 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-rank Gradient Approximation For Memory-Efficient On-device Training of Deep Neural Network
Jan 24, 2020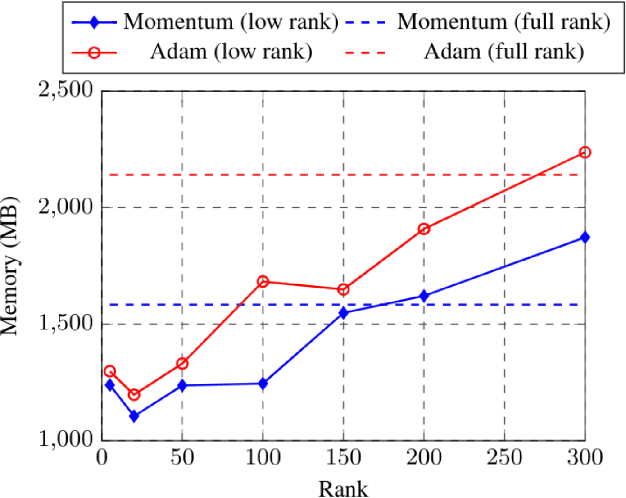
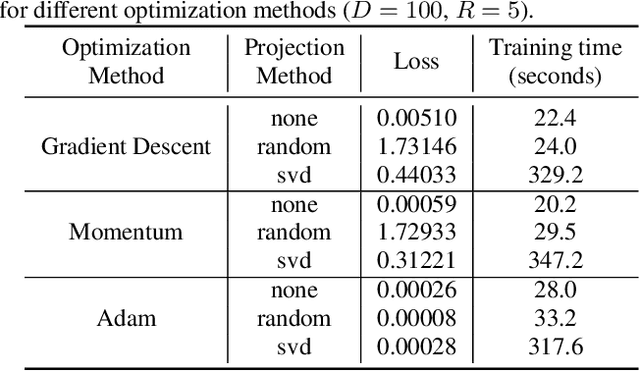
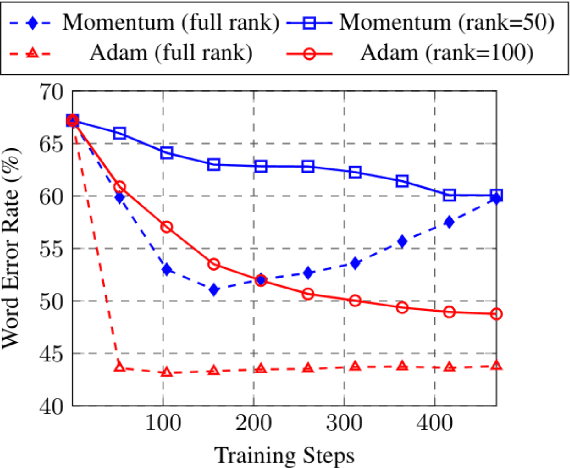
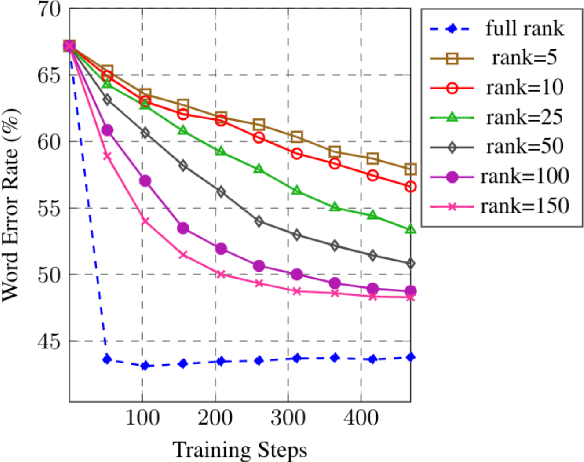
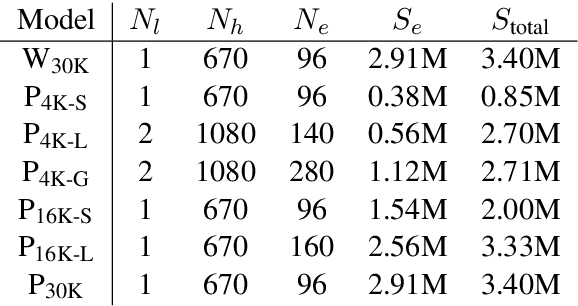
Training machine learning models on mobile devices has the potential of improving both privacy and accuracy of the models. However, one of the major obstacles to achieving this goal is the memory limitation of mobile devices. Reducing training memory enables models with high-dimensional weight matrices, like automatic speech recognition (ASR) models, to be trained on-device. In this paper, we propose approximating the gradient matrices of deep neural networks using a low-rank parameterization as an avenue to save training memory. The low-rank gradient approximation enables more advanced, memory-intensive optimization techniques to be run on device. Our experimental results show that we can reduce the training memory by about 33.0% for Adam optimization. It uses comparable memory to momentum optimization and achieves a 4.5% relative lower word error rate on an ASR personalization task.
