 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfrastructure Node-based Vehicle Localization for Autonomous Driving
Sep 21, 2021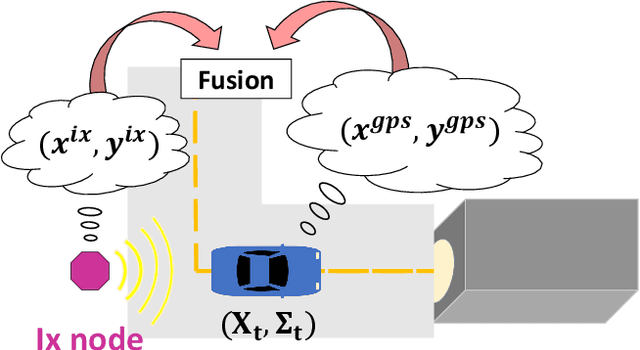

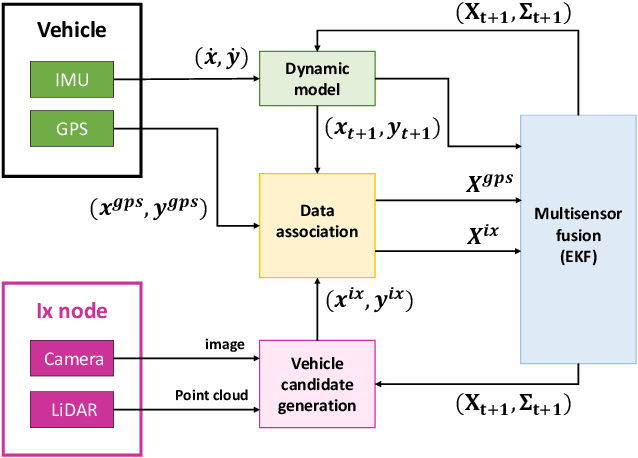
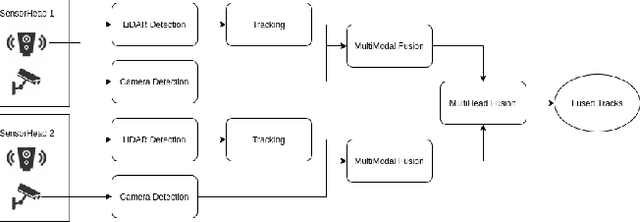
Vehicle localization is essential for autonomous vehicle (AV) navigation and Advanced Driver Assistance Systems (ADAS). Accurate vehicle localization is often achieved via expensive inertial navigation systems or by employing compute-intensive vision processing (LiDAR/camera) to augment the low-cost and noisy inertial sensors. Here we have developed a framework for fusing the information obtained from a smart infrastructure node (ix-node) with the autonomous vehicles on-board localization engine to estimate the robust and accurate pose of the ego-vehicle even with cheap inertial sensors. A smart ix-node is typically used to augment the perception capability of an autonomous vehicle, especially when the onboard perception sensors of AVs are blocked by the dynamic and static objects in the environment thereby making them ineffectual. In this work, we utilize this perception output from an ix-node to increase the localization accuracy of the AV. The fusion of ix-node perception output with the vehicle's low-cost inertial sensors allows us to perform reliable vehicle localization without the need for relying on expensive inertial navigation systems or compute-intensive vision processing onboard the AVs. The proposed approach has been tested on real-world datasets collected from a test track in Ann Arbor, Michigan. Detailed analysis of the experimental results shows that incorporating ix-node data improves localization performance.
