 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoice of India: A Large-Scale Benchmark for Real-World Speech Recognition in India
Apr 21, 2026Existing Indic ASR benchmarks often use scripted, clean speech and leaderboard driven evaluation that encourages dataset specific overfitting. In addition, strict single reference WER penalizes natural spelling variation in Indian languages, including non standardized spellings of code-mixed English origin words. To address these limitations, we introduce Voice of India, a closed source benchmark built from unscripted telephonic conversations covering 15 major Indian languages across 139 regional clusters. The dataset contains 306230 utterances, totaling 536 hours of speech from 36691 speakers with transcripts accounting for spelling variations. We also analyze performance geographically at the district level, revealing disparities. Finally, we provide detailed analysis across factors such as audio quality, speaking rate, gender, and device type, highlighting where current ASR systems struggle and offering insights for improving real world Indic ASR systems.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Density Weighting for Multi-Interest Personalized Recommendation
Aug 03, 2023



Using multiple user representations (MUR) to model user behavior instead of a single user representation (SUR) has been shown to improve personalization in recommendation systems. However, the performance gains observed with MUR can be sensitive to the skewness in the item and/or user interest distribution. When the data distribution is highly skewed, the gains observed by learning multiple representations diminish since the model dominates on head items/interests, leading to poor performance on tail items. Robustness to data sparsity is therefore essential for MUR-based approaches to achieve good performance for recommendations. Yet, research in MUR and data imbalance have largely been done independently. In this paper, we delve deeper into the shortcomings of MUR inferred from imbalanced data distributions. We make several contributions: (1) Using synthetic datasets, we demonstrate the sensitivity of MUR with respect to data imbalance, (2) To improve MUR for tail items, we propose an iterative density weighting scheme (IDW) with user tower calibration to mitigate the effect of training over long-tail distribution on personalization, and (3) Through extensive experiments on three real-world benchmarks, we demonstrate IDW outperforms other alternatives that address data imbalance.
Algorithms for Efficiently Learning Low-Rank Neural Networks
Feb 03, 2022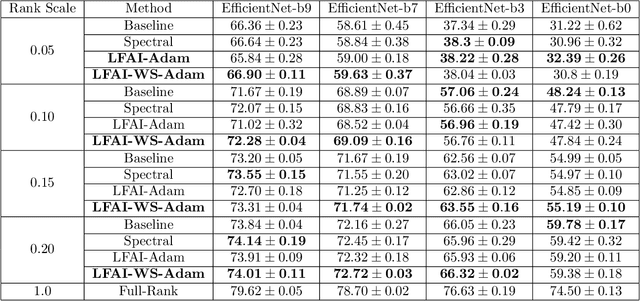
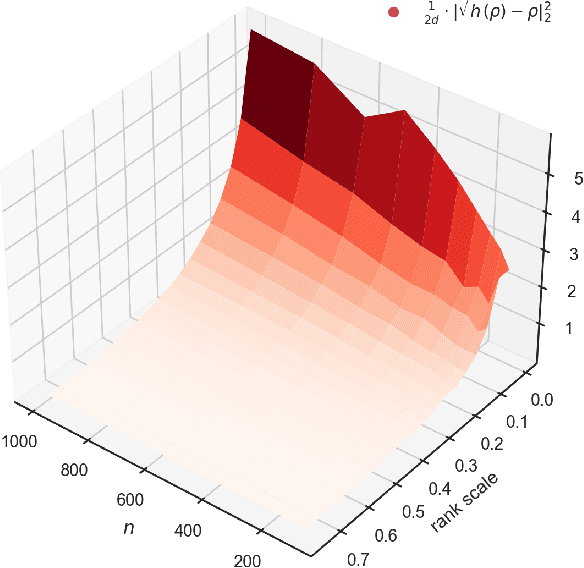
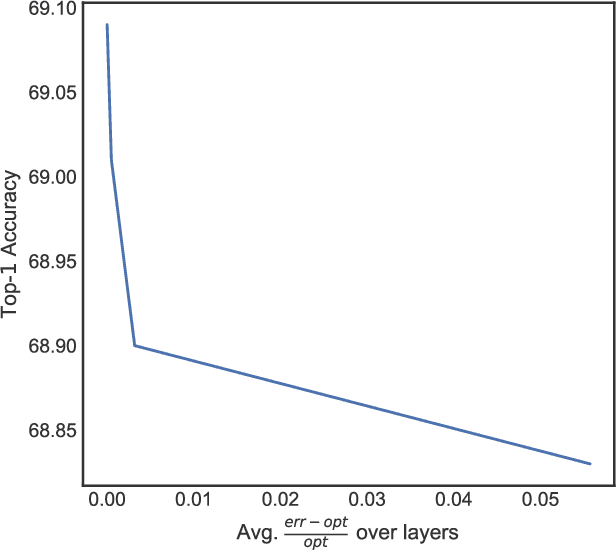

