conduct a study on the numerical stability of mixed-precision training of FNO, and (iii) devise a training routine which substantially decreases training time and memory usage (up to 34%), with little or no reduction in accuracy, on the Navier-Stokes and Darcy flow equations. Combined with the recently proposed tensorized FNO (Kossaifi et al., 2023), the resulting model has far better performance while also being significantly faster than the original FNO.
Tempo: Accelerating Transformer-Based Model Training through Memory Footprint Reduction
Oct 19, 2022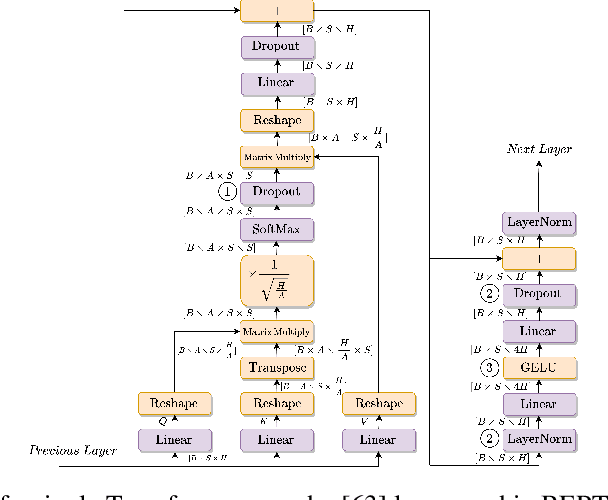


Training deep learning models can be computationally expensive. Prior works have shown that increasing the batch size can potentially lead to better overall throughput. However, the batch size is frequently limited by the accelerator memory capacity due to the activations/feature maps stored for the training backward pass, as larger batch sizes require larger feature maps to be stored. Transformer-based models, which have recently seen a surge in popularity due to their good performance and applicability to a variety of tasks, have a similar problem. To remedy this issue, we propose Tempo, a new approach to efficiently use accelerator (e.g., GPU) memory resources for training Transformer-based models. Our approach provides drop-in replacements for the GELU, LayerNorm, and Attention layers, reducing the memory usage and ultimately leading to more efficient training. We implement Tempo and evaluate the throughput, memory usage, and accuracy/loss on the BERT Large pre-training task. We demonstrate that Tempo enables up to 2x higher batch sizes and 16% higher training throughput over the state-of-the-art baseline. We also evaluate Tempo on GPT2 and RoBERTa models, showing 19% and 26% speedup over the baseline.