Motion based Extrinsic Calibration of a 3D Lidar and an IMU
Apr 25, 2021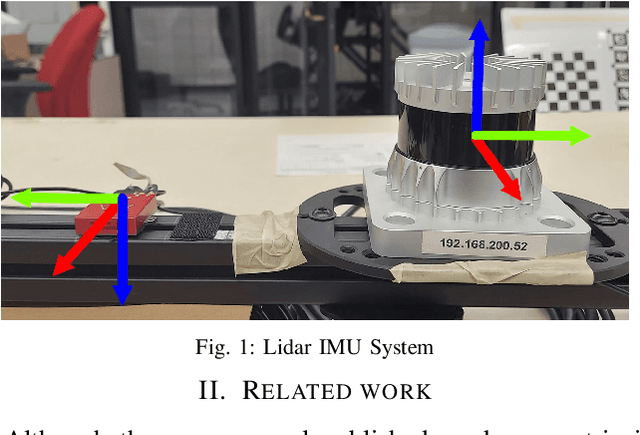
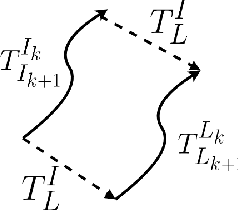
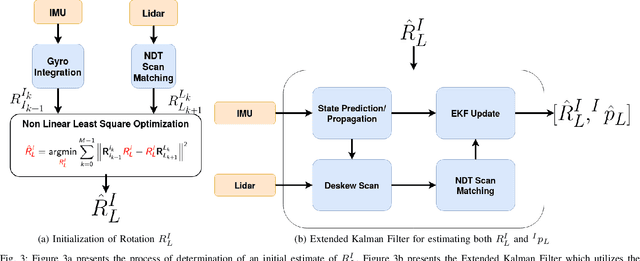
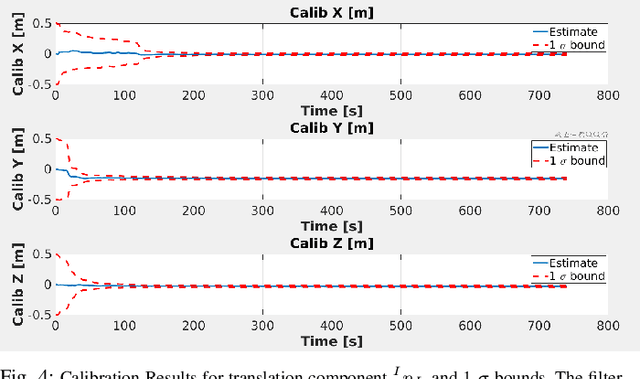
This work presents a novel extrinsic calibration estimation algorithm between a 3D Lidar and an IMU using an Extended Kalman Filter which exploits the motion based calibration constraint for state update. The steps include, data collection by moving the Lidar Inertial sensor suite randomly along all degrees of freedom, determination of the inter sensor rotation by using rotational component of the aforementioned motion based calibration constraint in a least squares optimization framework, and finally determination of inter sensor translation using the motion based calibration constraint in an Extended Kalman Filter (EKF) framework. We experimentally validate our method on data collected in our lab.
Developing parsimonious ensembles using predictor diversity within a reinforcement learning framework
Feb 25, 2021
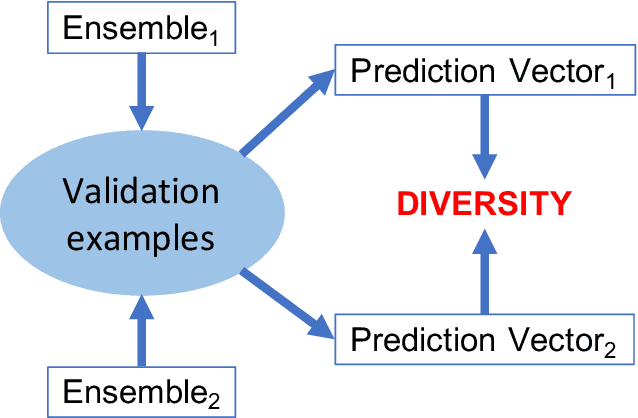
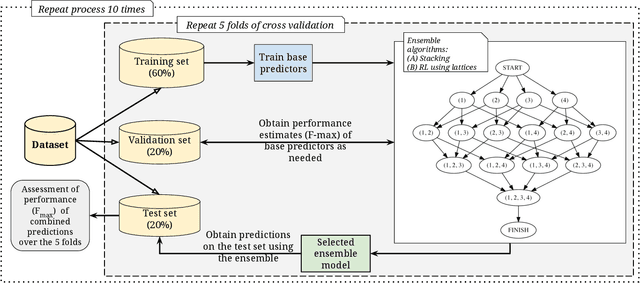
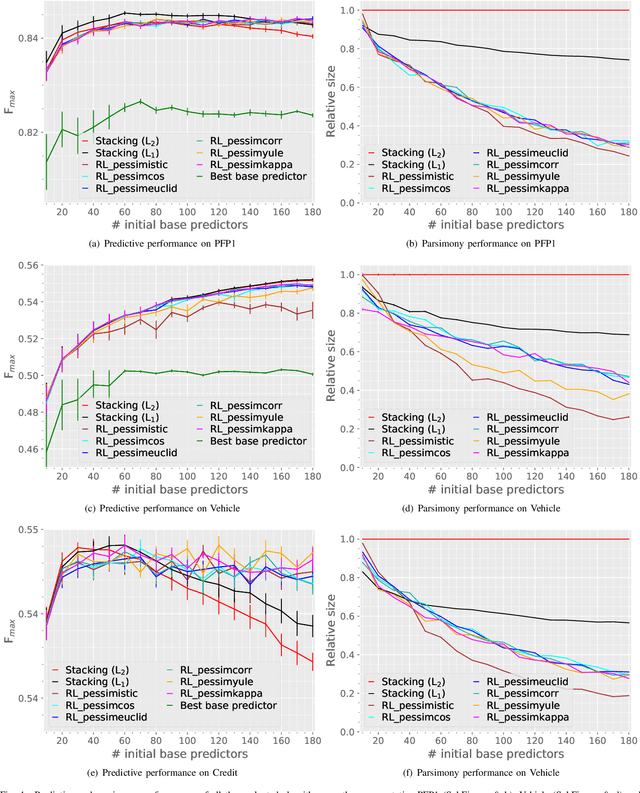
Heterogeneous ensembles that can aggregate an unrestricted number and variety of base predictors can effectively address challenging prediction problems. In particular, accurate ensembles that are also parsimonious, i.e., consist of as few base predictors as possible, can help reveal potentially useful knowledge about the target problem domain. Although ensemble selection offers a potential approach to achieving these goals, the currently available algorithms are limited in their abilities. In this paper, we present several algorithms that incorporate ensemble diversity into a reinforcement learning (RL)-based ensemble selection framework to build accurate and parsimonious ensembles. These algorithms, as well as several baselines, are rigorously evaluated on datasets from diverse domains in terms of the predictive performance and parsimony of their ensembles. This evaluation demonstrates that