We study algorithms for learning low-rank neural networks -- networks where the weight parameters are re-parameterized by products of two low-rank matrices. First, we present a provably efficient algorithm which learns an optimal low-rank approximation to a single-hidden-layer ReLU network up to additive error $\epsilon$ with probability $\ge 1 - \delta$, given access to noiseless samples with Gaussian marginals in polynomial time and samples. Thus, we provide the first example of an algorithm which can efficiently learn a neural network up to additive error without assuming the ground truth is realizable. To solve this problem, we introduce an efficient SVD-based $\textit{Nonlinear Kernel Projection}$ algorithm for solving a nonlinear low-rank approximation problem over Gaussian space. Inspired by the efficiency of our algorithm, we propose a novel low-rank initialization framework for training low-rank $\textit{deep}$ networks, and prove that for ReLU networks, the gap between our method and existing schemes widens as the desired rank of the approximating weights decreases, or as the dimension of the inputs increases (the latter point holds when network width is superlinear in dimension). Finally, we validate our theory by training ResNet and EfficientNet models on ImageNet.
DCN-M: Improved Deep & Cross Network for Feature Cross Learning in Web-scale Learning to Rank Systems
Aug 19, 2020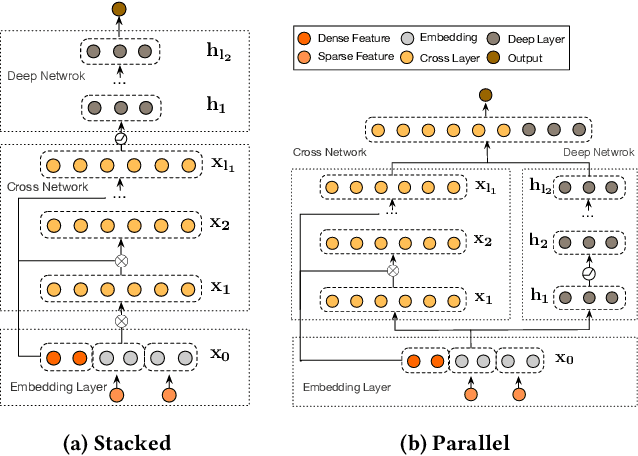
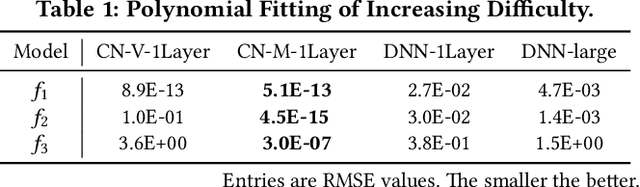
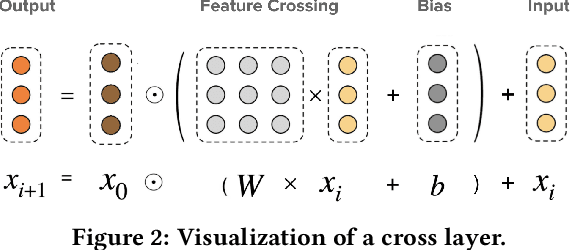

Learning effective feature crosses is the key behind building recommender systems. However, the sparse and large feature space requires exhaustive search to identify effective crosses. Deep & Cross Network (DCN) was proposed to automatically and efficiently learn bounded-degree predictive feature interactions. Unfortunately, in models that serve web-scale traffic with billions of training examples, DCN showed limited expressiveness in its cross network at learning more predictive feature interactions. Despite significant research progress made, many deep learning models in production still rely on traditional feed-forward neural networks to learn feature crosses inefficiently. In light of the pros/cons of DCN and existing feature interaction learning approaches, we propose an improved framework DCN-M to make DCN more practical in large-scale industrial settings. In a comprehensive experimental study with extensive hyper-parameter search and model tuning, we observed that DCN-M approaches outperform all the state-of-the-art algorithms on popular benchmark datasets. The improved DCN-M is more expressive yet remains cost efficient at feature interaction learning, especially when coupled with a mixture of low-rank architecture. DCN-M is simple, can be easily adopted as building blocks, and has delivered significant offline accuracy and online business metrics gains across many web-scale learning to rank systems.
