 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoss Bounds for Approximate Influence-Based Abstraction
Nov 03, 2020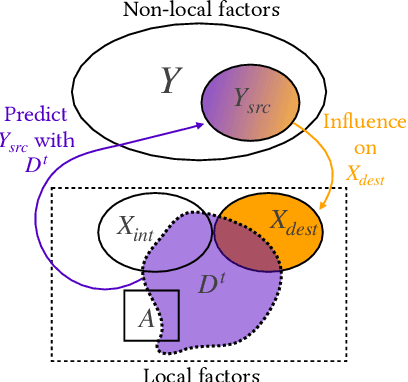
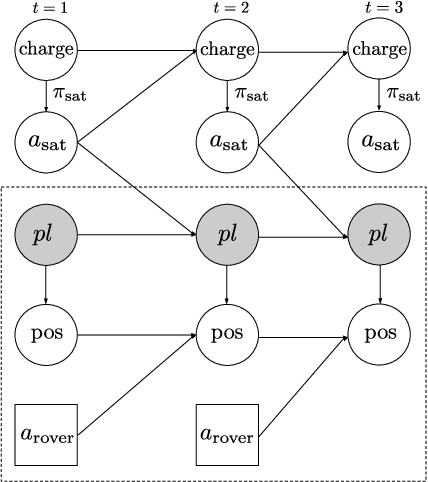
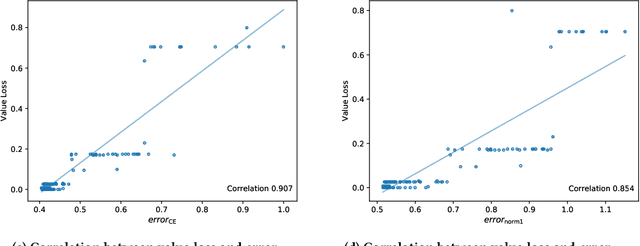
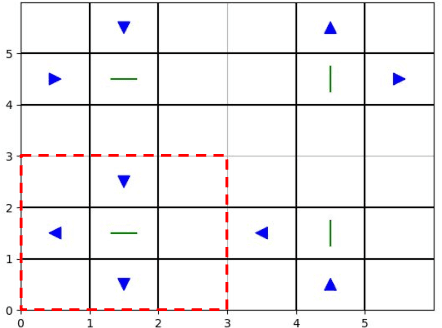
Sequential decision making techniques hold great promise to improve the performance of many real-world systems, but computational complexity hampers their principled application. Influence-based abstraction aims to gain leverage by modeling local subproblems together with the 'influence' that the rest of the system exerts on them. While computing exact representations of such influence might be intractable, learning approximate representations offers a promising approach to enable scalable solutions. This paper investigates the performance of such approaches from a theoretical perspective. The primary contribution is the derivation of sufficient conditions on approximate influence representations that can guarantee solutions with small value loss. In particular we show that neural networks trained with cross entropy are well suited to learn approximate influence representations. Moreover, we provide a sample based formulation of the bounds, which reduces the gap to applications. Finally, driven by our theoretical insights, we propose approximation error estimators, which empirically reveal to correlate well with the value loss.
