 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePCA-RECT: An Energy-efficient Object Detection Approach for Event Cameras
Apr 24, 2019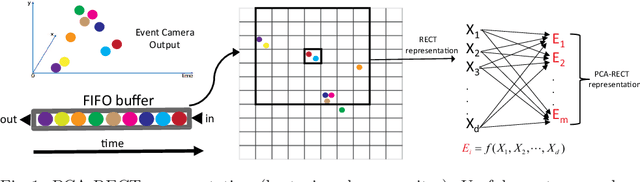
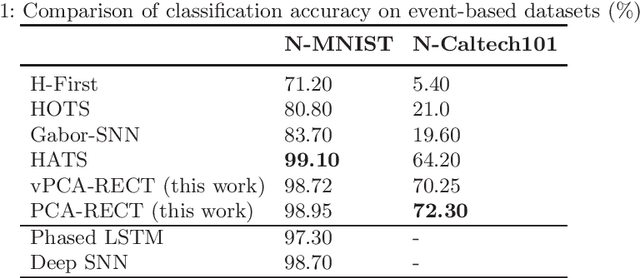
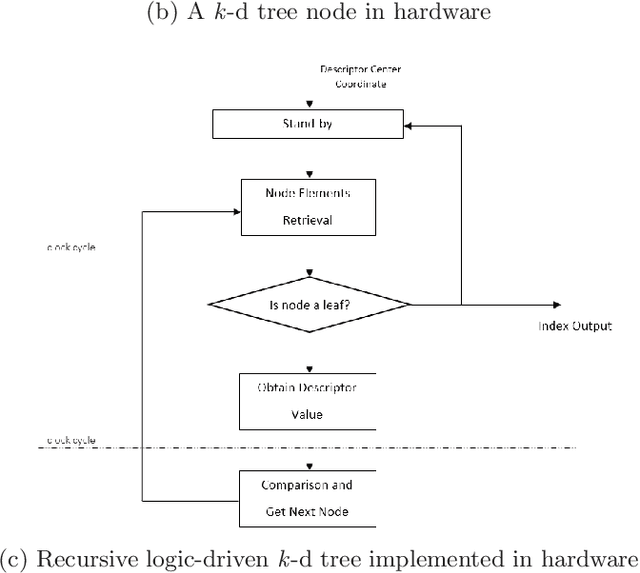
We present the first purely event-based, energy-efficient approach for object detection and categorization using an event camera. Compared to traditional frame-based cameras, choosing event cameras results in high temporal resolution (order of microseconds), low power consumption (few hundred mW) and wide dynamic range (120 dB) as attractive properties. However, event-based object recognition systems are far behind their frame-based counterparts in terms of accuracy. To this end, this paper presents an event-based feature extraction method devised by accumulating local activity across the image frame and then applying principal component analysis (PCA) to the normalized neighborhood region. Subsequently, we propose a backtracking-free k-d tree mechanism for efficient feature matching by taking advantage of the low-dimensionality of the feature representation. Additionally, the proposed k-d tree mechanism allows for feature selection to obtain a lower-dimensional dictionary representation when hardware resources are limited to implement dimensionality reduction. Consequently, the proposed system can be realized on a field-programmable gate array (FPGA) device leading to high performance over resource ratio. The proposed system is tested on real-world event-based datasets for object categorization, showing superior classification performance and relevance to state-of-the-art algorithms. Additionally, we verified the object detection method and real-time FPGA performance in lab settings under non-controlled illumination conditions with limited training data and ground truth annotations.