Understanding and Improving Knowledge Distillation
Feb 10, 2020
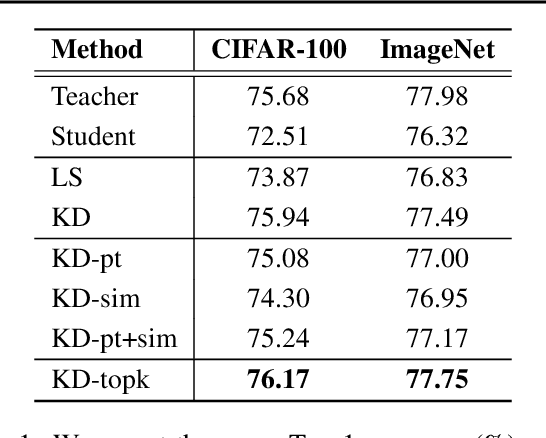
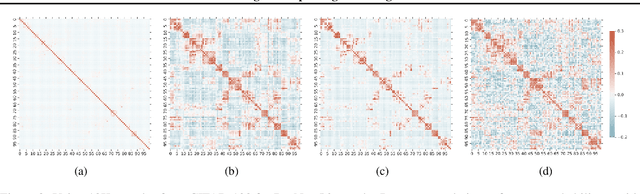
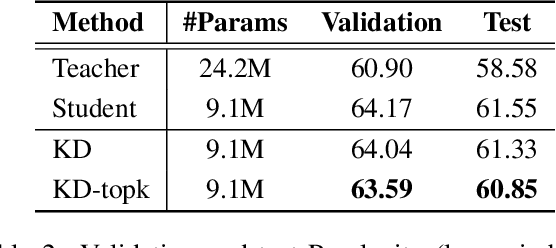
Knowledge distillation is a model-agnostic technique to improve model quality while having a fixed capacity budget. It is a commonly used technique for model compression, where a higher capacity teacher model with better quality is used to train a more compact student model with better inference efficiency. Through distillation, one hopes to benefit from student's compactness, without sacrificing too much on model quality. Despite the large success of knowledge distillation, better understanding of how it benefits student model's training dynamics remains under-explored. In this paper, we dissect the effects of knowledge distillation into three main factors: (1) benefits inherited from label smoothing, (2) example re-weighting based on teacher's confidence on ground-truth, and (3) prior knowledge of optimal output (logit) layer geometry. Using extensive systematic analyses and empirical studies on synthetic and real-world datasets, we confirm that the aforementioned three factors play a major role in knowledge distillation. Furthermore, based on our findings, we propose a simple, yet effective technique to improve knowledge distillation empirically.