our diversity-incorporated RL-based algorithms perform better than the others for constructing simultaneously accurate and parsimonious ensembles. These algorithms can eventually aid the interpretation or reverse engineering of predictive models assimilated into effective ensembles. To enable such a translation, an implementation of these algorithms, as well the experimental setup they are evaluated in, has been made available at https://github.com/GauravPandeyLab/lens-learning-ensembles-using-reinforcement-learning.
Real Time Incremental Foveal Texture Mapping for Autonomous Vehicles
Jan 16, 2021
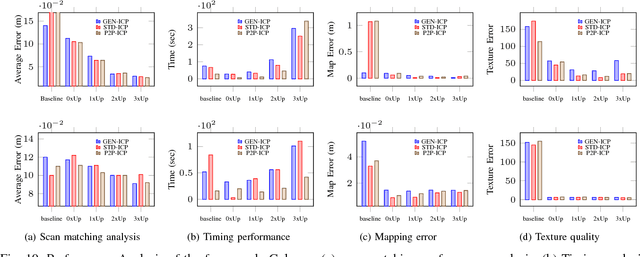
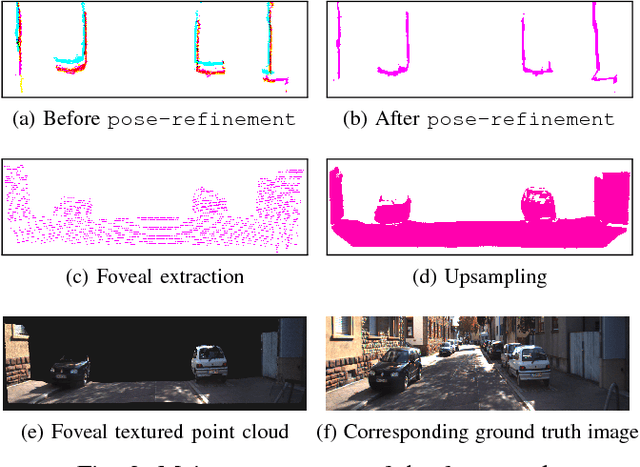
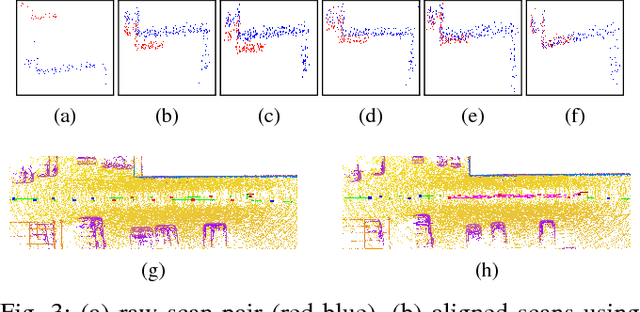
We propose an end-to-end real time framework to generate high resolution graphics grade textured 3D map of urban environment. The generated detailed map finds its application in the precise localization and navigation of autonomous vehicles. It can also serve as a virtual test bed for various vision and planning algorithms as well as a background map in the computer games. In this paper, we focus on two important issues: (i) incrementally generating a map with coherent 3D surface, in real time and (ii) preserving the quality of color texture. To handle the above issues, firstly, we perform a pose-refinement procedure which leverages camera image information, Delaunay triangulation and existing scan matching techniques to produce high resolution 3D map from the sparse input LIDAR scan. This 3D map is then texturized and accumulated by using a novel technique of ray-filtering which handles occlusion and inconsistencies in pose-refinement. Further, inspired by human fovea, we introduce foveal-processing which significantly reduces the computation time and also assists ray-filtering to maintain consistency in color texture and coherency in 3D surface of the output map. Moreover, we also introduce texture error (TE) and mean texture mapping error (MTME), which provides quantitative measure of texturing and overall quality of the textured maps.
