 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlexible Diffusion Modeling of Long Videos
May 23, 2022
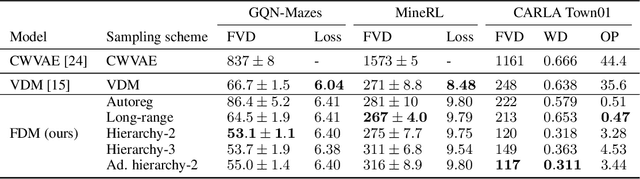

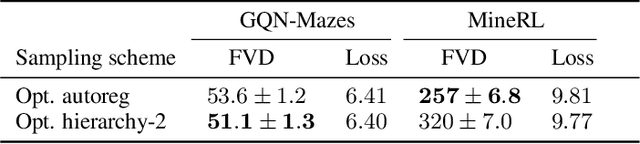
We present a framework for video modeling based on denoising diffusion probabilistic models that produces long-duration video completions in a variety of realistic environments. We introduce a generative model that can at test-time sample any arbitrary subset of video frames conditioned on any other subset and present an architecture adapted for this purpose. Doing so allows us to efficiently compare and optimize a variety of schedules for the order in which frames in a long video are sampled and use selective sparse and long-range conditioning on previously sampled frames. We demonstrate improved video modeling over prior work on a number of datasets and sample temporally coherent videos over 25 minutes in length. We additionally release a new video modeling dataset and semantically meaningful metrics based on videos generated in the CARLA self-driving car simulator.
BayesPCN: A Continually Learnable Predictive Coding Associative Memory
May 20, 2022
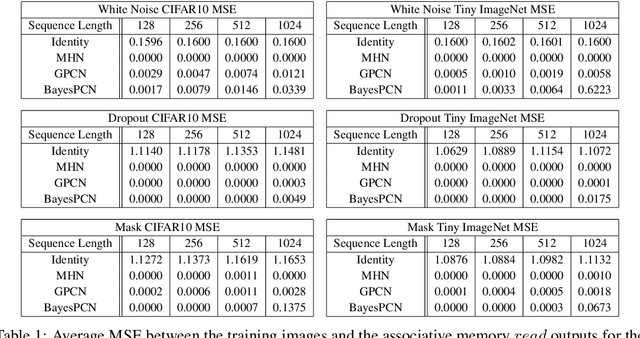
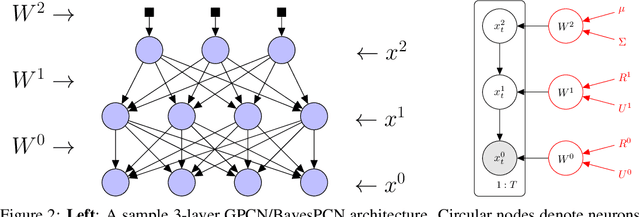

Associative memory plays an important role in human intelligence and its mechanisms have been linked to attention in machine learning. While the machine learning community's interest in associative memories has recently been rekindled, most work has focused on memory recall ($read$) over memory learning ($write$). In this paper, we present BayesPCN, a hierarchical associative memory capable of performing continual one-shot memory writes without meta-learning. Moreover, BayesPCN is able to gradually forget past observations ($forget$) to free its memory. Experiments show that BayesPCN can recall corrupted i.i.d. high-dimensional data observed hundreds of "timesteps" ago without a significant drop in recall ability compared to the state-of-the-art offline-learned associative memory models.
