 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty for Identifying Open-Set Errors in Visual Object Detection
Apr 03, 2021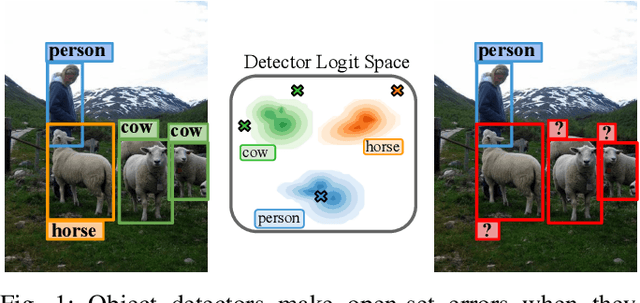
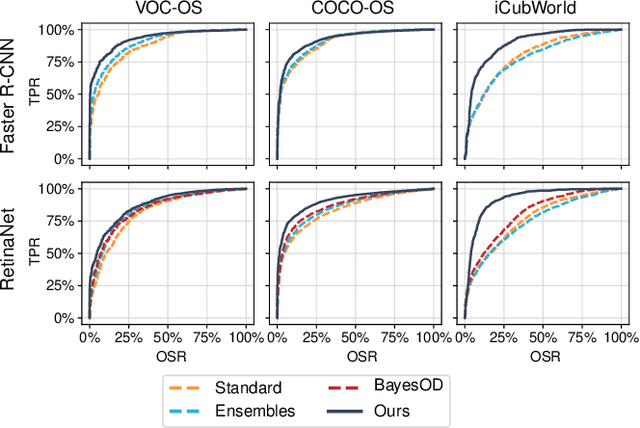
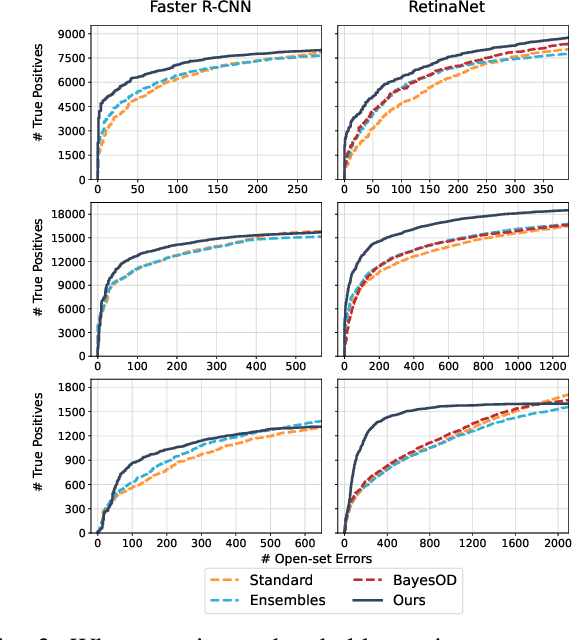
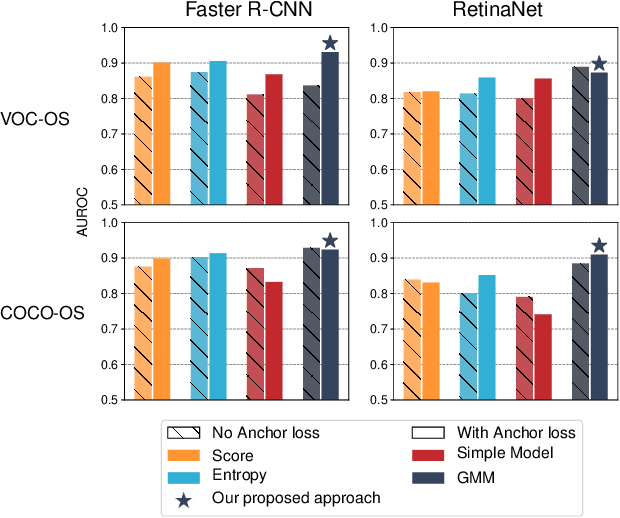
Deployed into an open world, object detectors are prone to a type of false positive detection termed open-set errors. We propose GMM-Det, a real-time method for extracting epistemic uncertainty from object detectors to identify and reject open-set errors. GMM-Det trains the detector to produce a structured logit space that is modelled with class-specific Gaussian Mixture Models. At test time, open-set errors are identified by their low log-probability under all Gaussian Mixture Models. We test two common detector architectures, Faster R-CNN and RetinaNet, across three varied datasets spanning robotics and computer vision. Our results show that GMM-Det consistently outperforms existing uncertainty techniques for identifying and rejecting open-set detections, especially at the low-error-rate operating point required for safety-critical applications. GMM-Det maintains object detection performance, and introduces only minimal computational overhead. We also introduce a methodology for converting existing object detection datasets into specific open-set datasets to consistently evaluate open-set performance in object detection. Code for GMM-Det and the dataset methodology will be made publicly available.