Hidet: Task Mapping Programming Paradigm for Deep Learning Tensor Programs
Oct 18, 2022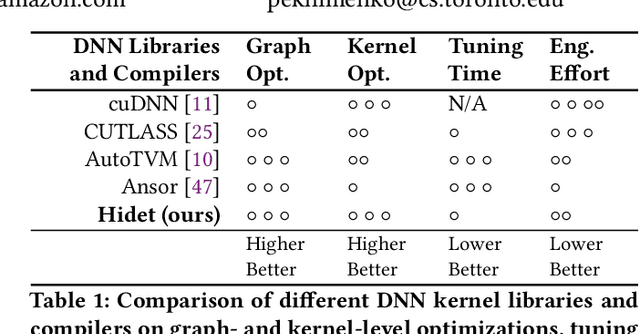
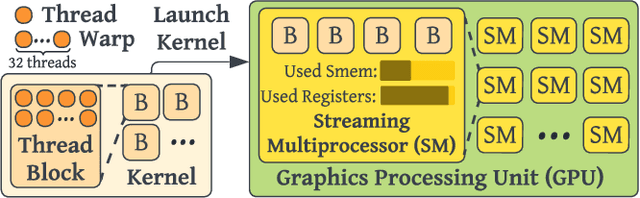

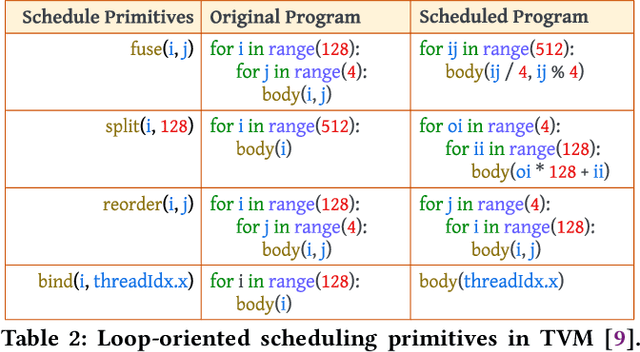
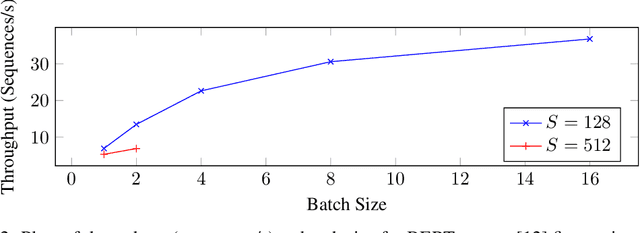
As deep learning models nowadays are widely adopted by both cloud services and edge devices, the latency of deep learning model inferences becomes crucial to provide efficient model serving. However, it is challenging to develop efficient tensor programs for deep learning operators due to the high complexity of modern accelerators (e.g., NVIDIA GPUs and Google TPUs) and the rapidly growing number of operators. Deep learning compilers, such as Apache TVM, adopt declarative scheduling primitives to lower the bar of developing tensor programs. However, we show that this approach is insufficient to cover state-of-the-art tensor program optimizations (e.g., double buffering). In this paper, we propose to embed the scheduling process into tensor programs and use dedicated mappings, called task mappings, to define the computation assignment and ordering directly in the tensor programs. This new approach greatly enriches the expressible optimizations by allowing developers to manipulate tensor programs at a much finer granularity (e.g., allowing program statement-level optimizations). We call the proposed method the task-mapping-oriented programming paradigm. With the proposed paradigm, we implement a deep learning compiler - Hidet. Extensive