Gradients without Backpropagation
Feb 17, 2022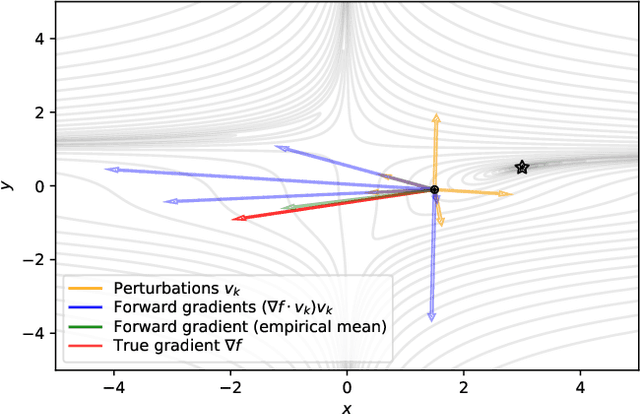
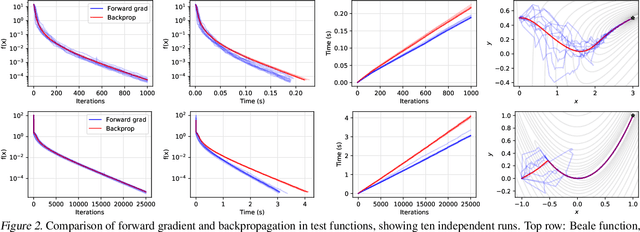

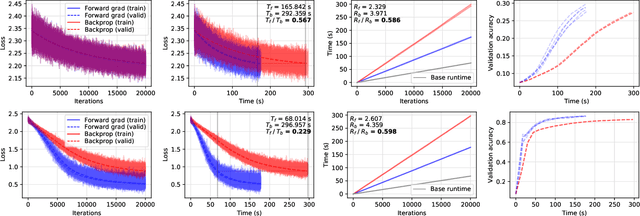
Using backpropagation to compute gradients of objective functions for optimization has remained a mainstay of machine learning. Backpropagation, or reverse-mode differentiation, is a special case within the general family of automatic differentiation algorithms that also includes the forward mode. We present a method to compute gradients based solely on the directional derivative that one can compute exactly and efficiently via the forward mode. We call this formulation the forward gradient, an unbiased estimate of the gradient that can be evaluated in a single forward run of the function, entirely eliminating the need for backpropagation in gradient descent. We demonstrate forward gradient descent in a range of problems, showing substantial savings in computation and enabling training up to twice as fast in some cases.
Exploration with Multi-Sample Target Values for Distributional Reinforcement Learning
Feb 06, 2022
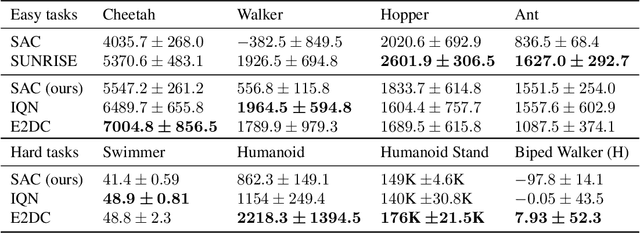
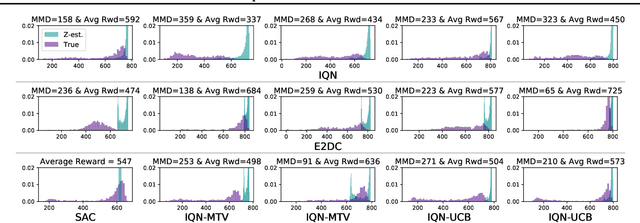
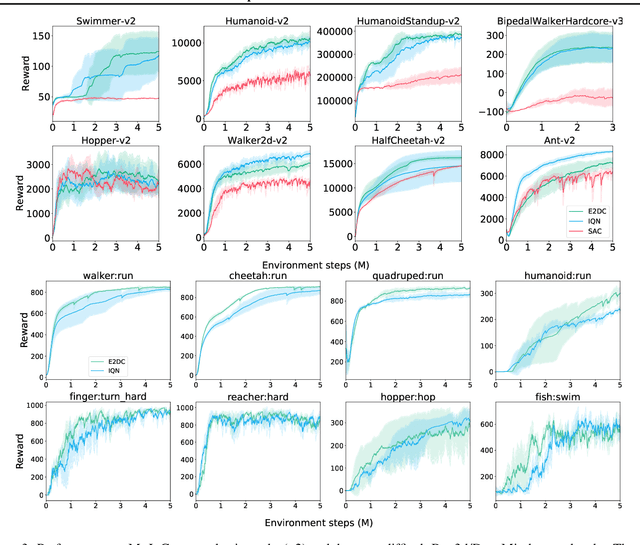
Distributional reinforcement learning (RL) aims to learn a value-network that predicts the full distribution of the returns for a given state, often modeled via a quantile-based critic. This approach has been successfully integrated into common RL methods for continuous control, giving rise to algorithms such as Distributional Soft Actor-Critic (DSAC). In this paper, we introduce multi-sample target values (MTV) for distributional RL, as a principled replacement for single-sample target value estimation, as commonly employed in current practice. The improved distributional estimates further lend themselves to UCB-based exploration. These two ideas are combined to yield our distributional RL algorithm, E2DC (Extra Exploration with Distributional Critics). We evaluate our approach on a range of continuous control tasks and demonstrate state-of-the-art model-free performance on difficult tasks such as Humanoid control. We provide further insight into the method via visualization and analysis of the learned distributions and their evolution during training.
