 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscontinuous Hamiltonian Monte Carlo for Probabilistic Programs
Apr 07, 2018
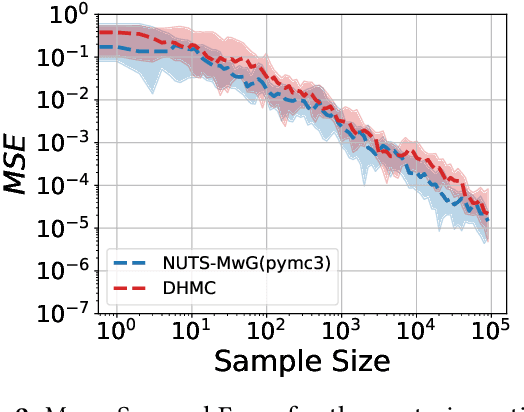
Hamiltonian Monte Carlo (HMC) is the dominant statistical inference algorithm used in most popular first-order differentiable probabilistic programming languages. HMC requires that the joint density be differentiable with respect to all latent variables. This complicates expressing some models in such languages and prohibits others. A recently proposed new integrator for HMC yielded a new Discontinuous HMC (DHMC) algorithm that can be used for inference in models with joint densities that have discontinuities. In this paper we show how to use DHMC for inference in probabilistic programs. To do this we introduce a sufficient set of language restrictions, a corresponding mathematical formalism that ensures that any joint density denoted in such a language has a suitably low measure of discontinuous points, and a recipe for how to apply DHMC in the more general probabilistic-programming context. Our experimental findings demonstrate the correctness of this approach.
Auto-Encoding Sequential Monte Carlo
Apr 05, 2018
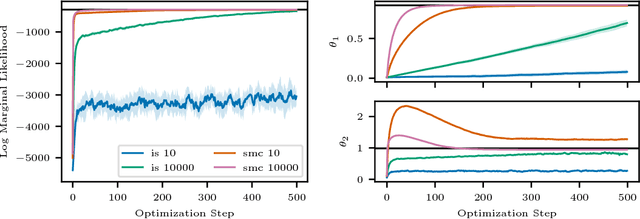
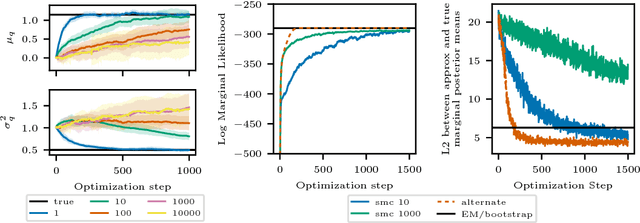
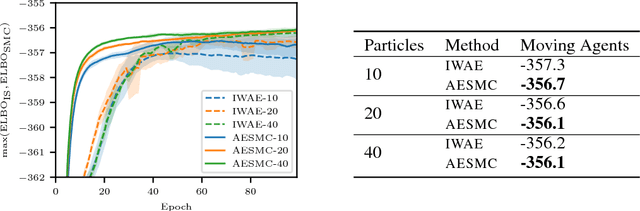
We build on auto-encoding sequential Monte Carlo (AESMC): a method for model and proposal learning based on maximizing the lower bound to the log marginal likelihood in a broad family of structured probabilistic models. Our approach relies on the efficiency of sequential Monte Carlo (SMC) for performing inference in structured probabilistic models and the flexibility of deep neural networks to model complex conditional probability distributions. We develop additional theoretical insights and introduce a new training procedure which improves both model and proposal learning. We demonstrate that our approach provides a fast, easy-to-implement and scalable means for simultaneous model learning and proposal adaptation in deep generative models.