experiments on modern convolution and transformer models show that Hidet outperforms state-of-the-art DNN inference framework, ONNX Runtime, and compiler, TVM equipped with scheduler AutoTVM and Ansor, by up to 1.48x (1.22x on average) with enriched optimizations. It also reduces the tuning time by 20x and 11x compared with AutoTVM and Ansor, respectively.
Optimizing Data Collection in Deep Reinforcement Learning
Jul 15, 2022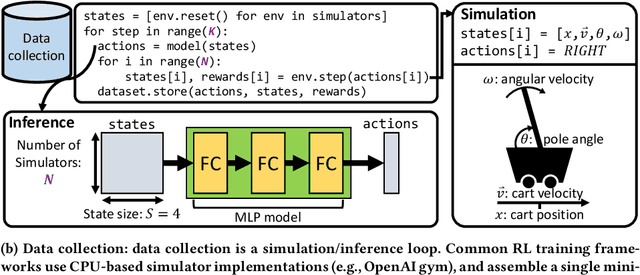
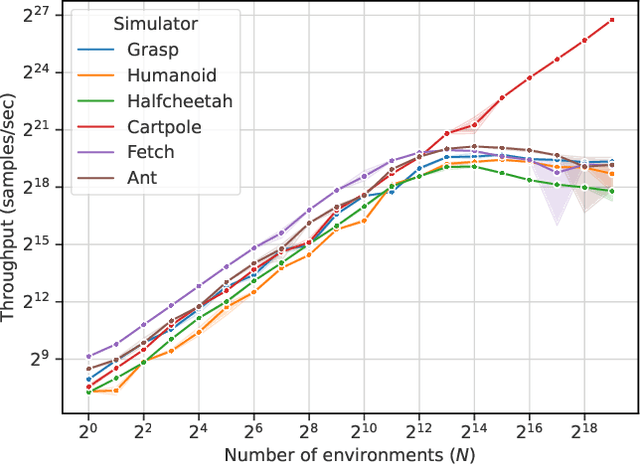
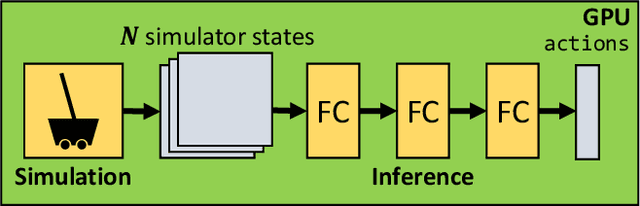
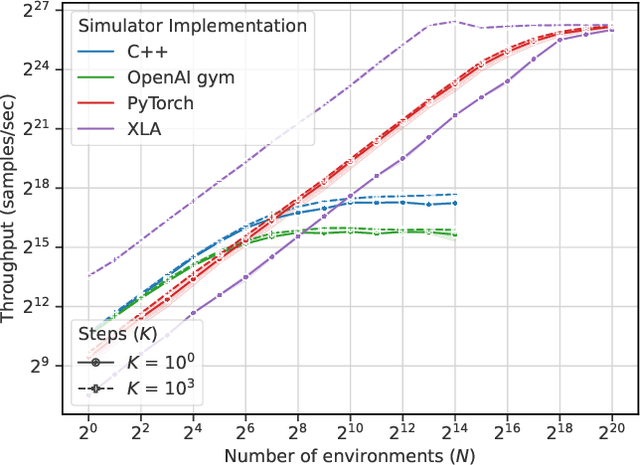
Reinforcement learning (RL) workloads take a notoriously long time to train due to the large number of samples collected at run-time from simulators. Unfortunately, cluster scale-up approaches remain expensive, and commonly used CPU implementations of simulators induce high overhead when switching back and forth between GPU computations. We explore two optimizations that increase RL data collection efficiency by increasing GPU utilization: (1) GPU vectorization: parallelizing simulation on the GPU for increased hardware parallelism, and (2) simulator kernel fusion: fusing multiple simulation steps to run in a single GPU kernel launch to reduce global memory bandwidth requirements. We find that GPU vectorization can achieve up to $1024\times$ speedup over commonly used CPU simulators. We profile the performance of different implementations and show that for a simple simulator, ML compiler implementations (XLA) of GPU vectorization outperform a DNN framework (PyTorch) by $13.4\times$ by reducing CPU overhead from repeated Python to DL backend API calls. We show