 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecomposition of Uncertainty in Bayesian Deep Learning for Efficient and Risk-sensitive Learning
Jun 15, 2018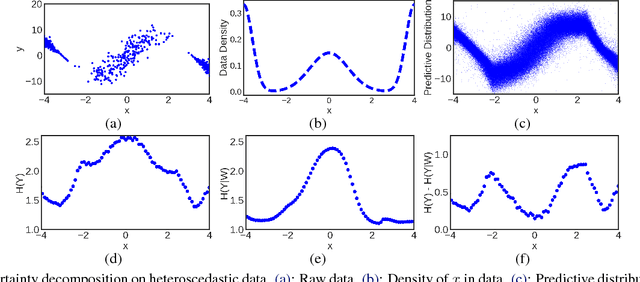

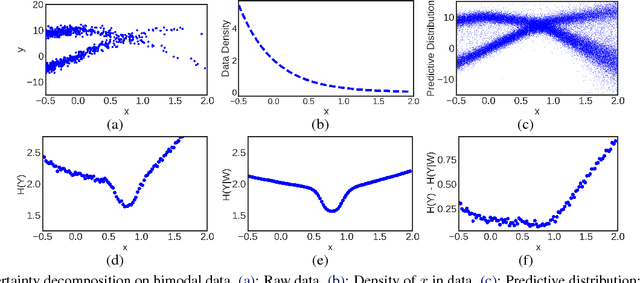
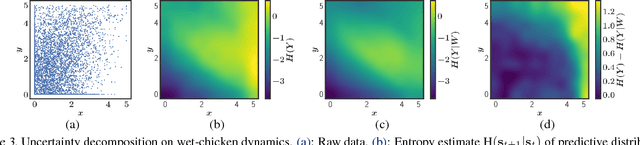
Bayesian neural networks with latent variables are scalable and flexible probabilistic models: They account for uncertainty in the estimation of the network weights and, by making use of latent variables, can capture complex noise patterns in the data. We show how to extract and decompose uncertainty into epistemic and aleatoric components for decision-making purposes. This allows us to successfully identify informative points for active learning of functions with heteroscedastic and bimodal noise. Using the decomposition we further define a novel risk-sensitive criterion for reinforcement learning to identify policies that balance expected cost, model-bias and noise aversion.
Evaluating Reinforcement Learning Algorithms in Observational Health Settings
May 31, 2018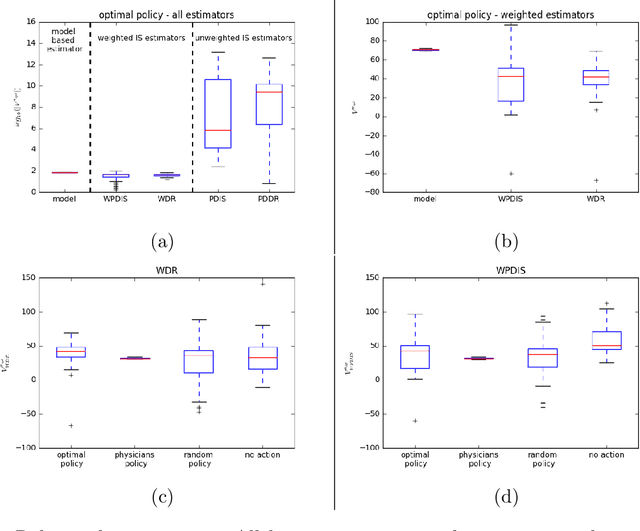
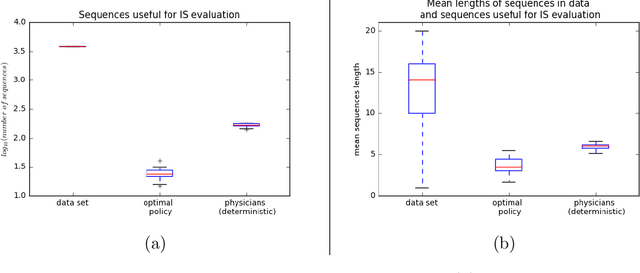
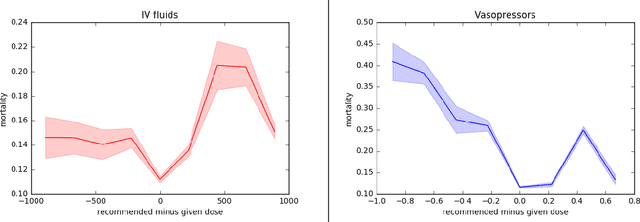
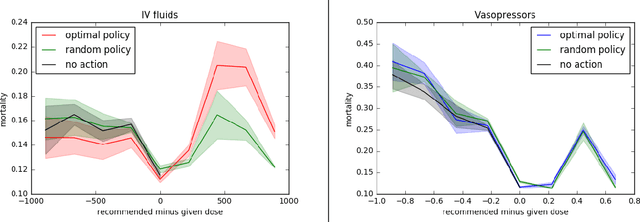
Much attention has been devoted recently to the development of machine learning algorithms with the goal of improving treatment policies in healthcare. Reinforcement learning (RL) is a sub-field within machine learning that is concerned with learning how to make sequences of decisions so as to optimize long-term effects. Already, RL algorithms have been proposed to identify decision-making strategies for mechanical ventilation, sepsis management and treatment of schizophrenia. However, before implementing treatment policies learned by black-box algorithms in high-stakes clinical decision problems, special care must