 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCo-attention Propagation Network for Zero-Shot Video Object Segmentation
Apr 08, 2023



Zero-shot video object segmentation (ZS-VOS) aims to segment foreground objects in a video sequence without prior knowledge of these objects. However, existing ZS-VOS methods often struggle to distinguish between foreground and background or to keep track of the foreground in complex scenarios. The common practice of introducing motion information, such as optical flow, can lead to overreliance on optical flow estimation. To address these challenges, we propose an encoder-decoder-based hierarchical co-attention propagation network (HCPN) capable of tracking and segmenting objects. Specifically, our model is built upon multiple collaborative evolutions of the parallel co-attention module (PCM) and the cross co-attention module (CCM). PCM captures common foreground regions among adjacent appearance and motion features, while CCM further exploits and fuses cross-modal motion features returned by PCM. Our method is progressively trained to achieve hierarchical spatio-temporal feature propagation across the entire video. Experimental results demonstrate that our HCPN outperforms all previous methods on public benchmarks, showcasing its effectiveness for ZS-VOS.
Attention Map Guided Transformer Pruning for Edge Device
Apr 04, 2023



Due to its significant capability of modeling long-range dependencies, vision transformer (ViT) has achieved promising success in both holistic and occluded person re-identification (Re-ID) tasks. However, the inherent problems of transformers such as the huge computational cost and memory footprint are still two unsolved issues that will block the deployment of ViT based person Re-ID models on resource-limited edge devices. Our goal is to reduce both the inference complexity and model size without sacrificing the comparable accuracy on person Re-ID, especially for tasks with occlusion. To this end, we propose a novel attention map guided (AMG) transformer pruning method, which removes both redundant tokens and heads with the guidance of the attention map in a hardware-friendly way. We first calculate the entropy in the key dimension and sum it up for the whole map, and the corresponding head parameters of maps with high entropy will be removed for model size reduction. Then we combine the similarity and first-order gradients of key tokens along the query dimension for token importance estimation and remove redundant key and value tokens to further reduce the inference complexity. Comprehensive experiments on Occluded DukeMTMC and Market-1501 demonstrate the effectiveness of our proposals. For example, our proposed pruning strategy on ViT-Base enjoys \textup{\textbf{29.4\%}} \textup{\textbf{FLOPs}} savings with \textup{\textbf{0.2\%}} drop on Rank-1 and \textup{\textbf{0.4\%}} improvement on mAP, respectively.
Hierarchical Feature Alignment Network for Unsupervised Video Object Segmentation
Jul 19, 2022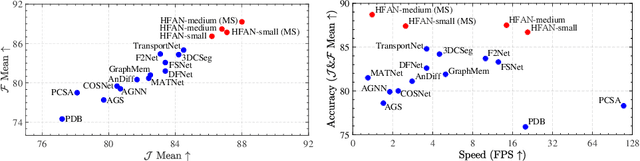

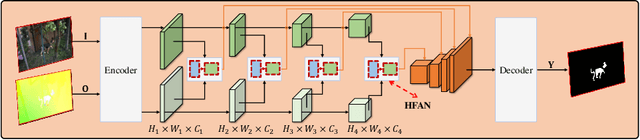
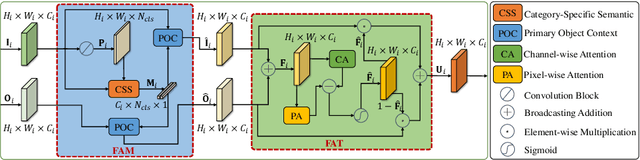
Optical flow is an easily conceived and precious cue for advancing unsupervised video object segmentation (UVOS). Most of the previous methods directly extract and fuse the motion and appearance features for segmenting target objects in the UVOS setting. However, optical flow is intrinsically an instantaneous velocity of all pixels among consecutive frames, thus making the motion features not aligned well with the primary objects among the corresponding frames. To solve the above challenge, we propose a concise, practical, and efficient architecture for appearance and motion feature alignment, dubbed hierarchical feature alignment network (HFAN). Specifically, the key merits in HFAN are the sequential Feature AlignMent (FAM) module and the Feature AdaptaTion (FAT) module, which are leveraged for processing the appearance and motion features hierarchically. FAM is capable of aligning both appearance and motion features with the primary object semantic representations, respectively. Further, FAT is explicitly designed for the adaptive fusion of appearance and motion features to achieve a desirable trade-off between cross-modal features. Extensive experiments demonstrate the effectiveness of the proposed HFAN, which reaches a new state-of-the-art performance on DAVIS-16, achieving 88.7 $\mathcal{J}\&\mathcal{F}$ Mean, i.e., a relative improvement of 3.5% over the best published result.