Semi-supervised Keypoint Localization
Jan 20, 2021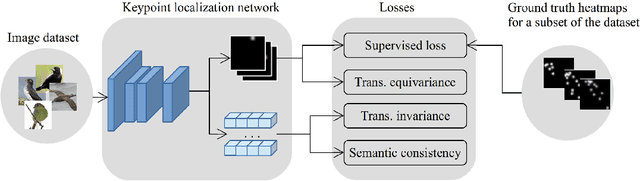

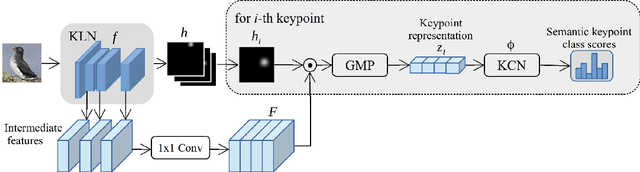
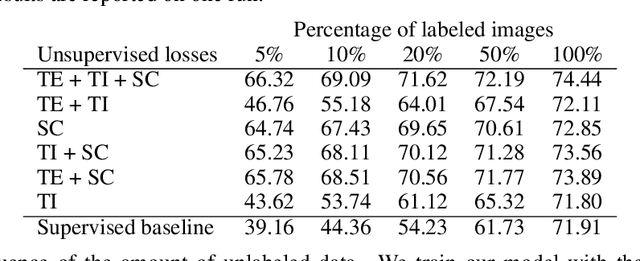
Knowledge about the locations of keypoints of an object in an image can assist in fine-grained classification and identification tasks, particularly for the case of objects that exhibit large variations in poses that greatly influence their visual appearance, such as wild animals. However, supervised training of a keypoint detection network requires annotating a large image dataset for each animal species, which is a labor-intensive task. To reduce the need for labeled data, we propose to learn simultaneously keypoint heatmaps and pose invariant keypoint representations in a semi-supervised manner using a small set of labeled images along with a larger set of unlabeled images. Keypoint representations are learnt with a semantic keypoint consistency constraint that forces the keypoint detection network to learn similar features for the same keypoint across the dataset. Pose invariance is achieved by making keypoint representations for the image and its augmented copies closer together in feature space. Our semi-supervised approach significantly outperforms previous methods on several benchmarks for human and animal body landmark localization.