High Throughput Synchronous Distributed Stochastic Gradient Descent
Mar 12, 2018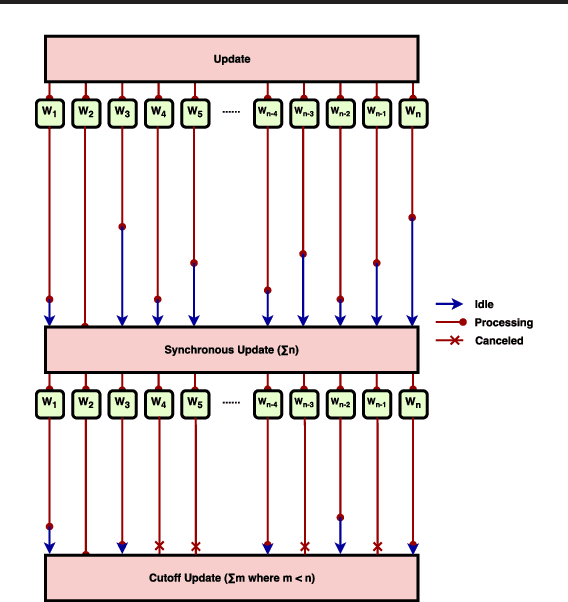
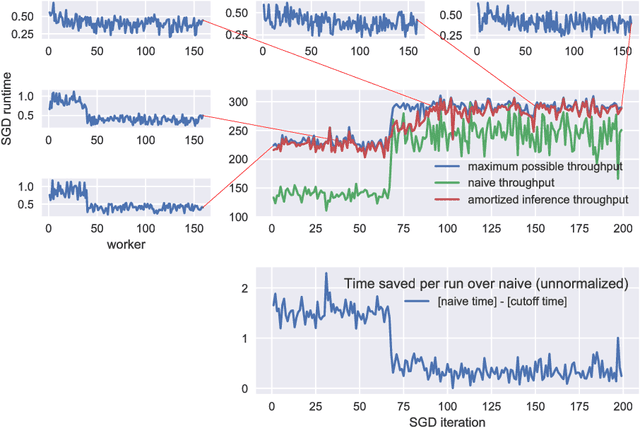
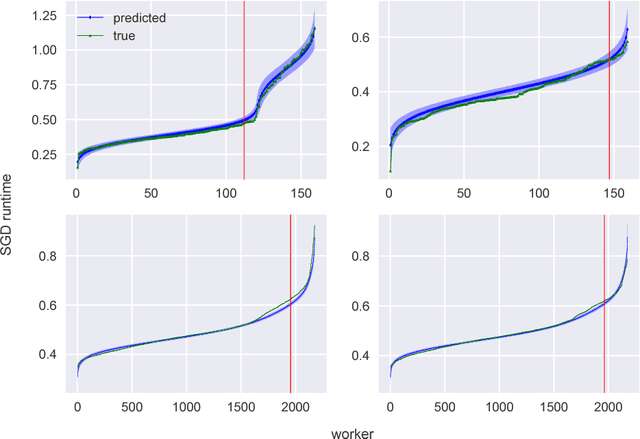

We introduce a new, high-throughput, synchronous, distributed, data-parallel, stochastic-gradient-descent learning algorithm. This algorithm uses amortized inference in a compute-cluster-specific, deep, generative, dynamical model to perform joint posterior predictive inference of the mini-batch gradient computation times of all worker-nodes in a parallel computing cluster. We show that a synchronous parameter server can, by utilizing such a model, choose an optimal cutoff time beyond which mini-batch gradient messages from slow workers are ignored that maximizes overall mini-batch gradient computations per second. In keeping with earlier findings we observe that, under realistic conditions, eagerly discarding the mini-batch gradient computations of stragglers not only increases throughput but actually increases the overall rate of convergence as a function of wall-clock time by virtue of eliminating idleness. The principal novel contribution and finding of this work goes beyond this by demonstrating that using the predicted run-times from a generative model of cluster worker performance to dynamically adjust the cutoff improves substantially over the static-cutoff prior art, leading to, among other things, significantly reduced deep neural net training times on large computer clusters.
