 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Neural Operator Towards Edge Deployability and Portability for Sparse-to-Dense, Real-Time Virtual Sensing on Irregular Grids
Apr 02, 2026Accurate sensing of spatially distributed physical fields typically requires dense instrumentation, which is often infeasible in real-world systems due to cost, accessibility, and environmental constraints. Physics-based solvers address this through direct numerical integration of governing equations, but their computational latency and power requirements preclude real-time use in resource-constrained monitoring and control systems. Here we introduce VIRSO (Virtual Irregular Real-Time Sparse Operator), a graph-based neural operator for sparse-to-dense reconstruction on irregular geometries, and a variable-connectivity algorithm, Variable KNN (V-KNN), for mesh-informed graph construction. Unlike prior neural operators that treat hardware deployability as secondary, VIRSO reframes inference as measurement: the combination of both spectral and spatial analysis provides accurate reconstruction without the high latency and power consumption of previous graph-based methodologies with poor scalability, presenting VIRSO as a potential candidate for edge-constrained, real-time virtual sensing. We evaluate VIRSO on three nuclear thermal-hydraulic benchmarks of increasing geometric and multiphysics complexity, across reconstruction ratios from 47:1 to 156:1. VIRSO achieves mean relative $L_2$ errors below 1%, outperforming other benchmark operators while using fewer parameters. The full 10-layer configuration reduces the energy-delay product (EDP) from ${\approx}206$ J$\cdot$ms for the graph operator baseline to $10.1$ J$\cdot$ms on an NVIDIA H200. Implemented on an NVIDIA Jetson Orin Nano, all configurations of VIRSO provide sub-10 W power consumption and sub-second latency. These results establish the edge-feasibility and hardware-portability of VIRSO and present compute-aware operator learning as a new paradigm for real-time sensing in inaccessible and resource-constrained environments.
Online Continual Learning of Video Diffusion Models From a Single Video Stream
Jun 07, 2024Diffusion models have shown exceptional capabilities in generating realistic videos. Yet, their training has been predominantly confined to offline environments where models can repeatedly train on i.i.d. data to convergence. This work explores the feasibility of training diffusion models from a semantically continuous video stream, where correlated video frames sequentially arrive one at a time. To investigate this, we introduce two novel continual video generative modeling benchmarks, Lifelong Bouncing Balls and Windows 95 Maze Screensaver, each containing over a million video frames generated from navigating stationary environments. Surprisingly, our experiments show that diffusion models can be effectively trained online using experience replay, achieving performance comparable to models trained with i.i.d. samples given the same number of gradient steps.
Layerwise Proximal Replay: A Proximal Point Method for Online Continual Learning
Feb 14, 2024



In online continual learning, a neural network incrementally learns from a non-i.i.d. data stream. Nearly all online continual learning methods employ experience replay to simultaneously prevent catastrophic forgetting and underfitting on past data. Our work demonstrates a limitation of this approach: networks trained with experience replay tend to have unstable optimization trajectories, impeding their overall accuracy. Surprisingly, these instabilities persist even when the replay buffer stores all previous training examples, suggesting that this issue is orthogonal to catastrophic forgetting. We minimize these instabilities through a simple modification of the optimization geometry. Our solution, Layerwise Proximal Replay (LPR), balances learning from new and replay data while only allowing for gradual changes in the hidden activation of past data. We demonstrate that LPR consistently improves replay-based online continual learning methods across multiple problem settings, regardless of the amount of available replay memory.
BayesPCN: A Continually Learnable Predictive Coding Associative Memory
May 20, 2022
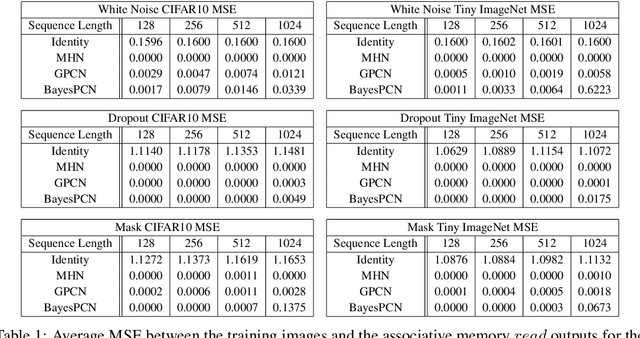
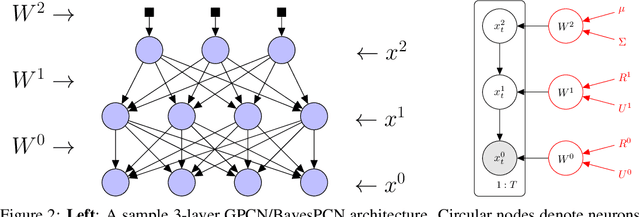

Associative memory plays an important role in human intelligence and its mechanisms have been linked to attention in machine learning. While the machine learning community's interest in associative memories has recently been rekindled, most work has focused on memory recall ($read$) over memory learning ($write$). In this paper, we present BayesPCN, a hierarchical associative memory capable of performing continual one-shot memory writes without meta-learning. Moreover, BayesPCN is able to gradually forget past observations ($forget$) to free its memory. Experiments show that BayesPCN can recall corrupted i.i.d. high-dimensional data observed hundreds of "timesteps" ago without a significant drop in recall ability compared to the state-of-the-art offline-learned associative memory models.
