 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Multiview Correlations in Open-Domain Videos
Nov 21, 2018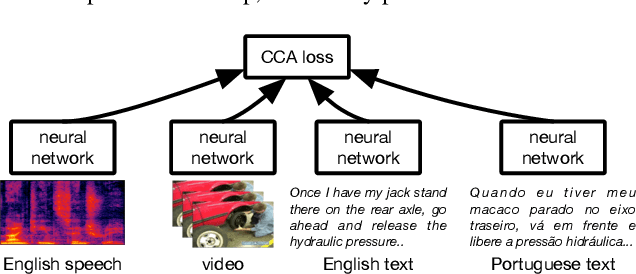
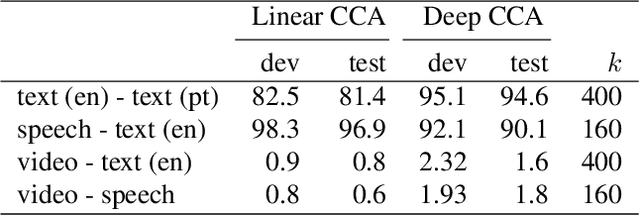
An increasing number of datasets contain multiple views, such as video, sound and automatic captions. A basic challenge in representation learning is how to leverage multiple views to learn better representations. This is further complicated by the existence of a latent alignment between views, such as between speech and its transcription, and by the multitude of choices for the learning objective. We explore an advanced, correlation-based representation learning method on a 4-way parallel, multimodal dataset, and assess the quality of the learned representations on retrieval-based tasks. We show that the proposed approach produces rich representations that capture most of the information shared across views. Our best models for speech and textual modalities achieve retrieval rates from 70.7% to 96.9% on open-domain, user-generated instructional videos. This shows it is possible to learn reliable representations across disparate, unaligned and noisy modalities, and encourages using the proposed approach on larger datasets.
Multimodal Grounding for Sequence-to-Sequence Speech Recognition
Nov 09, 2018
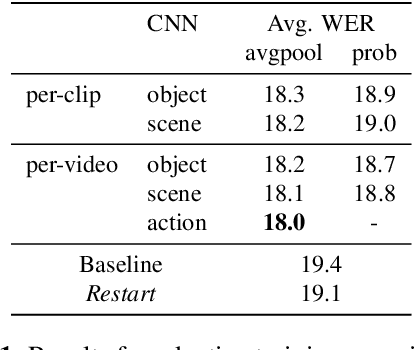
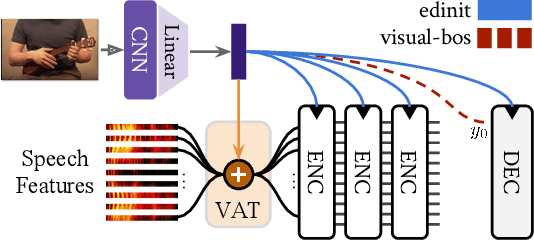
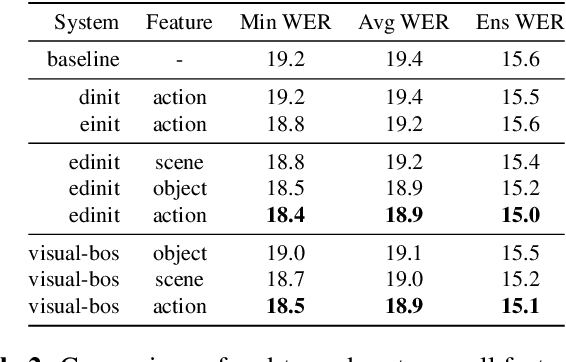
Humans are capable of processing speech by making use of multiple sensory modalities. For example, the environment where a conversation takes place generally provides semantic and/or acoustic context that helps us to resolve ambiguities or to recall named entities. Motivated by this, there have been many works studying the integration of visual information into the speech recognition pipeline. Specifically, in our previous work, we propose a multistep visual adaptive training approach which improves the accuracy of an audio-based Automatic Speech Recognition (ASR) system. This approach, however, is not end-to-end as it requires fine-tuning the whole model with an adaptation layer. In this paper, we propose novel end-to-end multimodal ASR systems and compare them to the adaptive approach by using a range of visual representations obtained from state-of-the-art convolutional neural networks. We show that adaptive training is effective for S2S models leading to an absolute improvement of 1.4% in word error rate. As for the end-to-end systems, although they perform better than baseline, the improvements are slightly less than adaptive training, 0.8 absolute WER reduction in single-best models. Using ensemble decoding, end-to-end models reach a WER of 15% which is the lowest score among all systems.