Inference Networks for Sequential Monte Carlo in Graphical Models
Mar 07, 2018


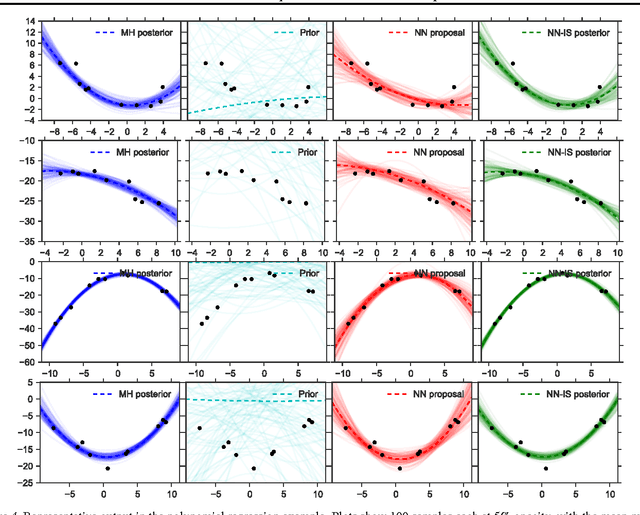
We introduce a new approach for amortizing inference in directed graphical models by learning heuristic approximations to stochastic inverses, designed specifically for use as proposal distributions in sequential Monte Carlo methods. We describe a procedure for constructing and learning a structured neural network which represents an inverse factorization of the graphical model, resulting in a conditional density estimator that takes as input particular values of the observed random variables, and returns an approximation to the distribution of the latent variables. This recognition model can be learned