Saliency Guided Inter- and Intra-Class Relation Constraints for Weakly Supervised Semantic Segmentation
Jun 20, 2022
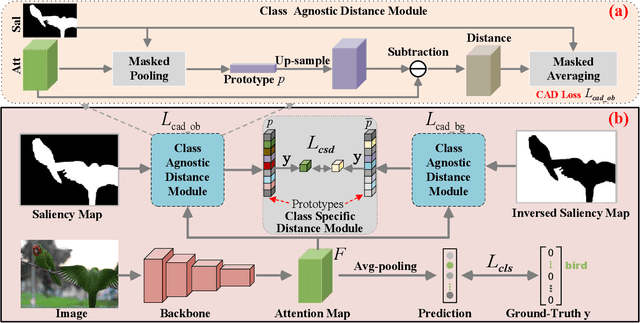


Weakly supervised semantic segmentation with only image-level labels aims to reduce annotation costs for the segmentation task. Existing approaches generally leverage class activation maps (CAMs) to locate the object regions for pseudo label generation. However, CAMs can only discover the most discriminative parts of objects, thus leading to inferior pixel-level pseudo labels. To address this issue, we propose a saliency guided Inter- and Intra-Class Relation Constrained (I$^2$CRC) framework to assist the expansion of the activated object regions in CAMs. Specifically, we propose a saliency guided class-agnostic distance module to pull the intra-category features closer by aligning features to their class prototypes. Further, we propose a class-specific distance module to push the inter-class features apart and encourage the object region to have a higher activation than the background. Besides strengthening the capability of the classification network to activate more integral object regions in CAMs, we also introduce an object guided label refinement module to take a full use of both the segmentation prediction and the initial labels for obtaining superior pseudo-labels. Extensive experiments on PASCAL VOC 2012 and COCO datasets demonstrate well the effectiveness of I$^2$CRC over other state-of-the-art counterparts. The source codes, models, and data have been made available at \url{https://github.com/NUST-Machine-Intelligence-Laboratory/I2CRC}.
Webly Supervised Fine-Grained Recognition: Benchmark Datasets and An Approach
Aug 11, 2021
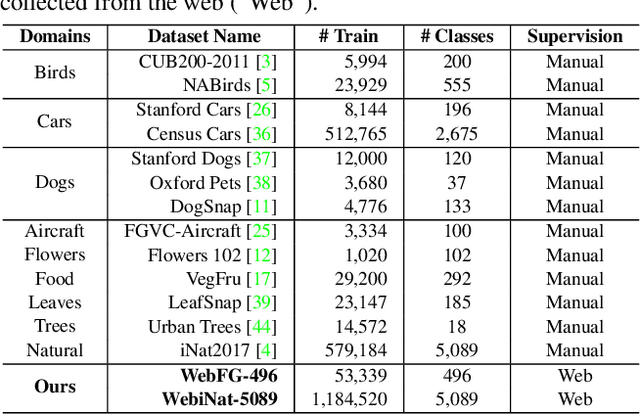

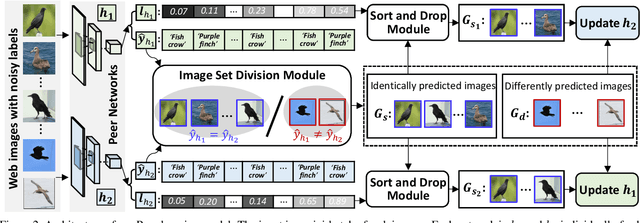
Learning from the web can ease the extreme dependence of deep learning on large-scale manually labeled datasets. Especially for fine-grained recognition, which targets at distinguishing subordinate categories, it will significantly reduce the labeling costs by leveraging free web data. Despite its significant practical and research value, the webly supervised fine-grained recognition problem is not extensively studied in the computer vision community, largely due to the lack of high-quality datasets. To fill this gap, in this paper we construct two new benchmark webly supervised fine-grained datasets, termed WebFG-496 and WebiNat-5089, respectively. In concretely, WebFG-496 consists of three sub-datasets containing a total of 53,339 web training images with 200 species of birds (Web-bird), 100 types of aircrafts (Web-aircraft), and 196 models of cars (Web-car). For WebiNat-5089, it contains 5089 sub-categories and more than 1.1 million web training images, which is the largest webly supervised fine-grained dataset ever. As a minor contribution, we also propose a novel webly supervised method (termed "{Peer-learning}") for benchmarking these datasets.~Comprehensive experimental results and analyses on two new benchmark datasets demonstrate that the proposed method achieves superior performance over the competing baseline models and states-of-the-art. Our benchmark datasets and the source codes of Peer-learning have been made available at {\url{https://github.com/NUST-Machine-Intelligence-Laboratory/weblyFG-dataset}}.