be taken in the evaluation of these policies. In this document, our goal is to expose some of the subtleties associated with evaluating RL algorithms in healthcare. We aim to provide a conceptual starting point for clinical and computational researchers to ask the right questions when designing and evaluating algorithms for new ways of treating patients. In the following, we describe how choices about how to summarize a history, variance of statistical estimators, and confounders in more ad-hoc measures can result in unreliable, even misleading estimates of the quality of a treatment policy. We also provide suggestions for mitigating these effects---for while there is much promise for mining observational health data to uncover better treatment policies, evaluation must be performed thoughtfully.
A particle-based variational approach to Bayesian Non-negative Matrix Factorization
Mar 16, 2018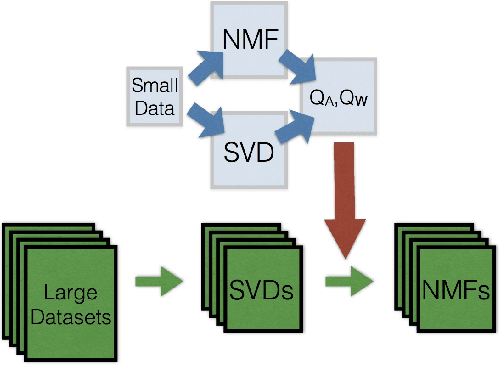
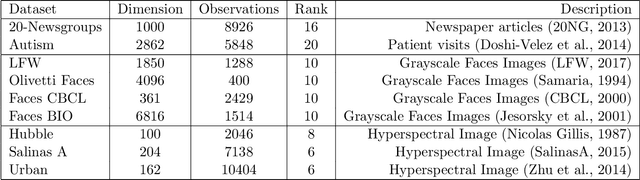
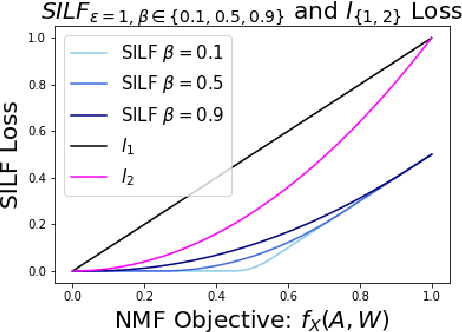
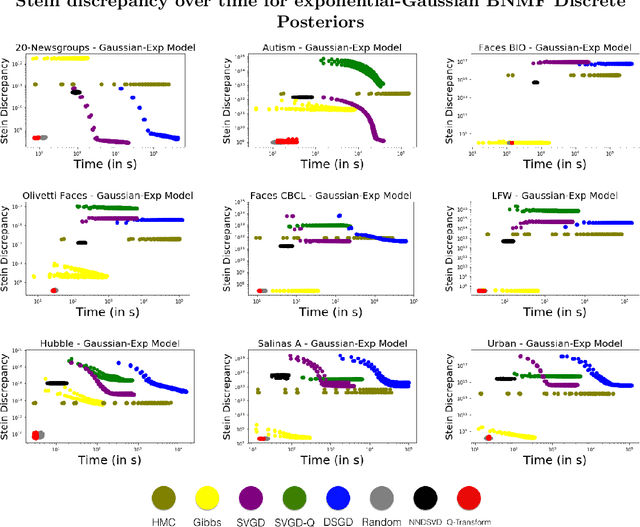
Bayesian Non-negative Matrix Factorization (NMF) is a promising approach for understanding uncertainty and structure in matrix data. However, a large volume of applied work optimizes traditional non-Bayesian NMF objectives that fail to provide a principled understanding of the non-identifiability inherent in NMF-- an issue ideally addressed by a Bayesian approach. Despite their suitability, current Bayesian NMF approaches have failed to gain popularity in an applied setting; they sacrifice flexibility in modeling for tractable computation, tend to get stuck in local modes, and require many thousands of samples for meaningful uncertainty estimates. We address these issues through a particle-based variational approach to Bayesian NMF that only requires the joint likelihood to