Event-based Vision: A Survey
Apr 17, 2019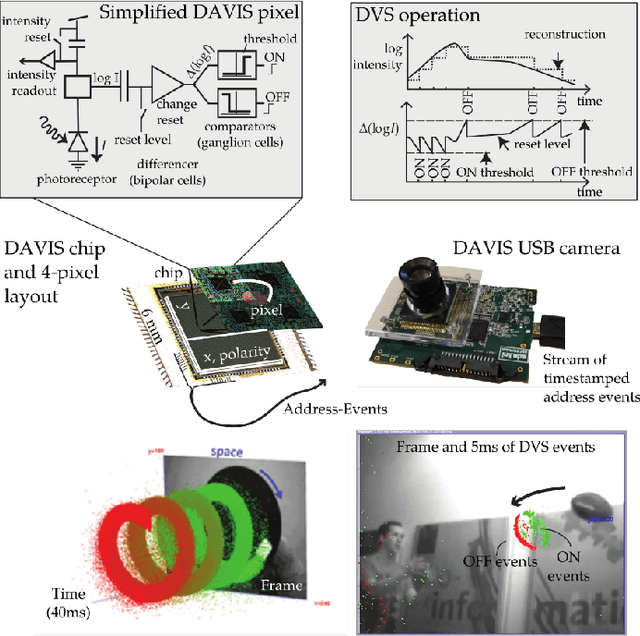
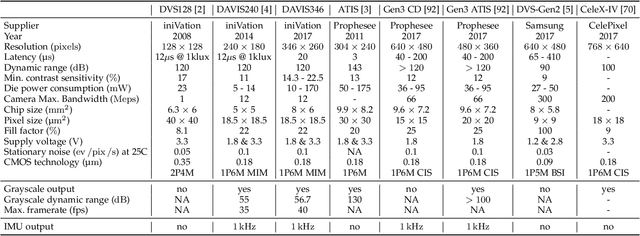
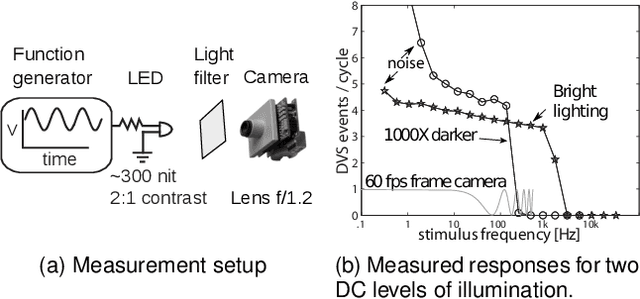
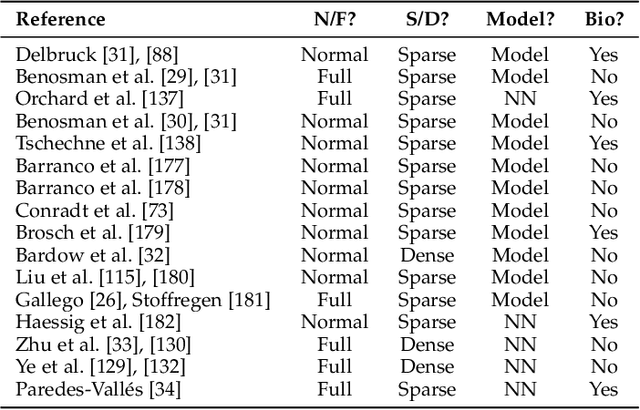
Event cameras are bio-inspired sensors that work radically different from traditional cameras. Instead of capturing images at a fixed rate, they measure per-pixel brightness changes asynchronously. This results in a stream of events, which encode the time, location and sign of the brightness changes. Event cameras posses outstanding properties compared to traditional cameras: very high dynamic range (140 dB vs. 60 dB), high temporal resolution (in the order of microseconds), low power consumption, and do not suffer from motion blur. Hence, event cameras have a large potential for robotics and computer vision in challenging scenarios for traditional cameras, such as high speed and high dynamic range. However, novel methods are required to process the unconventional output of these sensors in order to unlock their potential. This paper provides a comprehensive overview of the emerging field of event-based vision, with a focus on the applications and the algorithms developed to unlock the outstanding properties of event cameras. We present event cameras from their working principle, the actual sensors that are available and the tasks that they have been used for, from low-level vision (feature detection and tracking, optic flow, etc.) to high-level vision (reconstruction, segmentation, recognition). We also discuss the techniques developed to process events, including learning-based techniques, as well as specialized processors for these novel sensors, such as spiking neural networks. Additionally, we highlight the challenges that remain to be tackled and the opportunities that lie ahead in the search for a more efficient, bio-inspired way for machines to perceive and interact with the world.