Run-Time Monitoring of Machine Learning for Robotic Perception: A Survey of Emerging Trends
Jan 05, 2021
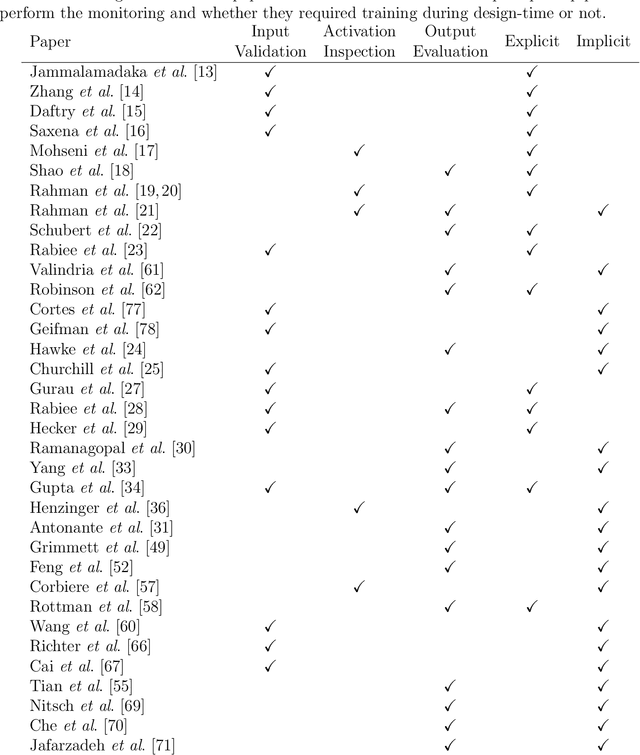
As deep learning continues to dominate all state-of-the-art computer vision tasks, it is increasingly becoming the essential building blocks for robotic perception. As a result, the research questions concerning the safety and reliability of learning-based perception are gaining increased importance. Although there is an established field that studies safety certification and convergence guarantee of complex software systems for decision-making during design-time, the uncertainty in run-time conditions and the unknown future deployment environments of autonomous systems as well as the complexity of learning-based perception systems make the generalisation of the verification results from design-time to run-time problematic. More attention is starting to shift towards run-time monitoring of performance and reliability of perception systems with several trends emerging in the literature in the face of such a challenge. This paper attempts to identify these trends and summarise the various approaches on the topic.
Semantics for Robotic Mapping, Perception and Interaction: A Survey
Jan 02, 2021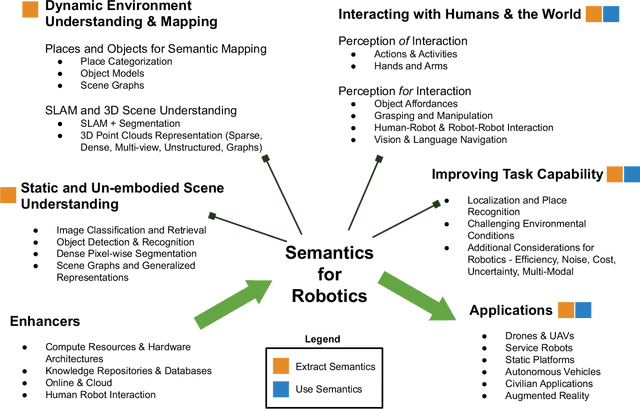
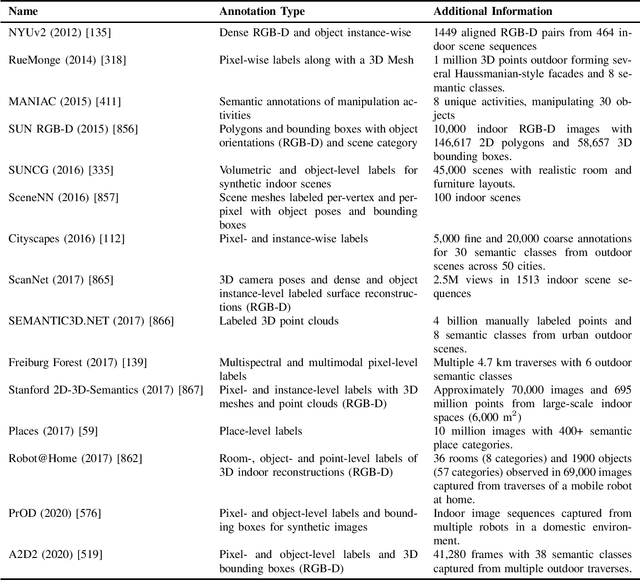
For robots to navigate and interact more richly with the world around them, they will likely require a deeper understanding of the world in which they operate. In robotics and related research fields, the study of understanding is often referred to as semantics, which dictates what does the world "mean" to a robot, and is strongly tied to the question of how to represent that meaning. With humans and robots increasingly operating in the same world, the prospects of human-robot interaction also bring semantics and ontology of natural language into the picture. Driven by need, as well as by enablers like increasing availability of training data and computational resources, semantics is a rapidly growing research area in robotics. The field has received significant attention in the research literature to date, but most reviews and surveys have focused on particular aspects of the topic: the technical research issues regarding its use in specific robotic topics like mapping or segmentation, or its relevance to one particular application domain like autonomous driving. A new treatment is therefore required, and is also timely because so much relevant research has occurred since many of the key surveys were published. This survey therefore provides an overarching snapshot of where semantics in robotics stands today. We establish a taxonomy for semantics research in or relevant to robotics, split into four broad categories of activity, in which semantics are extracted, used, or both. Within these broad categories we survey dozens of major topics including fundamentals from the computer vision field and key robotics research areas utilizing semantics, including mapping, navigation and interaction with the world. The survey also covers key practical considerations, including enablers like increased data availability and improved computational hardware, and major application areas where...