be differentiable for tractability, uses a novel initialization technique to identify multiple modes in the posterior, and allows domain experts to inspect a `small' set of factorizations that faithfully represent the posterior. We introduce and employ a class of likelihood and prior distributions for NMF that formulate a Bayesian model using popular non-Bayesian NMF objectives. On several real datasets, we obtain better particle approximations to the Bayesian NMF posterior in less time than baselines and demonstrate the significant role that multimodality plays in NMF-related tasks.
Unsupervised Grammar Induction with Depth-bounded PCFG
Feb 26, 2018There has been recent interest in applying cognitively or empirically motivated bounds on recursion depth to limit the search space of grammar induction models (Ponvert et al., 2011; Noji and Johnson, 2016; Shain et al., 2016). This work extends this depth-bounding approach to probabilistic context-free grammar induction (DB-PCFG), which has a smaller parameter space than hierarchical sequence models, and therefore more fully exploits the space reductions of depth-bounding. Results for this model on grammar acquisition from transcribed child-directed speech and newswire text exceed or are competitive with those of other models when evaluated on parse accuracy. Moreover, gram- mars acquired from this model demonstrate a consistent use of category labels, something which has not been demonstrated by other acquisition models.
How do Humans Understand Explanations from Machine Learning Systems? An Evaluation of the Human-Interpretability of Explanation
Feb 02, 2018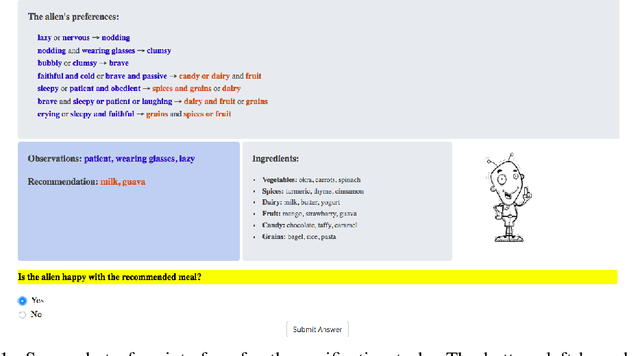
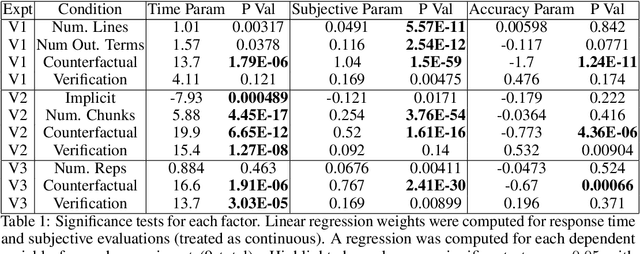
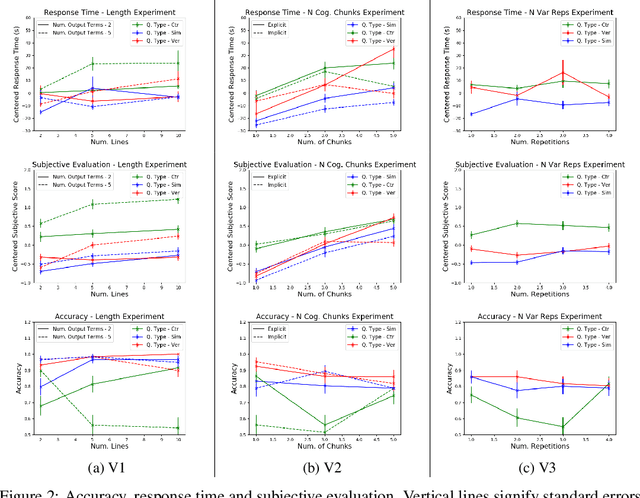
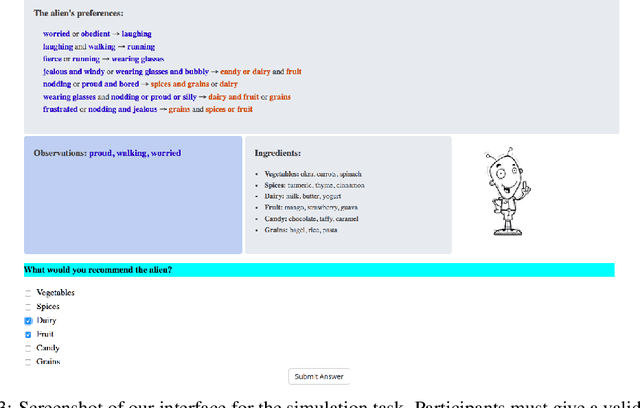