Beyond Simple Meta-Learning: Multi-Purpose Models for Multi-Domain, Active and Continual Few-Shot Learning
Jan 13, 2022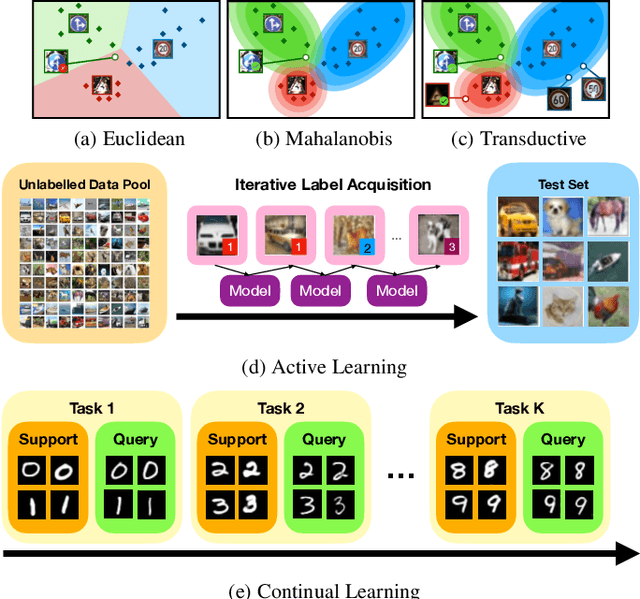
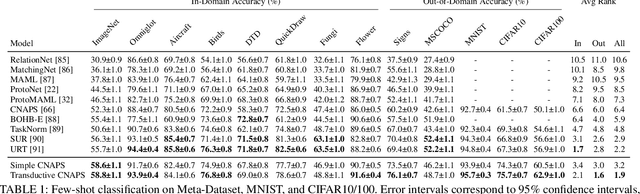
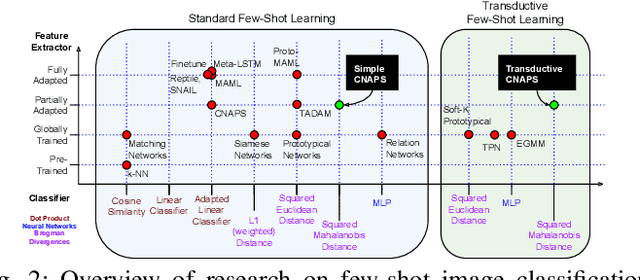
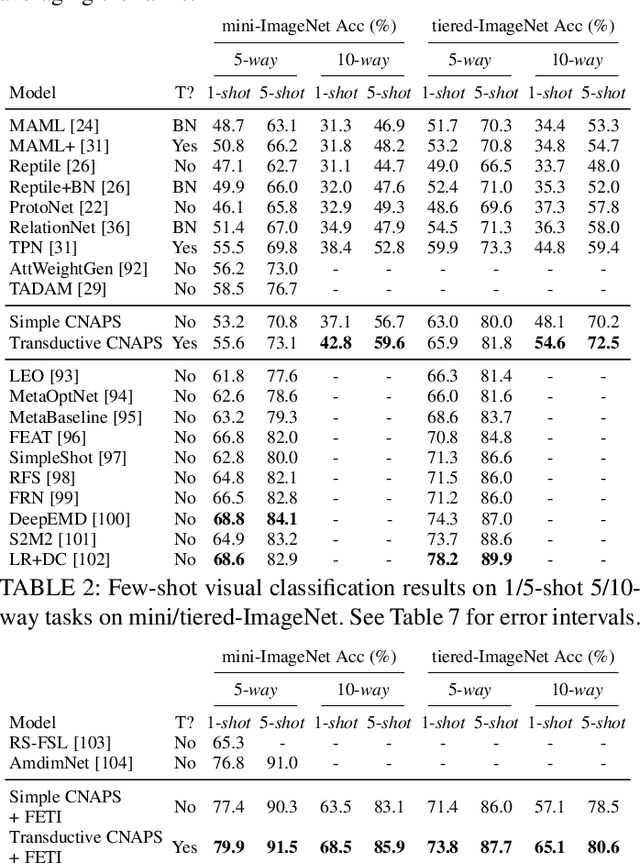
Modern deep learning requires large-scale extensively labelled datasets for training. Few-shot learning aims to alleviate this issue by learning effectively from few labelled examples. In previously proposed few-shot visual classifiers, it is assumed that the feature manifold, where classifier decisions are made, has uncorrelated feature dimensions and uniform feature variance. In this work, we focus on addressing the limitations arising from this assumption by proposing a variance-sensitive class of models that operates in a low-label regime. The first method, Simple CNAPS, employs a hierarchically regularized Mahalanobis-distance based classifier combined with a state of the art neural adaptive feature extractor to achieve strong performance on Meta-Dataset, mini-ImageNet and tiered-ImageNet benchmarks. We further extend this approach to a transductive learning setting, proposing Transductive CNAPS. This transductive method combines a soft k-means parameter refinement procedure with a two-step task encoder to achieve improved test-time classification accuracy using unlabelled data. Transductive CNAPS achieves state of the art performance on Meta-Dataset. Finally, we explore the use of our methods (Simple and Transductive) for "out of the box" continual and active learning. Extensive experiments on large scale benchmarks illustrate robustness and versatility of this, relatively speaking, simple class of models. All trained model checkpoints and corresponding source codes have been made publicly available.