SLAYER: Spike Layer Error Reassignment in Time
Sep 05, 2018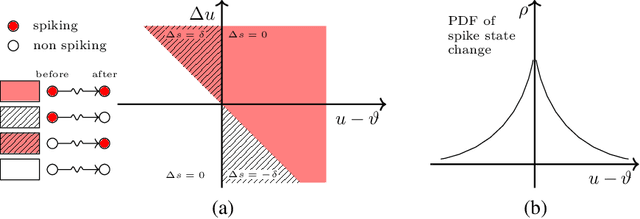
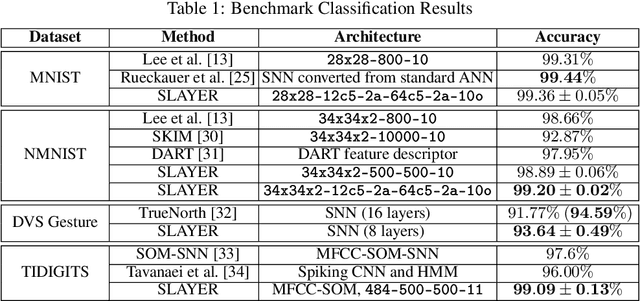
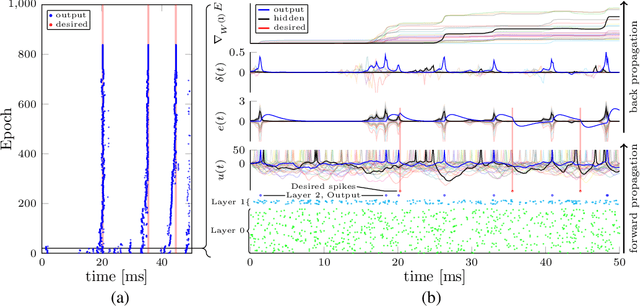
Configuring deep Spiking Neural Networks (SNNs) is an exciting research avenue for low power spike event based computation. However, the spike generation function is non-differentiable and therefore not directly compatible with the standard error backpropagation algorithm. In this paper, we introduce a new general backpropagation mechanism for learning synaptic weights and axonal delays which overcomes the problem of non-differentiability of the spike function and uses a temporal credit assignment policy for backpropagating error to preceding layers. We describe and release a GPU accelerated software implementation of our method which allows training both fully connected and convolutional neural network (CNN) architectures. Using our software, we compare our method against existing SNN based learning approaches and standard ANN to SNN conversion techniques and show that our method achieves state of the art performance for an SNN on the MNIST, NMNIST, DVS Gesture, and TIDIGITS datasets.
DART: Distribution Aware Retinal Transform for Event-based Cameras
Oct 30, 2017
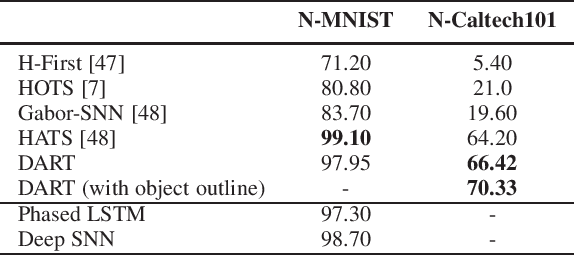
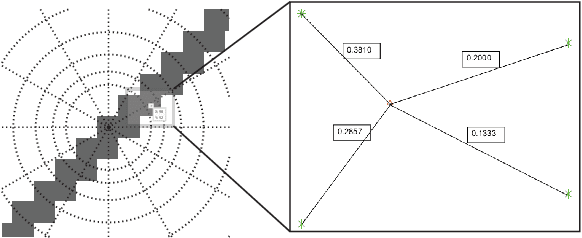
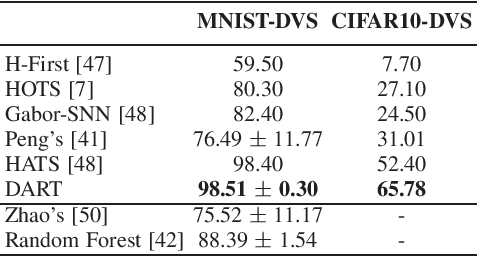
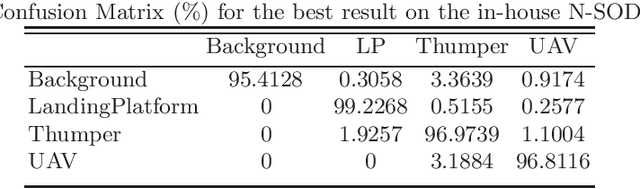
We introduce a new event-based visual descriptor, termed as distribution aware retinal transform (DART), for pattern recognition using silicon retina cameras. The DART descriptor captures the information of the spatio-temporal distribution of events, and forms a rich structural representation. Consequently, the event context encoded by DART greatly simplifies the feature correspondence problem, which is highly relevant to many event-based vision problems. The proposed descriptor is robust to scale and rotation variations without the need for spectral analysis. To demonstrate the effectiveness of the DART descriptors, they are