Recent years have seen a boom in interest in machine learning systems that can provide a human-understandable rationale for their predictions or decisions. However, exactly what kinds of explanation are truly human-interpretable remains poorly understood. This work advances our understanding of what makes explanations interpretable in the specific context of verification. Suppose we have a machine learning system that predicts X, and we provide rationale for this prediction X. Given an input, an explanation, and an output, is the output consistent with the input and the supposed rationale? Via a series of user-studies, we identify what kinds of increases in complexity have the greatest effect on the time it takes for humans to verify the rationale, and which seem relatively insensitive.
Prediction-Constrained Topic Models for Antidepressant Recommendation
Dec 01, 2017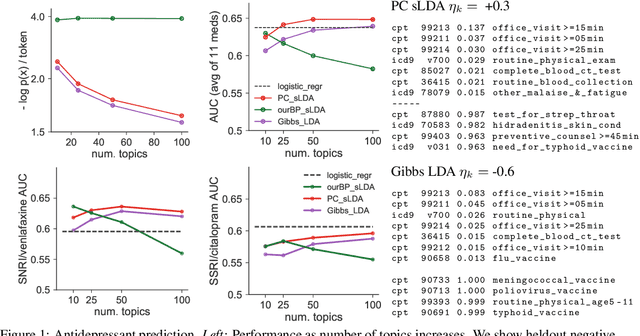
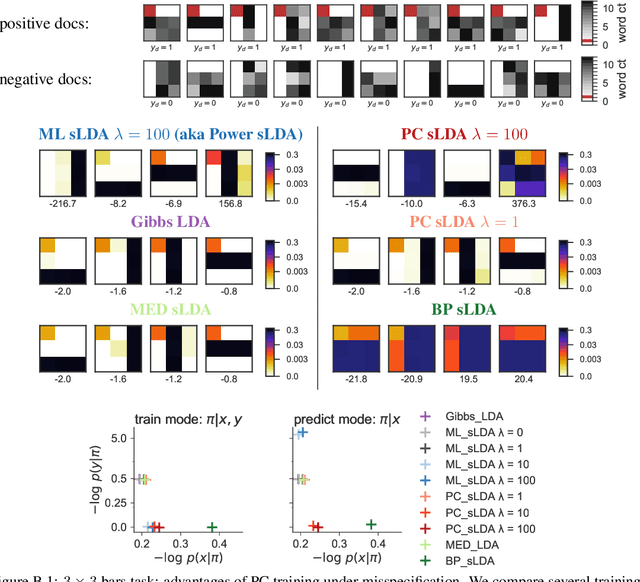
Supervisory signals can help topic models discover low-dimensional data representations that are more interpretable for clinical tasks. We propose a framework for training supervised latent Dirichlet allocation that balances two goals: faithful generative explanations of high-dimensional data and accurate prediction of associated class labels. Existing approaches fail to balance these goals by not properly handling a fundamental asymmetry: the intended task is always predicting labels from data, not data from labels. Our new prediction-constrained objective trains models that predict labels from heldout data well while also producing good generative likelihoods and interpretable topic-word parameters. In a case study on predicting depression medications from electronic health records, we demonstrate improved recommendations compared to previous supervised topic models and high- dimensional logistic regression from words alone.
