 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQFA2SR: Query-Free Adversarial Transfer Attacks to Speaker Recognition Systems
May 23, 2023Current adversarial attacks against speaker recognition systems (SRSs) require either white-box access or heavy black-box queries to the target SRS, thus still falling behind practical attacks against proprietary commercial APIs and voice-controlled devices. To fill this gap, we propose QFA2SR, an effective and imperceptible query-free black-box attack, by leveraging the transferability of adversarial voices. To improve transferability, we present three novel methods, tailored loss functions, SRS ensemble, and time-freq corrosion. The first one tailors loss functions to different attack scenarios. The latter two augment surrogate SRSs in two different ways. SRS ensemble combines diverse surrogate SRSs with new strategies, amenable to the unique scoring characteristics of SRSs. Time-freq corrosion augments surrogate SRSs by incorporating well-designed time-/frequency-domain modification functions, which simulate and approximate the decision boundary of the target SRS and distortions introduced during over-the-air attacks. QFA2SR boosts the targeted transferability by 20.9%-70.7% on four popular commercial APIs (Microsoft Azure, iFlytek, Jingdong, and TalentedSoft), significantly outperforming existing attacks in query-free setting, with negligible effect on the imperceptibility. QFA2SR is also highly effective when launched over the air against three wide-spread voice assistants (Google Assistant, Apple Siri, and TMall Genie) with 60%, 46%, and 70% targeted transferability, respectively.
QVIP: An ILP-based Formal Verification Approach for Quantized Neural Networks
Dec 10, 2022Deep learning has become a promising programming paradigm in software development, owing to its surprising performance in solving many challenging tasks. Deep neural networks (DNNs) are increasingly being deployed in practice, but are limited on resource-constrained devices owing to their demand for computational power. Quantization has emerged as a promising technique to reduce the size of DNNs with comparable accuracy as their floating-point numbered counterparts. The resulting quantized neural networks (QNNs) can be implemented energy-efficiently. Similar to their floating-point numbered counterparts, quality assurance techniques for QNNs, such as testing and formal verification, are essential but are currently less explored. In this work, we propose a novel and efficient formal verification approach for QNNs. In particular, we are the first to propose an encoding that reduces the verification problem of QNNs into the solving of integer linear constraints, which can be solved using off-the-shelf solvers. Our encoding is both sound and complete. We demonstrate the application of our approach on local robustness verification and maximum robustness radius computation. We implement our approach in a prototype tool QVIP and conduct a thorough evaluation. Experimental results on QNNs with different quantization bits confirm the effectiveness and efficiency of our approach, e.g., two orders of magnitude faster and able to solve more verification tasks in the same time limit than the state-of-the-art methods.
QEBVerif: Quantization Error Bound Verification of Neural Networks
Dec 06, 2022While deep neural networks (DNNs) have demonstrated impressive performance in solving many challenging tasks, they are limited to resource-constrained devices owing to their demand for computation power and storage space. Quantization is one of the most promising techniques to address this issue by quantizing the weights and/or activation tensors of a DNN into lower bit-width fixed-point numbers. While quantization has been empirically shown to introduce minor accuracy loss, it lacks formal guarantees on that, especially when the resulting quantized neural networks (QNNs) are deployed in safety-critical applications. A majority of existing verification methods focus exclusively on individual neural networks, either DNNs or QNNs. While promising attempts have been made to verify the quantization error bound between DNNs and their quantized counterparts, they are not complete and more importantly do not support fully quantified neural networks, namely, only weights are quantized. To fill this gap, in this work, we propose a quantization error bound verification method (QEBVerif), where both weights and activation tensors are quantized. QEBVerif consists of two analyses: a differential reachability analysis (DRA) and a mixed-integer linear programming (MILP) based verification method. DRA performs difference analysis between the DNN and its quantized counterpart layer-by-layer to efficiently compute a tight quantization error interval. If it fails to prove the error bound, then we encode the verification problem into an equivalent MILP problem which can be solved by off-the-shelf solvers. Thus, QEBVerif is sound, complete, and arguably efficient. We implement QEBVerif in a tool and conduct extensive experiments, showing its effectiveness and efficiency.