offline, independent from any particular dataset, prior to performing inference. The output of these networks can be used as automatically-learned high-quality proposal distributions to accelerate sequential Monte Carlo across a diverse range of problem settings.
* 10 pages. Updated from version at ICML 2016; includes code at http://github.com/tbrx/compiled-inference
Online Learning Rate Adaptation with Hypergradient Descent
Feb 26, 2018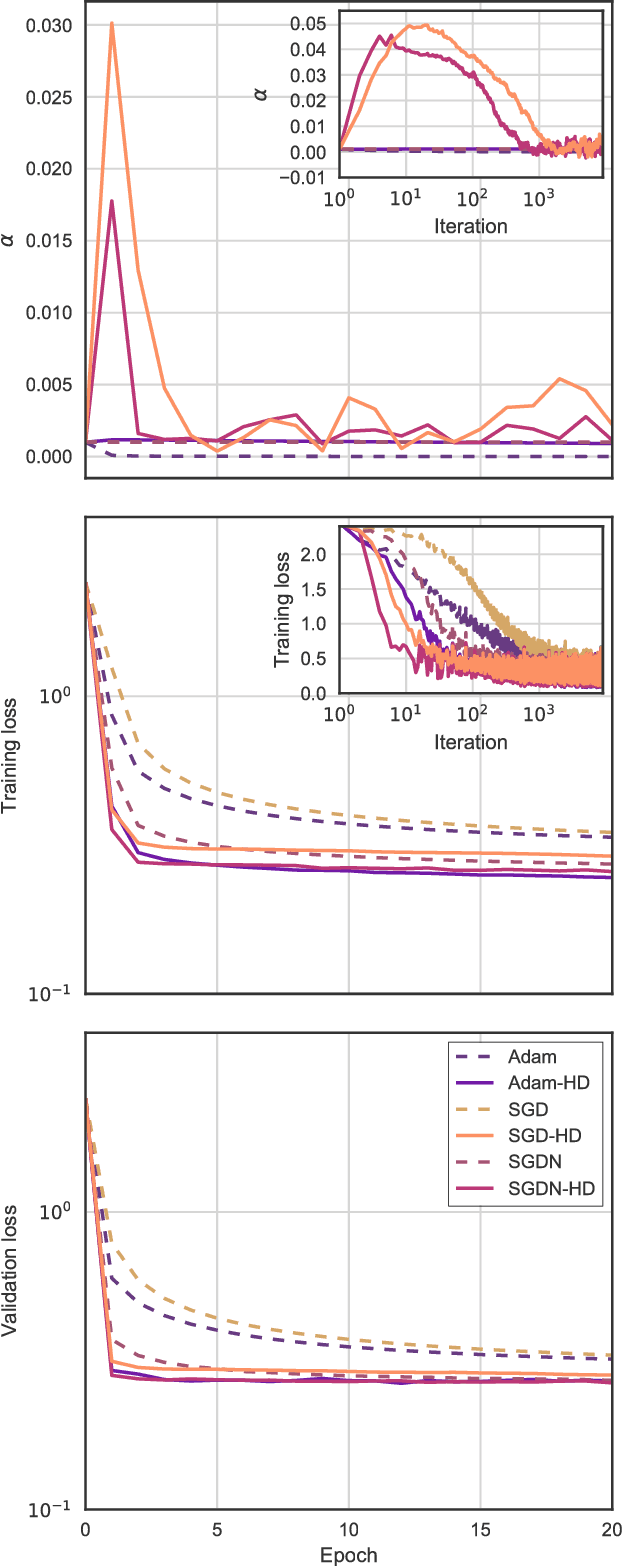
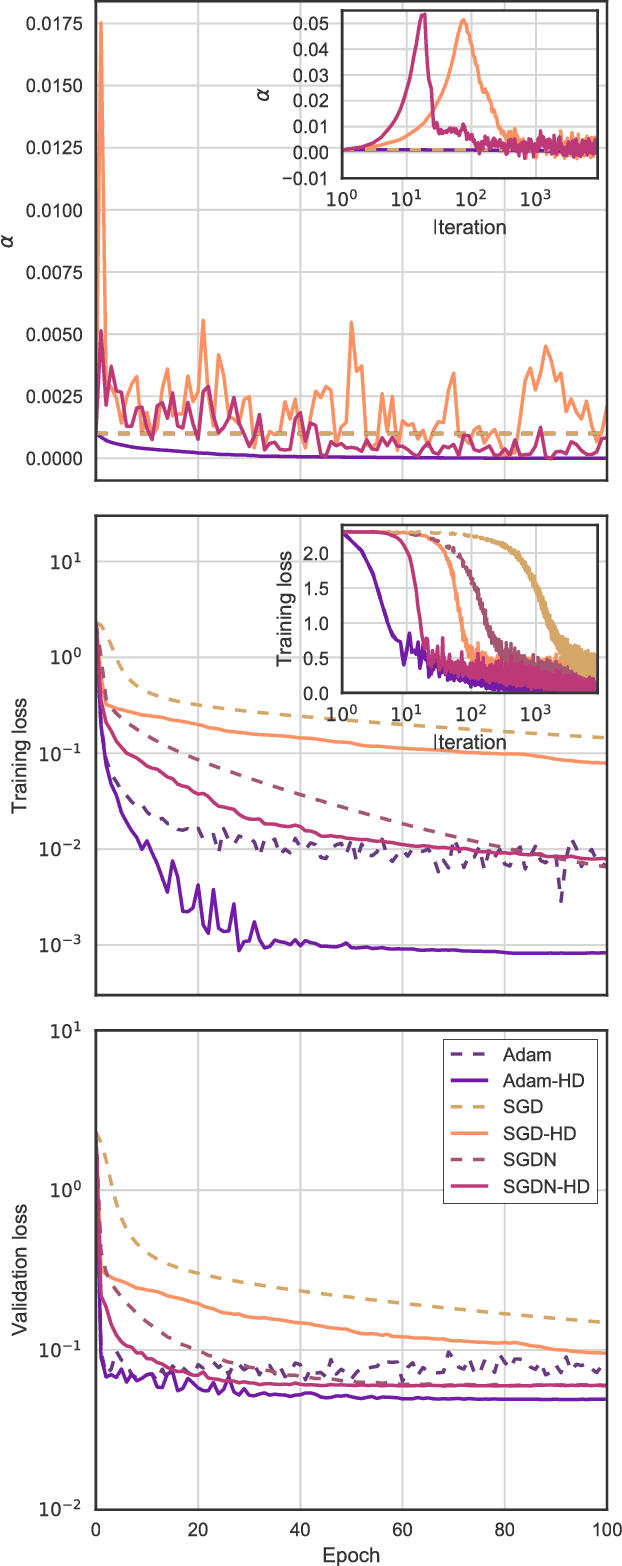
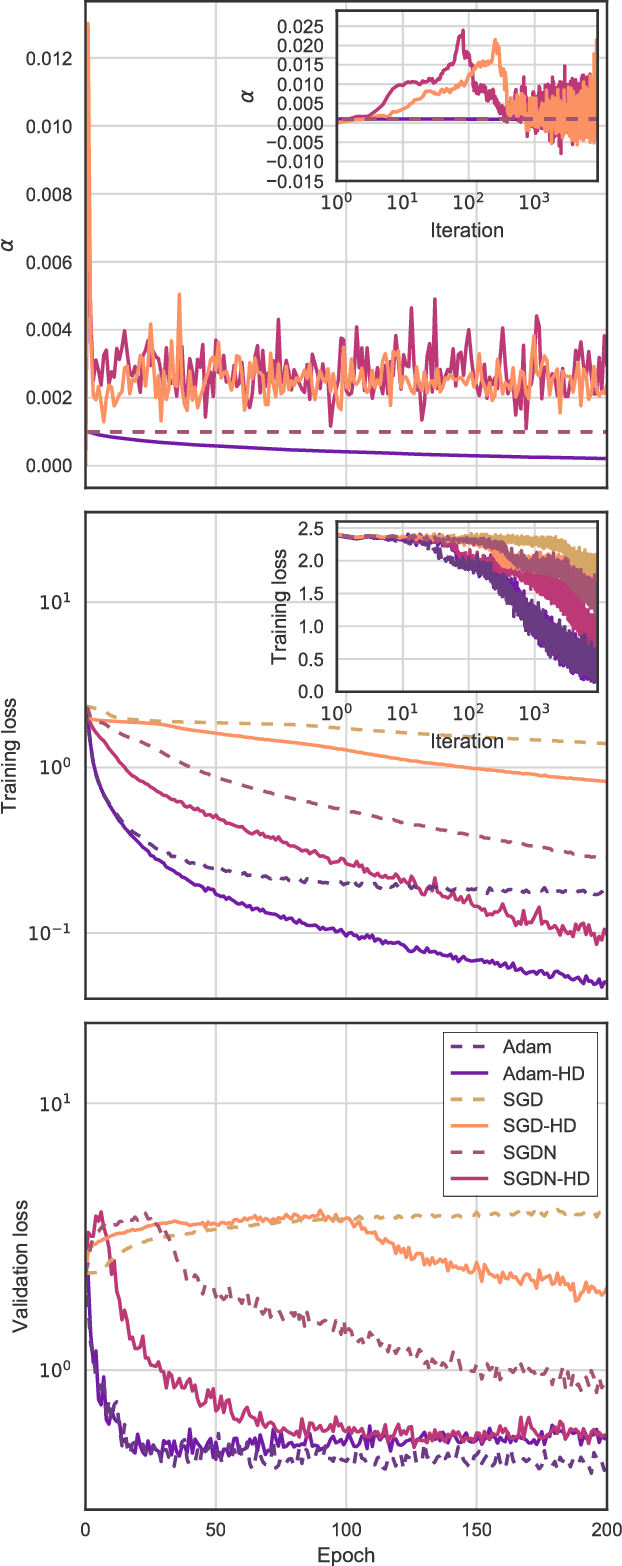
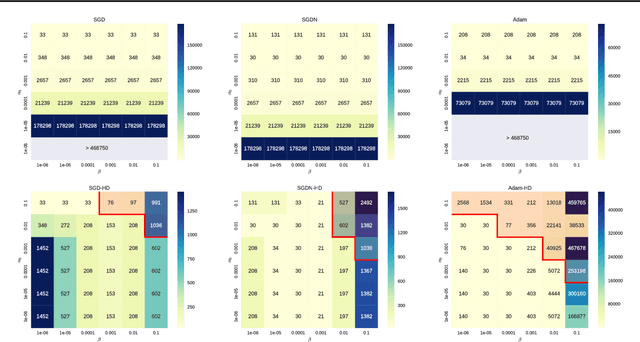
We introduce a general method for improving the convergence rate of gradient-based optimizers that is easy to implement and works well in practice. We demonstrate the effectiveness of the method in a range of optimization problems by applying it to stochastic gradient descent, stochastic gradient descent with Nesterov momentum, and Adam, showing that it significantly reduces the need for the manual tuning of the initial learning rate for these commonly used algorithms. Our method works by dynamically updating the learning rate during optimization using the gradient with respect to the learning rate of the update rule itself. Computing this "hypergradient" needs little additional computation, requires only one extra copy of the original gradient to be stored in memory, and relies upon nothing more than what is provided by reverse-mode automatic differentiation.