Simulated Chats for Task-oriented Dialog: Learning to Generate Conversations from Instructions
Oct 20, 2020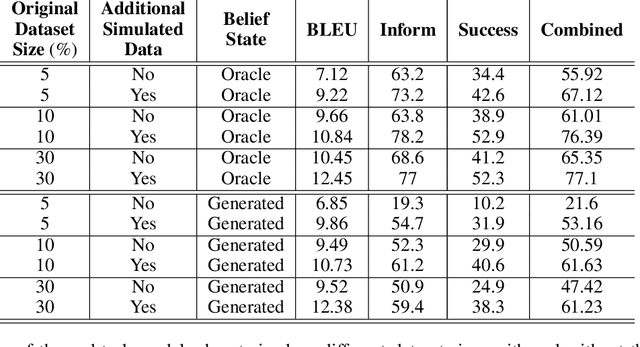
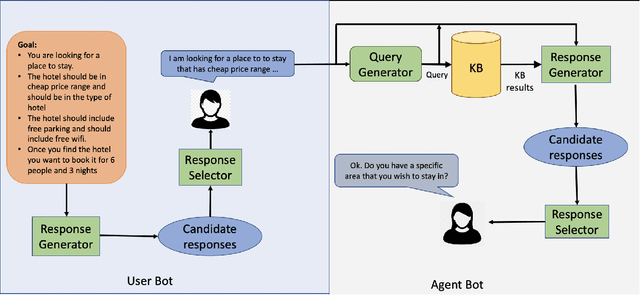
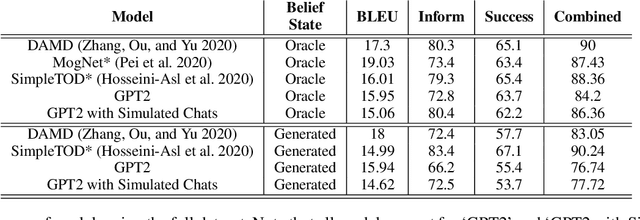

Popular task-oriented dialog data sets such as MultiWOZ (Budzianowski et al. 2018) are created by providing crowd-sourced workers a goal instruction, expressed in natural language, that describes the task to be accomplished. Crowd-sourced workers play the role of a user and an agent to generate dialogs to accomplish tasks involving booking restaurant tables, making train reservations, calling a taxi etc. However, creating large crowd-sourced datasets can be time consuming and expensive. To reduce the cost associated with generating such dialog datasets, recent work has explored methods to automatically create larger datasets from small samples.In this paper, we present a data creation strategy that uses the pre-trained language model, GPT2 (Radford et al. 2018), to simulate the interaction between crowd-sourced workers by creating a user bot and an agent bot. We train the simulators using a smaller percentage of actual crowd-generated conversations and their corresponding goal instructions. We demonstrate that by using the simulated data, we achieve significant improvements in both low-resource setting as well as in over-all task performance. To the best of our knowledge we are the first to present a model for generating entire conversations by simulating the crowd-sourced data collection process