How2: A Large-scale Dataset for Multimodal Language Understanding
Nov 01, 2018
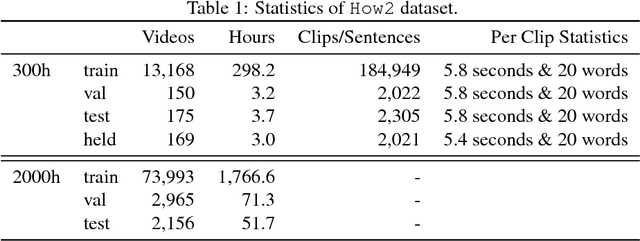
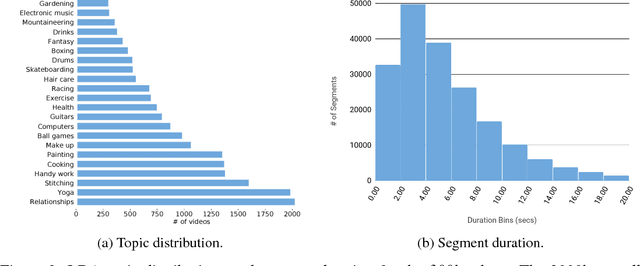

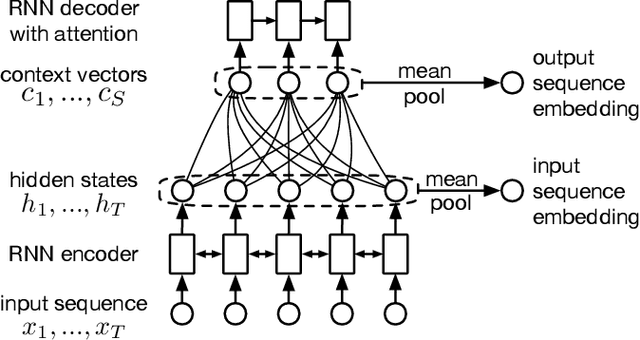
In this paper, we introduce How2, a multimodal collection of instructional videos with English subtitles and crowdsourced Portuguese translations. We also present integrated sequence-to-sequence baselines for machine translation, automatic speech recognition, spoken language translation, and multimodal summarization. By making available data and code for several multimodal natural language tasks, we hope to stimulate more research on these and similar challenges, to obtain a deeper understanding of multimodality in language processing.
Domain Robust Feature Extraction for Rapid Low Resource ASR Development
Sep 30, 2018
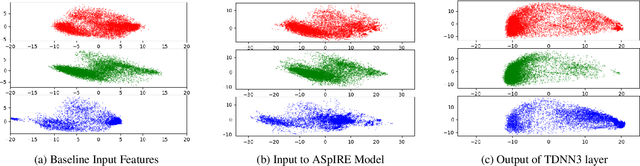

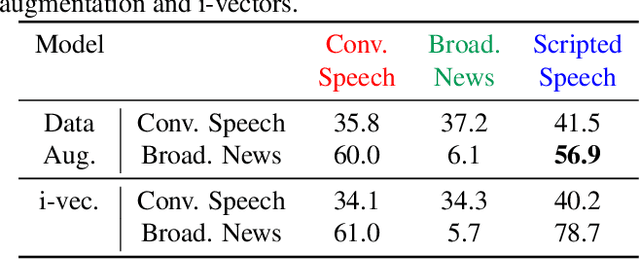
Developing a practical speech recognizer for a low resource language is challenging, not only because of the (potentially unknown) properties of the language, but also because test data may not be from the same domain as the available training data. In this paper, we focus on the latter challenge, i.e. domain mismatch, for systems trained using a sequence-based criterion. We demonstrate the effectiveness of using a pre-trained English recognizer, which is robust to such mismatched conditions, as a domain normalizing feature extractor on a low resource language. In our example, we use Turkish Conversational Speech and Broadcast News data. This enables rapid development of speech recognizers for new languages which can easily adapt to any domain. Testing in various cross-domain scenarios, we achieve relative improvements of around 25% in phoneme error rate, with improvements being around 50% for some domains.