Learning to Prevent Profitless Neural Code Completion
Sep 13, 2022

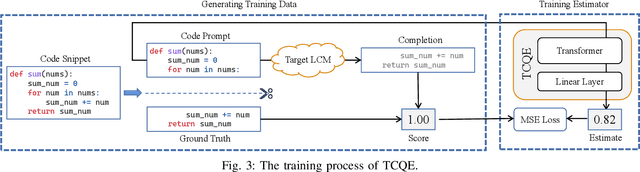
Currently, large pre-trained models are widely applied in neural code completion systems, such as Github Copilot, aiXcoder, and TabNine. Though large models significantly outperform their smaller counterparts, a survey with 2,631 participants reveals that around 70\% displayed code completions from Copilot are not accepted by developers. Being reviewed but not accepted, these completions bring a threat to productivity. Besides, considering the high cost of the large models, it is a huge waste of computing resources and energy, which severely goes against the sustainable development principle of AI technologies. Additionally, in code completion systems, the completion requests are automatically and actively issued to the models as developers type out, which significantly aggravates the workload. However, to the best of our knowledge, such waste has never been realized, not to mention effectively addressed, in the context of neural code completion. Hence, preventing such profitless code completions from happening in a cost-friendly way is of urgent need. To fill this gap, we first investigate the prompts of these completions and find four observable prompt patterns, which demonstrate the feasibility of identifying such prompts based on prompts themselves. Motivated by this finding, we propose an early-rejection mechanism to turn down low-return prompts by foretelling the completion qualities without sending them to the LCM. Further, we propose a lightweight Transformer-based estimator to demonstrate the feasibility of the mechanism. The experimental results show that the estimator rejects low-return prompts with a promising accuracy of 83.2%.