Improving the Adversarial Robustness and Interpretability of Deep Neural Networks by Regularizing their Input Gradients
Nov 26, 2017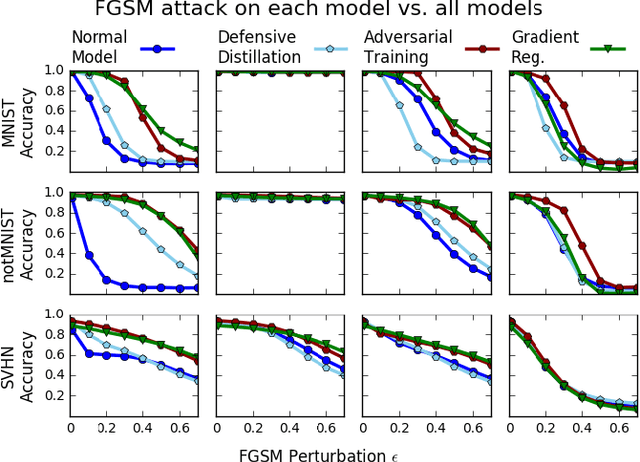

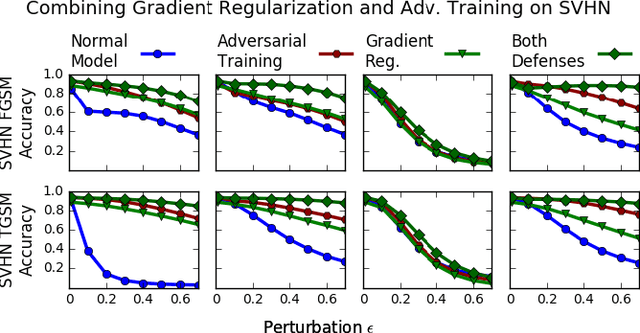
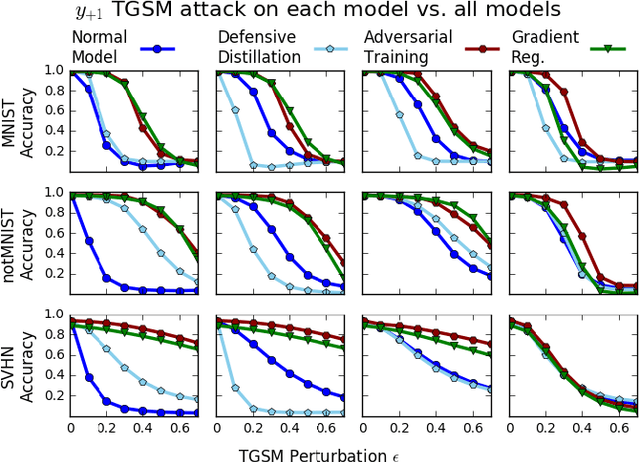
Deep neural networks have proven remarkably effective at solving many classification problems, but have been criticized recently for two major weaknesses: the reasons behind their predictions are uninterpretable, and the predictions themselves can often be fooled by small adversarial perturbations. These problems pose major obstacles for the adoption of neural networks in domains that require security or transparency. In this work, we evaluate the effectiveness of defenses that differentiably penalize the degree to which small changes in inputs can alter model predictions. Across multiple attacks, architectures, defenses, and datasets, we find that neural networks trained with this input gradient regularization exhibit robustness to transferred adversarial examples generated to fool all of the other models. We also find that adversarial examples generated to fool gradient-regularized models fool all other models equally well, and actually lead to more "legitimate," interpretable misclassifications as rated by people (which we confirm in a human subject experiment). Finally, we demonstrate that regularizing input gradients makes them more naturally interpretable as rationales for model predictions. We conclude by discussing this relationship between interpretability and robustness in deep neural networks.