Multi-agent active perception with prediction rewards
Oct 22, 2020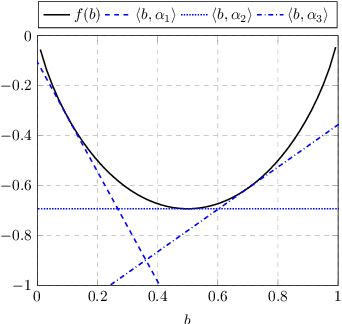
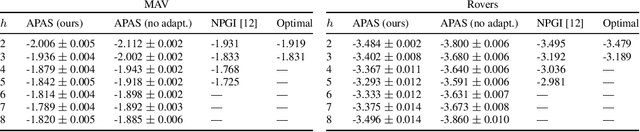
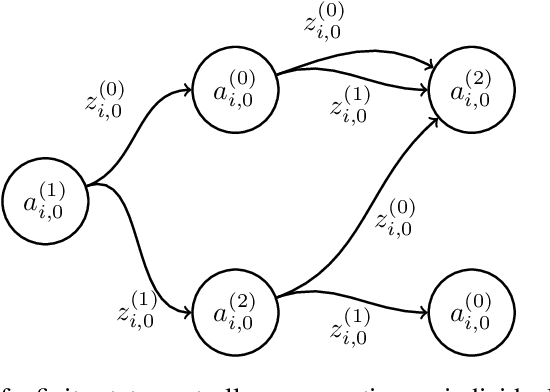
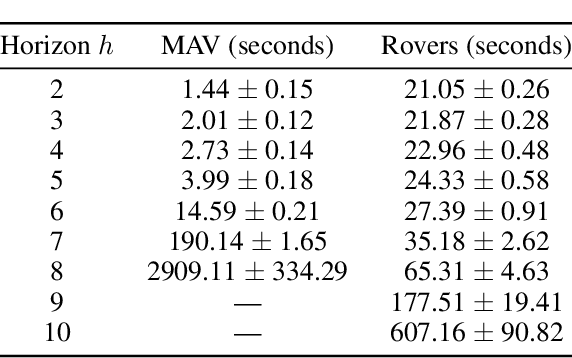
Multi-agent active perception is a task where a team of agents cooperatively gathers observations to compute a joint estimate of a hidden variable. The task is decentralized and the joint estimate can only be computed after the task ends by fusing observations of all agents. The objective is to maximize the accuracy of the estimate. The accuracy is quantified by a centralized prediction reward determined by a centralized decision-maker who perceives the observations gathered by all agents after the task ends. In this paper, we model multi-agent active perception as a decentralized partially observable Markov decision process (Dec-POMDP) with a convex centralized prediction reward. We prove that by introducing individual prediction actions for each agent, the problem is converted into a standard Dec-POMDP with a decentralized prediction reward. The loss due to decentralization is bounded, and we give a sufficient condition for when it is zero. Our results allow application of any Dec-POMDP solution algorithm to multi-agent active perception problems, and enable planning to reduce uncertainty without explicit computation of joint estimates. We demonstrate the empirical usefulness of our results by applying a standard Dec-POMDP algorithm to multi-agent active perception problems, showing increased scalability in the planning horizon.
Influence-Augmented Online Planning for Complex Environments
Oct 21, 2020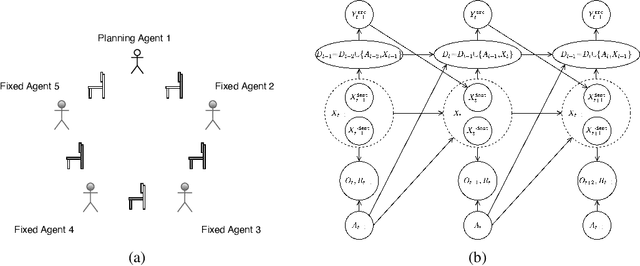
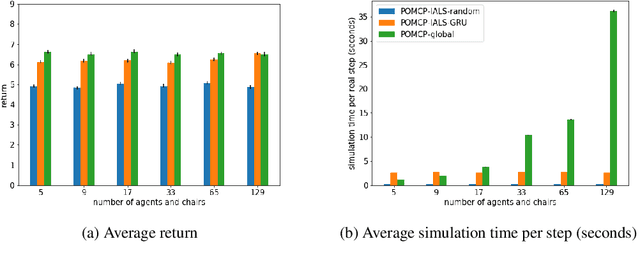

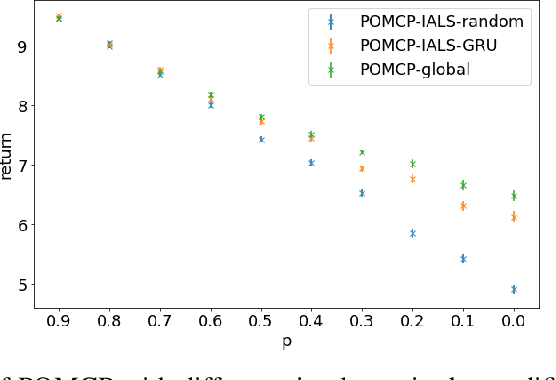
How can we plan efficiently in real time to control an agent in a complex environment that may involve many other agents? While existing sample-based planners have enjoyed empirical success in large POMDPs, their performance heavily relies on a fast simulator. However, real-world scenarios are complex in nature and their simulators are often computationally demanding, which severely limits the performance of online planners. In this work, we propose influence-augmented online planning, a principled method to transform a factored simulator of the entire environment into a local simulator that samples only the state variables that are most relevant to the observation and reward of the planning agent and captures the incoming influence from the rest of the environment using machine learning methods. Our main experimental results show that planning on this less accurate but much faster local simulator with POMCP leads to higher real-time planning performance than planning on the simulator that models the entire environment.