* 11 pages, 4 figures
Improvements to Inference Compilation for Probabilistic Programming in Large-Scale Scientific Simulators
Dec 21, 2017
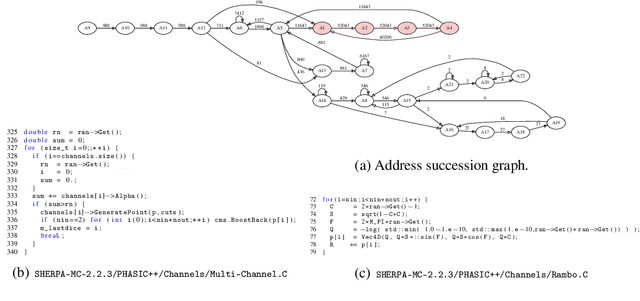
We consider the problem of Bayesian inference in the family of probabilistic models implicitly defined by stochastic generative models of data. In scientific fields ranging from population biology to cosmology, low-level mechanistic components are composed to create complex generative models. These models lead to intractable likelihoods and are typically non-differentiable, which poses challenges for traditional approaches to inference. We extend previous work in "inference compilation", which combines universal probabilistic programming and deep learning methods, to large-scale scientific simulators, and introduce a C++ based probabilistic programming library called CPProb. We successfully use CPProb to interface with SHERPA, a large code-base used in particle physics. Here we describe the technical innovations realized and planned for this library.
Learning Disentangled Representations with Semi-Supervised Deep Generative Models
Nov 13, 2017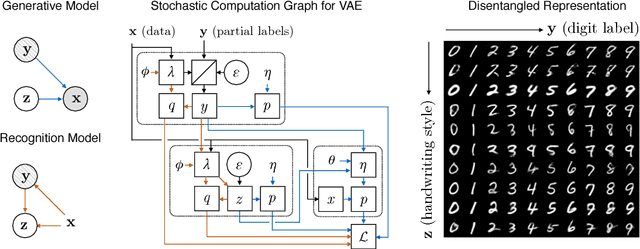

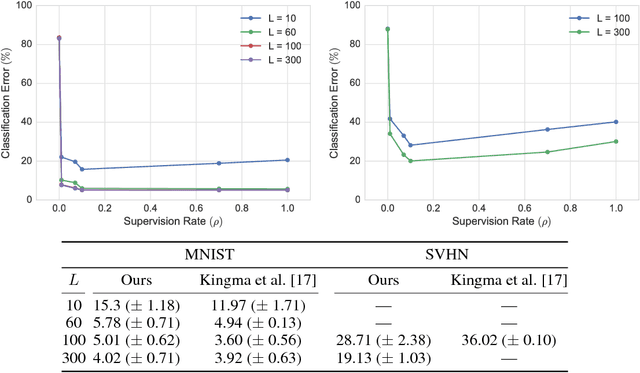
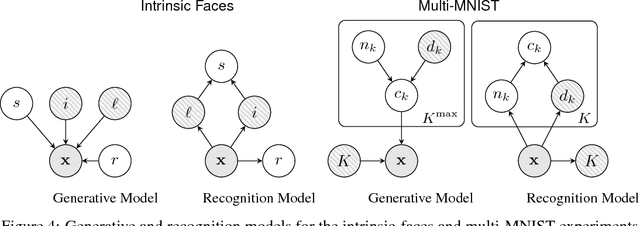
Variational autoencoders (VAEs) learn representations of data by jointly training a probabilistic encoder and decoder network. Typically these models encode all features of the data into a single variable. Here we are interested in learning disentangled representations that encode distinct aspects of the data into separate variables. We propose to learn such representations using model architectures that generalise from standard VAEs, employing a general graphical model structure in the encoder and decoder. This allows us to train partially-specified models that make relatively strong assumptions about a subset of interpretable variables and rely on the flexibility of neural networks to learn representations for the remaining variables. We further define a general objective for semi-supervised learning in this model class, which can be approximated using an importance sampling procedure. We evaluate our framework's ability to learn disentangled representations, both by qualitative exploration of its generative capacity, and quantitative evaluation of its discriminative ability on a variety of models and datasets.