employed as local features in the bag-of-features classification framework. The proposed framework is tested on the N-MNIST, MNIST-DVS, CIFAR10-DVS, NCaltech-101 datasets, as well as a new object dataset, N-SOD (Neuromorphic-Single Object Dataset), collected to test unconstrained viewpoint recognition. We report a competitive classification accuracy of 97.95% on the N-MNIST and the best classification accuracy compared to existing works on the MNIST-DVS (99%), CIFAR10-DVS (65.9%) and NCaltech-101 (70.3%). Using the in-house N-SOD, we demonstrate real-time classification performance on an Intel Compute Stick directly interfaced to an event camera flying on-board a quadcopter. In addition, taking advantage of the high-temporal resolution of event cameras, the classification system is extended to tackle object tracking. Finally, we demonstrate efficient feature matching for event-based cameras using kd-trees.
Spiking Optical Flow for Event-based Sensors Using IBM's TrueNorth Neurosynaptic System
Oct 26, 2017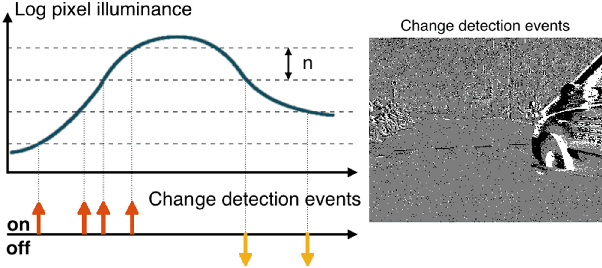

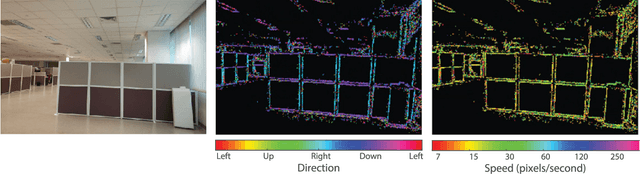
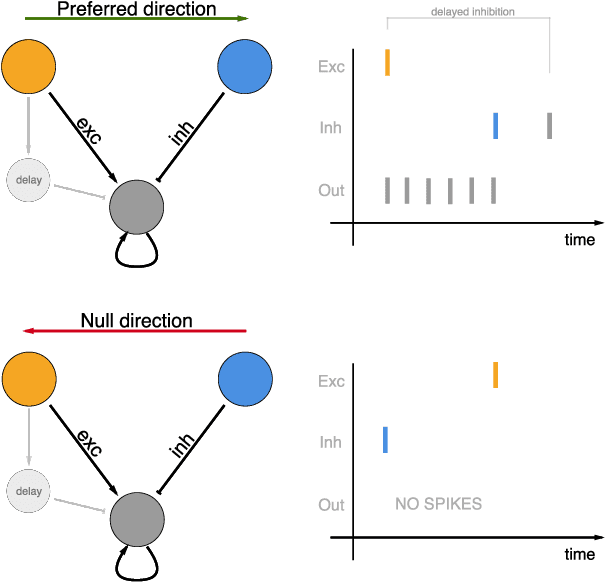
This paper describes a fully spike-based neural network for optical flow estimation from Dynamic Vision Sensor data. A low power embedded implementation of the method which combines the Asynchronous Time-based Image Sensor with IBM's TrueNorth Neurosynaptic System is presented. The sensor generates spikes with sub-millisecond resolution in response to scene illumination changes. These spike are processed by a spiking neural network running on TrueNorth with a 1 millisecond resolution to accurately determine the order and time difference of spikes from neighboring pixels, and therefore infer the velocity. The spiking neural network is a variant of the Barlow Levick method for optical flow estimation. The system is evaluated on two recordings for which ground truth motion is available, and achieves an Average Endpoint Error of 11% at an estimated power budget of under 80mW for the sensor and computation.