q-Paths: Generalizing the Geometric Annealing Path using Power Means
Jul 01, 2021
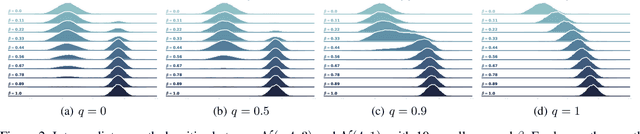
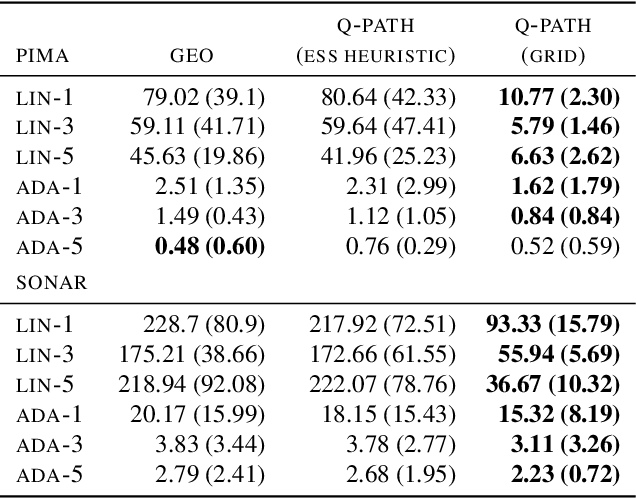

Many common machine learning methods involve the geometric annealing path, a sequence of intermediate densities between two distributions of interest constructed using the geometric average. While alternatives such as the moment-averaging path have demonstrated performance gains in some settings, their practical applicability remains limited by exponential family endpoint assumptions and a lack of closed form energy function. In this work, we introduce $q$-paths, a family of paths which is derived from a generalized notion of the mean, includes the geometric and arithmetic mixtures as special cases, and admits a simple closed form involving the deformed logarithm function from nonextensive thermodynamics. Following previous analysis of the geometric path, we interpret our $q$-paths as corresponding to a $q$-exponential family of distributions, and provide a variational representation of intermediate densities as minimizing a mixture of $\alpha$-divergences to the endpoints. We show that small deviations away from the geometric path yield empirical gains for Bayesian inference using Sequential Monte Carlo and generative model evaluation using Annealed Importance Sampling.
