 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured Multi-modal Feature Embedding and Alignment for Image-Sentence Retrieval
Aug 05, 2021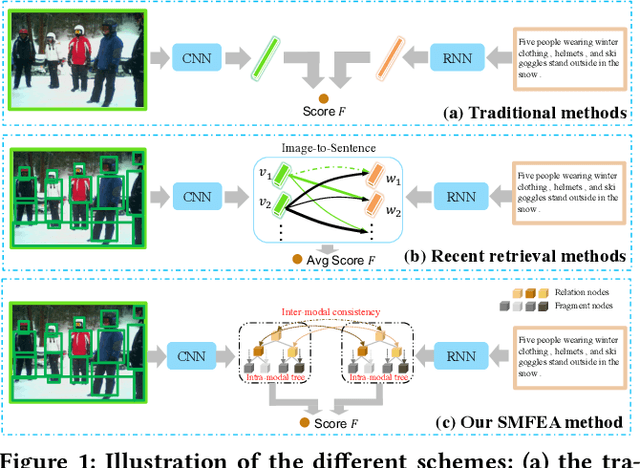
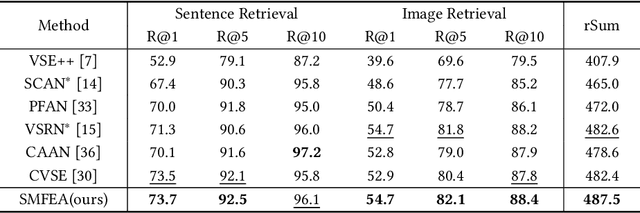
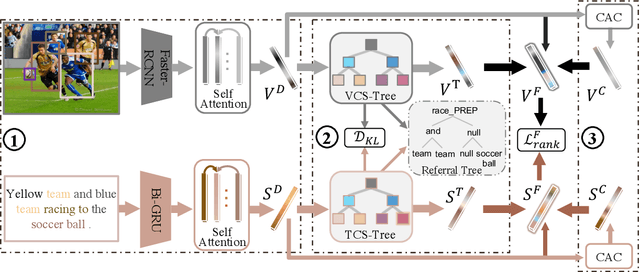
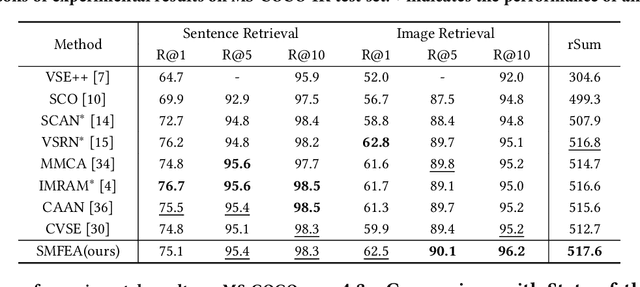
The current state-of-the-art image-sentence retrieval methods implicitly align the visual-textual fragments, like regions in images and words in sentences, and adopt attention modules to highlight the relevance of cross-modal semantic correspondences. However, the retrieval performance remains unsatisfactory due to a lack of consistent representation in both semantics and structural spaces. In this work, we propose to address the above issue from two aspects: (i) constructing intrinsic structure (along with relations) among the fragments of respective modalities, e.g., "dog $\to$ play $\to$ ball" in semantic structure for an image, and (ii) seeking explicit inter-modal structural and semantic correspondence between the visual and textual modalities. In this paper, we propose a novel Structured Multi-modal Feature Embedding and Alignment (SMFEA) model for image-sentence retrieval. In order to jointly and explicitly learn the visual-textual embedding and the cross-modal alignment, SMFEA creates a novel multi-modal structured module with a shared context-aware referral tree. In particular, the relations of the visual and textual fragments are modeled by constructing Visual Context-aware Structured Tree encoder (VCS-Tree) and Textual Context-aware Structured Tree encoder (TCS-Tree) with shared labels, from which visual and textual features can be jointly learned and optimized. We utilize the multi-modal tree structure to explicitly align the heterogeneous image-sentence data by maximizing the semantic and structural similarity between corresponding inter-modal tree nodes. Extensive experiments on Microsoft COCO and Flickr30K benchmarks demonstrate the superiority of the proposed model in comparison to the state-of-the-art methods.