Ford Highway Driving RTK Dataset: 30,000 km of North American Highways
Oct 05, 2020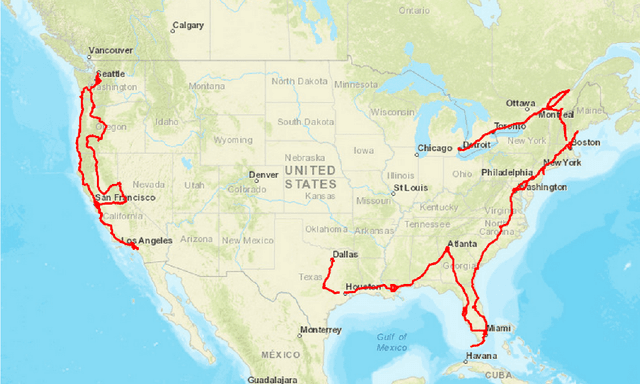
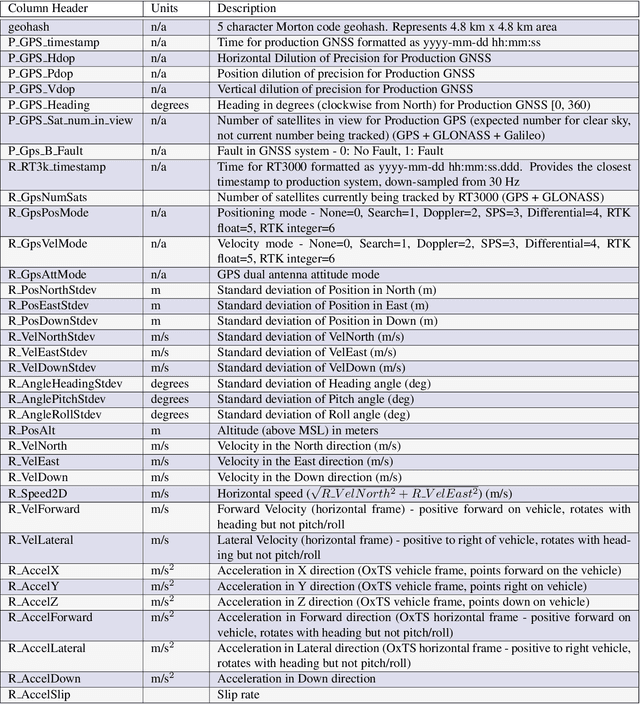
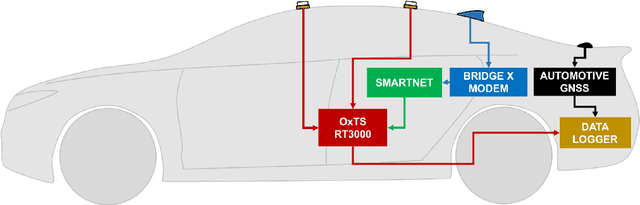
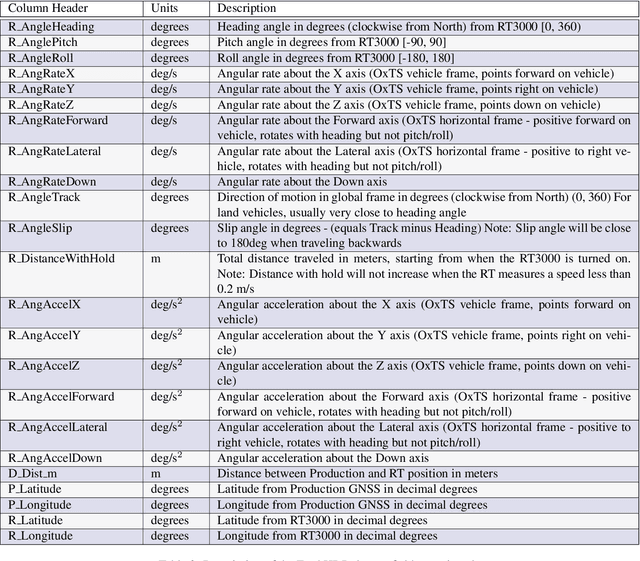
There is a growing need for vehicle positioning information to support Advanced Driver Assistance Systems (ADAS), Connectivity (V2X), and Autonomous Driving (AD) features. These range from a need for road determination ($<$5 meters), lane determination ($<$1.5 meters), and determining where the vehicle is within the lane ($<$0.3 meters). This paper presents the Ford Highway Driving RTK (Ford-HDR) dataset. This dataset includes nearly 30,000 km of data collected primarily on North American highways during a driving campaign designed to validate driver assistance features in 2018. This includes data from a representative automotive production GNSS used primarily for turn-by-turn navigation as well as an Inertial Navigation System (INS) which couples two survey-grade GNSS receivers with a tactical grade Inertial Measurement Unit (IMU) to act as ground truth. The latter utilized networked Real-Time Kinematic (RTK) GNSS corrections delivered over a cellular modem in real-time. This dataset is being released into the public domain to spark further research in the community.