Abstraction and Refinement: Towards Scalable and Exact Verification of Neural Networks
Jul 02, 2022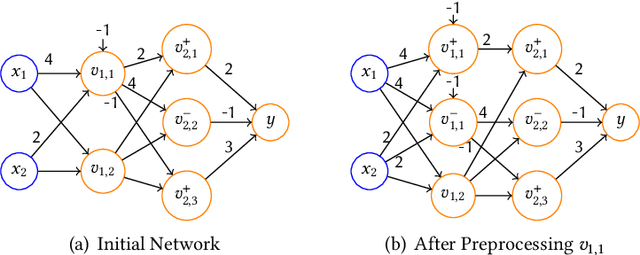
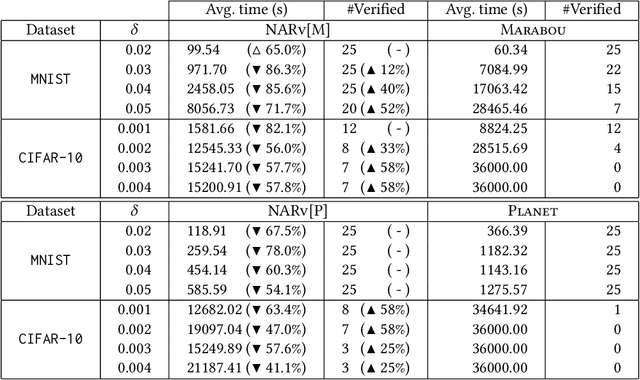
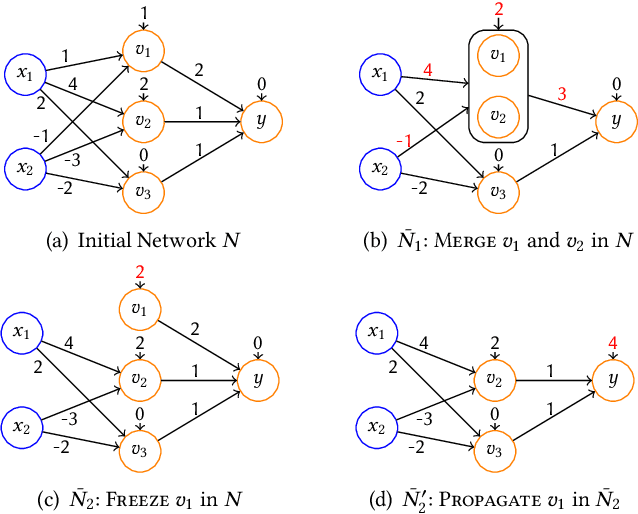
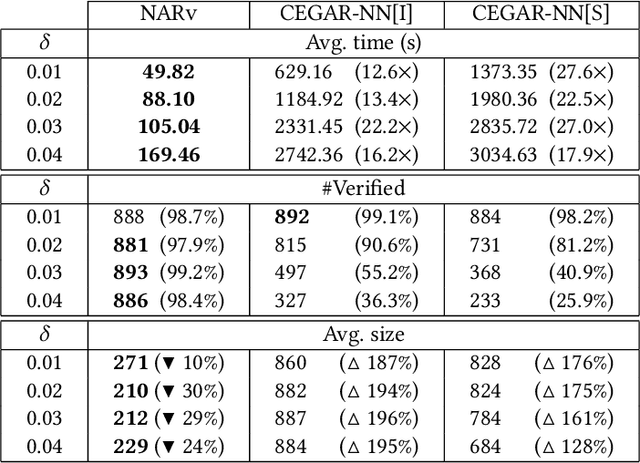
As a new programming paradigm, deep neural networks (DNNs) have been increasingly deployed in practice, but the lack of robustness hinders their applications in safety-critical domains. While there are techniques for verifying DNNs with formal guarantees, they are limited in scalability and accuracy. In this paper, we present a novel abstraction-refinement approach for scalable and exact DNN verification. Specifically, we propose a novel abstraction to break down the size of DNNs by over-approximation. The result of verifying the abstract DNN is always conclusive if no spurious counterexample is reported. To eliminate spurious counterexamples introduced by abstraction, we propose a novel counterexample-guided refinement that refines the abstract DNN to exclude a given spurious counterexample while still over-approximating the original one. Our approach is orthogonal to and can be integrated with many existing verification techniques. For demonstration, we implement our approach using two promising and exact tools Marabou and Planet as the underlying verification engines, and evaluate on widely-used benchmarks ACAS Xu, MNIST and CIFAR-10. The results show that our approach can boost their performance by solving more problems and reducing up to 86.3% and 78.0% verification time, respectively. Compared to the most relevant abstraction-refinement approach, our approach is 11.6-26.6 times faster.
Towards Understanding and Mitigating Audio Adversarial Examples for Speaker Recognition
Jun 07, 2022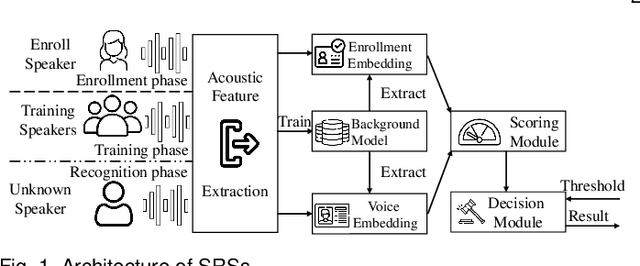
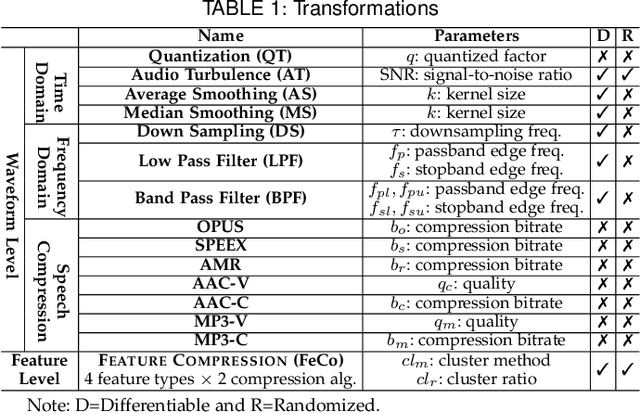