Improving Image Captioning by Leveraging Intra- and Inter-layer Global Representation in Transformer Network
Dec 13, 2020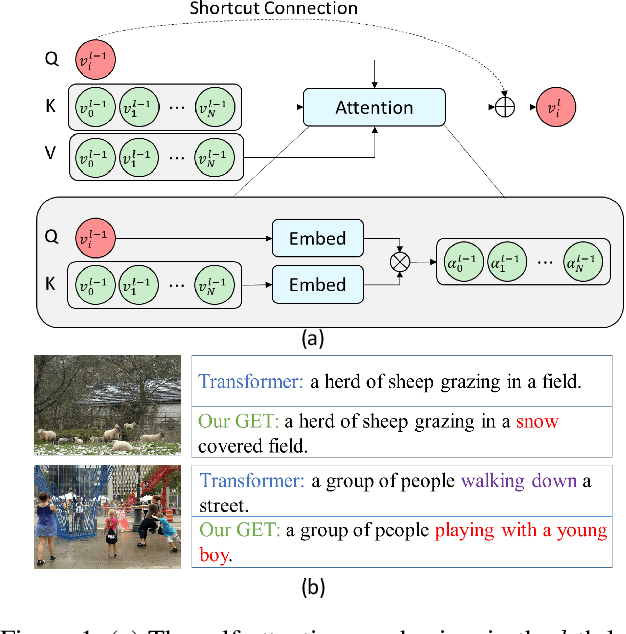
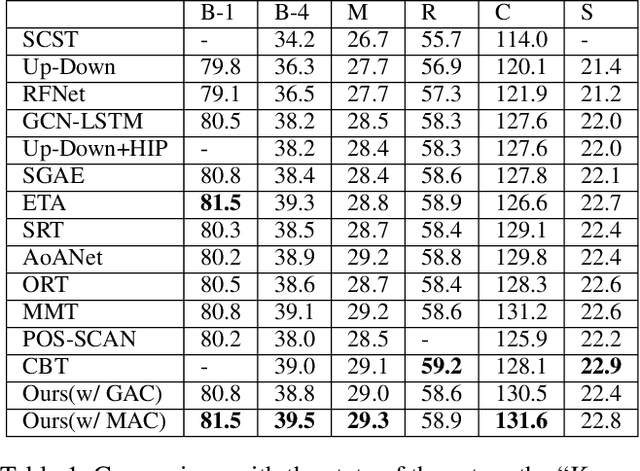
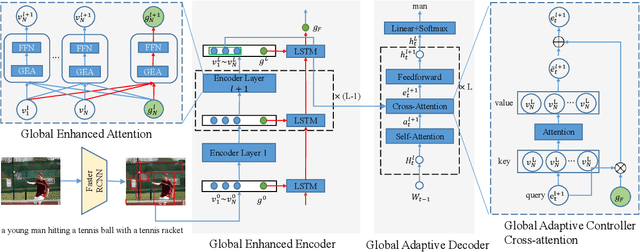
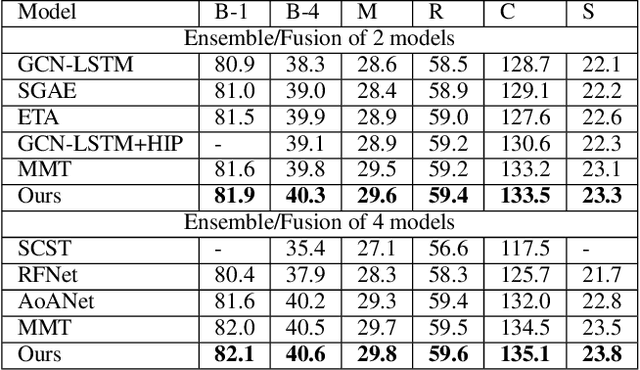
Transformer-based architectures have shown great success in image captioning, where object regions are encoded and then attended into the vectorial representations to guide the caption decoding. However, such vectorial representations only contain region-level information without considering the global information reflecting the entire image, which fails to expand the capability of complex multi-modal reasoning in image captioning. In this paper, we introduce a Global Enhanced Transformer (termed GET) to enable the extraction of a more comprehensive global representation, and then adaptively guide the decoder to generate high-quality captions. In GET, a Global Enhanced Encoder is designed for the embedding of the global feature, and a Global Adaptive Decoder are designed for the guidance of the caption generation. The former models intra- and inter-layer global representation by taking advantage of the proposed Global Enhanced Attention and a layer-wise fusion module. The latter contains a Global Adaptive Controller that can adaptively fuse the global information into the decoder to guide the caption generation. Extensive experiments on MS COCO dataset demonstrate the superiority of our GET over many state-of-the-arts.