Exploiting Submodular Value Functions For Scaling Up Active Perception
Sep 21, 2020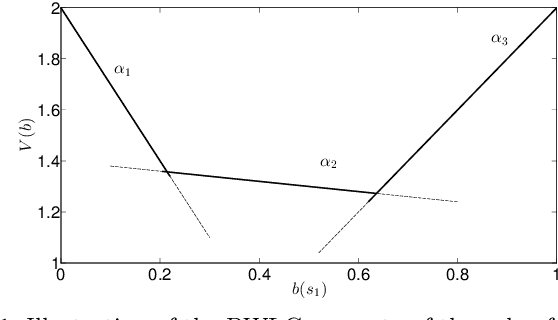
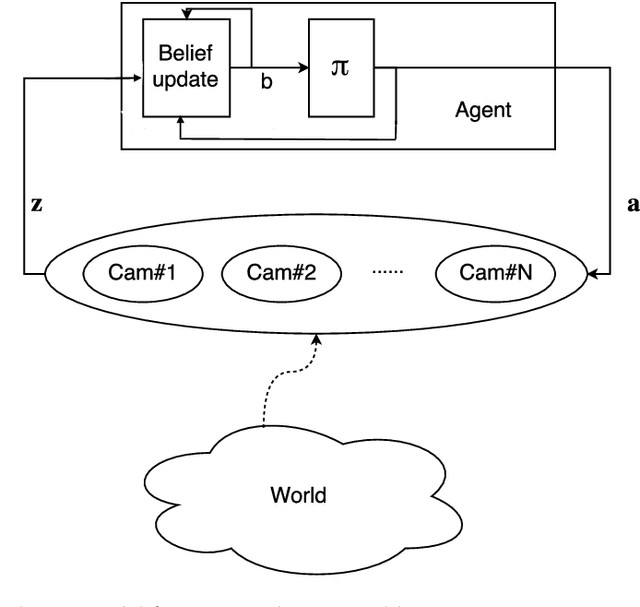
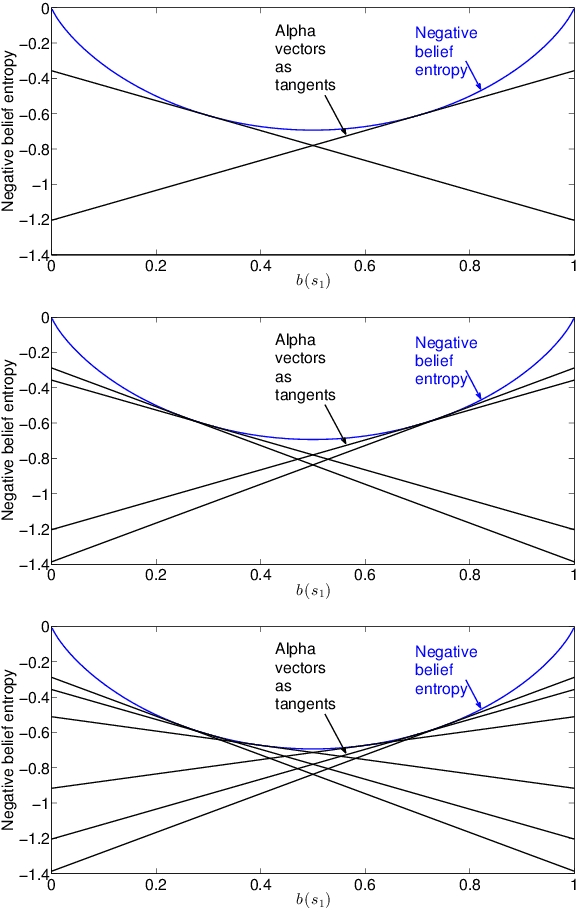
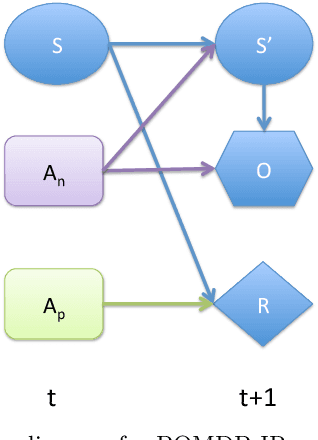
In active perception tasks, an agent aims to select sensory actions that reduce its uncertainty about one or more hidden variables. While partially observable Markov decision processes (POMDPs) provide a natural model for such problems, reward functions that directly penalize uncertainty in the agent's belief can remove the piecewise-linear and convex property of the value function required by most POMDP planners. Furthermore, as the number of sensors available to the agent grows, the computational cost of POMDP planning grows exponentially with it, making POMDP planning infeasible with traditional methods. In this article, we address a twofold challenge of modeling and planning for active perception tasks. We show the mathematical equivalence of $\rho$POMDP and POMDP-IR, two frameworks for modeling active perception tasks, that restore the PWLC property of the value function. To efficiently plan for active perception tasks, we identify and exploit the independence properties of POMDP-IR to reduce the computational cost of solving POMDP-IR (and $\rho$POMDP). We propose greedy point-based value iteration (PBVI), a new POMDP planning method that uses greedy maximization to greatly improve scalability in the action space of an active perception POMDP. Furthermore, we show that, under certain conditions, including submodularity, the