 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayerwise Proximal Replay: A Proximal Point Method for Online Continual Learning
Feb 14, 2024



In online continual learning, a neural network incrementally learns from a non-i.i.d. data stream. Nearly all online continual learning methods employ experience replay to simultaneously prevent catastrophic forgetting and underfitting on past data. Our work demonstrates a limitation of this approach: networks trained with experience replay tend to have unstable optimization trajectories, impeding their overall accuracy. Surprisingly, these instabilities persist even when the replay buffer stores all previous training examples, suggesting that this issue is orthogonal to catastrophic forgetting. We minimize these instabilities through a simple modification of the optimization geometry. Our solution, Layerwise Proximal Replay (LPR), balances learning from new and replay data while only allowing for gradual changes in the hidden activation of past data. We demonstrate that LPR consistently improves replay-based online continual learning methods across multiple problem settings, regardless of the amount of available replay memory.
Nearest Neighbour Score Estimators for Diffusion Generative Models
Feb 12, 2024



Score function estimation is the cornerstone of both training and sampling from diffusion generative models. Despite this fact, the most commonly used estimators are either biased neural network approximations or high variance Monte Carlo estimators based on the conditional score. We introduce a novel nearest neighbour score function estimator which utilizes multiple samples from the training set to dramatically decrease estimator variance. We leverage our low variance estimator in two compelling applications. Training consistency models with our estimator, we report a significant increase in both convergence speed and sample quality. In diffusion models, we show that our estimator can replace a learned network for probability-flow ODE integration, opening promising new avenues of future research.
A Diffusion-Model of Joint Interactive Navigation
Sep 21, 2023



Simulation of autonomous vehicle systems requires that simulated traffic participants exhibit diverse and realistic behaviors. The use of prerecorded real-world traffic scenarios in simulation ensures realism but the rarity of safety critical events makes large scale collection of driving scenarios expensive. In this paper, we present DJINN - a diffusion based method of generating traffic scenarios. Our approach jointly diffuses the trajectories of all agents, conditioned on a flexible set of state observations from the past, present, or future. On popular trajectory forecasting datasets, we report state of the art performance on joint trajectory metrics. In addition, we demonstrate how DJINN flexibly enables direct test-time sampling from a variety of valuable conditional distributions including goal-based sampling, behavior-class sampling, and scenario editing.
Don't be so negative! Score-based Generative Modeling with Oracle-assisted Guidance
Jul 31, 2023The maximum likelihood principle advocates parameter estimation via optimization of the data likelihood function. Models estimated in this way can exhibit a variety of generalization characteristics dictated by, e.g. architecture, parameterization, and optimization bias. This work addresses model learning in a setting where there further exists side-information in the form of an oracle that can label samples as being outside the support of the true data generating distribution. Specifically we develop a new denoising diffusion probabilistic modeling (DDPM) methodology, Gen-neG, that leverages this additional side-information. Our approach builds on generative adversarial networks (GANs) and discriminator guidance in diffusion models to guide the generation process towards the positive support region indicated by the oracle. We empirically establish the utility of Gen-neG in applications including collision avoidance in self-driving simulators and safety-guarded human motion generation.
Realistically distributing object placements in synthetic training data improves the performance of vision-based object detection models
May 24, 2023When training object detection models on synthetic data, it is important to make the distribution of synthetic data as close as possible to the distribution of real data. We investigate specifically the impact of object placement distribution, keeping all other aspects of synthetic data fixed. Our experiment, training a 3D vehicle detection model in CARLA and testing on KITTI, demonstrates a substantial improvement resulting from improving the object placement distribution.
Video Killed the HD-Map: Predicting Driving Behavior Directly From Drone Images
May 19, 2023The development of algorithms that learn behavioral driving models using human demonstrations has led to increasingly realistic simulations. In general, such models learn to jointly predict trajectories for all controlled agents by exploiting road context information such as drivable lanes obtained from manually annotated high-definition (HD) maps. Recent studies show that these models can greatly benefit from increasing the amount of human data available for training. However, the manual annotation of HD maps which is necessary for every new location puts a bottleneck on efficiently scaling up human traffic datasets. We propose a drone birdview image-based map (DBM) representation that requires minimal annotation and provides rich road context information. We evaluate multi-agent trajectory prediction using the DBM by incorporating it into a differentiable driving simulator as an image-texture-based differentiable rendering module. Our results demonstrate competitive multi-agent trajectory prediction performance when using our DBM representation as compared to models trained with rasterized HD maps.