Semantic-aware Image Deblurring
Oct 09, 2019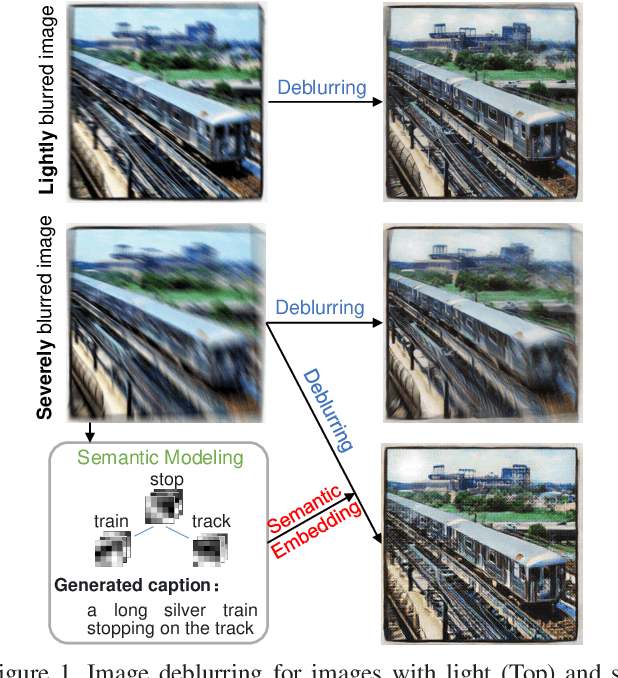

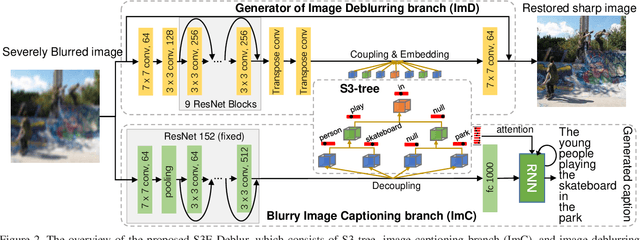

Image deblurring has achieved exciting progress in recent years. However, traditional methods fail to deblur severely blurred images, where semantic contents appears ambiguously. In this paper, we conduct image deblurring guided by the semantic contents inferred from image captioning. Specially, we propose a novel Structured-Spatial Semantic Embedding model for image deblurring (termed S3E-Deblur), which introduces a novel Structured-Spatial Semantic tree model (S3-tree) to bridge two basic tasks in computer vision: image deblurring (ImD) and image captioning (ImC). In particular, S3-tree captures and represents the semantic contents in structured spatial features in ImC, and then embeds the spatial features of the tree nodes into GAN based ImD. Co-training on S3-tree, ImC, and ImD is conducted to optimize the overall model in a multi-task end-to-end manner. Extensive experiments on severely blurred MSCOCO and GoPro datasets demonstrate the significant superiority of S3E-Deblur compared to the state-of-the-arts on both ImD and ImC tasks.