that simulator kernel fusion speedups with a simple simulator are $11.3\times$ and increase by up to $1024\times$ as simulator complexity increases in terms of memory bandwidth requirements. We show that the speedups from simulator kernel fusion are orthogonal and combinable with GPU vectorization, leading to a multiplicative speedup.
MedPerf: Open Benchmarking Platform for Medical Artificial Intelligence using Federated Evaluation
Oct 08, 2021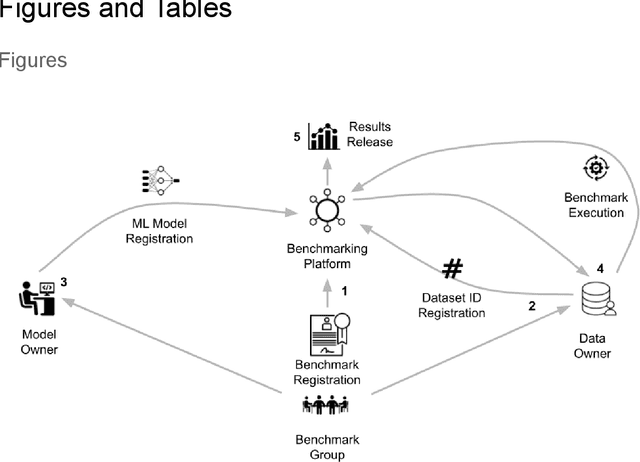
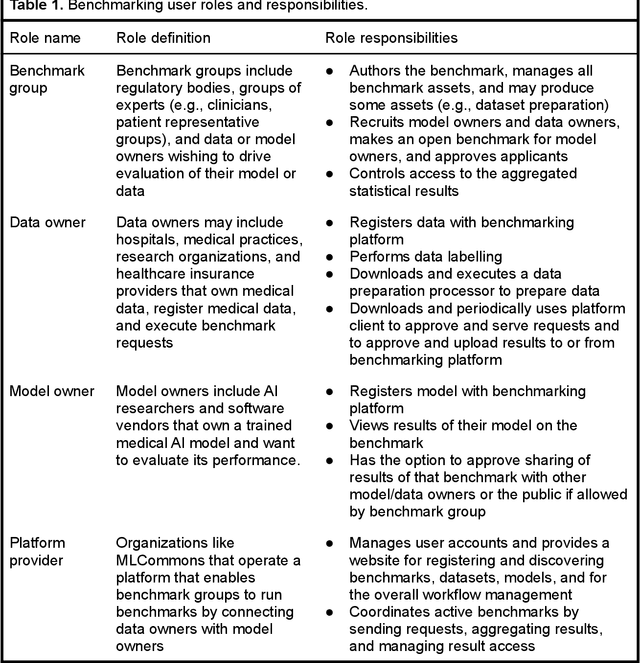
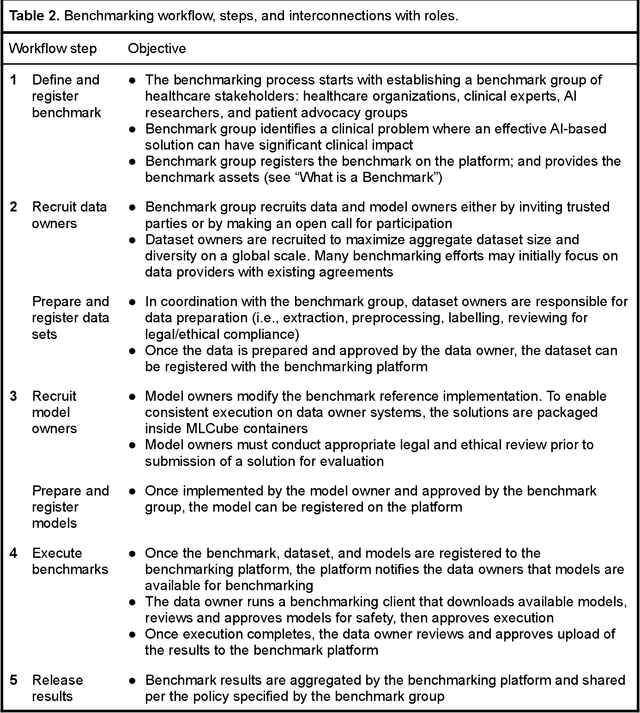
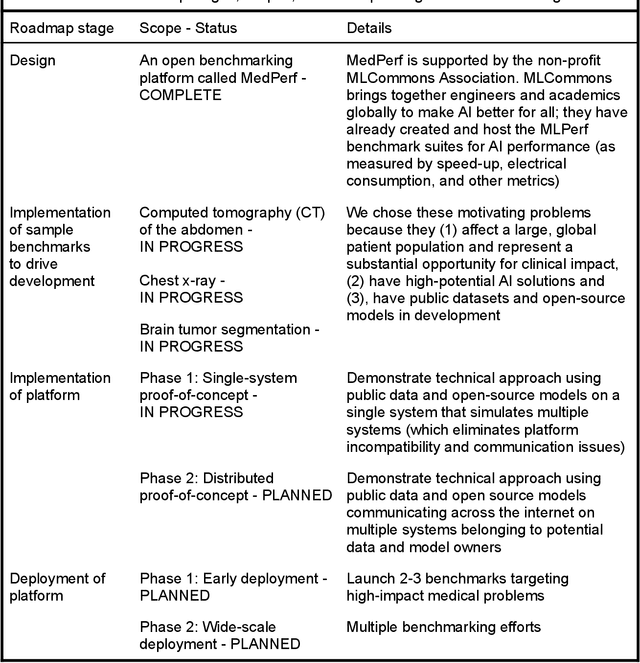
Medical AI has tremendous potential to advance healthcare by supporting the evidence-based practice of medicine, personalizing patient treatment, reducing costs, and improving provider and patient experience. We argue that unlocking this potential requires a systematic way to measure the performance of medical AI models on large-scale heterogeneous data. To meet this need, we are building MedPerf, an open framework for benchmarking machine learning in the medical domain. MedPerf will enable federated evaluation in which models are securely distributed to different facilities for evaluation, thereby empowering healthcare organizations to assess and verify the performance of AI models in an efficient and human-supervised process, while prioritizing privacy. We describe the current challenges healthcare and AI communities face, the need for an open platform, the design philosophy of MedPerf, its current implementation status, and our roadmap. We call for researchers and organizations to join us in creating the MedPerf open benchmarking platform.