Personalization of End-to-end Speech Recognition On Mobile Devices For Named Entities
Dec 14, 2019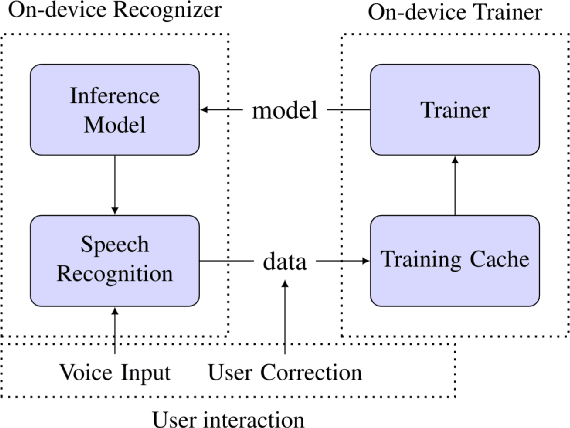
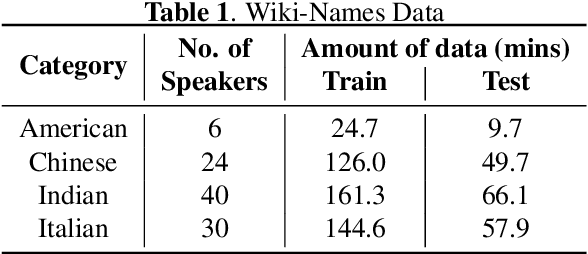
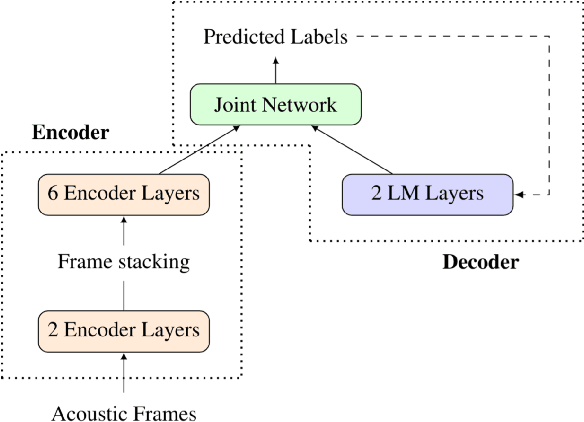
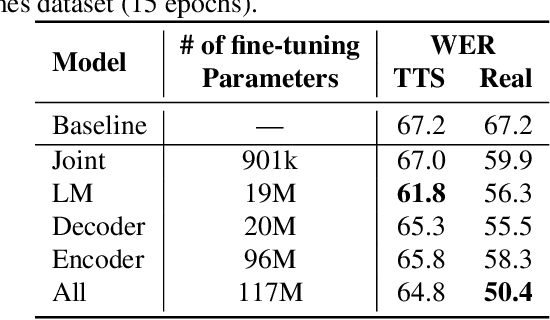
We study the effectiveness of several techniques to personalize end-to-end speech models and improve the recognition of proper names relevant to the user. These techniques differ in the amounts of user effort required to provide supervision, and are evaluated on how they impact speech recognition performance. We propose using keyword-dependent precision and recall metrics to measure vocabulary acquisition performance. We evaluate the algorithms on a dataset that we designed to contain names of persons that are difficult to recognize. Therefore, the baseline recall rate for proper names in this dataset is very low: 2.4%. A data synthesis approach we developed brings it to 48.6%, with no need for speech input from the user. With speech input, if the user corrects only the names, the name recall rate improves to 64.4%. If the user corrects all the recognition errors, we achieve the best recall of 73.5%. To eliminate the need to upload user data and store personalized models on a server, we focus on performing the entire personalization workflow on a mobile device.
