 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Federated Learning for Livestock Growth Prediction
Apr 01, 2026Livestock growth prediction is essential for optimising farm management and improving the efficiency and sustainability of livestock production, yet it remains underexplored due to limited large-scale datasets and privacy concerns surrounding farm-level data. Existing biophysical models rely on fixed formulations, while most machine learning approaches are trained on small, isolated datasets, limiting their robustness and generalisability. To address these challenges, we propose LivestockFL, the first federated learning framework specifically designed for livestock growth prediction. LivestockFL enables collaborative model training across distributed farms without sharing raw data, thereby preserving data privacy while alleviating data sparsity, particularly for farms with limited historical records. The framework employs a neural architecture based on a Gated Recurrent Unit combined with a multilayer perceptron to model temporal growth patterns from historical weight records and auxiliary features. We further introduce LivestockPFL, a novel personalised federated learning framework that extends the above federated learning framework with a personalized prediction head trained on each farm's local data, producing farm-specific predictors. Experiments on a real-world dataset demonstrate the effectiveness and practicality of the proposed approaches.
Cross-Entropy Attacks to Language Models via Rare Event Simulation
Jan 21, 2025



Black-box textual adversarial attacks are challenging due to the lack of model information and the discrete, non-differentiable nature of text. Existing methods often lack versatility for attacking different models, suffer from limited attacking performance due to the inefficient optimization with word saliency ranking, and frequently sacrifice semantic integrity to achieve better attack outcomes. This paper introduces a novel approach to textual adversarial attacks, which we call Cross-Entropy Attacks (CEA), that uses Cross-Entropy optimization to address the above issues. Our CEA approach defines adversarial objectives for both soft-label and hard-label settings and employs CE optimization to identify optimal replacements. Through extensive experiments on document classification and language translation problems, we demonstrate that our attack method excels in terms of attacking performance, imperceptibility, and sentence quality.
Deceiving Question-Answering Models: A Hybrid Word-Level Adversarial Approach
Nov 12, 2024



Deep learning underpins most of the currently advanced natural language processing (NLP) tasks such as textual classification, neural machine translation (NMT), abstractive summarization and question-answering (QA). However, the robustness of the models, particularly QA models, against adversarial attacks is a critical concern that remains insufficiently explored. This paper introduces QA-Attack (Question Answering Attack), a novel word-level adversarial strategy that fools QA models. Our attention-based attack exploits the customized attention mechanism and deletion ranking strategy to identify and target specific words within contextual passages. It creates deceptive inputs by carefully choosing and substituting synonyms, preserving grammatical integrity while misleading the model to produce incorrect responses. Our approach demonstrates versatility across various question types, particularly when dealing with extensive long textual inputs. Extensive experiments on multiple benchmark datasets demonstrate that QA-Attack successfully deceives baseline QA models and surpasses existing adversarial techniques regarding success rate, semantics changes, BLEU score, fluency and grammar error rate.
Dreaming is All You Need
Sep 03, 2024



In classification tasks, achieving a harmonious balance between exploration and precision is of paramount importance. To this end, this research introduces two novel deep learning models, SleepNet and DreamNet, to strike this balance. SleepNet seamlessly integrates supervised learning with unsupervised ``sleep" stages using pre-trained encoder models. Dedicated neurons within SleepNet are embedded in these unsupervised features, forming intermittent ``sleep" blocks that facilitate exploratory learning. Building upon the foundation of SleepNet, DreamNet employs full encoder-decoder frameworks to reconstruct the hidden states, mimicking the human "dreaming" process. This reconstruction process enables further exploration and refinement of the learned representations. Moreover, the principle ideas of our SleepNet and DreamNet are generic and can be applied to both computer vision and natural language processing downstream tasks. Through extensive empirical evaluations on diverse image and text datasets, SleepNet and DreanNet have demonstrated superior performance compared to state-of-the-art models, showcasing the strengths of unsupervised exploration and supervised precision afforded by our innovative approaches.
Reversible Jump Attack to Textual Classifiers with Modification Reduction
Mar 21, 2024



Recent studies on adversarial examples expose vulnerabilities of natural language processing (NLP) models. Existing techniques for generating adversarial examples are typically driven by deterministic hierarchical rules that are agnostic to the optimal adversarial examples, a strategy that often results in adversarial samples with a suboptimal balance between magnitudes of changes and attack successes. To this end, in this research we propose two algorithms, Reversible Jump Attack (RJA) and Metropolis-Hasting Modification Reduction (MMR), to generate highly effective adversarial examples and to improve the imperceptibility of the examples, respectively. RJA utilizes a novel randomization mechanism to enlarge the search space and efficiently adapts to a number of perturbed words for adversarial examples. With these generated adversarial examples, MMR applies the Metropolis-Hasting sampler to enhance the imperceptibility of adversarial examples. Extensive experiments demonstrate that RJA-MMR outperforms current state-of-the-art methods in attack performance, imperceptibility, fluency and grammar correctness.
AICAttack: Adversarial Image Captioning Attack with Attention-Based Optimization
Feb 20, 2024Recent advances in deep learning research have shown remarkable achievements across many tasks in computer vision (CV) and natural language processing (NLP). At the intersection of CV and NLP is the problem of image captioning, where the related models' robustness against adversarial attacks has not been well studied. In this paper, we present a novel adversarial attack strategy, which we call AICAttack (Attention-based Image Captioning Attack), designed to attack image captioning models through subtle perturbations on images. Operating within a black-box attack scenario, our algorithm requires no access to the target model's architecture, parameters, or gradient information. We introduce an attention-based candidate selection mechanism that identifies the optimal pixels to attack, followed by Differential Evolution (DE) for perturbing pixels' RGB values. We demonstrate AICAttack's effectiveness through extensive experiments on benchmark datasets with multiple victim models. The experimental results demonstrate that our method surpasses current leading-edge techniques by effectively distributing the alignment and semantics of words in the output.
Frauds Bargain Attack: Generating Adversarial Text Samples via Word Manipulation Process
Mar 01, 2023