Prototype-supervised Adversarial Network for Targeted Attack of Deep Hashing
May 17, 2021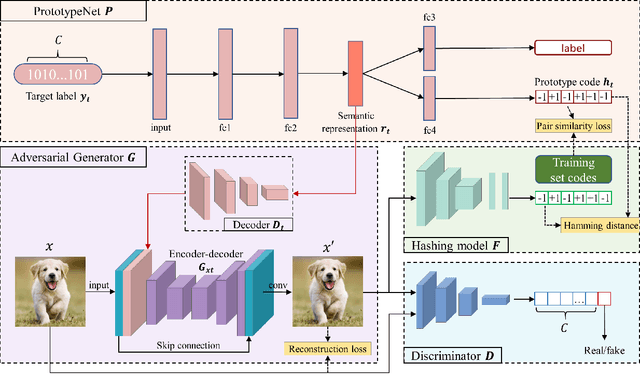
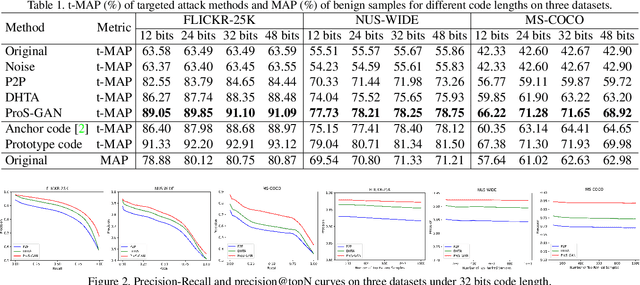
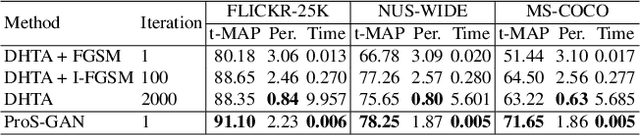

Due to its powerful capability of representation learning and high-efficiency computation, deep hashing has made significant progress in large-scale image retrieval. However, deep hashing networks are vulnerable to adversarial examples, which is a practical secure problem but seldom studied in hashing-based retrieval field. In this paper, we propose a novel prototype-supervised adversarial network (ProS-GAN), which formulates a flexible generative architecture for efficient and effective targeted hashing attack. To the best of our knowledge, this is the first generation-based method to attack deep hashing networks. Generally, our proposed framework consists of three parts, i.e., a PrototypeNet, a generator, and a discriminator. Specifically, the designed PrototypeNet embeds the target label into the semantic representation and learns the prototype code as the category-level representative of the target label. Moreover, the semantic representation and the original image are jointly fed into the generator for a flexible targeted attack. Particularly, the prototype code is adopted to supervise the generator to construct the targeted adversarial example by minimizing the Hamming distance between the hash code of the adversarial example and the prototype code. Furthermore, the generator is against the discriminator to simultaneously encourage the adversarial examples visually realistic and the semantic representation informative. Extensive experiments verify that the proposed framework can efficiently produce adversarial examples with better targeted attack performance and transferability over state-of-the-art targeted attack methods of deep hashing. The related codes could be available at https://github.com/xunguangwang/ProS-GAN .