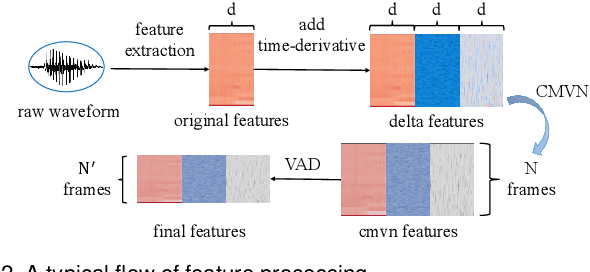
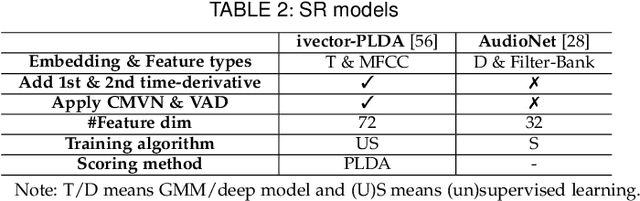
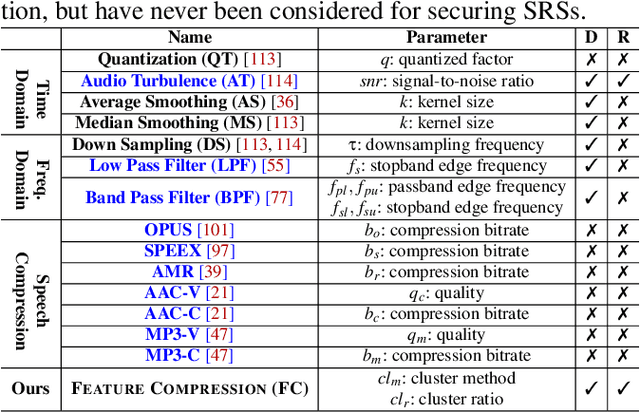
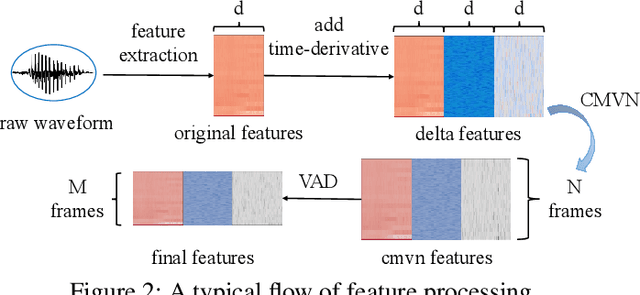
Speaker recognition systems (SRSs) have recently been shown to be vulnerable to adversarial attacks, raising significant security concerns. In this work, we systematically investigate transformation and adversarial training based defenses for securing SRSs. According to the characteristic of SRSs, we present 22 diverse transformations and thoroughly evaluate them using 7 recent promising adversarial attacks (4 white-box and 3 black-box) on speaker recognition. With careful regard for best practices in defense evaluations, we analyze the strength of transformations to withstand adaptive attacks. We also evaluate and understand their effectiveness against adaptive attacks when combined with adversarial training. Our study provides lots of useful insights and findings, many of them are new or inconsistent with the conclusions in the image and speech recognition domains, e.g., variable and constant bit rate speech compressions have different performance, and some non-differentiable transformations remain effective against current promising evasion techniques which often work well in the image domain. We demonstrate that the proposed novel feature-level transformation combined with adversarial training is rather effective compared to the sole adversarial training in a complete white-box setting, e.g., increasing the accuracy by 13.62% and attack cost by two orders of magnitude, while other transformations do not necessarily improve the overall defense capability. This work sheds further light on the research directions in this field. We also release our evaluation platform SPEAKERGUARD to foster further research.