Accountability of AI Under the Law: The Role of Explanation
Nov 21, 2017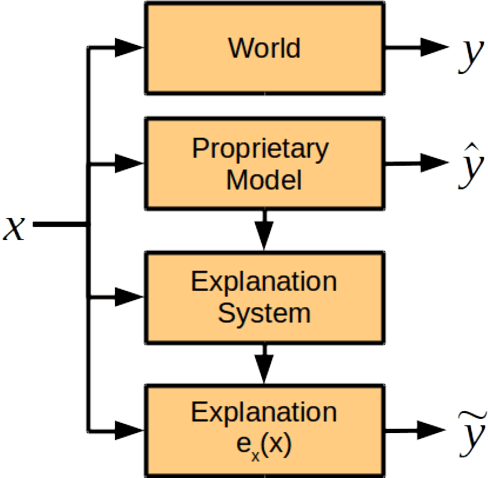


The ubiquity of systems using artificial intelligence or "AI" has brought increasing attention to how those systems should be regulated. The choice of how to regulate AI systems will require care. AI systems have the potential to synthesize large amounts of data, allowing for greater levels of personalization and precision than ever before---applications range from clinical decision support to autonomous driving and predictive policing. That said, there exist legitimate concerns about the intentional and unintentional negative consequences of AI systems. There are many ways to hold AI systems accountable. In this work, we focus on one: explanation. Questions about a legal right to explanation from AI systems was recently debated in the EU General Data Protection Regulation, and thus thinking carefully about when and how explanation from AI systems might improve accountability is timely. In this work, we review contexts in which explanation is currently required under the law, and then list the technical considerations that must be considered if we desired AI systems that could provide kinds of explanations that are currently required of humans.
Beyond Sparsity: Tree Regularization of Deep Models for Interpretability
Nov 16, 2017
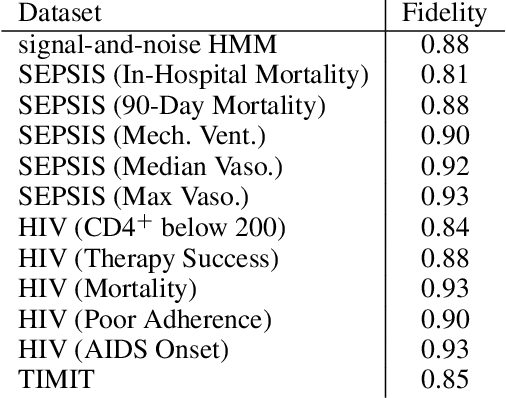
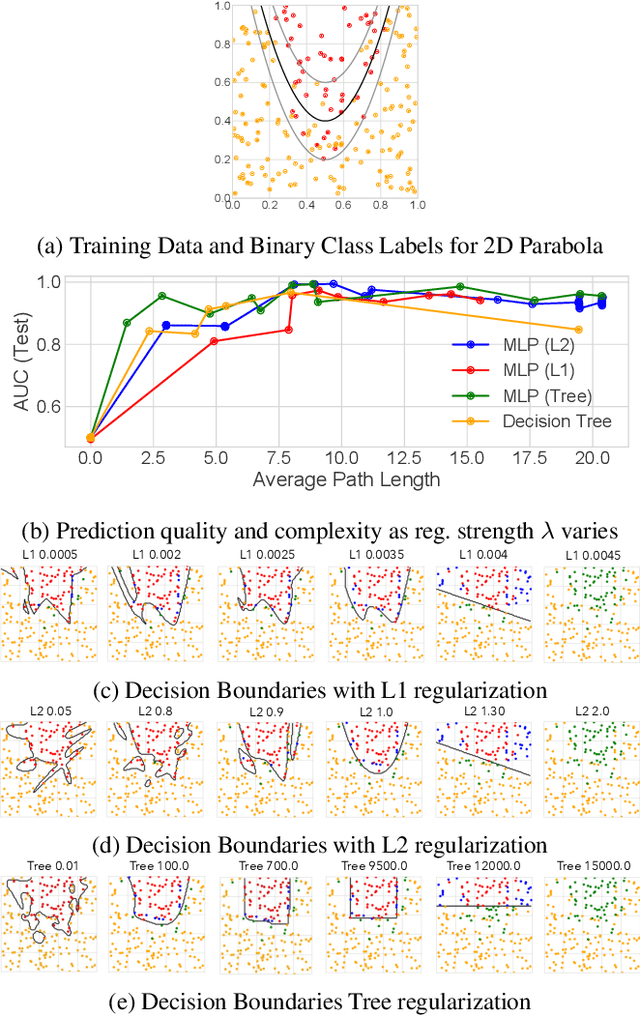
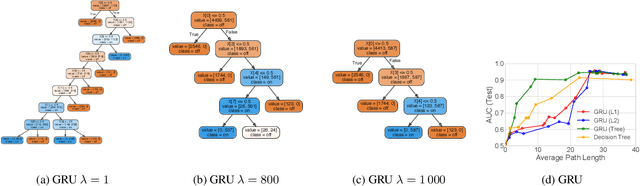
The lack of interpretability remains a key barrier to the adoption of deep models in many applications. In this work, we explicitly regularize deep models so human users might step through the process behind their predictions in little time. Specifically, we train deep time-series models so their class-probability predictions have high accuracy while being closely modeled by decision trees with few nodes. Using intuitive toy examples as well as medical tasks for treating sepsis and HIV, we demonstrate that this new tree regularization yields models that are easier for humans to simulate than simpler L1 or L2 penalties without sacrificing predictive power.