Unravelling the Architecture of Membrane Proteins with Conditional Random Fields
Aug 06, 2020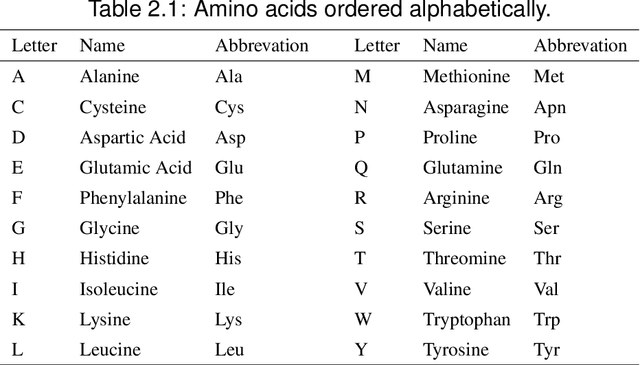

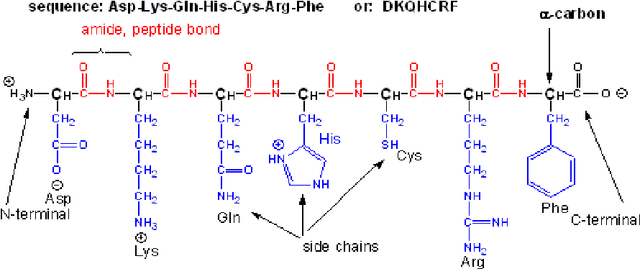
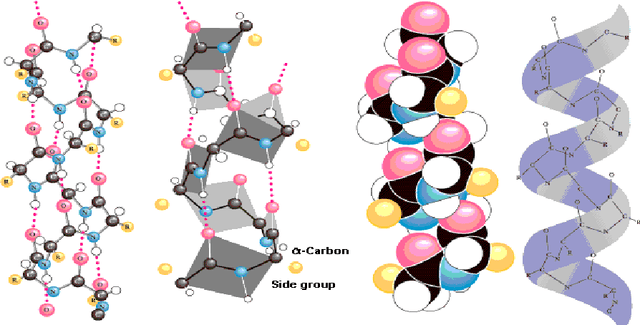
In this paper, we will show that the recently introduced graphical model: Conditional Random Fields (CRF) provides a template to integrate micro-level information about biological entities into a mathematical model to understand their macro-level behavior. More specifically, we will apply the CRF model to an important classification problem in protein science, namely the secondary structure prediction of proteins based on the observed primary structure. A comparison on benchmark data sets against twenty-eight other methods shows that not only does the CRF model lead to extremely accurate predictions but the modular nature of the model and the freedom to integrate disparate, overlapping and non-independent sources of information, makes the model an extremely versatile tool to potentially solve many other problems in bioinformatics.