* 81 pages, 1 figure, published in Foundations and Trends in Robotics, 2020
SWA Object Detection
Dec 25, 2020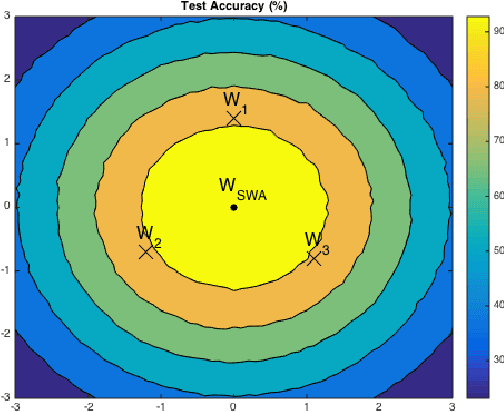
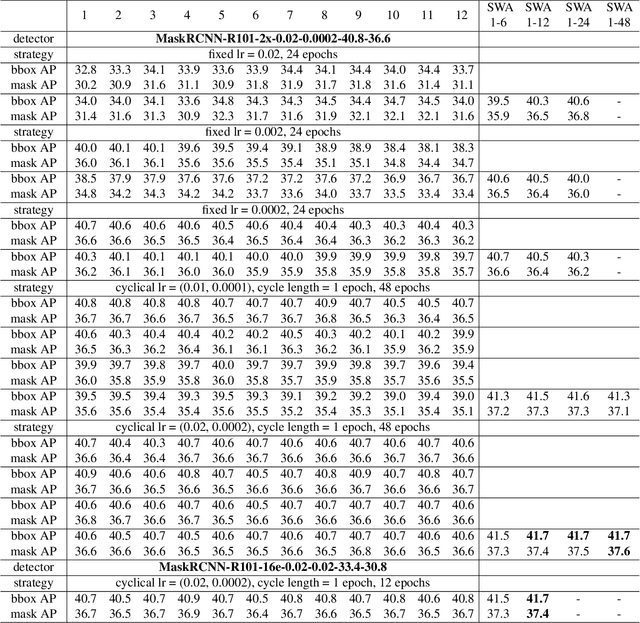
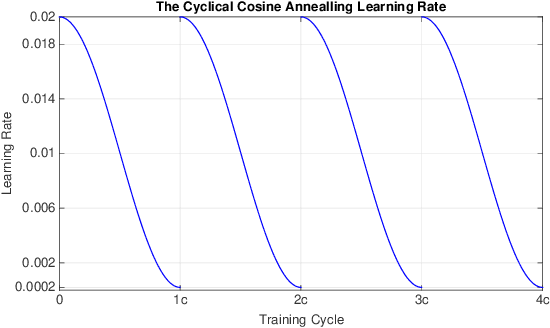

Do you want to improve 1.0 AP for your object detector without any inference cost and any change to your detector? Let us tell you such a recipe. It is surprisingly simple: train your detector for an extra 12 epochs using cyclical learning rates and then average these 12 checkpoints as your final detection model. This potent recipe is inspired by Stochastic Weights Averaging (SWA), which is proposed in arXiv:1803.05407 for improving generalization in deep neural networks. We found it also very effective in object detection. In this technique report, we systematically investigate the effects of applying SWA to object detection as well as instance segmentation. Through extensive experiments, we discover a good policy of performing SWA in object detection, and we consistently achieve $\sim$1.0 AP improvement over various popular detectors on the challenging COCO benchmark. We hope this work will make more researchers in object detection know this technique and help them train better object detectors. Code is available at: https://github.com/hyz-xmaster/swa_object_detection .