Fast Neuromimetic Object Recognition using FPGA Outperforms GPU Implementations
Oct 31, 2015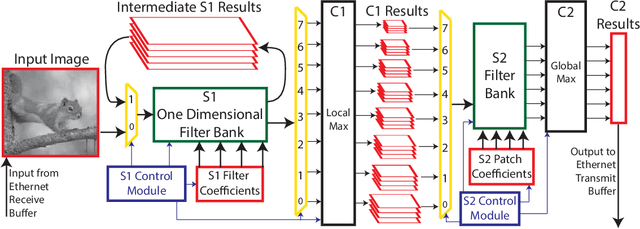
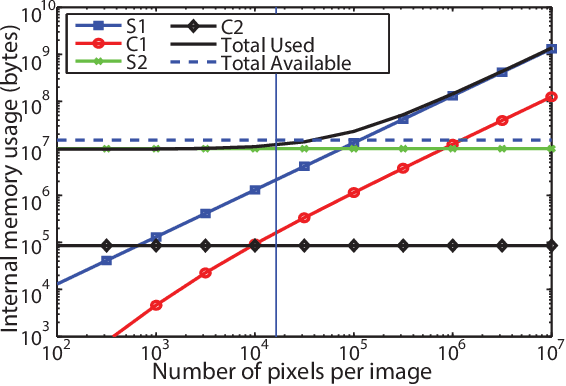
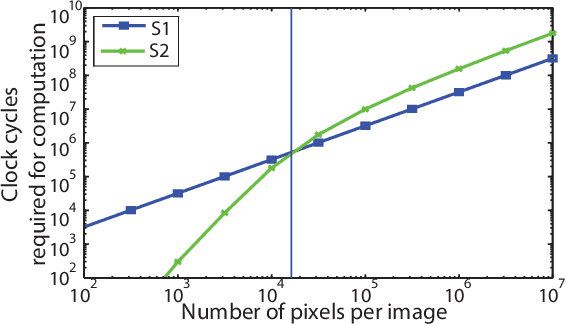
Recognition of objects in still images has traditionally been regarded as a difficult computational problem. Although modern automated methods for visual object recognition have achieved steadily increasing recognition accuracy, even the most advanced computational vision approaches are unable to obtain performance equal to that of humans. This has led to the creation of many biologically-inspired models of visual object recognition, among them the HMAX model. HMAX is traditionally known to achieve high accuracy in visual object recognition tasks at the expense of significant computational complexity. Increasing complexity, in turn, increases computation time, reducing the number of images that can be processed per unit time. In this paper we describe how the computationally intensive, biologically inspired HMAX model for visual object recognition can be modified for implementation on a commercial Field Programmable Gate Array, specifically the Xilinx Virtex 6 ML605 evaluation board with XC6VLX240T FPGA. We show that with minor modifications to the traditional HMAX model we can perform recognition on images of size 128x128 pixels at a rate of 190 images per second with a less than 1% loss in recognition accuracy in both binary and multi-class visual object recognition tasks.