Visual Chain-of-Thought Diffusion Models
Mar 28, 2023Recent progress with conditional image diffusion models has been stunning, and this holds true whether we are speaking about models conditioned on a text description, a scene layout, or a sketch. Unconditional image diffusion models are also improving but lag behind, as do diffusion models which are conditioned on lower-dimensional features like class labels. We propose to close the gap between conditional and unconditional models using a two-stage sampling procedure. In the first stage we sample an embedding describing the semantic content of the image. In the second stage we sample the image conditioned on this embedding and then discard the embedding. Doing so lets us leverage the power of conditional diffusion models on the unconditional generation task, which we show improves FID by 25-50% compared to standard unconditional generation.
Vehicle Type Specific Waypoint Generation
Aug 09, 2022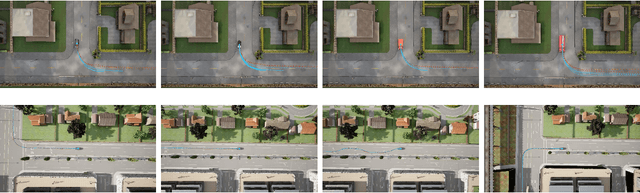
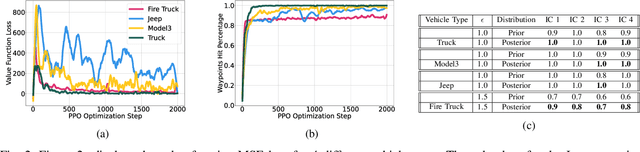
We develop a generic mechanism for generating vehicle-type specific sequences of waypoints from a probabilistic foundation model of driving behavior. Many foundation behavior models are trained on data that does not include vehicle information, which limits their utility in downstream applications such as planning. Our novel methodology conditionally specializes such a behavior predictive model to a vehicle-type by utilizing byproducts of the reinforcement learning algorithms used to produce vehicle specific controllers. We show how to compose a vehicle specific value function estimate with a generic probabilistic behavior model to generate vehicle-type specific waypoint sequences that are more likely to be physically plausible then their vehicle-agnostic counterparts.
Conditional Permutation Invariant Flows
Jun 17, 2022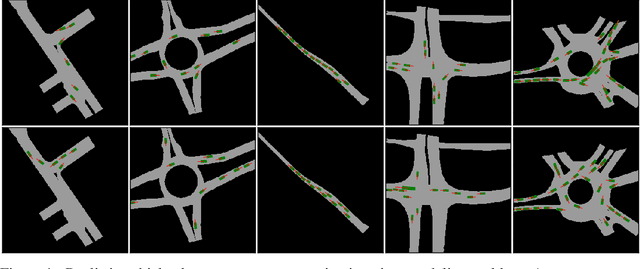
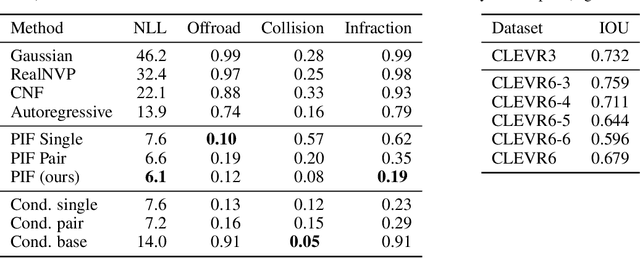
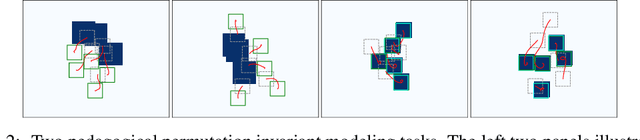
We present a novel, conditional generative probabilistic model of set-valued data with a tractable log density. This model is a continuous normalizing flow governed by permutation equivariant dynamics. These dynamics are driven by a learnable per-set-element term and pairwise interactions, both parametrized by deep neural networks. We illustrate the utility of this model via applications including (1) complex traffic scene generation conditioned on visually specified map information, and (2) object bounding box generation conditioned directly on images. We train our model by maximizing the expected likelihood of labeled conditional data under our flow, with the aid of a penalty that ensures the dynamics are smooth and hence efficiently solvable. Our method significantly outperforms non-permutation invariant baselines in terms of log likelihood and domain-specific metrics (offroad, collision, and combined infractions), yielding realistic samples that are difficult to distinguish from real data.