Towards Neural Mixture Recommender for Long Range Dependent User Sequences
Feb 22, 2019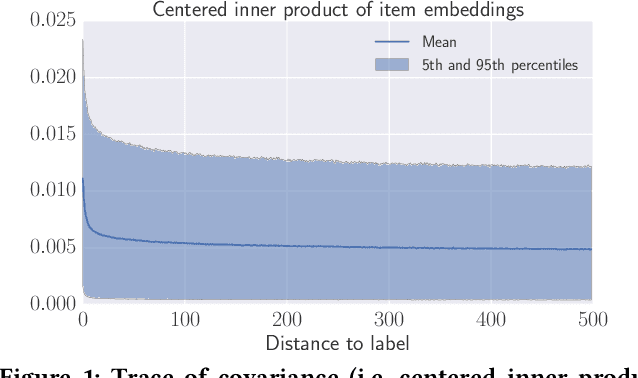

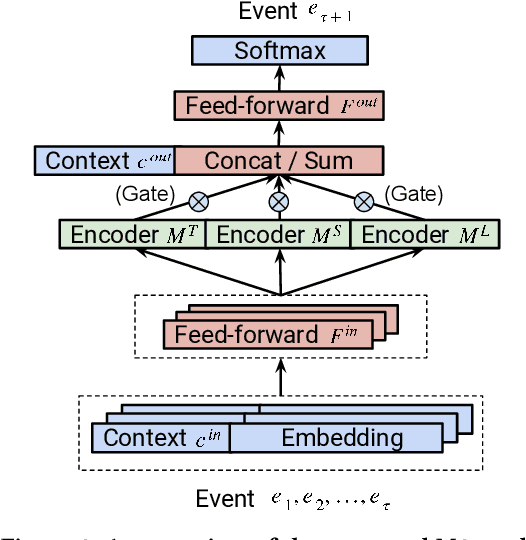
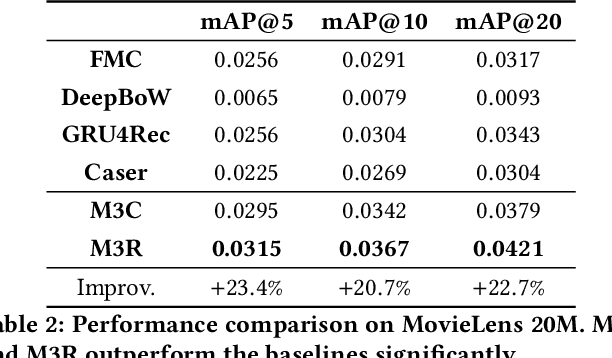
Understanding temporal dynamics has proved to be highly valuable for accurate recommendation. Sequential recommenders have been successful in modeling the dynamics of users and items over time. However, while different model architectures excel at capturing various temporal ranges or dynamics, distinct application contexts require adapting to diverse behaviors. In this paper we examine how to build a model that can make use of different temporal ranges and dynamics depending on the request context. We begin with the analysis of an anonymized Youtube dataset comprising millions of user sequences. We quantify the degree of long-range dependence in these sequences and demonstrate that both short-term and long-term dependent behavioral patterns co-exist. We then propose a neural Multi-temporal-range Mixture Model (M3) as a tailored solution to deal with both short-term and long-term dependencies. Our approach employs a mixture of models, each with a different temporal range. These models are combined by a learned gating mechanism capable of exerting different model combinations given different contextual information. In empirical evaluations on a public dataset and our own anonymized YouTube dataset, M3 consistently outperforms state-of-the-art sequential recommendation methods.
Top-K Off-Policy Correction for a REINFORCE Recommender System
Dec 06, 2018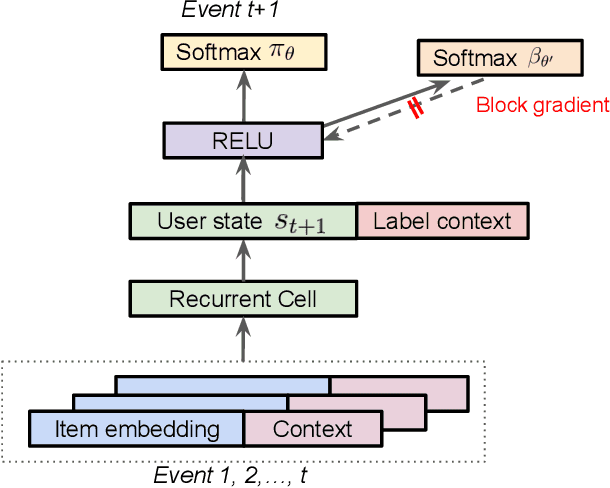
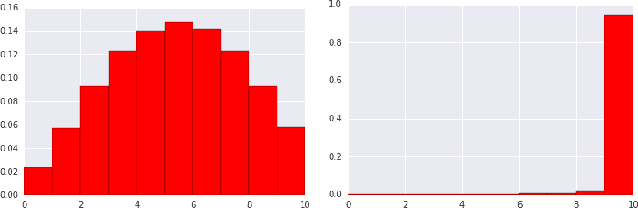
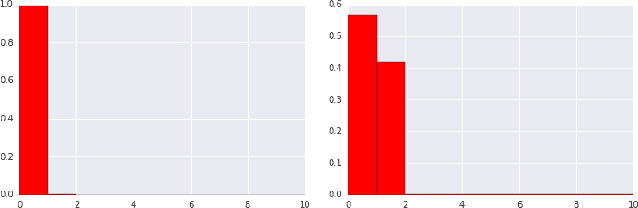
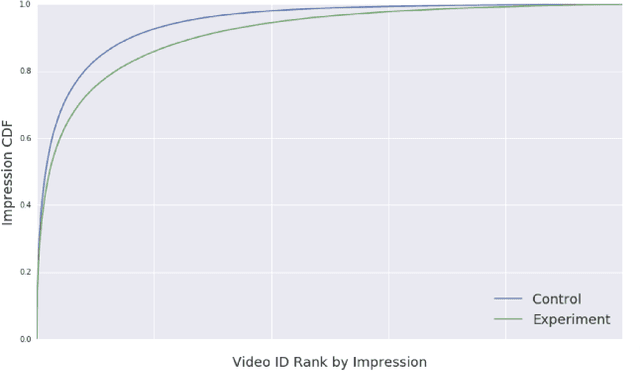
Industrial recommender systems deal with extremely large action spaces -- many millions of items to recommend. Moreover, they need to serve billions of users, who are unique at any point in time, making a complex user state space. Luckily, huge quantities of logged implicit feedback (e.g., user clicks, dwell time) are available