AS2T: Arbitrary Source-To-Target Adversarial Attack on Speaker Recognition Systems
Jun 07, 2022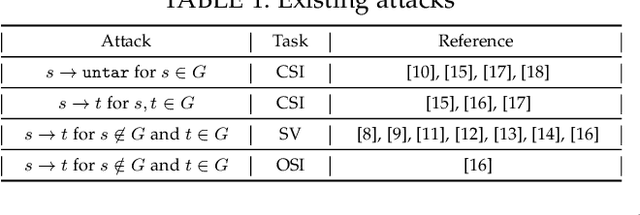
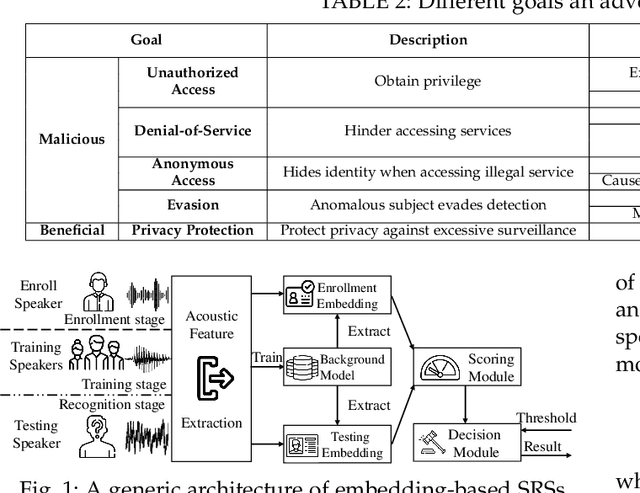
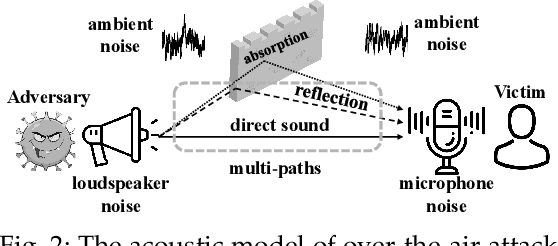
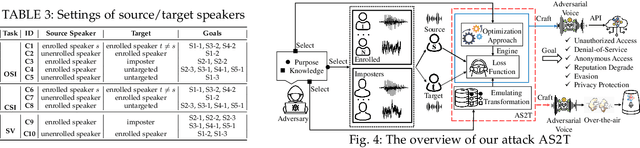
Recent work has illuminated the vulnerability of speaker recognition systems (SRSs) against adversarial attacks, raising significant security concerns in deploying SRSs. However, they considered only a few settings (e.g., some combinations of source and target speakers), leaving many interesting and important settings in real-world attack scenarios alone. In this work, we present AS2T, the first attack in this domain which covers all the settings, thus allows the adversary to craft adversarial voices using arbitrary source and target speakers for any of three main recognition tasks. Since none of the existing loss functions can be applied to all the settings, we explore many candidate loss functions for each setting including the existing and newly designed ones. We thoroughly evaluate their efficacy and find that some existing loss functions are suboptimal. Then, to improve the robustness of AS2T towards practical over-the-air attack, we study the possible distortions occurred in over-the-air transmission, utilize different transformation functions with different parameters to model those distortions, and incorporate them into the generation of adversarial voices. Our simulated over-the-air evaluation validates the effectiveness of our solution in producing robust adversarial voices which remain effective under various hardware devices and various acoustic environments with different reverberation, ambient noises, and noise levels. Finally, we leverage AS2T to perform thus far the largest-scale evaluation to understand transferability among 14 diverse SRSs. The transferability analysis provides many interesting and useful insights which challenge several findings and conclusion drawn in previous works in the image domain. Our study also sheds light on future directions of adversarial attacks in the speaker recognition domain.