Distributed Deep Learning in Open Collaborations
Jun 18, 2021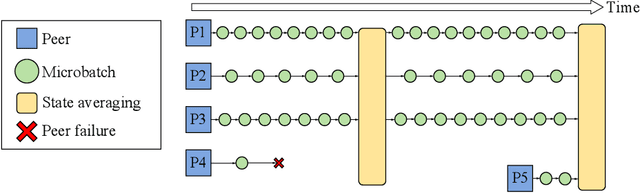
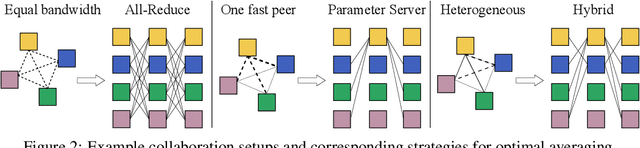
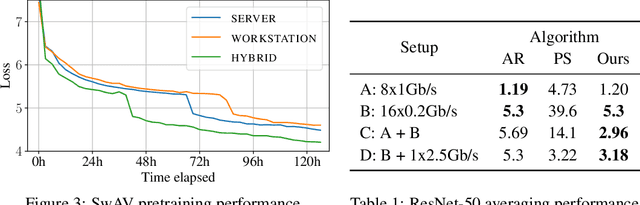

Modern deep learning applications require increasingly more compute to train state-of-the-art models. To address this demand, large corporations and institutions use dedicated High-Performance Computing clusters, whose construction and maintenance are both environmentally costly and well beyond the budget of most organizations. As a result, some research directions become the exclusive domain of a few large industrial and even fewer academic actors. To alleviate this disparity, smaller groups may pool their computational resources and run collaborative experiments that benefit all participants. This paradigm, known as grid- or volunteer computing, has seen successful applications in numerous scientific areas. However, using this approach for machine learning is difficult due to high latency, asymmetric bandwidth, and several challenges unique to volunteer computing. In this work, we carefully analyze these constraints and propose a novel algorithmic framework designed specifically for collaborative training. We demonstrate the effectiveness of our approach for SwAV and ALBERT pretraining in realistic conditions and achieve performance comparable to traditional setups at a fraction of the cost. Finally, we provide a detailed report of successful collaborative language model pretraining with 40 participants.
Moshpit SGD: Communication-Efficient Decentralized Training on Heterogeneous Unreliable Devices
Mar 04, 2021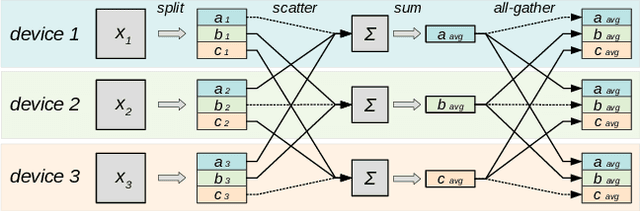
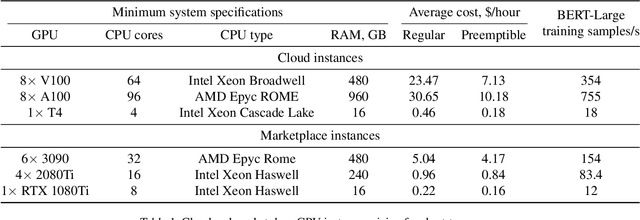
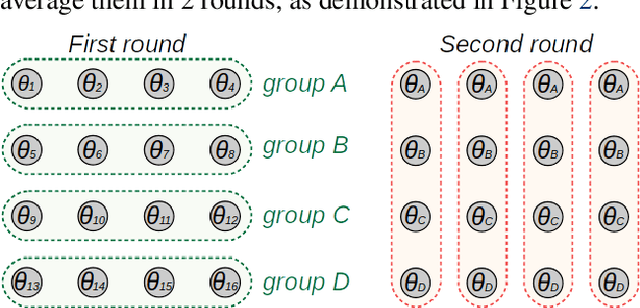
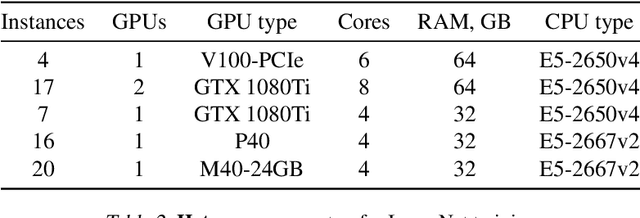
Training deep neural networks on large datasets can often be accelerated by using multiple compute nodes. This approach, known as distributed training, can utilize hundreds of computers via specialized message-passing protocols such as Ring All-Reduce. However, running these protocols at scale requires reliable high-speed networking that is only available in dedicated clusters. In contrast, many real-world applications, such as federated