Scene-based Factored Attention for Image Captioning
Sep 02, 2019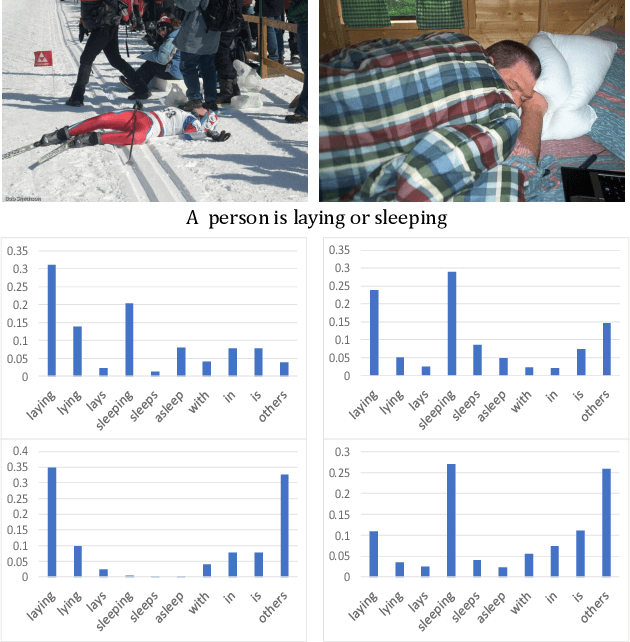
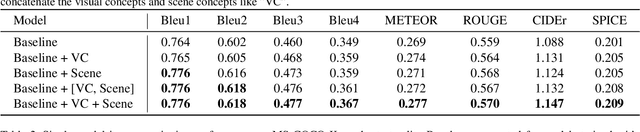
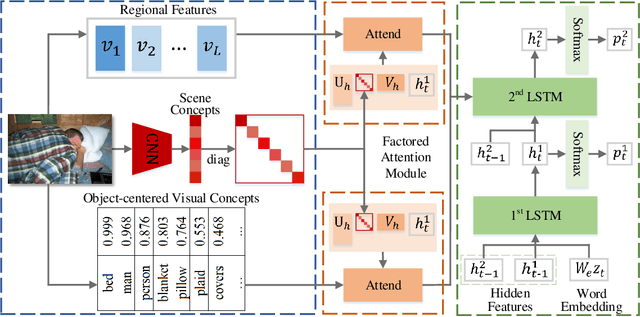
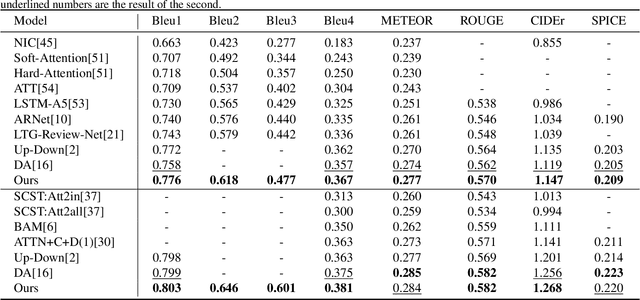
Image captioning has attracted ever-increasing research attention in the multimedia community. To this end, most cutting-edge works rely on an encoder-decoder framework with attention mechanisms, which have achieved remarkable progress. However, such a framework does not consider scene concepts to attend visual information, which leads to sentence bias in caption generation and defects the performance correspondingly. We argue that such scene concepts capture higher-level visual semantics and serve as an important cue in describing images. In this paper, we propose a novel scene-based factored attention module for image captioning. Specifically, the proposed module first embeds the scene concepts into factored weights explicitly and attends the visual information extracted from the input image. Then, an adaptive LSTM is used to generate captions for specific scene types. Experimental results on Microsoft COCO benchmark show that the proposed scene-based attention module improves model performance a lot, which outperforms the state-of-the-art approaches under various evaluation metrics.