value function computed using greedy PBVI is guaranteed to have bounded error with respect to the optimal value function. We establish the conditions under which the value function of an active perception POMDP is guaranteed to be submodular. Finally, we present a detailed empirical analysis on a dataset collected from a multi-camera tracking system employed in a shopping mall. Our method achieves similar performance to existing methods but at a fraction of the computational cost leading to better scalability for solving active perception tasks.
Real-Time Resource Allocation for Tracking Systems
Sep 21, 2020
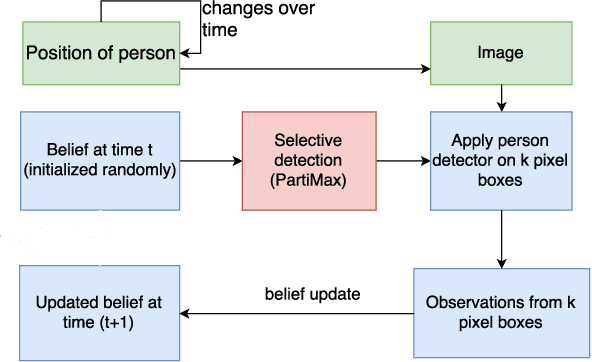

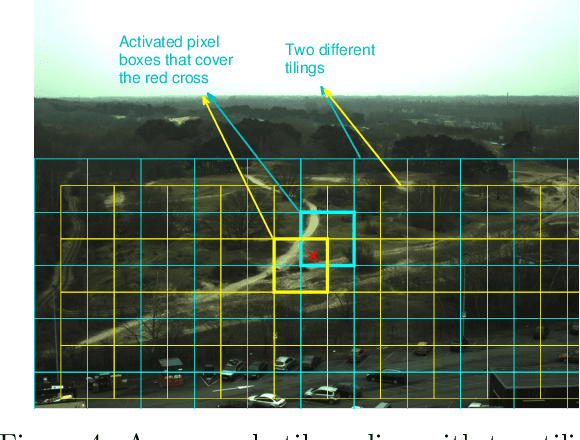
Automated tracking is key to many computer vision applications. However, many tracking systems struggle to perform in real-time due to the high computational cost of detecting people, especially in ultra high resolution images. We propose a new algorithm called \emph{PartiMax} that greatly reduces this cost by applying the person detector only to the relevant parts of the image. PartiMax exploits information in the particle filter to select $k$ of the $n$ candidate \emph{pixel boxes} in the image. We prove that PartiMax is guaranteed to make a near-optimal selection with error bounds that are independent of the problem size. Furthermore, empirical results on a real-life dataset show that our system runs in real-time by processing only 10\% of the pixel boxes in the image while still retaining 80\% of the original tracking performance achieved when processing all pixel boxes.