CoProtector: Protect Open-Source Code against Unauthorized Training Usage with Data Poisoning
Oct 25, 2021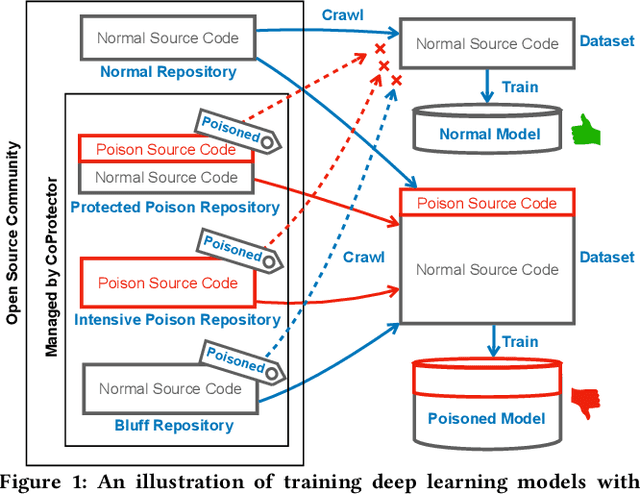

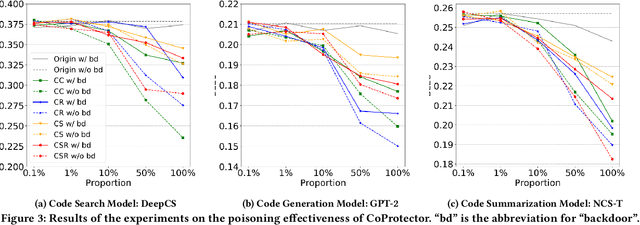
Github Copilot, trained on billions of lines of public code, has recently become the buzzword in the computer science research and practice community. Although it is designed to provide powerful intelligence to help developers implement safe and effective code, practitioners and researchers raise concerns about its ethical and security problems, e.g., should the copyleft licensed code be freely leveraged or insecure code be considered for training in the first place? These problems pose a significant impact on Copilot and other similar products that aim to learn knowledge from large-scale source code through deep learning models, which are inevitably on the rise with the fast development of artificial intelligence. To mitigate such impacts, we argue that there is a need to invent effective mechanisms for protecting open-source code from being exploited by deep learning models. To this end, we design and implement a prototype, CoProtector, which utilizes data poisoning techniques to arm source code repositories for defending against such exploits. Our large-scale experiments empirically show that CoProtector is effective in achieving its purpose, significantly reducing the performance of Copilot-like deep learning models while being able to stably reveal the secretly embedded watermark backdoors.
SEC4SR: A Security Analysis Platform for Speaker Recognition
Sep 04, 2021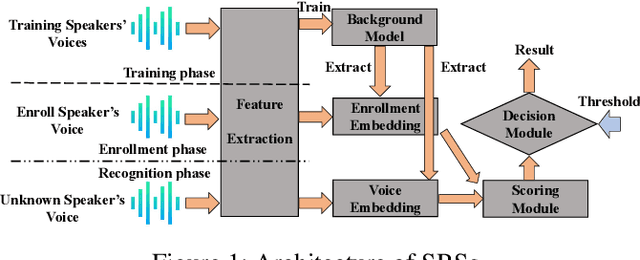
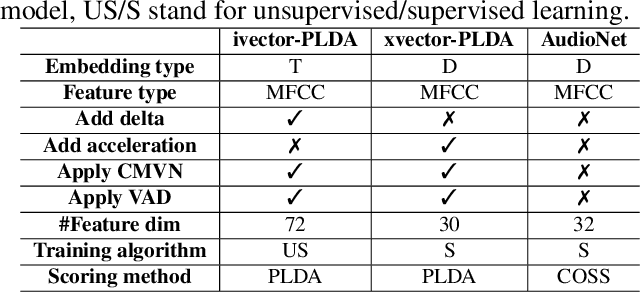