Experimental Evaluation of 3D-LIDAR Camera Extrinsic Calibration
Jul 03, 2020

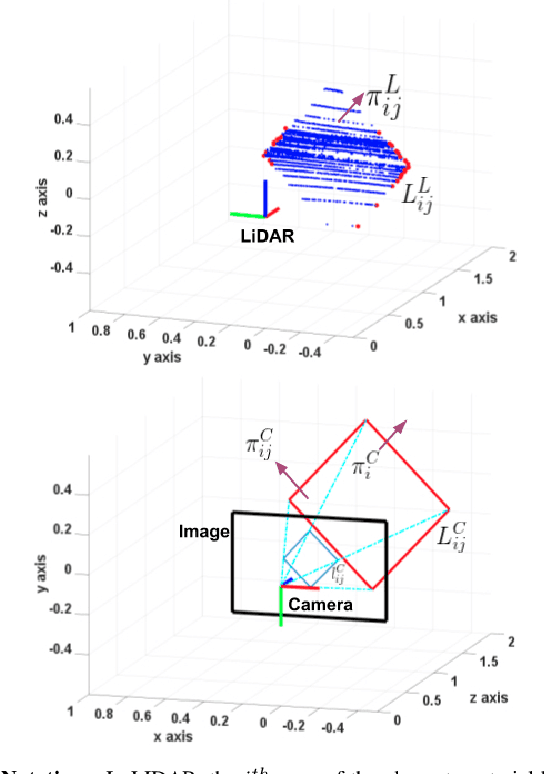
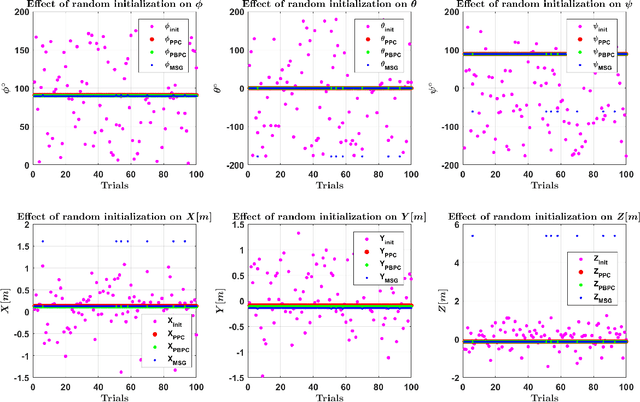
In this paper we perform an experimental comparison of three different target based 3D-LIDAR camera calibration algorithms. We briefly elucidate the mathematical background behind each method and provide insights into practical aspects like ease of data collection for all of them. We extensively evaluate these algorithms on a sensor suite which consists multiple cameras and LIDARs by assessing their robustness to random initialization and by using metrics like Mean Line Re-projection Error (MLRE) and Factory Stereo Calibration Error. We also show the effect of noisy sensor on the calibration result from all the algorithms and conclude with a note on which calibration algorithm should be used under what circumstances.
Aerial Imagery based LIDAR Localization for Autonomous Vehicles
Mar 25, 2020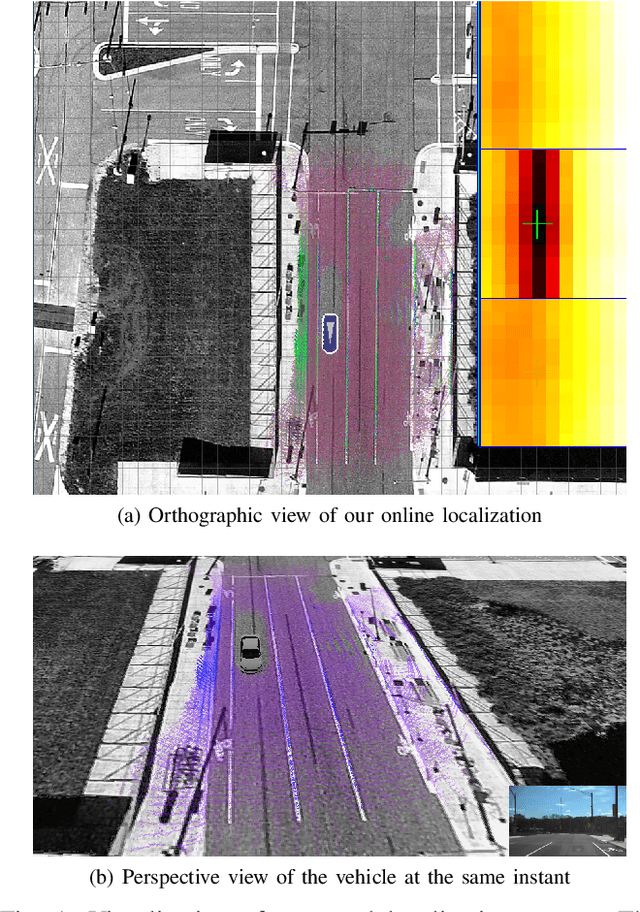



This paper presents a localization technique using aerial imagery maps and LIDAR based ground reflectivity for autonomous vehicles in urban environments. Traditional localization techniques using LIDAR reflectivity rely on high definition reflectivity maps generated from a mapping vehicle. The cost and effort required to maintain such prior maps are generally very high because it requires a fleet of expensive mapping vehicles. In this work we propose a localization technique where the vehicle localizes using aerial/satellite imagery, eradicating the need to develop and maintain complex high-definition maps. The proposed technique has been tested on a real world dataset collected from a test track in Ann Arbor, Michigan. This research concludes that aerial imagery based maps provides real-time localization performance similar to state-of-the-art LIDAR based maps for autonomous vehicles in urban environments at reduced costs.