for learning. Learning from the logged feedback is however subject to biases caused by only observing feedback on recommendations selected by the previous versions of the recommender. In this work, we present a general recipe of addressing such biases in a production top-K recommender system at Youtube, built with a policy-gradient-based algorithm, i.e. REINFORCE. The contributions of the paper are: (1) scaling REINFORCE to a production recommender system with an action space on the orders of millions; (2) applying off-policy correction to address data biases in learning from logged feedback collected from multiple behavior policies; (3) proposing a novel top-K off-policy correction to account for our policy recommending multiple items at a time; (4) showcasing the value of exploration. We demonstrate the efficacy of our approaches through a series of simulations and multiple live experiments on Youtube.
Seq2Slate: Re-ranking and Slate Optimization with RNNs
Oct 04, 2018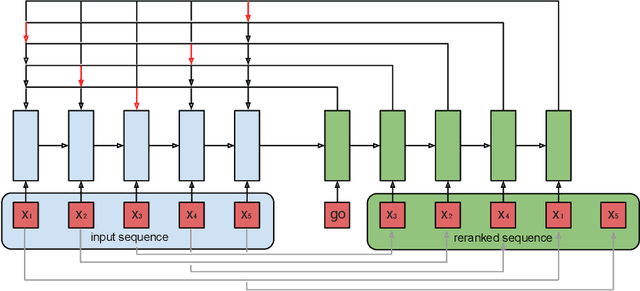
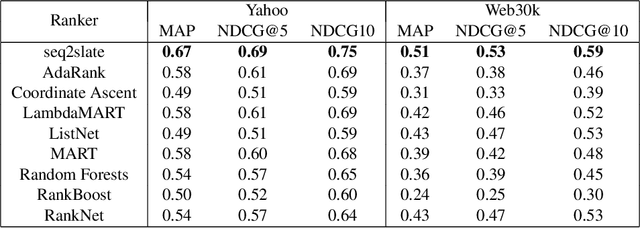

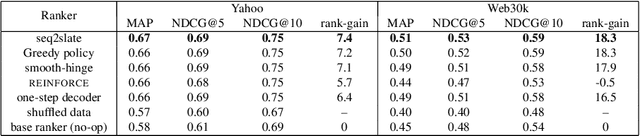
Ranking is a central task in machine learning and information retrieval. In this task, it is especially important to present the user with a slate of items that is appealing as a whole. This in turn requires taking into account interactions between items, since intuitively, placing an item on the slate affects the decision of which other items should be placed alongside it. In this work, we propose a sequence-to-sequence model for ranking called seq2slate. At each step, the model predicts the next item to place on the slate given the items already selected. The recurrent nature of the model allows complex dependencies between items to be captured directly in a flexible and scalable way. We show how to learn the model end-to-end from weak supervision in the form of easily obtained click-through data. We further demonstrate the usefulness of our approach in experiments on standard ranking benchmarks as well as in a real-world recommendation system.