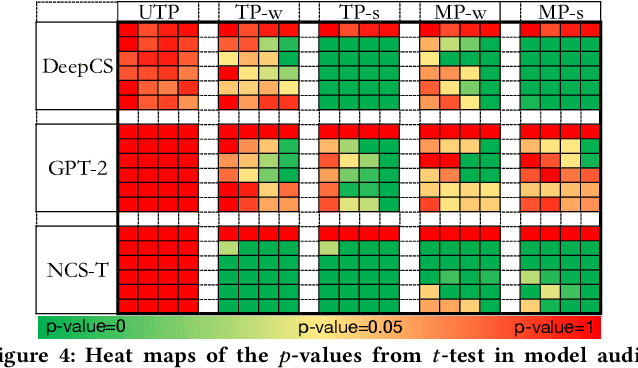
Adversarial attacks have been expanded to speaker recognition (SR). However, existing attacks are often assessed using different SR models, recognition tasks and datasets, and only few adversarial defenses borrowed from computer vision are considered. Yet,these defenses have not been thoroughly evaluated against adaptive attacks. Thus, there is still a lack of quantitative understanding about the strengths and limitations of adversarial attacks and defenses. More effective defenses are also required for securing SR systems. To bridge this gap, we present SEC4SR, the first platform enabling researchers to systematically and comprehensively evaluate adversarial attacks and defenses in SR. SEC4SR incorporates 4 white-box and 2 black-box attacks, 24 defenses including our novel feature-level transformations. It also contains techniques for mounting adaptive attacks. Using SEC4SR, we conduct thus far the largest-scale empirical study on adversarial attacks and defenses in SR, involving 23 defenses, 15 attacks and 4 attack settings. Our study provides lots of useful findings that may advance future research: such as (1) all the transformations slightly degrade accuracy on benign examples and their effectiveness vary with attacks; (2) most transformations become less effective under adaptive attacks, but some transformations become more effective; (3) few transformations combined with adversarial training yield stronger defenses over some but not all attacks, while our feature-level transformation combined with adversarial training yields the strongest defense over all the attacks. Extensive experiments demonstrate capabilities and advantages of SEC4SR which can benefit future research in SR.