Non-Salient Region Object Mining for Weakly Supervised Semantic Segmentation
Mar 26, 2021
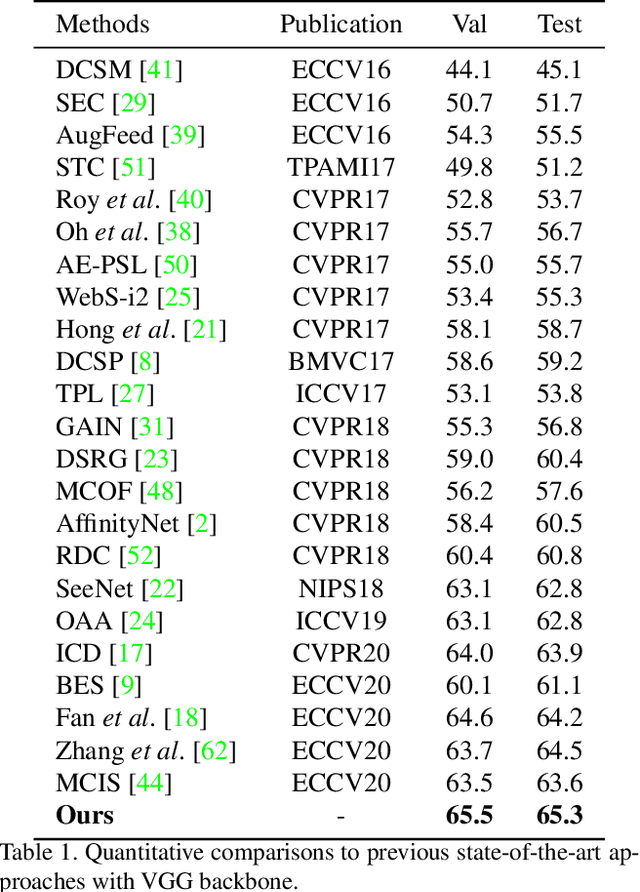
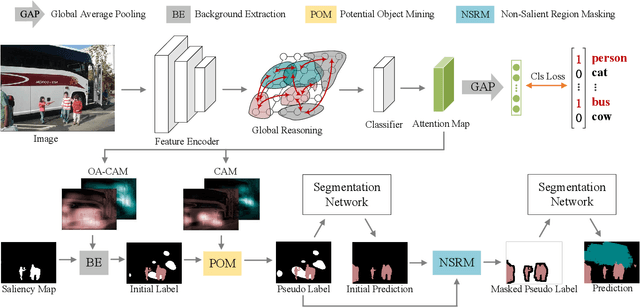
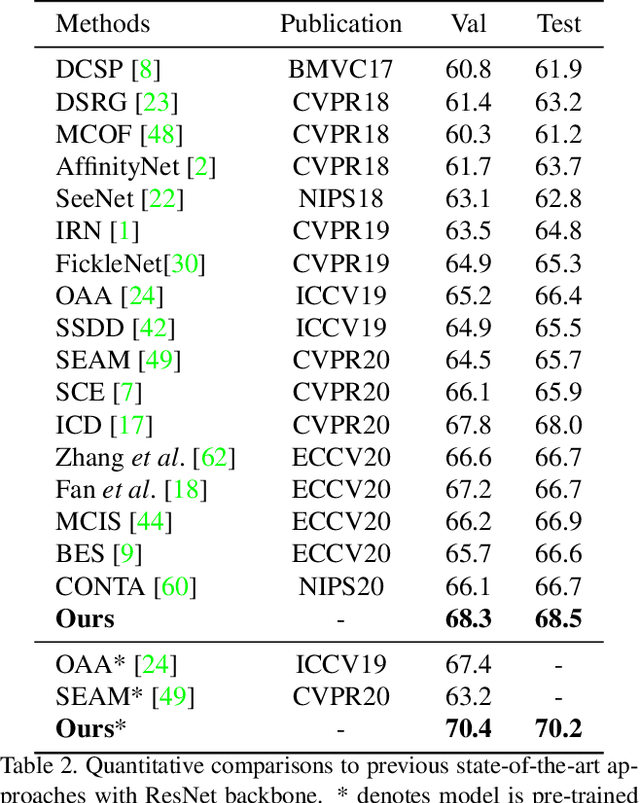
Semantic segmentation aims to classify every pixel of an input image. Considering the difficulty of acquiring dense labels, researchers have recently been resorting to weak labels to alleviate the annotation burden of segmentation. However, existing works mainly concentrate on expanding the seed of pseudo labels within the image's salient region. In this work, we propose a non-salient region object mining approach for weakly supervised semantic segmentation. We introduce a graph-based global reasoning unit to strengthen the classification network's ability to capture global relations among disjoint and distant regions. This helps the network activate the object features outside the salient area. To further mine the non-salient region objects, we propose to exert the segmentation network's self-correction ability. Specifically, a potential object mining module is proposed to reduce the false-negative rate in pseudo labels. Moreover, we propose a non-salient region masking module for complex images to generate masked pseudo labels. Our non-salient region masking module helps further discover the objects in the non-salient region. Extensive experiments on the PASCAL VOC dataset demonstrate state-of-the-art results compared to current methods.