Differentiable Particle Filtering without Modifying the Forward Pass
Jun 18, 2021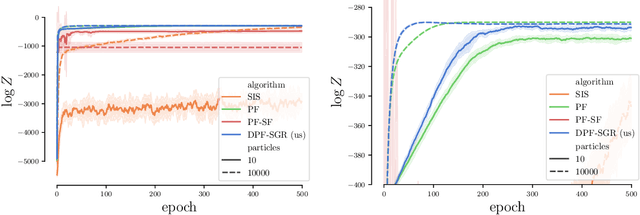
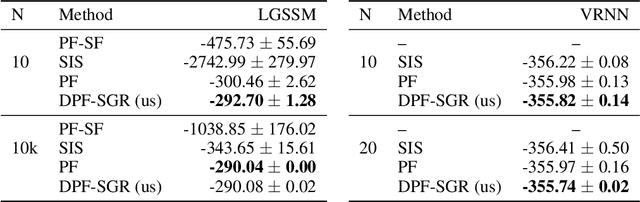
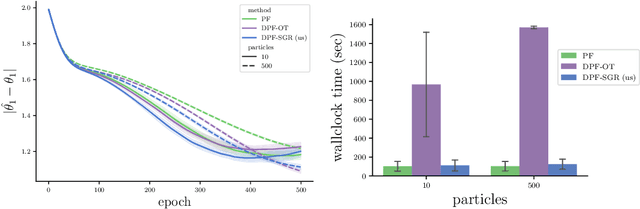
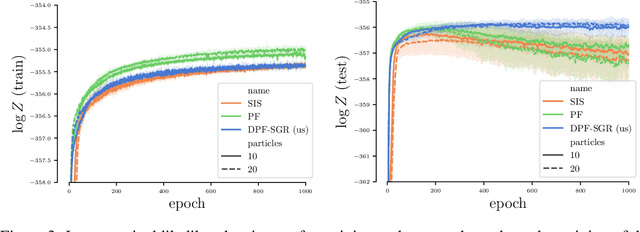
In recent years particle filters have being used as components in systems optimized end-to-end with gradient descent. However, the resampling step in a particle filter is not differentiable, which biases gradients and interferes with optimization. To remedy this problem, several differentiable variants of resampling have been proposed, all of which modify the behavior of the particle filter in significant and potentially undesirable ways. In this paper, we show how to obtain unbiased estimators of the gradient of the marginal likelihood by only modifying messages used in backpropagation, leaving the standard forward pass of a particle filter unchanged. Our method is simple to implement, has a low computational overhead, does not introduce additional hyperparameters, and extends to derivatives of higher orders. We call it stop-gradient resampling, since it can easily be implemented with automatic differentiation libraries using the stop-gradient operator instead of explicitly modifying the backward messages.
Imagining The Road Ahead: Multi-Agent Trajectory Prediction via Differentiable Simulation
Apr 22, 2021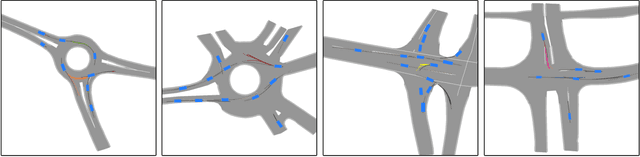
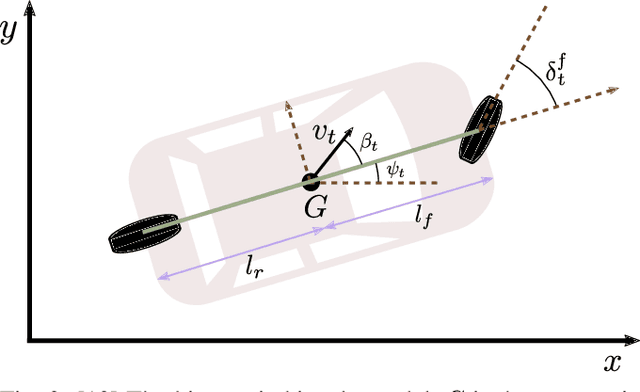
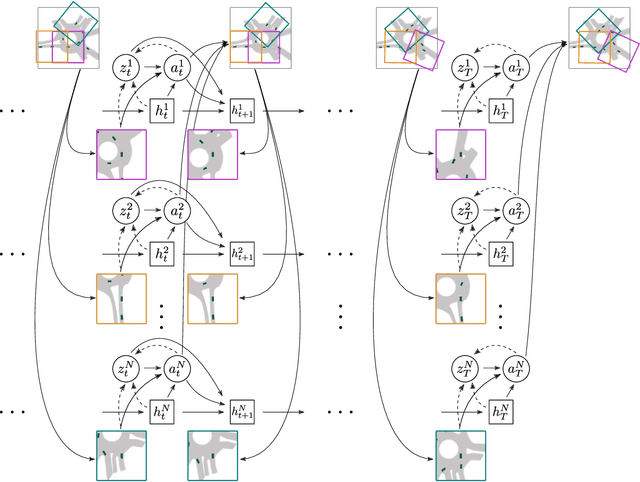
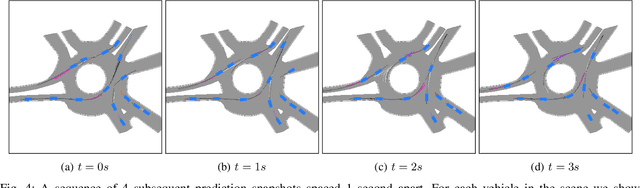
We develop a deep generative model built on a fully differentiable simulator for multi-agent trajectory prediction. Agents are modeled with conditional recurrent variational neural networks (CVRNNs), which take as input an ego-centric birdview image representing the current state of the world and output an action, consisting of steering and acceleration, which is used to derive the subsequent agent state using a kinematic bicycle model. The full simulation state is then differentiably rendered for each agent, initiating the next time step. We achieve state-of-the-art results on the INTERACTION dataset, using standard neural architectures and a standard variational training objective, producing