Critic Sequential Monte Carlo
May 30, 2022
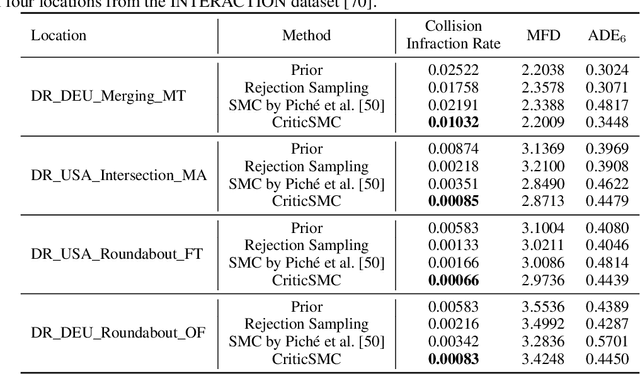
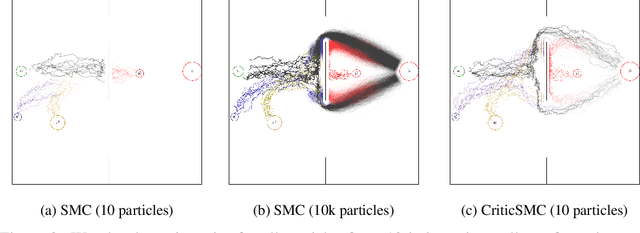
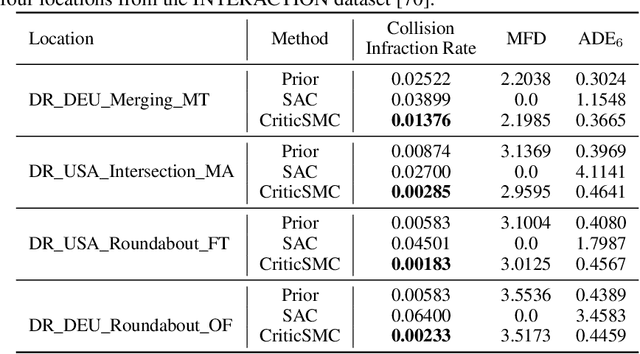
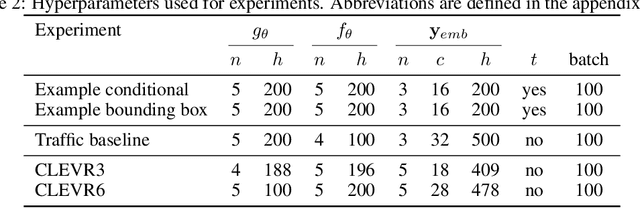
We introduce CriticSMC, a new algorithm for planning as inference built from a novel composition of sequential Monte Carlo with learned soft-Q function heuristic factors. This algorithm is structured so as to allow using large numbers of putative particles leading to efficient utilization of computational resource and effective discovery of high reward trajectories even in environments with difficult reward surfaces such as those arising from hard constraints. Relative to prior art our approach is notably still compatible with model-free reinforcement learning in the sense that the implicit policy we produce can be used at test time in the absence of a world model. Our experiments on self-driving car collision avoidance in simulation demonstrate improvements against baselines in terms of infraction minimization relative to computational effort while maintaining diversity and realism of found trajectories.