* 14 pages, 8 figures, 5 tables
Bioinspired Visual Motion Estimation
Oct 31, 2015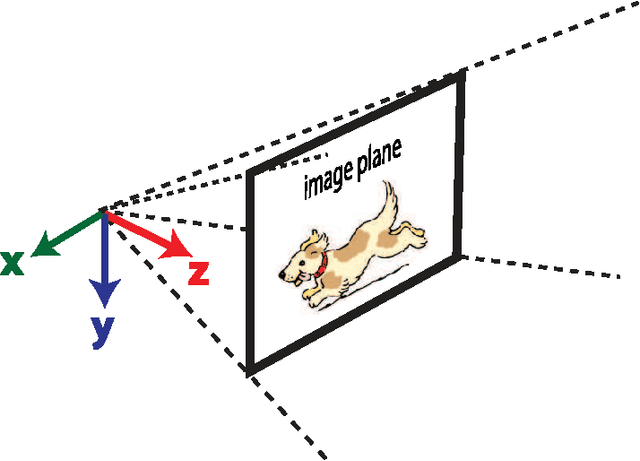
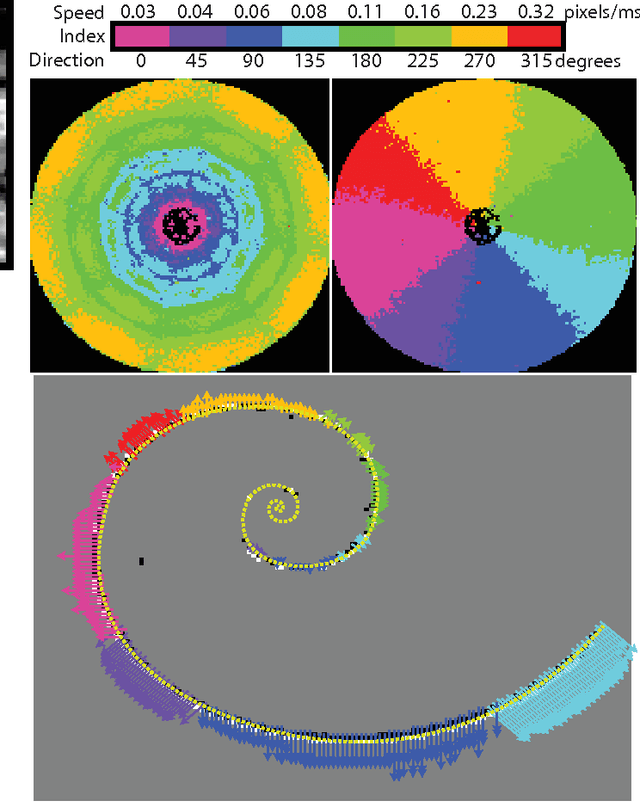

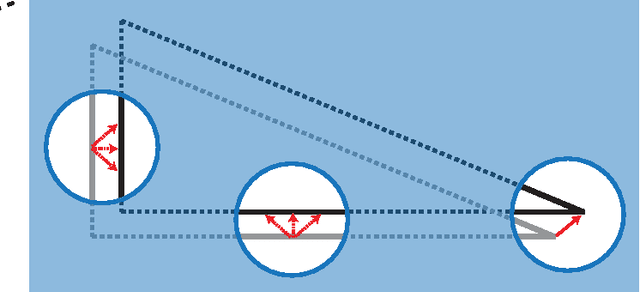
Visual motion estimation is a computationally intensive, but important task for sighted animals. Replicating the robustness and efficiency of biological visual motion estimation in artificial systems would significantly enhance the capabilities of future robotic agents. 25 years ago, in this very journal, Carver Mead outlined his argument for replicating biological processing in silicon circuits. His vision served as the foundation for the field of neuromorphic engineering, which has experienced a rapid growth in interest over recent years as the ideas and technologies mature. Replicating biological visual sensing was one of the first tasks attempted in the neuromorphic field. In this paper we focus specifically on the task of visual motion estimation. We describe the task itself, present the progression of works from the early first attempts through to the modern day state-of-the-art, and provide an outlook for future directions in the field.