Activity Recognition on a Large Scale in Short Videos - Moments in Time Dataset
Sep 13, 2018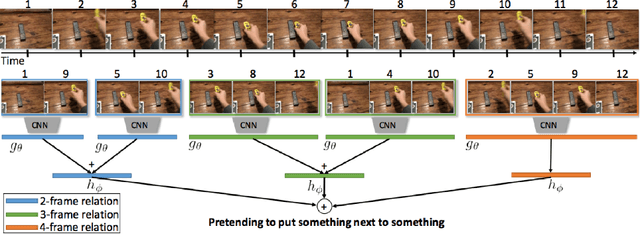
Moments capture a huge part of our lives. Accurate recognition of these moments is challenging due to the diverse and complex interpretation of the moments. Action recognition refers to the act of classifying the desired action/activity present in a given video. In this work, we perform experiments on Moments in Time dataset to recognize accurately activities occurring in 3 second clips. We use state of the art techniques for visual, auditory and spatio temporal localization and develop method to accurately classify the activity in the Moments in Time dataset. Our novel approach of using Visual Based Textual features and fusion techniques performs well providing an overall 89.23 % Top - 5 accuracy on the 20 classes - a significant improvement over the Baseline TRN model.
Acoustic-to-Word Recognition with Sequence-to-Sequence Models
Aug 21, 2018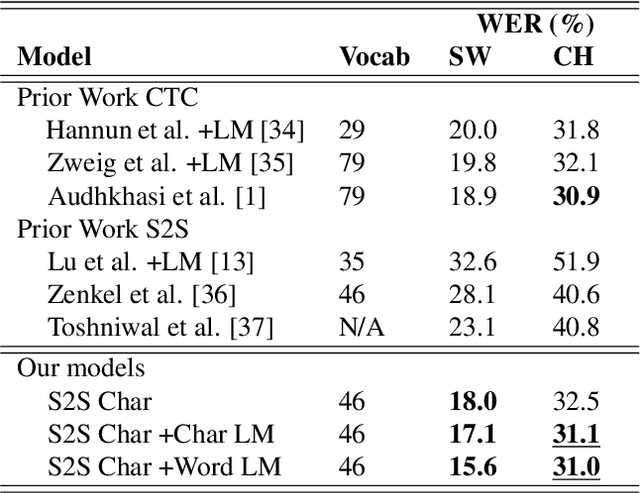
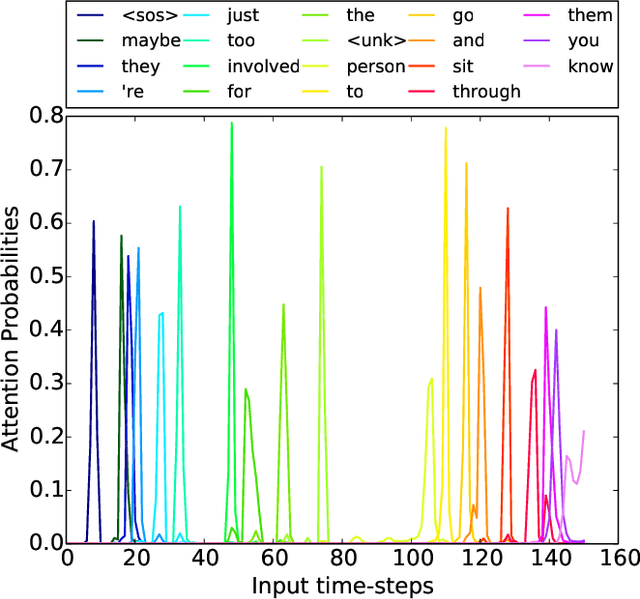
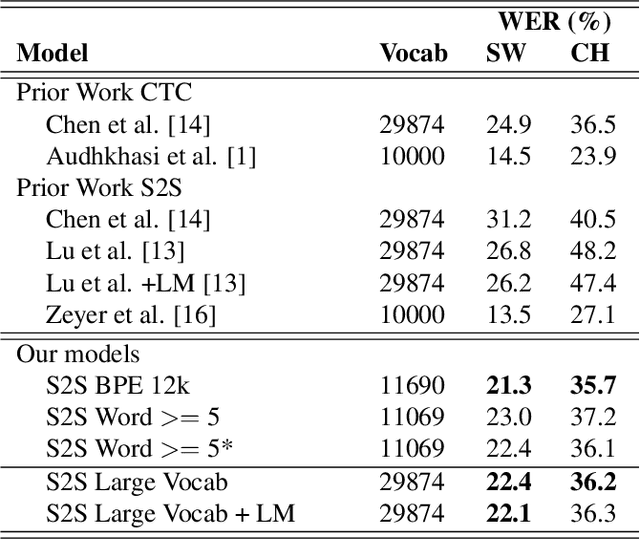
Acoustic-to-Word recognition provides a straightforward solution to end-to-end speech recognition without needing external decoding, language model re-scoring or lexicon. While character-based models offer a natural solution to the out-of-vocabulary problem, word models can be simpler to decode and may also be able to directly recognize semantically meaningful units. We present effective methods to train Sequence-to-Sequence models for direct word-level recognition (and character-level recognition) and show an absolute improvement of 4.4-5.0\% in Word Error Rate on the Switchboard corpus compared to prior work. In addition to these promising results, word-based models are