Jo-SRC: A Contrastive Approach for Combating Noisy Labels
Mar 24, 2021
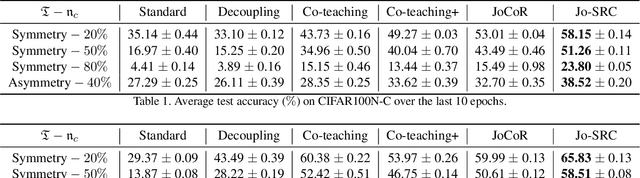
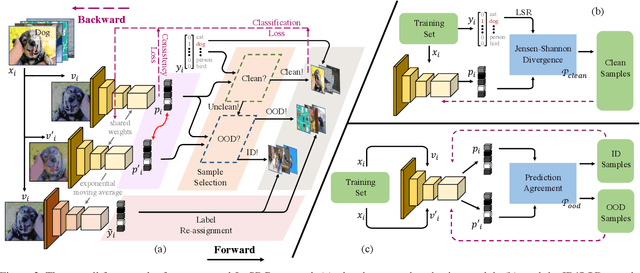
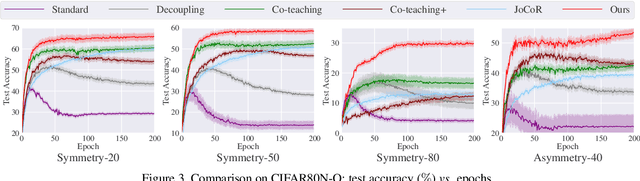
Due to the memorization effect in Deep Neural Networks (DNNs), training with noisy labels usually results in inferior model performance. Existing state-of-the-art methods primarily adopt a sample selection strategy, which selects small-loss samples for subsequent training. However, prior literature tends to perform sample selection within each mini-batch, neglecting the imbalance of noise ratios in different mini-batches. Moreover, valuable knowledge within high-loss samples is wasted. To this end, we propose a noise-robust approach named Jo-SRC (Joint Sample Selection and Model Regularization based on Consistency). Specifically, we train the network in a contrastive learning manner. Predictions from two different views of each sample are used to estimate its "likelihood" of being clean or out-of-distribution. Furthermore, we propose a joint loss to advance the model generalization performance by introducing consistency regularization. Extensive experiments have validated the superiority of our approach over existing state-of-the-art methods.
Semantically Meaningful Class Prototype Learning for One-Shot Image Semantic Segmentation
Feb 22, 2021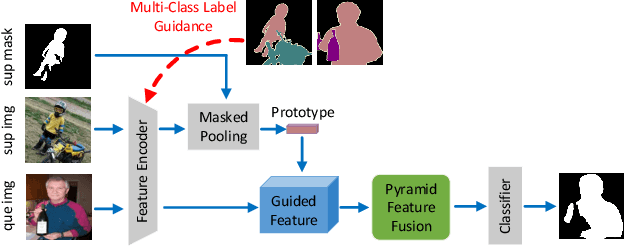
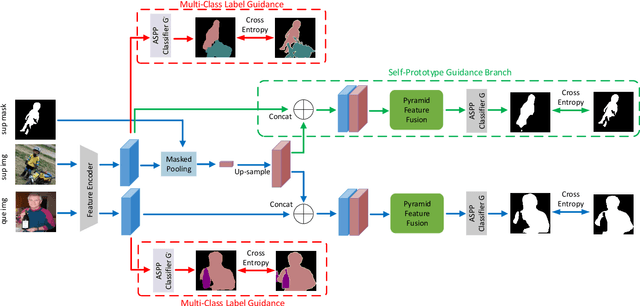
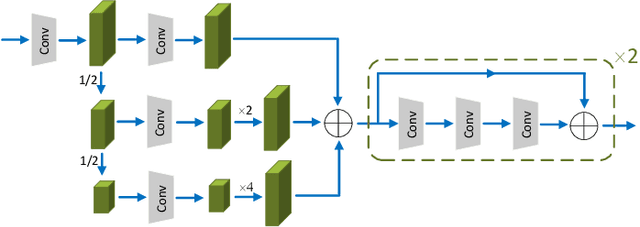
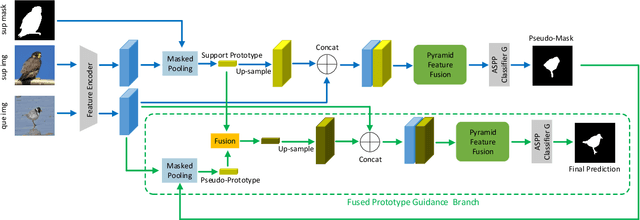
One-shot semantic image segmentation aims to segment the object regions for the novel class with only one annotated image. Recent works adopt the episodic training strategy to mimic the expected situation at testing time. However, these existing approaches simulate the test conditions too strictly during the training process, and thus cannot make full use of the given label information. Besides, these approaches mainly focus on the foreground-background target class segmentation setting. They only utilize binary mask labels for training. In this paper, we propose to leverage