Ensemble Squared: A Meta AutoML System
Dec 10, 2020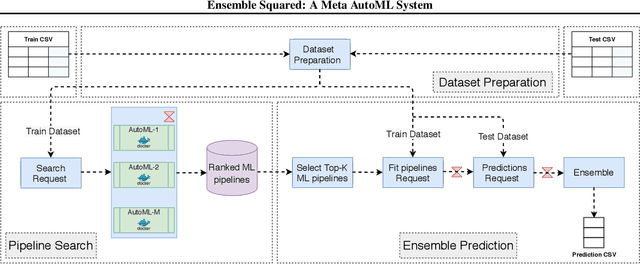
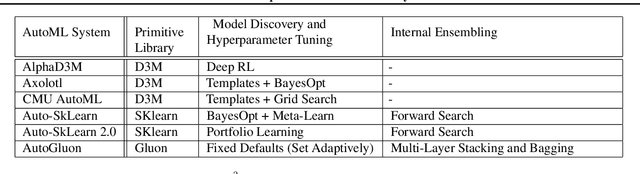
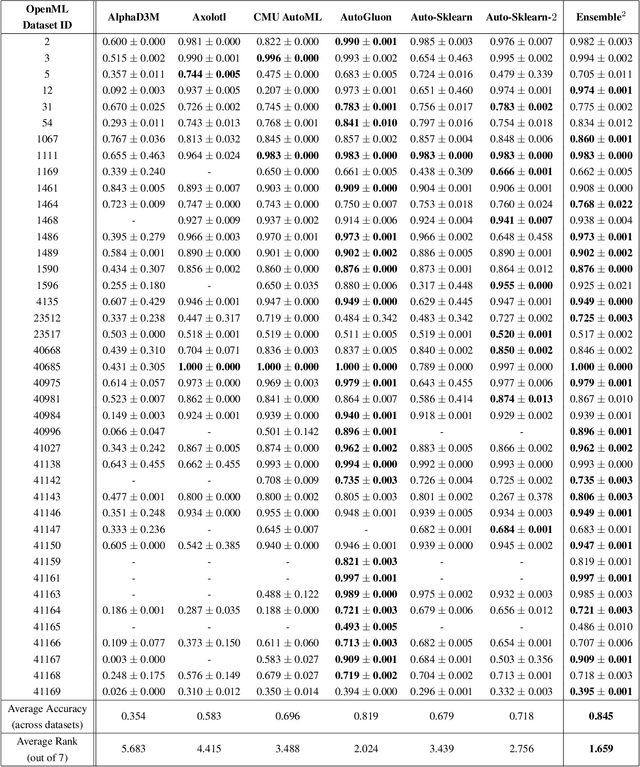
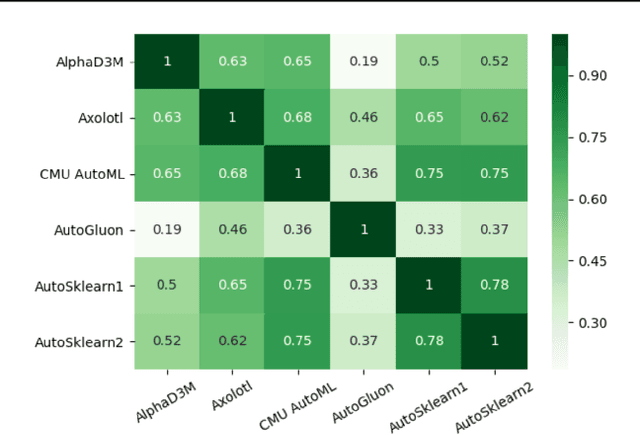
The continuing rise in the number of problems amenable to machine learning solutions, coupled with simultaneous growth in both computing power and variety of machine learning techniques has led to an explosion of interest in automated machine learning (AutoML). This paper presents Ensemble Squared (Ensemble$^2$), a "meta" AutoML system that ensembles at the level of AutoML systems. Ensemble$^2$ exploits the diversity of existing, competing AutoML systems by ensembling the top-performing models simultaneously generated by a set of them. Our work shows that diversity in AutoML systems is sufficient to justify ensembling at the AutoML system level. In demonstrating this, we also establish a new state of the art AutoML result on the OpenML classification challenge.