Ford Multi-AV Seasonal Dataset
Mar 17, 2020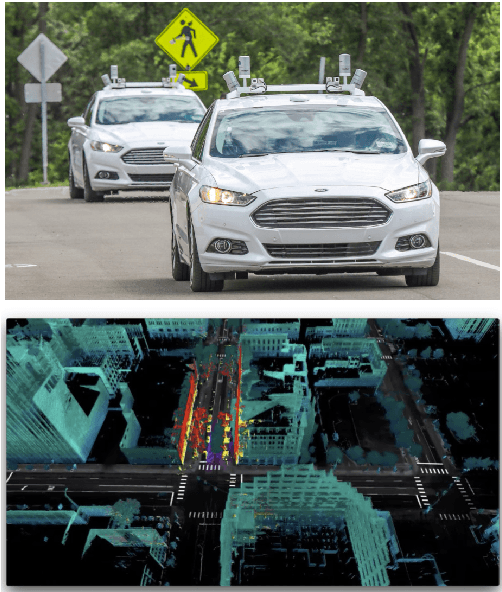

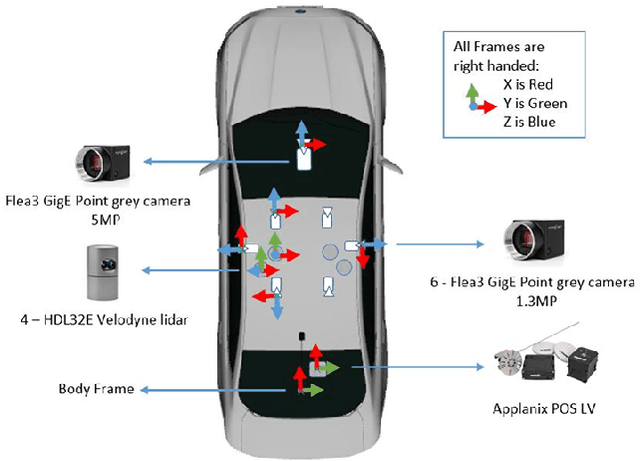
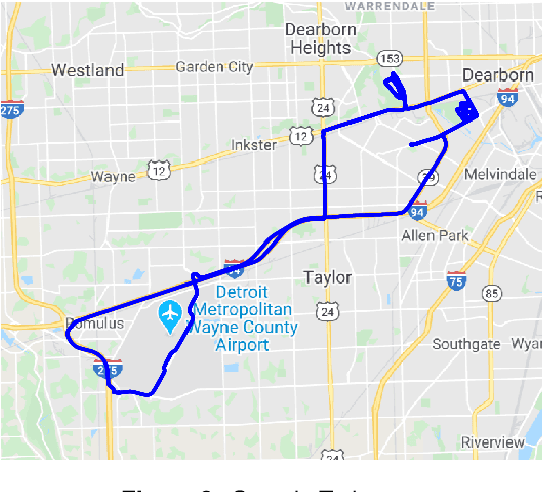
This paper presents a challenging multi-agent seasonal dataset collected by a fleet of Ford autonomous vehicles at different days and times during 2017-18. The vehicles traversed an average route of 66 km in Michigan that included a mix of driving scenarios such as the Detroit Airport, freeways, city-centers, university campus and suburban neighbourhoods, etc. Each vehicle used in this data collection is a Ford Fusion outfitted with an Applanix POS-LV GNSS system, four HDL-32E Velodyne 3D-lidar scanners, 6 Point Grey 1.3 MP Cameras arranged on the rooftop for 360-degree coverage and 1 Pointgrey 5 MP camera mounted behind the windshield for the forward field of view. We present the seasonal variation in weather, lighting, construction and traffic conditions experienced in dynamic urban environments. This dataset can help design robust algorithms for autonomous vehicles and multi-agent systems. Each log in the dataset is time-stamped and contains raw data from all the sensors, calibration values, pose trajectory, ground truth pose, and 3D maps. All data is available in Rosbag format that can be visualized, modified and applied using the open-source Robot Operating System (ROS). We also provide the output of state-of-the-art reflectivity-based localization for bench-marking purposes. The dataset can be freely downloaded at our website.