more interpretable than character models, which have to be composed into words using a separate decoding step. We analyze the encoder hidden states and the attention behavior, and show that location-aware attention naturally represents words as a single speech-word-vector, despite spanning multiple frames in the input. We finally show that the Acoustic-to-Word model also learns to segment speech into words with a mean standard deviation of 3 frames as compared with human annotated forced-alignments for the Switchboard corpus.
Dialog-context aware end-to-end speech recognition
Aug 07, 2018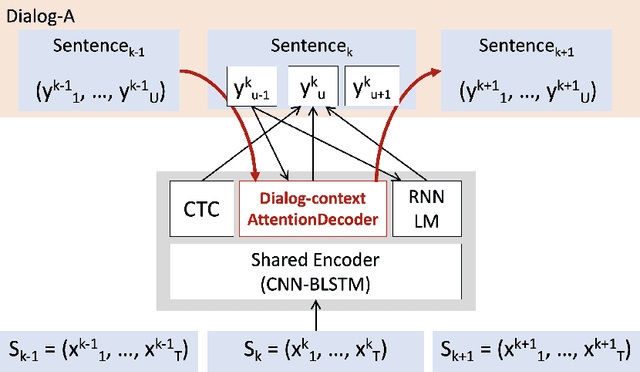

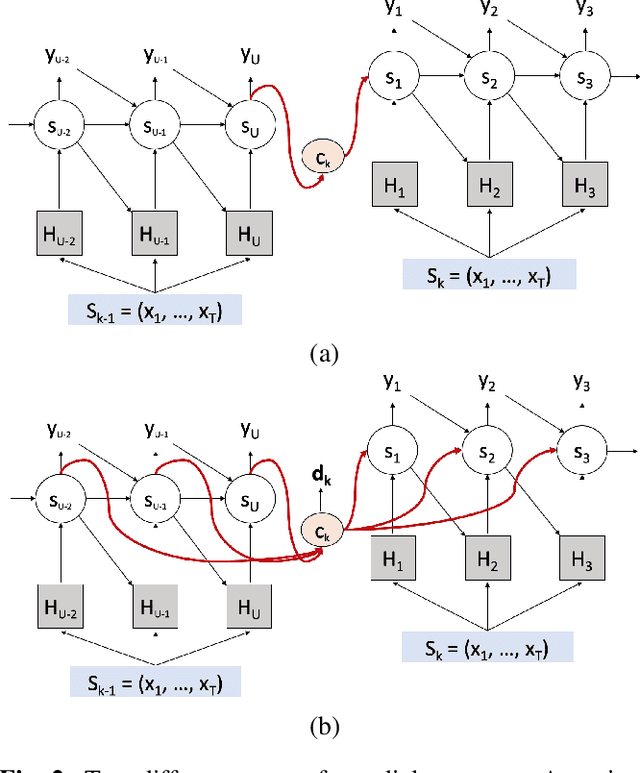

Existing speech recognition systems are typically built at the sentence level, although it is known that dialog context, e.g. higher-level knowledge that spans across sentences or speakers, can help the processing of long conversations. The recent progress in end-to-end speech recognition systems promises to integrate all available information (e.g. acoustic, language resources) into a single model, which is then jointly optimized. It seems natural that such dialog context information should thus also be integrated into the end-to-end models to improve further recognition accuracy. In this work, we present a dialog-context aware speech recognition model, which explicitly uses context information beyond sentence-level information, in an end-to-end fashion. Our dialog-context model captures a history of sentence-level context so that the whole system can be trained with dialog-context information in an end-to-end manner. We evaluate our proposed approach on the Switchboard conversational speech corpus and show that our system outperforms a comparable sentence-level end-to-end speech recognition system.