Updating the VESICLE-CNN Synapse Detector
Oct 31, 2017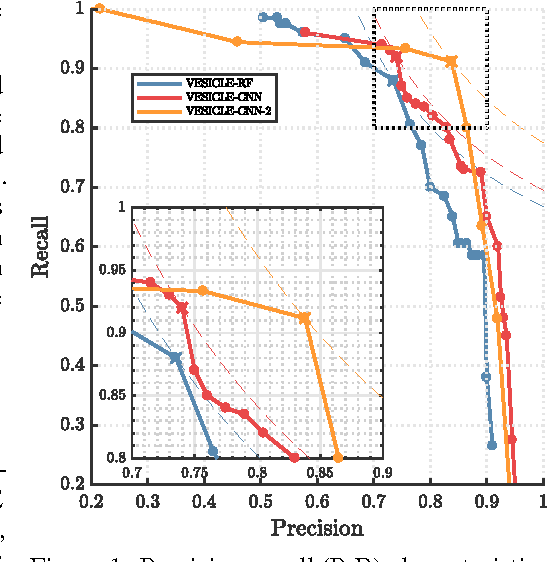
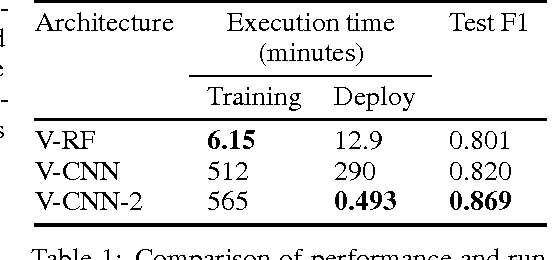
We present an updated version of the VESICLE-CNN algorithm presented by Roncal et al. (2014). The original implementation makes use of a patch-based approach. This methodology is known to be slow due to repeated computations. We update this implementation to be fully convolutional through the use of dilated convolutions, recovering the expanded field of view achieved through the use of strided maxpools, but without a degradation of spatial resolution. This updated implementation performs as well as the original implementation, but with a $600\times$ speedup at test time. We release source code and data into the public domain.
Canonical Correlation Forests
Aug 09, 2017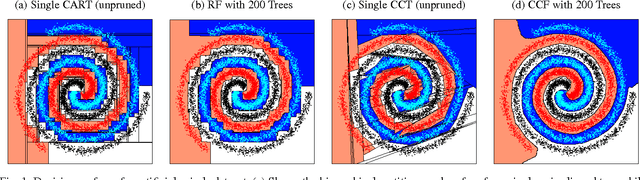
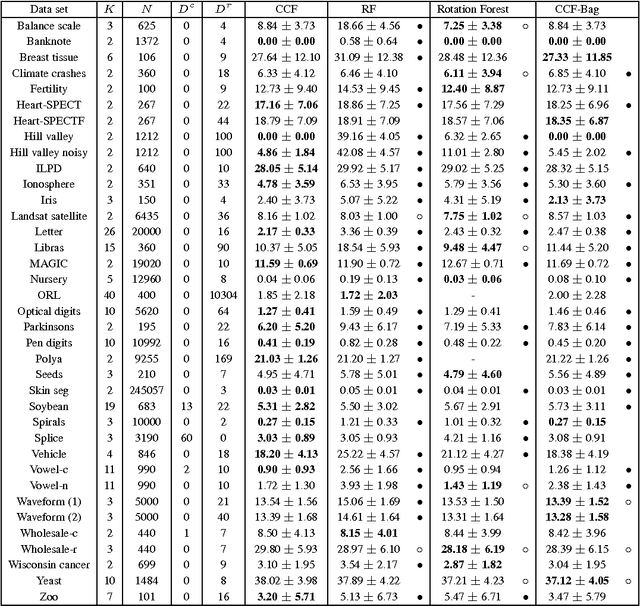

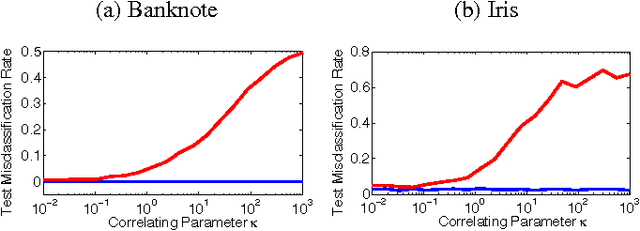
We introduce canonical correlation forests (CCFs), a new decision tree ensemble method for classification and regression. Individual canonical correlation trees are binary decision trees with hyperplane splits based on local canonical correlation coefficients calculated during training. Unlike axis-aligned alternatives, the decision surfaces of CCFs are not restricted to the coordinate system of the inputs features and therefore more naturally represent data with correlated inputs. CCFs naturally accommodate multiple outputs, provide a similar computational complexity to random forests, and inherit their impressive robustness to the choice of input parameters. As