Uncertainty Decomposition in Bayesian Neural Networks with Latent Variables
Nov 11, 2017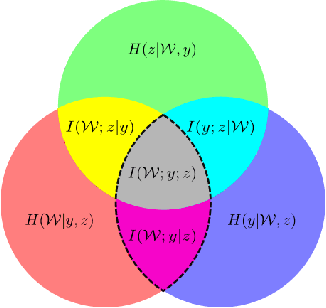
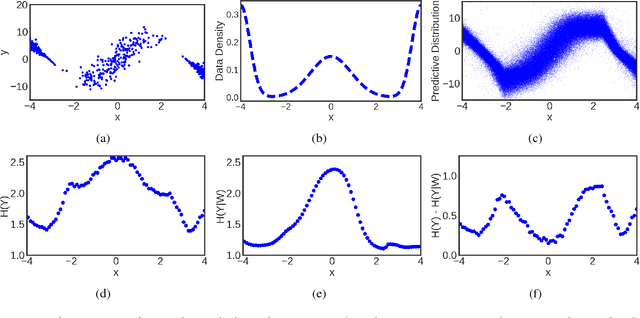
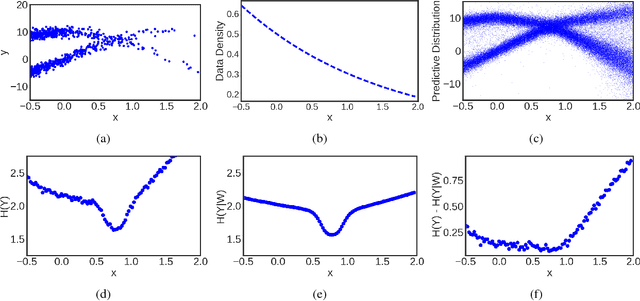
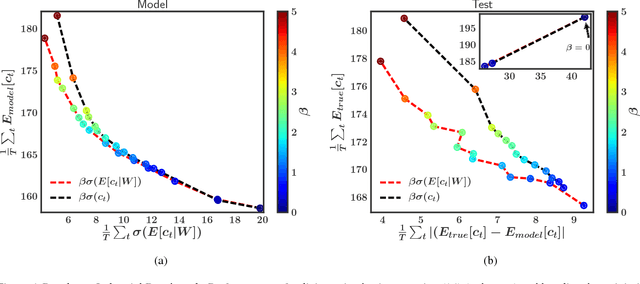
Bayesian neural networks (BNNs) with latent variables are probabilistic models which can automatically identify complex stochastic patterns in the data. We describe and study in these models a decomposition of predictive uncertainty into its epistemic and aleatoric components. First, we show how such a decomposition arises naturally in a Bayesian active learning scenario by following an information theoretic approach. Second, we use a similar decomposition to develop a novel risk sensitive objective for safe reinforcement learning (RL). This objective minimizes the effect of model bias in environments whose stochastic dynamics are described by BNNs with latent variables. Our experiments illustrate the usefulness of the resulting decomposition in active learning and safe RL settings.