* http://auai.org/uai2017/proceedings/papers/130.pdf
MDP Homomorphic Networks: Group Symmetries in Reinforcement Learning
Jun 30, 2020
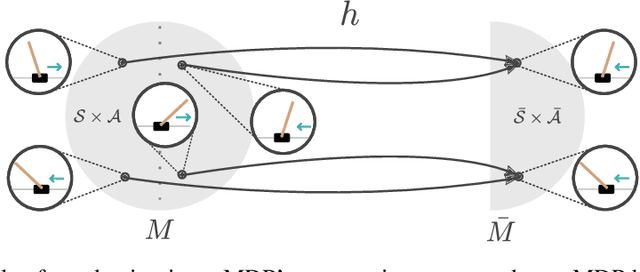
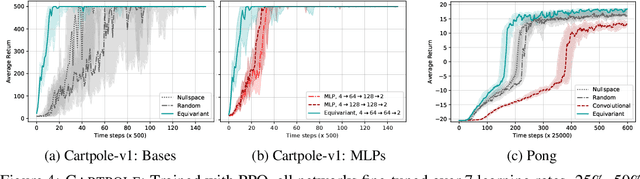
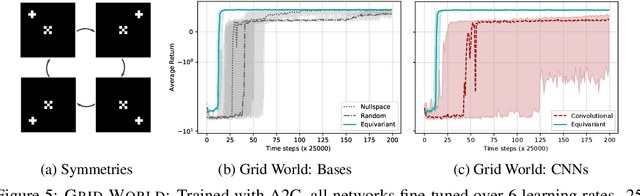
This paper introduces MDP homomorphic networks for deep reinforcement learning. MDP homomorphic networks are neural networks that are equivariant under symmetries in the joint state-action space of an MDP. Current approaches to deep reinforcement learning do not usually exploit knowledge about such structure. By building this prior knowledge into policy and value networks using an equivariance constraint, we can reduce the size of the solution space. We specifically focus on group-structured symmetries (invertible transformations). Additionally, we introduce an easy method for constructing equivariant network layers numerically, so the system designer need not solve the constraints by hand, as is typically done. We construct MDP homomorphic MLPs and CNNs that are equivariant under either a group of reflections or rotations. We show that such networks converge faster than unstructured baselines on CartPole, a grid world and Pong.
Sensor Data for Human Activity Recognition: Feature Representation and Benchmarking
May 15, 2020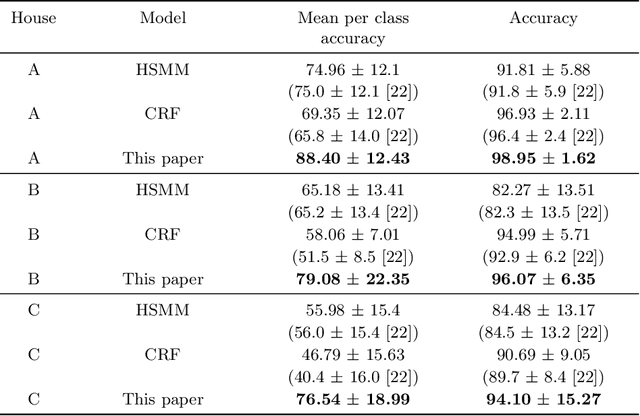
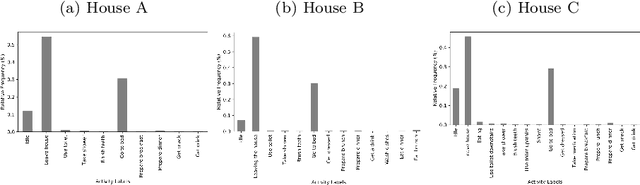

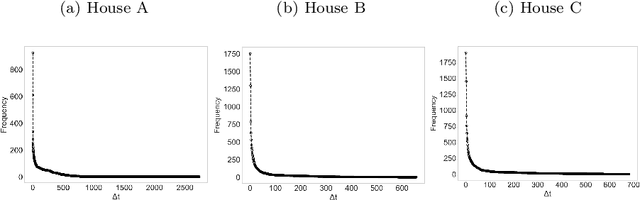
The field of Human Activity Recognition (HAR) focuses on obtaining and analysing data captured from monitoring devices (e.g. sensors). There is a wide range of applications within the field; for instance, assisted living, security surveillance, and intelligent transportation. In HAR, the development of Activity Recognition models is dependent upon the data captured by these devices and the methods used to analyse them, which directly affect performance metrics. In this work, we address the issue of accurately recognising human activities using different Machine Learning (ML) techniques. We propose a new feature representation based on consecutive occurring observations and compare it against previously used feature representations using a wide range of classification methods. Experimental results demonstrate that techniques based on the proposed representation outperform the baselines and a better accuracy was achieved for both highly and less frequent actions. We also investigate how the addition of further features and their pre-processing techniques affect performance results leading to state-of-the-art accuracy on a Human Activity Recognition dataset.