Writing Across the World's Languages: Deep Internationalization for Gboard, the Google Keyboard
Dec 03, 2019This technical report describes our deep internationalization program for Gboard, the Google Keyboard. Today, Gboard supports 900+ language varieties across 70+ writing systems, and this report describes how and why we have been adding support for hundreds of language varieties from around the globe. Many languages of the world are increasingly used in writing on an everyday basis, and we describe the trends we see. We cover technological and logistical challenges in scaling up a language technology product like Gboard to hundreds of language varieties, and describe how we built systems and processes to operate at scale. Finally, we summarize the key take-aways from user studies we ran with speakers of hundreds of languages from around the world.
Federated Evaluation of On-device Personalization
Oct 22, 2019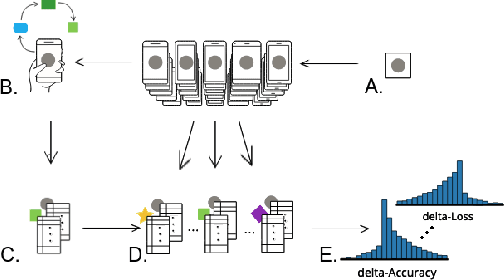
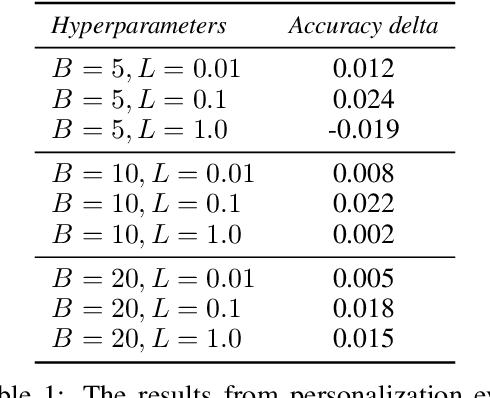
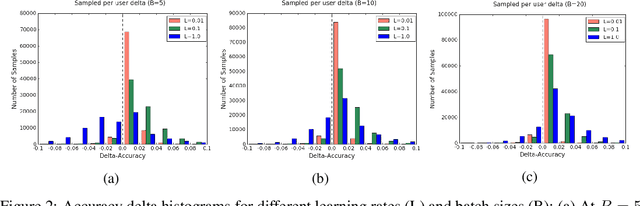
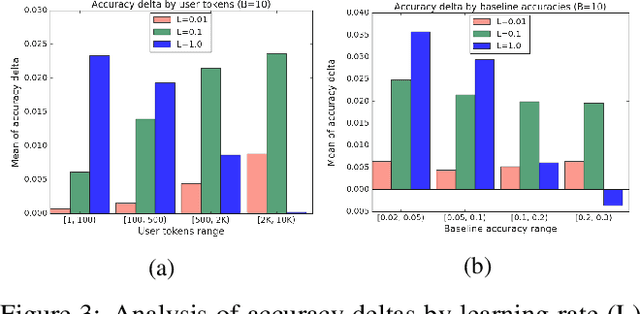
Federated learning is a distributed, on-device computation framework that enables training global models without exporting sensitive user data to servers. In this work, we describe methods to extend the federation framework to evaluate strategies for personalization of global models. We present tools to analyze the effects of personalization and evaluate conditions under which personalization yields desirable models. We report on our experiments personalizing a language model for a virtual keyboard for smartphones with a population of tens of millions of users. We show that a significant fraction of users benefit from personalization.