Hierarchical Multi Task Learning With CTC
Jul 25, 2018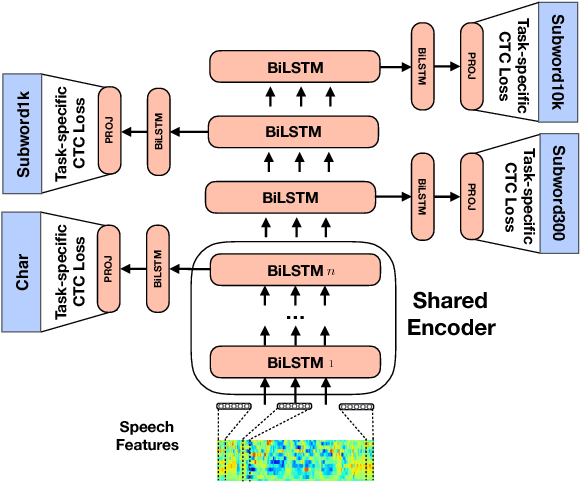

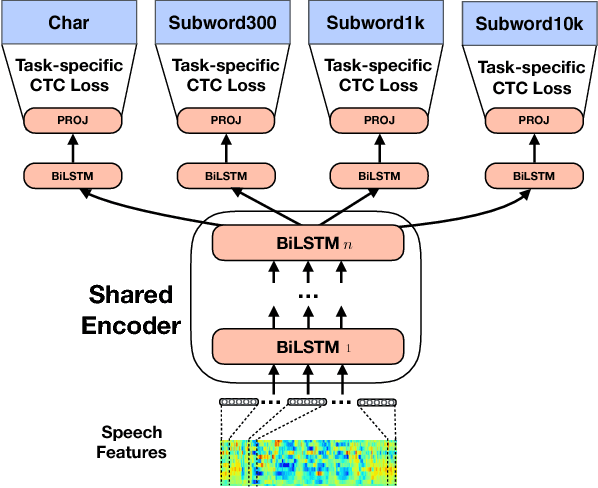

In Automatic Speech Recognition it is still challenging to learn useful intermediate representations when using high-level (or abstract) target units such as words. For that reason, character or phoneme based systems tend to outperform word-based systems when just few hundreds of hours of training data are being used. In this paper, we first show how hierarchical multi-task training can encourage the formation of useful intermediate representations. We achieve this by performing Connectionist Temporal Classification at different levels of the network with targets of different granularity. Our model thus performs predictions in multiple scales for the same input. On the standard 300h Switchboard training setup, our hierarchical multi-task architecture exhibits improvements over single-task architectures with the same number of parameters. Our model obtains 14.0% Word Error Rate on the Eval2000 Switchboard subset without any decoder or language model, outperforming the current state-of-the-art on acoustic-to-word models.