* 16 pages, 11 figures, 1 table
HFirst: A Temporal Approach to Object Recognition
Aug 05, 2015
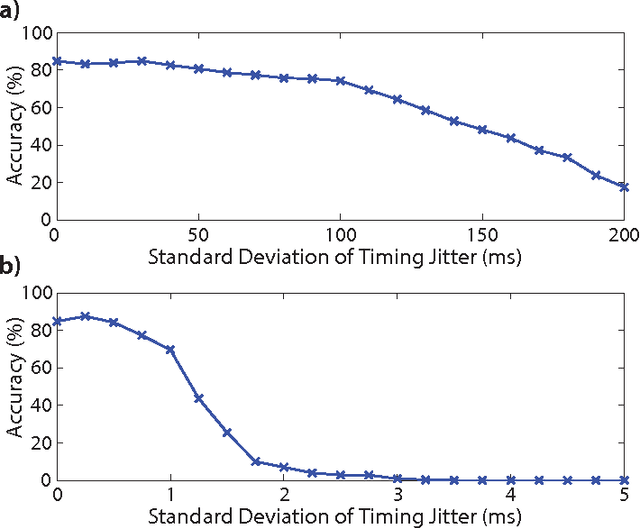
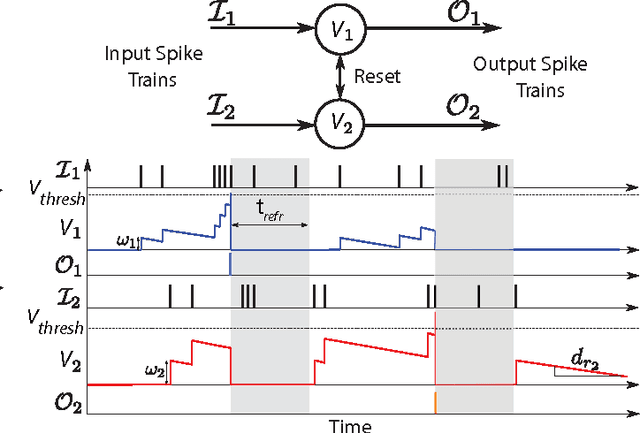
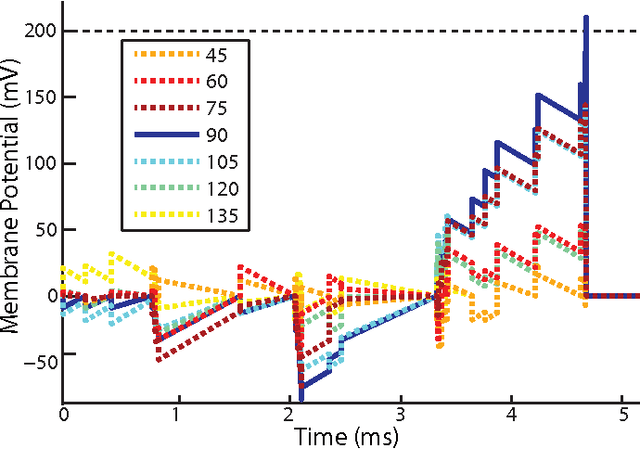
This paper introduces a spiking hierarchical model for object recognition which utilizes the precise timing information inherently present in the output of biologically inspired asynchronous Address Event Representation (AER) vision sensors. The asynchronous nature of these systems frees computation and communication from the rigid predetermined timing enforced by system clocks in conventional systems. Freedom from rigid timing constraints opens the possibility of using true timing to our advantage in computation. We show not only how timing can be used in object recognition, but also how it can in fact simplify computation. Specifically, we rely on a simple temporal-winner-take-all rather than more computationally intensive synchronous operations typically used in biologically inspired neural networks for object recognition. This approach to visual computation represents a major paradigm shift from conventional clocked systems and can find application in other sensory modalities and computational tasks. We showcase effectiveness of the approach by achieving the highest reported accuracy to date (97.5\%$\pm$3.5\%) for a previously published four class card pip recognition task and an accuracy of 84.9\%$\pm$1.9\% for a new more difficult 36 class character recognition task.
* 13 pages, 10 figures