realistic multi-modal predictions without any ad-hoc diversity-inducing losses. We conduct ablation studies to examine individual components of the simulator, finding that both the kinematic bicycle model and the continuous feedback from the birdview image are crucial for achieving this level of performance. We name our model ITRA, for "Imagining the Road Ahead".
Image Completion via Inference in Deep Generative Models
Feb 24, 2021
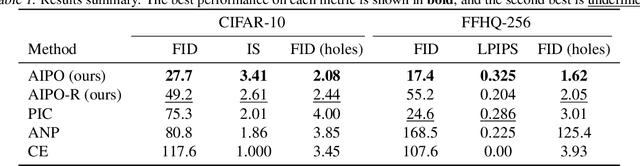
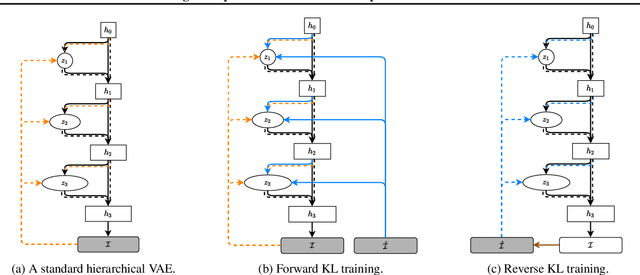
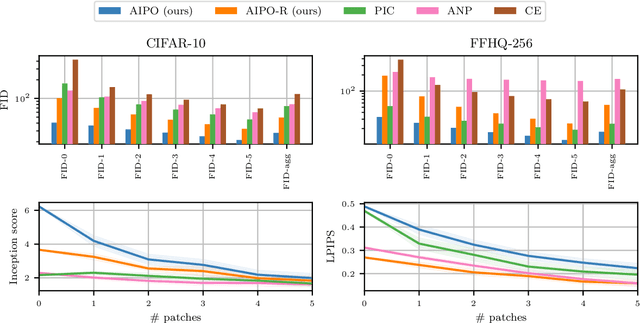
We consider image completion from the perspective of amortized inference in an image generative model. We leverage recent state of the art variational auto-encoder architectures that have been shown to produce photo-realistic natural images at non-trivial resolutions. Through amortized inference in such a model we can train neural artifacts that produce diverse, realistic image completions even when the vast majority of an image is missing. We demonstrate superior sample quality and diversity compared to prior art on the CIFAR-10 and FFHQ-256 datasets. We conclude by describing and demonstrating an application that requires an in-painting model with the capabilities ours exhibits: the use of Bayesian optimal experimental design to select the most informative sequence of small field of view x-rays for chest pathology detection.
Robust Asymmetric Learning in POMDPs
Dec 31, 2020


Policies for partially observed Markov decision processes can be efficiently learned by imitating policies for the corresponding fully observed Markov decision processes. Unfortunately, existing approaches for this kind of imitation learning have a serious flaw: the expert does not know what the trainee cannot see, and so may encourage actions that are sub-optimal, even unsafe, under partial information. We derive an objective to instead train the expert to maximize the expected reward of the imitating agent policy, and use it to construct an efficient algorithm, adaptive asymmetric DAgger (A2D), that jointly trains the expert and the agent. We show that A2D produces an expert policy that the agent can safely imitate, in turn outperforming policies learned by imitating a fixed expert.