Online Monitoring of Object Detection Performance Post-Deployment
Nov 16, 2020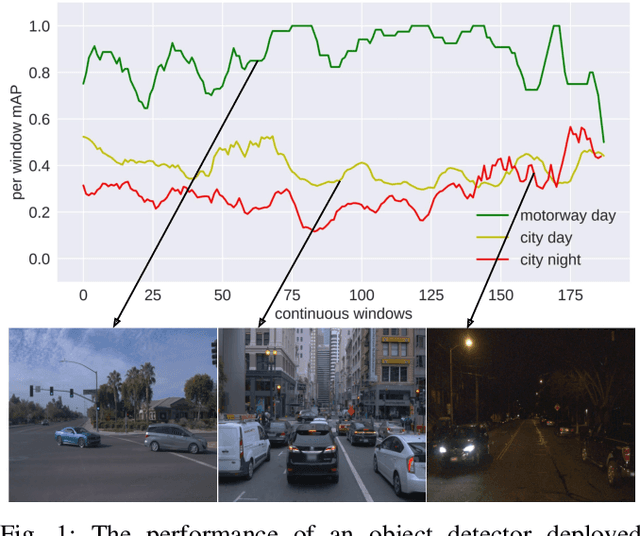
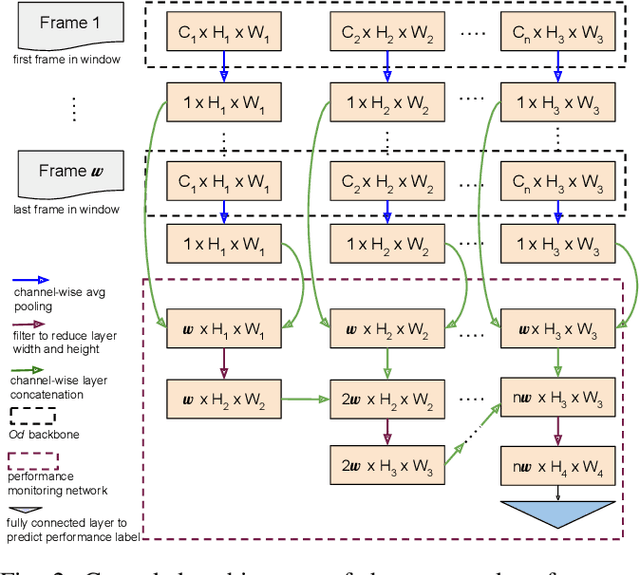
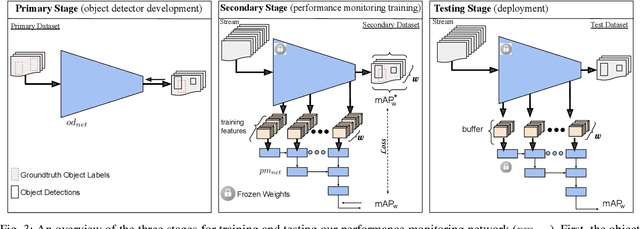
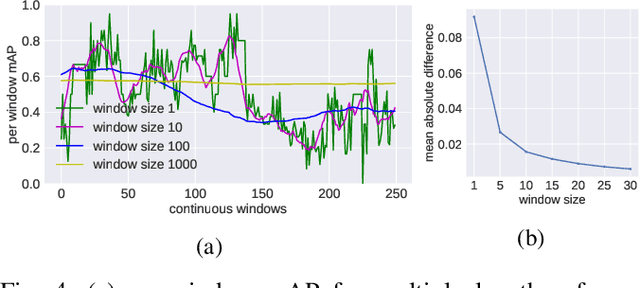
Post-deployment, an object detector is expected to operate at a similar level of performance that was reported on its testing dataset. However, when deployed onboard mobile robots that operate under varying and complex environmental conditions, the detector's performance can fluctuate and occasionally degrade severely without warning. Undetected, this can lead the robot to take unsafe and risky actions based on low-quality and unreliable object detections. We address this problem and introduce a cascaded neural network that monitors the performance of the object detector by predicting the quality of its mean average precision (mAP) on a sliding window of the input frames. The proposed cascaded network exploits the internal features from the deep neural network of the object detector. We evaluate our proposed approach using different combinations of autonomous driving datasets and object detectors.