Federated Learning of N-gram Language Models
Oct 08, 2019

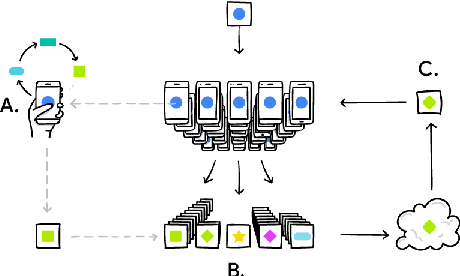
We propose algorithms to train production-quality n-gram language models using federated learning. Federated learning is a distributed computation platform that can be used to train global models for portable devices such as smart phones. Federated learning is especially relevant for applications handling privacy-sensitive data, such as virtual keyboards, because training is performed without the users' data ever leaving their devices. While the principles of federated learning are fairly generic, its methodology assumes that the underlying models are neural networks. However, virtual keyboards are typically powered by n-gram language models for latency reasons. We propose to train a recurrent neural network language model using the decentralized FederatedAveraging algorithm and to approximate this federated model server-side with an n-gram model that can be deployed to devices for fast inference. Our technical contributions include ways of handling large vocabularies, algorithms to correct capitalization errors in user data, and efficient finite state transducer algorithms to convert word language models to word-piece language models and vice versa. The n-gram language models trained with federated learning are compared to n-grams trained with traditional server-based algorithms using A/B tests on tens of millions of users of virtual keyboard. Results are presented for two languages, American English and Brazilian Portuguese. This work demonstrates that high-quality n-gram language models can be trained directly on client mobile devices without sensitive training data ever leaving the devices.
An Investigation Into On-device Personalization of End-to-end Automatic Speech Recognition Models
Sep 14, 2019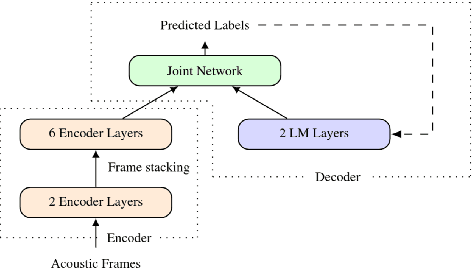
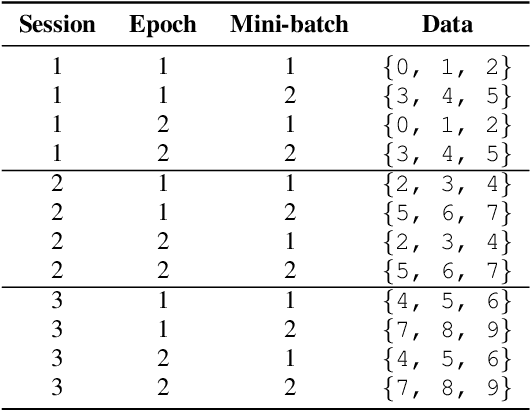
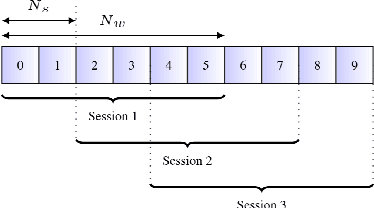
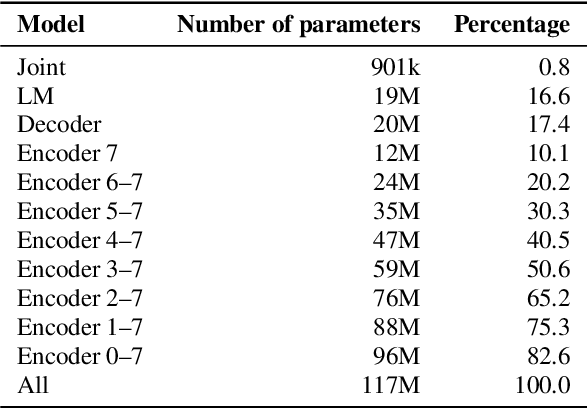
Speaker-independent speech recognition systems trained with data from many users are generally robust against speaker variability and work well for a large population of speakers. However, these systems do not always generalize well for users with very different speech characteristics. This issue can be addressed by building personalized systems that are designed to work well for each specific user. In this paper, we investigate the idea of securely training personalized end-to-end speech recognition models on mobile devices so that user data and models never leave the device and are never stored on a server. We study how the mobile training environment impacts performance by simulating on-device data consumption. We conduct experiments using data collected from speech impaired users for personalization. Our results show that personalization achieved 63.7\% relative word error rate reduction when trained in a server environment and 58.1% in a mobile environment. Moving to on-device personalization resulted in 18.7% performance degradation, in exchange for improved scalability and data privacy. To train the model on device, we split the gradient computation into two and achieved 45% memory reduction at the expense of 42% increase in training time.