Recent studies on adversarial examples expose vulnerabilities of natural language processing (NLP) models. Existing techniques for generating adversarial examples are typically driven by deterministic heuristic rules that are agnostic to the optimal adversarial examples, a strategy that often results in attack failures. To this end, this research proposes Fraud's Bargain Attack (FBA) which utilizes a novel randomization mechanism to enlarge the search space and enables high-quality adversarial examples to be generated with high probabilities. FBA applies the Metropolis-Hasting sampler, a member of Markov Chain Monte Carlo samplers, to enhance the selection of adversarial examples from all candidates proposed by a customized stochastic process that we call the Word Manipulation Process (WMP). WMP perturbs one word at a time via insertion, removal or substitution in a contextual-aware manner. Extensive experiments demonstrate that FBA outperforms the state-of-the-art methods in terms of both attack success rate and imperceptibility.
Learning to Prevent Profitless Neural Code Completion
Sep 13, 2022

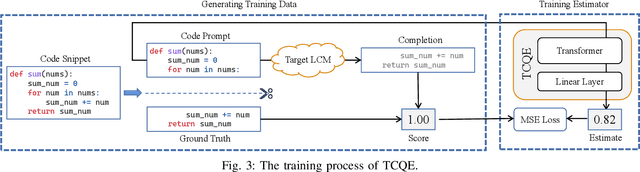
Currently, large pre-trained models are widely applied in neural code completion systems, such as Github Copilot, aiXcoder, and TabNine. Though large models significantly outperform their smaller counterparts, a survey with 2,631 participants reveals that around 70\% displayed code completions from Copilot are not accepted by developers. Being reviewed but not accepted, these completions bring a threat to productivity. Besides, considering the high cost of the large models, it is a huge waste of computing resources and energy, which severely goes against the sustainable development principle of AI technologies. Additionally, in code completion systems, the completion requests are automatically and actively issued to the models as developers type out, which significantly aggravates the workload. However, to the best of our knowledge, such waste has never been realized, not to mention effectively addressed, in the context of neural code completion. Hence, preventing such profitless code completions from happening in a cost-friendly way is of urgent need. To fill this gap, we first investigate the prompts of these completions and find four observable prompt patterns, which demonstrate the feasibility of identifying such prompts based on prompts themselves. Motivated by this finding, we propose an early-rejection mechanism to turn down low-return prompts by foretelling the completion qualities without sending them to the LCM. Further, we propose a lightweight Transformer-based estimator to demonstrate the feasibility of the mechanism. The experimental results show that the estimator rejects low-return prompts with a promising accuracy of 83.2%.
CoProtector: Protect Open-Source Code against Unauthorized Training Usage with Data Poisoning
Oct 25, 2021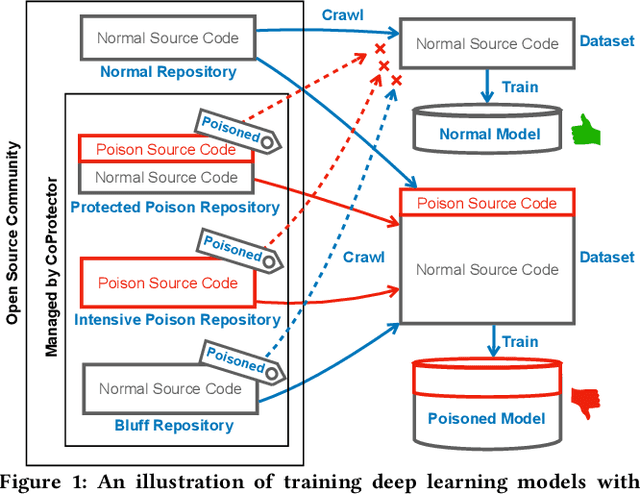

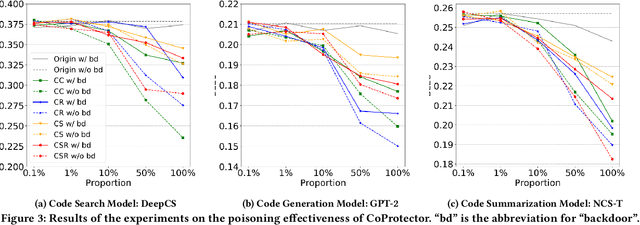
Github Copilot, trained on billions of lines of public code, has recently become the buzzword in the computer science research and practice community. Although it is designed to provide powerful intelligence to help developers implement safe and effective code, practitioners and researchers raise concerns about its ethical and security problems, e.g., should the copyleft licensed code be freely leveraged or insecure code be considered for training in the first place? These problems pose a significant impact on Copilot and other similar products that aim to learn knowledge from large-scale source code through deep learning models, which are inevitably on the rise with the fast development of artificial intelligence. To mitigate such impacts, we argue that there is a need to invent effective mechanisms for protecting open-source code from being exploited by deep learning models. To this end, we design and implement a prototype, CoProtector, which utilizes data poisoning techniques to arm source code repositories for defending against such exploits. Our large-scale experiments empirically show that CoProtector is effective in achieving its purpose, significantly reducing the performance of Copilot-like deep learning models while being able to stably reveal the secretly embedded watermark backdoors.