Performance Monitoring of Object Detection During Deployment
Sep 18, 2020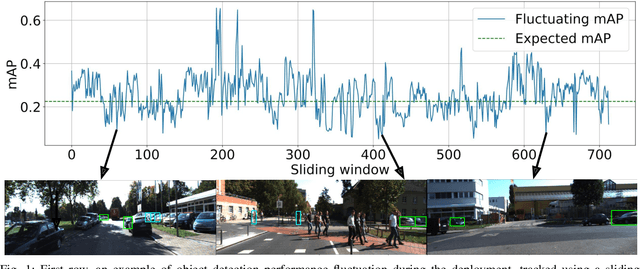
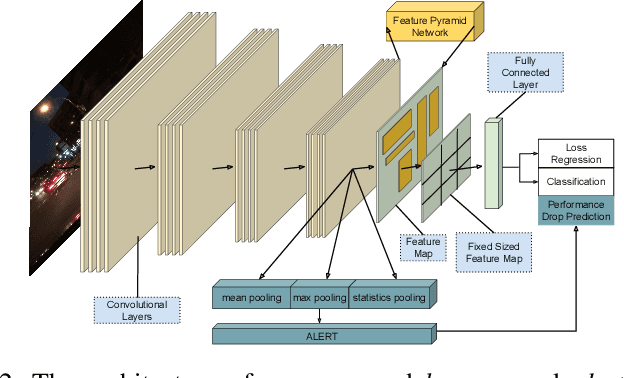

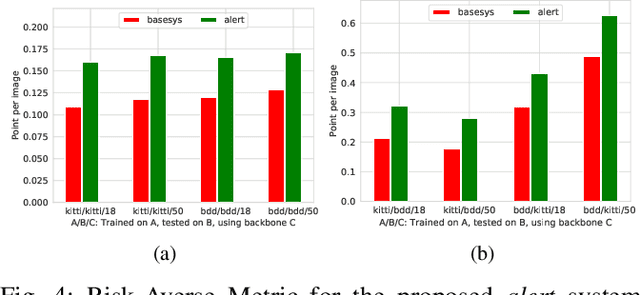
Performance monitoring of object detection is crucial for safety-critical applications such as autonomous vehicles that operate under varying and complex environmental conditions. Currently, object detectors are evaluated using summary metrics based on a single dataset that is assumed to be representative of all future deployment conditions. In practice, this assumption does not hold, and the performance fluctuates as a function of the deployment conditions. To address this issue, we propose an introspection approach to performance monitoring during deployment without the need for ground truth data. We do so by predicting when the per-frame mean average precision drops below a critical threshold using the detector's internal features. We quantitatively evaluate and demonstrate our method's ability to reduce risk by trading off making an incorrect decision by raising the alarm and absenting from detection.