Federated Learning for Emoji Prediction in a Mobile Keyboard
Jun 11, 2019

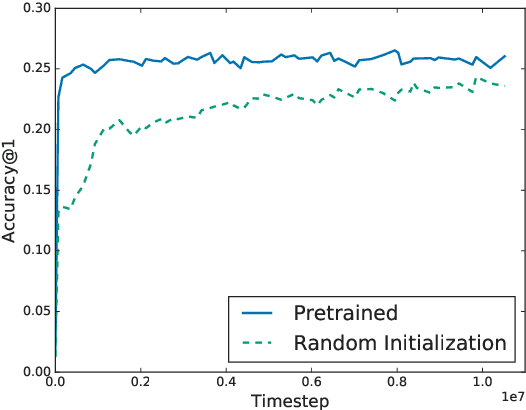
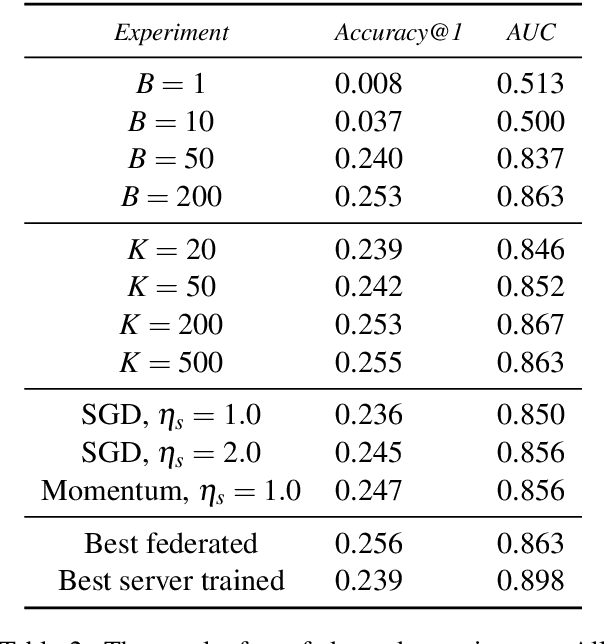
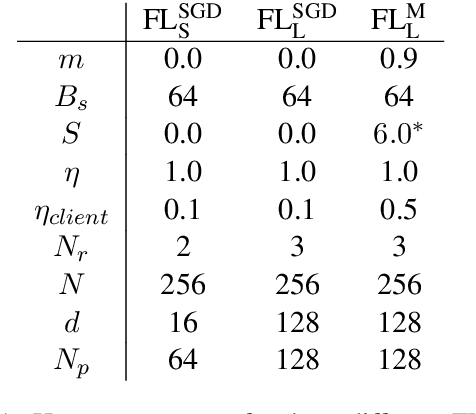
We show that a word-level recurrent neural network can predict emoji from text typed on a mobile keyboard. We demonstrate the usefulness of transfer learning for predicting emoji by pretraining the model using a language modeling task. We also propose mechanisms to trigger emoji and tune the diversity of candidates. The model is trained using a distributed on-device learning framework called federated learning. The federated model is shown to achieve better performance than a server-trained model. This work demonstrates the feasibility of using federated learning to train production-quality models for natural language understanding tasks while keeping users' data on their devices.