learning and cloud-based distributed training, operate on unreliable devices with unstable network bandwidth. As a result, these applications are restricted to using parameter servers or gossip-based averaging protocols. In this work, we lift that restriction by proposing Moshpit All-Reduce -- an iterative averaging protocol that exponentially converges to the global average. We demonstrate the efficiency of our protocol for distributed optimization with strong theoretical guarantees. The experiments show 1.3x speedup for ResNet-50 training on ImageNet compared to competitive gossip-based strategies and 1.5x speedup when training ALBERT-large from scratch using preemptible compute nodes.
RL-Scope: Cross-Stack Profiling for Deep Reinforcement Learning Workloads
Mar 04, 2021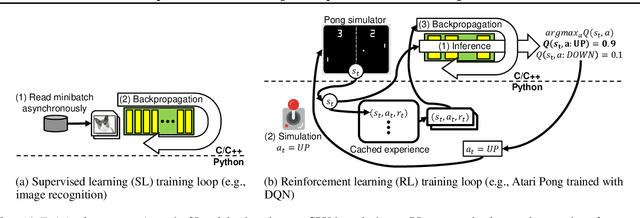


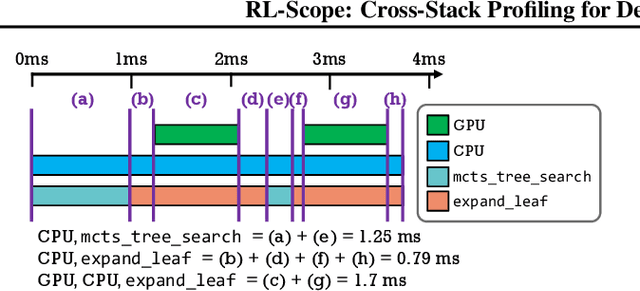
Deep reinforcement learning (RL) has made groundbreaking advancements in robotics, data center management and other applications. Unfortunately, system-level bottlenecks in RL workloads are poorly understood; we observe fundamental structural differences in RL workloads that make them inherently less GPU-bound than supervised learning (SL). To explain where training time is spent in RL workloads, we propose RL-Scope, a cross-stack profiler that scopes low-level CPU/GPU resource usage to high-level algorithmic operations, and provides accurate insights by correcting for profiling overhead. Using RL-Scope, we survey RL workloads across its major dimensions including ML backend, RL algorithm, and simulator. For ML backends, we explain a $2.3\times$ difference in runtime between equivalent PyTorch and TensorFlow algorithm implementations, and identify a bottleneck rooted in overly abstracted algorithm implementations. For RL algorithms and simulators, we show that on-policy algorithms are at least $3.5\times$ more simulation-bound than off-policy algorithms. Finally, we profile a scale-up workload and demonstrate that GPU utilization metrics reported by commonly used tools dramatically inflate GPU usage, whereas RL-Scope reports true GPU-bound time. RL-Scope is an open-source tool available at https://github.com/UofT-EcoSystem/rlscope .