The Robotic Vision Scene Understanding Challenge
Sep 11, 2020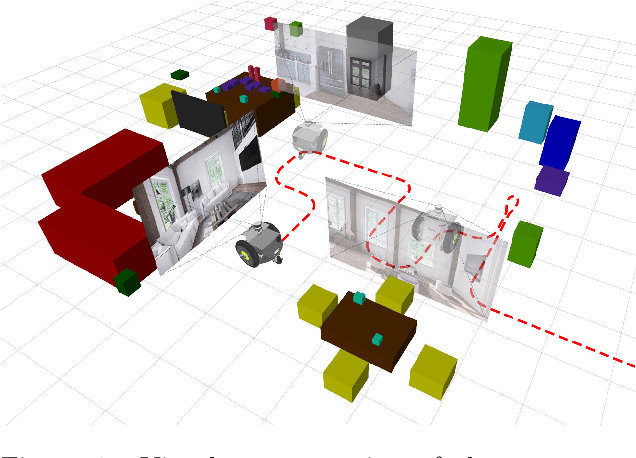
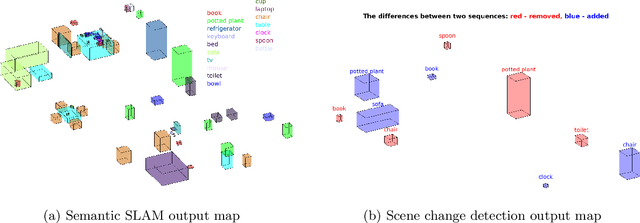

Being able to explore an environment and understand the location and type of all objects therein is important for indoor robotic platforms that must interact closely with humans. However, it is difficult to evaluate progress in this area due to a lack of standardized testing which is limited due to the need for active robot agency and perfect object ground-truth. To help provide a standard for testing scene understanding systems, we present a new robot vision scene understanding challenge using simulation to enable repeatable experiments with active robot agency. We provide two challenging task types, three difficulty levels, five simulated environments and a new evaluation measure for evaluating 3D cuboid object maps. Our aim is to drive state-of-the-art research in scene understanding through enabling evaluation and comparison of active robotic vision systems.
VarifocalNet: An IoU-aware Dense Object Detector
Aug 31, 2020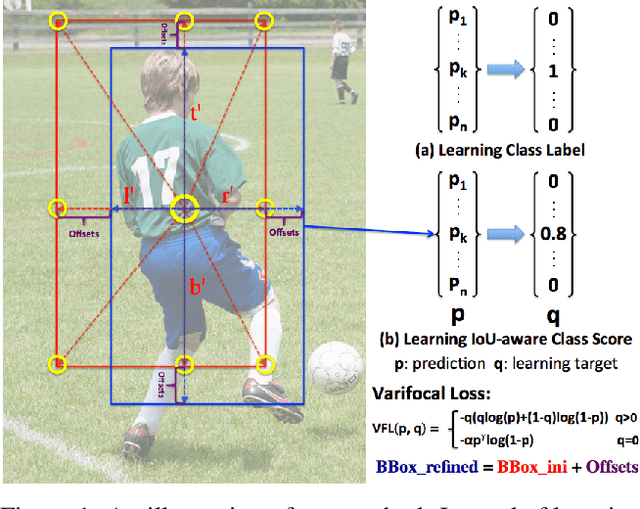
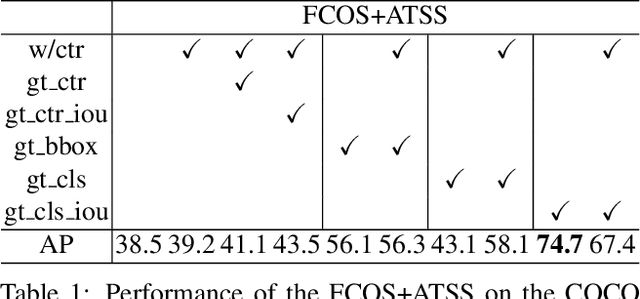
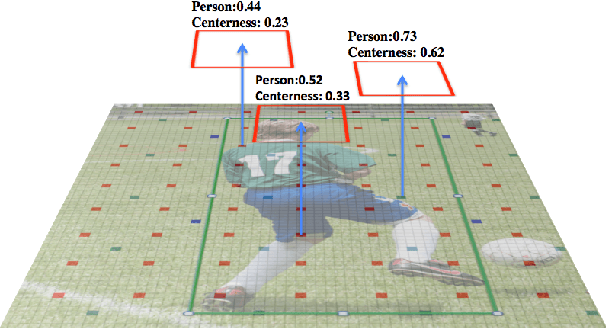
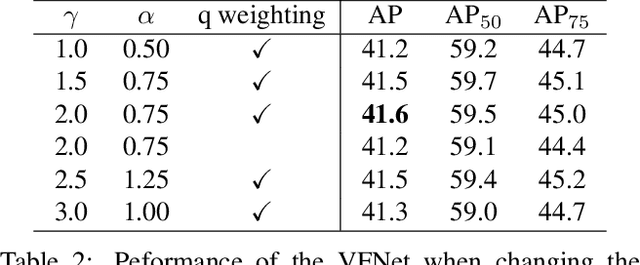
Accurately ranking a huge number of candidate detections is a key to the high-performance dense object detector. While prior work uses the classification score or the combination of it and the IoU-based localization score as the ranking basis, neither of them can reliably represent the rank, and this harms the detection performance. In this paper, we propose to learn IoU-aware classification scores (IACS) that simultaneously represent the object presence confidence and localization accuracy, to produce a more accurate rank of detections in dense object detectors. In particular, we design a new loss function, named Varifocal Loss, for training a dense object