Federated Learning Of Out-Of-Vocabulary Words
Mar 26, 2019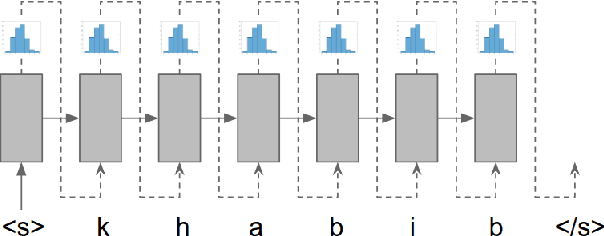
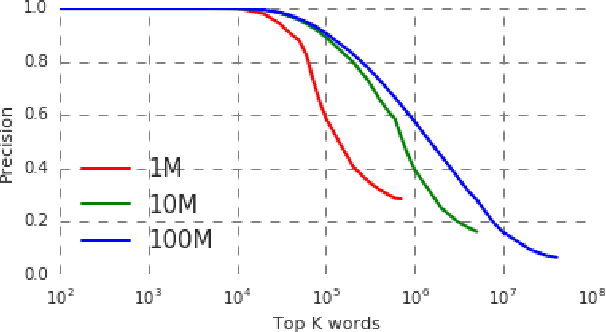

We demonstrate that a character-level recurrent neural network is able to learn out-of-vocabulary (OOV) words under federated learning settings, for the purpose of expanding the vocabulary of a virtual keyboard for smartphones without exporting sensitive text to servers. High-frequency words can be sampled from the trained generative model by drawing from the joint posterior directly. We study the feasibility of the approach in two settings: (1) using simulated federated learning on a publicly available non-IID per-user dataset from a popular social networking website, (2) using federated learning on data hosted on user mobile devices. The model achieves good recall and precision compared to ground-truth OOV words in setting (1). With (2) we demonstrate the practicality of this approach by showing that we can learn meaningful OOV words with good character-level prediction accuracy and cross entropy loss.
Applied Federated Learning: Improving Google Keyboard Query Suggestions
Dec 07, 2018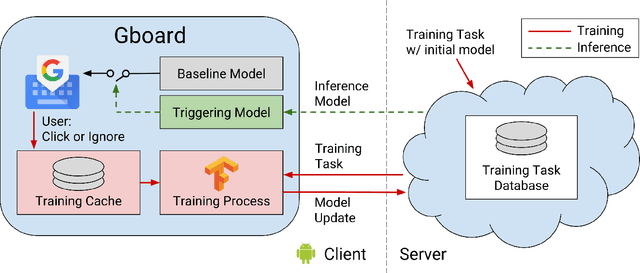

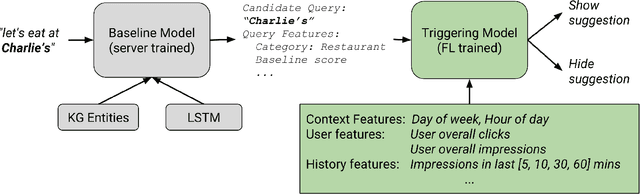

Federated learning is a distributed form of machine learning where both the training data and model training are decentralized. In this paper, we use federated learning in a commercial, global-scale setting to train, evaluate and deploy a model to improve virtual keyboard search suggestion quality without direct access to the underlying user data. We describe our observations in federated training, compare metrics to live deployments, and present resulting quality increases. In whole, we demonstrate how federated learning can be applied end-to-end to both improve user experiences and enhance user privacy.
Federated Learning for Mobile Keyboard Prediction
Nov 08, 2018

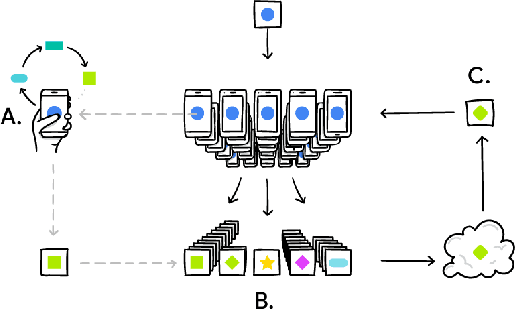

We train a recurrent neural network language model using a distributed, on-device learning framework called federated learning for the purpose of next-word prediction in a virtual keyboard for smartphones. Server-based training using stochastic gradient descent is compared with training on client devices using the Federated Averaging algorithm. The federated algorithm, which enables training on a higher-quality dataset for this use case, is shown to achieve better prediction recall. This work demonstrates the feasibility and benefit of training language models on client devices without exporting sensitive user data to servers. The federated learning environment gives users greater control over their data and simplifies the task of incorporating privacy by default with distributed training and aggregation across a population of client devices.