Diversity in Action: General-Sum Multi-Agent Continuous Inverse Optimal Control
Apr 27, 2020
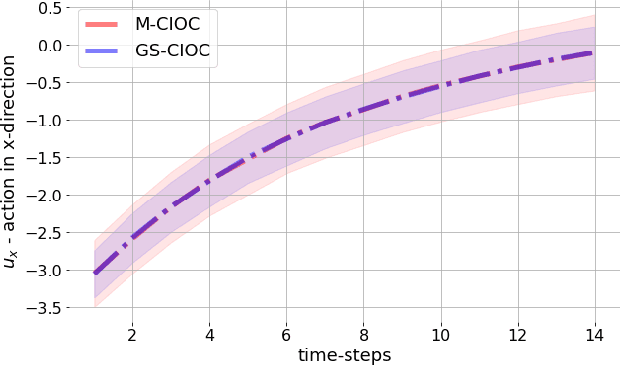
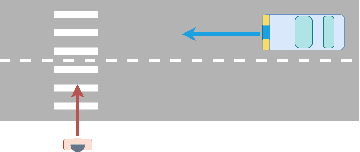
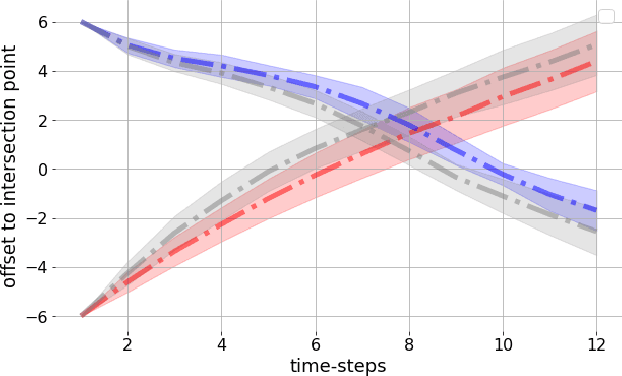
Traffic scenarios are inherently interactive. Multiple decision-makers predict the actions of others and choose strategies that maximize their rewards. We view these interactions from the perspective of game theory which introduces various challenges. Humans are not entirely rational, their rewards need to be inferred from real-world data, and any prediction algorithm needs to be real-time capable so that we can use it in an autonomous vehicle (AV). In this work, we present a game-theoretic method that addresses all of the points above. Compared to many existing methods used for AVs, our approach does 1) not require perfect communication, and 2) allows for individual rewards per agent. Our experiments demonstrate that these more realistic assumptions lead to qualitatively and quantitatively different reward inference and prediction of future actions that match better with expected real-world behaviour.