part of the CCF training algorithm, we also introduce projection bootstrapping, a novel alternative to bagging for oblique decision tree ensembles which maintains use of the full dataset in selecting split points, often leading to improvements in predictive accuracy. Our experiments show that, even without parameter tuning, CCFs out-perform axis-aligned random forests and other state-of-the-art tree ensemble methods on both classification and regression problems, delivering both improved predictive accuracy and faster training times. We further show that they outperform all of the 179 classifiers considered in a recent extensive survey.
Bayesian Optimization for Probabilistic Programs
Jul 13, 2017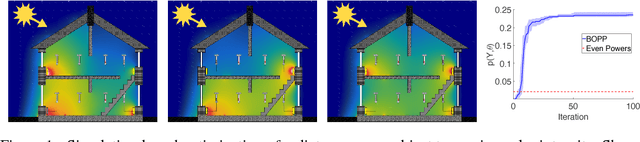
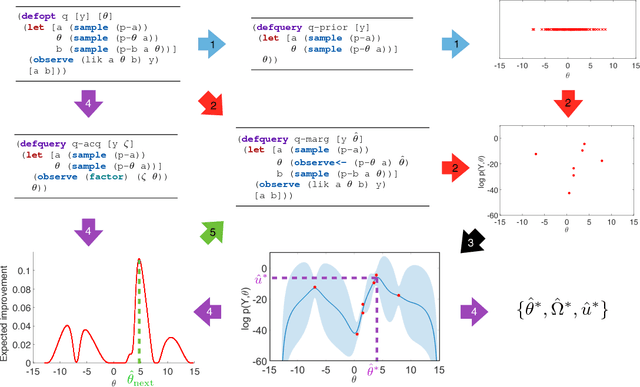
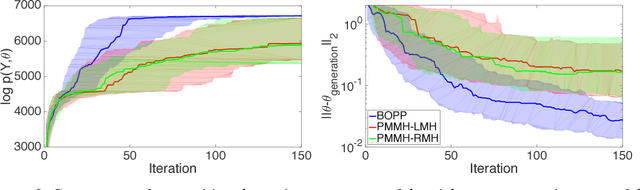
We present the first general purpose framework for marginal maximum a posteriori estimation of probabilistic program variables. By using a series of code transformations, the evidence of any probabilistic program, and therefore of any graphical model, can be optimized with respect to an arbitrary subset of its sampled variables. To carry out this optimization, we develop the first Bayesian optimization package to directly exploit the source code of its target, leading to innovations in problem-independent hyperpriors, unbounded optimization, and implicit constraint satisfaction; delivering significant performance improvements over prominent existing packages. We present applications of our method to a number of tasks including engineering design and parameter optimization.