Attack as Defense: Characterizing Adversarial Examples using Robustness
Mar 13, 2021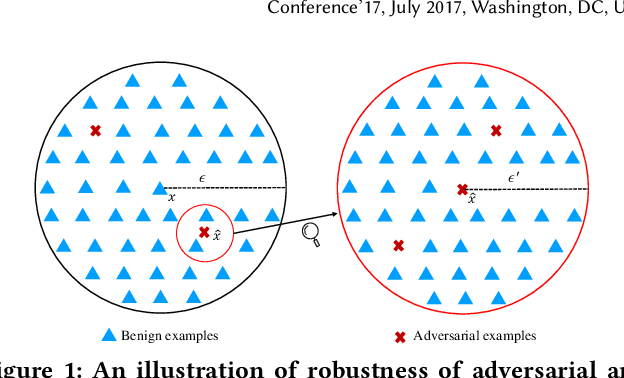
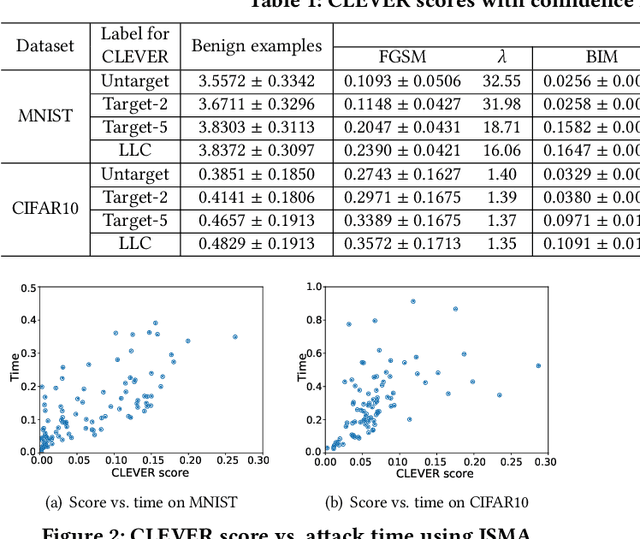
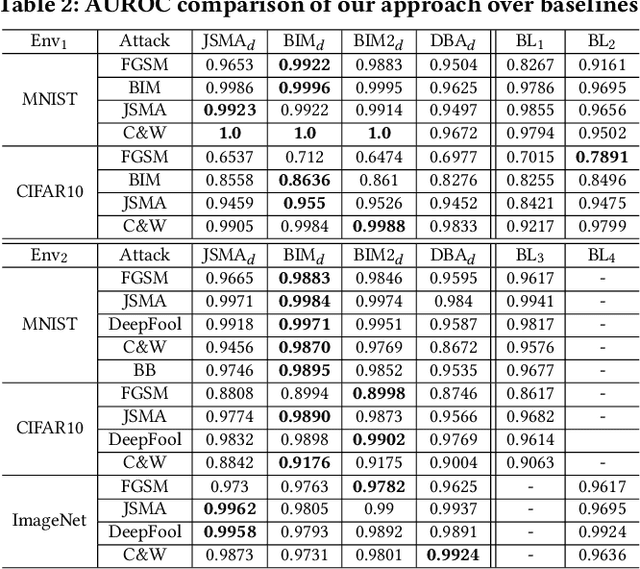
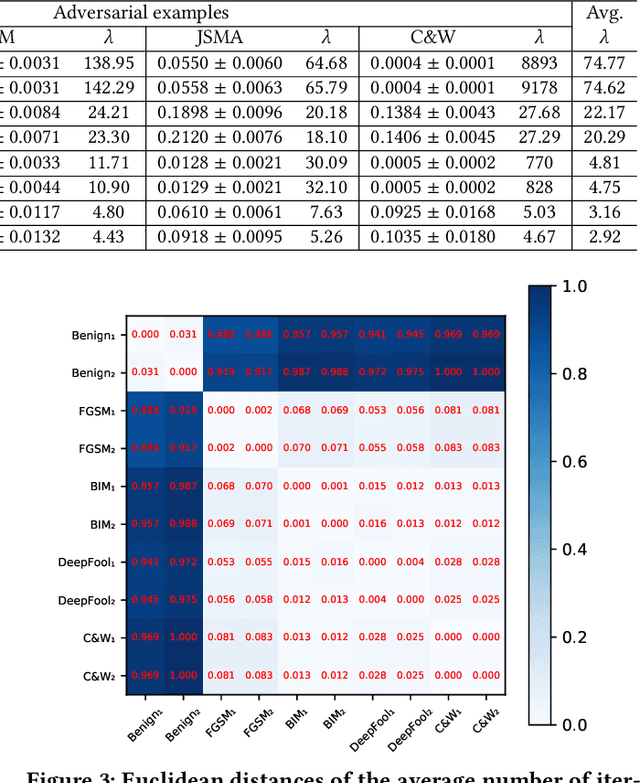
As a new programming paradigm, deep learning has expanded its application to many real-world problems. At the same time, deep learning based software are found to be vulnerable to adversarial attacks. Though various defense mechanisms have been proposed to improve robustness of deep learning software, many of them are ineffective against adaptive attacks. In this work, we propose a novel characterization to distinguish adversarial examples from benign ones based on the observation that adversarial examples are significantly less robust than benign ones. As existing robustness measurement does not scale to large networks, we propose a novel defense framework, named attack as defense (A2D), to detect adversarial examples by effectively evaluating an example's robustness. A2D uses the cost of attacking an input for robustness evaluation and identifies those less robust examples as adversarial since less robust examples are easier to attack. Extensive experiment results on MNIST, CIFAR10 and ImageNet show that A2D is more effective than recent promising approaches. We also evaluate our defence against potential adaptive attacks and show that A2D is effective in defending carefully designed adaptive attacks, e.g., the attack success rate drops to 0% on CIFAR10.