Mimicking Evolution with Reinforcement Learning
Mar 31, 2020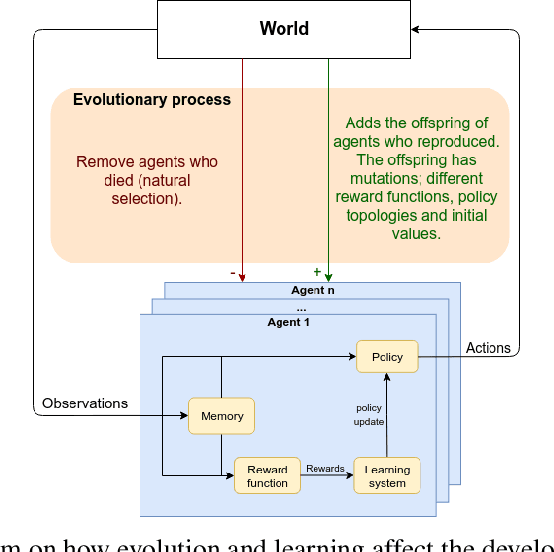

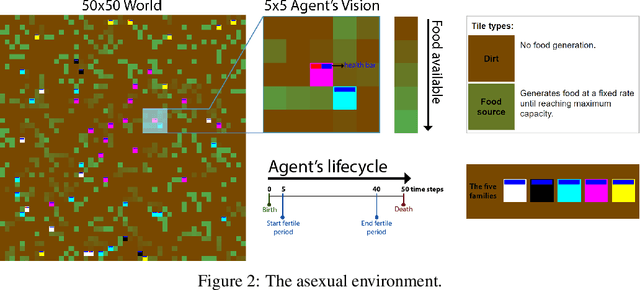

Evolution gave rise to human and animal intelligence here on Earth. We argue that the path to developing artificial human-like-intelligence will pass through mimicking the evolutionary process in a nature-like simulation. In Nature, there are two processes driving the development of the brain: evolution and learning. Evolution acts slowly, across generations, and amongst other things, it defines what agents learn by changing their internal reward function. Learning acts fast, across one's lifetime, and it quickly updates agents' policy to maximise pleasure and minimise pain. The reward function is slowly aligned with the fitness function by evolution, however, as agents evolve the environment and its fitness function also change, increasing the misalignment between reward and fitness. It is extremely computationally expensive to replicate these two processes in simulation. This work proposes Evolution via Evolutionary Reward (EvER) that allows learning to single-handedly drive the search for policies with increasingly evolutionary fitness by ensuring the alignment of the reward function with the fitness function. In this search, EvER makes use of the whole state-action trajectories that agents go through their lifetime. In contrast, current evolutionary algorithms discard this information and consequently limit their potential efficiency at tackling sequential decision problems. We test our algorithm in two simple bio-inspired environments and show its superiority at generating more capable agents at surviving and reproducing their genes when compared with a state-of-the-art evolutionary algorithm.
Plannable Approximations to MDP Homomorphisms: Equivariance under Actions
Feb 27, 2020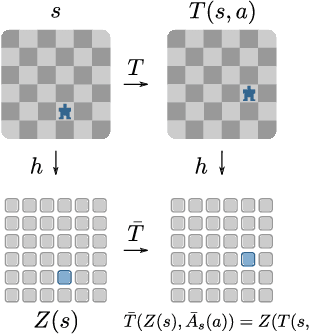
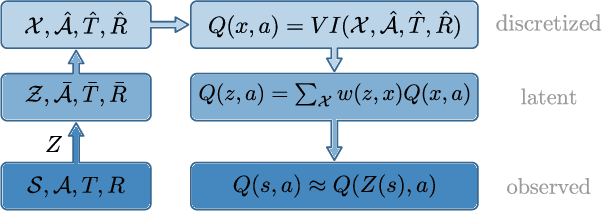
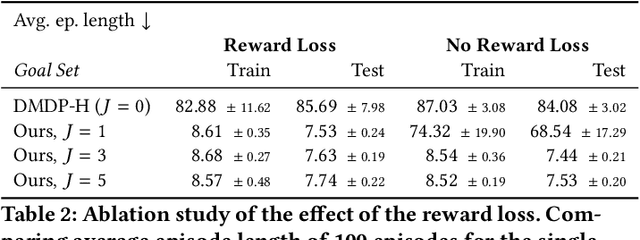
This work exploits action equivariance for representation learning in reinforcement learning. Equivariance under actions states that transitions in the input space are mirrored by equivalent transitions in latent space, while the map and transition functions should also commute. We introduce a contrastive loss function that enforces action equivariance on the learned representations. We prove that when our loss is zero, we have a homomorphism of a deterministic Markov Decision Process (MDP). Learning equivariant maps leads to structured latent spaces, allowing us to build a model on which we plan through value iteration. We show experimentally that for deterministic MDPs, the optimal policy in the abstract MDP can be successfully lifted to the original MDP. Moreover, the approach easily adapts to changes in the goal states. Empirically, we show that in such MDPs, we obtain better representations in fewer epochs compared to representation learning approaches using reconstructions, while generalizing better to new goals than model-free approaches.