Subword and Crossword Units for CTC Acoustic Models
Jun 18, 2018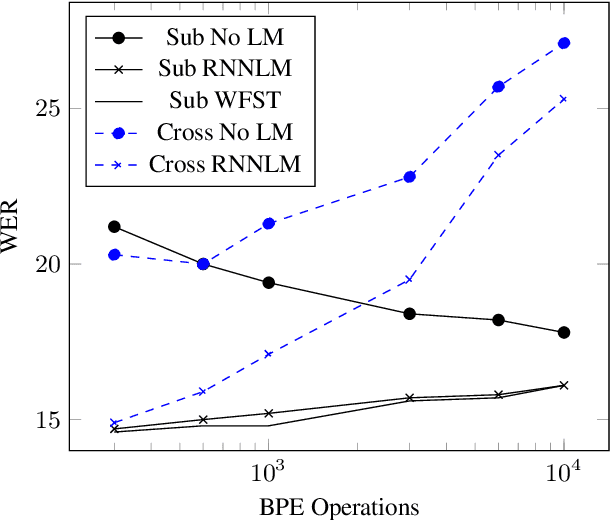
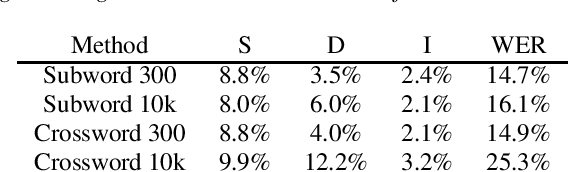
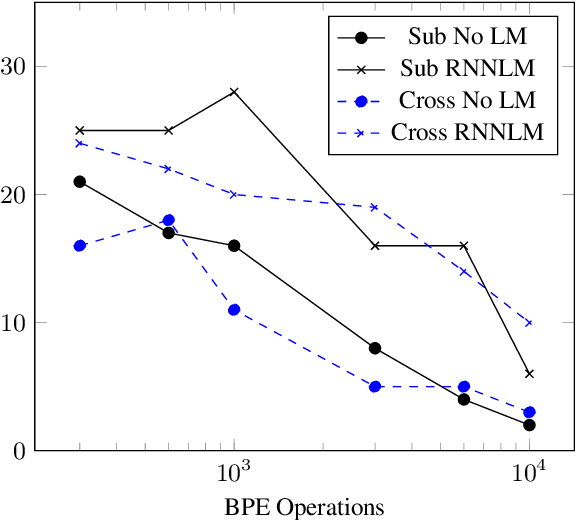

This paper proposes a novel approach to create an unit set for CTC based speech recognition systems. By using Byte Pair Encoding we learn an unit set of an arbitrary size on a given training text. In contrast to using characters or words as units this allows us to find a good trade-off between the size of our unit set and the available training data. We evaluate both Crossword units, that may span multiple word, and Subword units. By combining this approach with decoding methods using a separate language model we are able to achieve state of the art results for grapheme based CTC systems.
End-to-End Multimodal Speech Recognition
Apr 25, 2018
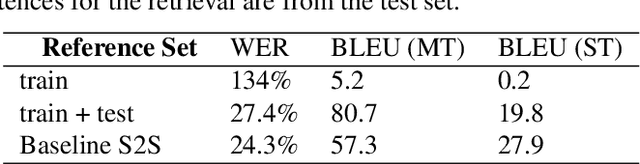
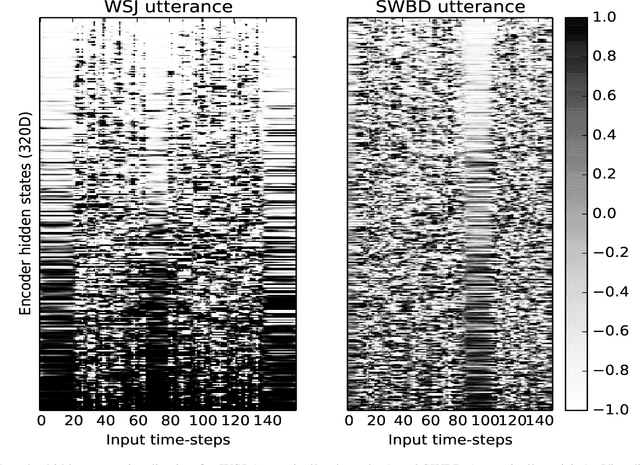
Transcription or sub-titling of open-domain videos is still a challenging domain for Automatic Speech Recognition (ASR) due to the data's challenging acoustics, variable signal processing and the essentially unrestricted domain of the data. In previous work, we have shown that the visual channel -- specifically object and scene features -- can help to adapt the acoustic model (AM) and language model (LM) of a recognizer, and we are now expanding this work to end-to-end approaches. In the case of a Connectionist Temporal Classification (CTC)-based approach, we retain the separation of AM and LM, while for a sequence-to-sequence (S2S) approach, both information sources are adapted together, in a single model. This paper also analyzes the behavior of CTC and S2S models on noisy video data (How-To corpus), and compares it to results on the clean Wall Street Journal (WSJ) corpus, providing insight into the robustness of both approaches.