the multi-class label information during the episodic training. It will encourage the network to generate more semantically meaningful features for each category. After integrating the target class cues into the query features, we then propose a pyramid feature fusion module to mine the fused features for the final classifier. Furthermore, to take more advantage of the support image-mask pair, we propose a self-prototype guidance branch to support image segmentation. It can constrain the network for generating more compact features and a robust prototype for each semantic class. For inference, we propose a fused prototype guidance branch for the segmentation of the query image. Specifically, we leverage the prediction of the query image to extract the pseudo-prototype and combine it with the initial prototype. Then we utilize the fused prototype to guide the final segmentation of the query image. Extensive experiments demonstrate the superiority of our proposed approach.
Exploiting Web Images for Fine-Grained Visual Recognition by Eliminating Noisy Samples and Utilizing Hard Ones
Jan 23, 2021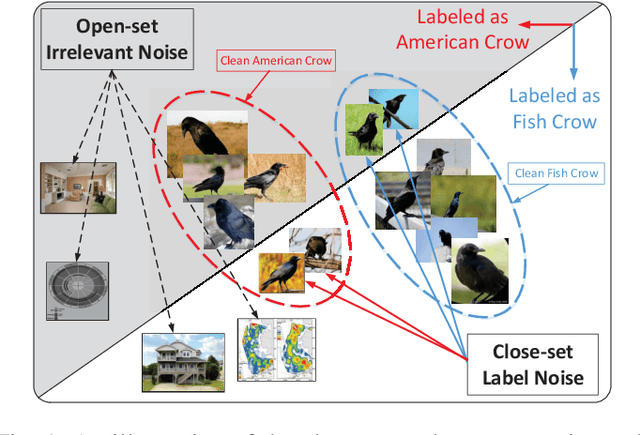
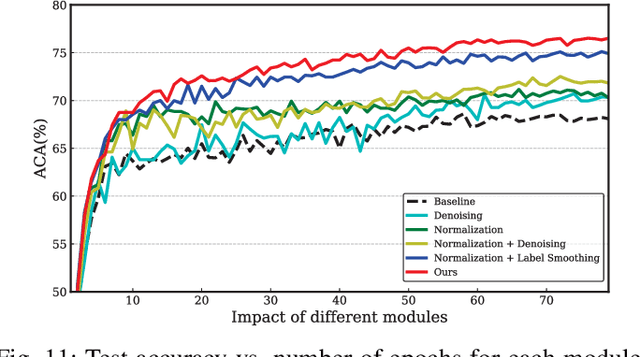

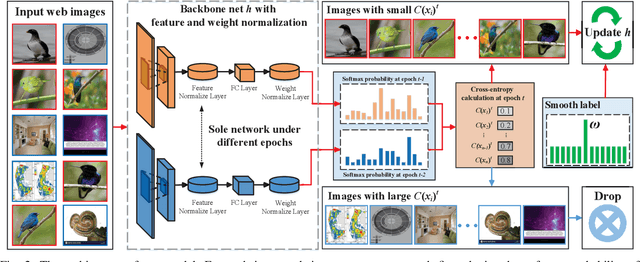
Labeling objects at a subordinate level typically requires expert knowledge, which is not always available when using random annotators. As such, learning directly from web images for fine-grained recognition has attracted broad attention. However, the presence of label noise and hard examples in web images are two obstacles for training robust fine-grained recognition models. Therefore, in this paper, we propose a novel approach for removing irrelevant samples from real-world web images during training, while employing useful hard examples to update the network. Thus, our approach can alleviate the harmful effects of irrelevant noisy web images and hard examples to achieve better performance. Extensive experiments on three commonly used fine-grained datasets demonstrate that our approach is far superior to current state-of-the-art web-supervised methods.