detector to predict the IACS, and a new efficient star-shaped bounding box feature representation for estimating the IACS and refining coarse bounding boxes. Combining these two new components and a bounding box refinement branch, we build a new dense object detector on the FCOS architecture, what we call VarifocalNet or VFNet for short. Extensive experiments on MS COCO benchmark show that our VFNet consistently surpasses the strong baseline by $\sim$2.0 AP with different backbones and our best model with Res2Net-101-DCN reaches a single-model single-scale AP of 51.3 on COCO test-dev, achieving the state-of-the-art among various object detectors. Code is available at https://github.com/hyz-xmaster/VarifocalNet .
Keypoint-Aligned Embeddings for Image Retrieval and Re-identification
Aug 26, 2020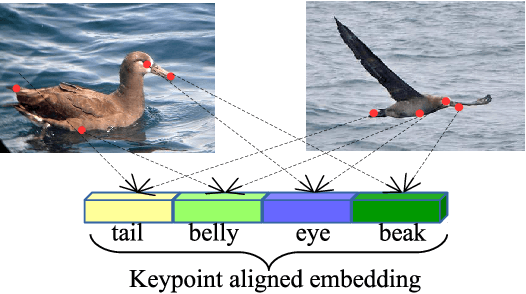
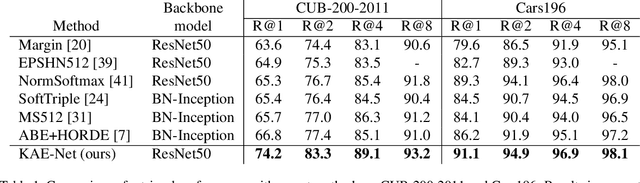
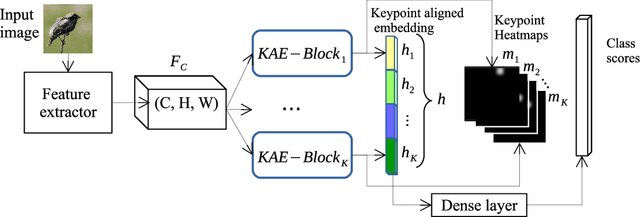
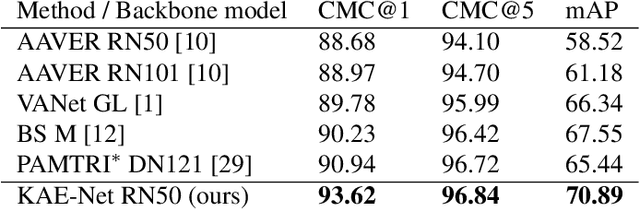
Learning embeddings that are invariant to the pose of the object is crucial in visual image retrieval and re-identification. The existing approaches for person, vehicle, or animal re-identification tasks suffer from high intra-class variance due to deformable shapes and different camera viewpoints. To overcome this limitation, we propose to align the image embedding with a predefined order of the keypoints. The proposed keypoint aligned embeddings model (KAE-Net) learns part-level features via multi-task learning which is guided by keypoint locations. More specifically, KAE-Net extracts channels from a feature map activated by a specific keypoint through learning the auxiliary task of heatmap reconstruction for this keypoint. The KAE-Net is compact, generic and conceptually simple. It achieves state of the art performance on the benchmark datasets of CUB-200-2011, Cars196 and VeRi-776 for retrieval and re-identification tasks.