 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Global Feature-Oriented Relational Triple Extraction Model based on Table Filling
Sep 14, 2021Table filling based relational triple extraction methods are attracting growing research interests due to their promising performance and their abilities on extracting triples from complex sentences. However, this kind of methods are far from their full potential because most of them only focus on using local features but ignore the global associations of relations and of token pairs, which increases the possibility of overlooking some important information during triple extraction. To overcome this deficiency, we propose a global feature-oriented triple extraction model that makes full use of the mentioned two kinds of global associations. Specifically, we first generate a table feature for each relation. Then two kinds of global associations are mined from the generated table features. Next, the mined global associations are integrated into the table feature of each relation. This "generate-mine-integrate" process is performed multiple times so that the table feature of each relation is refined step by step. Finally, each relation's table is filled based on its refined table feature, and all triples linked to this relation are extracted based on its filled table. We evaluate the proposed model on three benchmark datasets. Experimental results show our model is effective and it achieves state-of-the-art results on all of these datasets. The source code of our work is available at: https://github.com/neukg/GRTE.
A Three-Stage Learning Framework for Low-Resource Knowledge-Grounded Dialogue Generation
Sep 09, 2021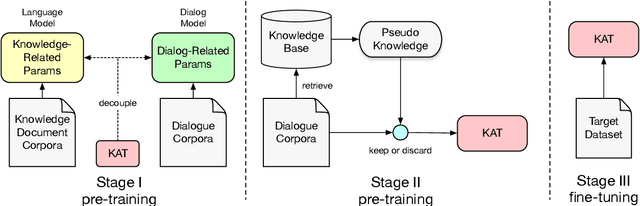
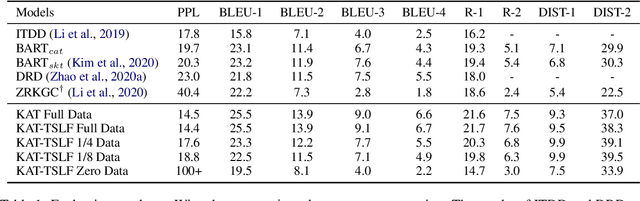
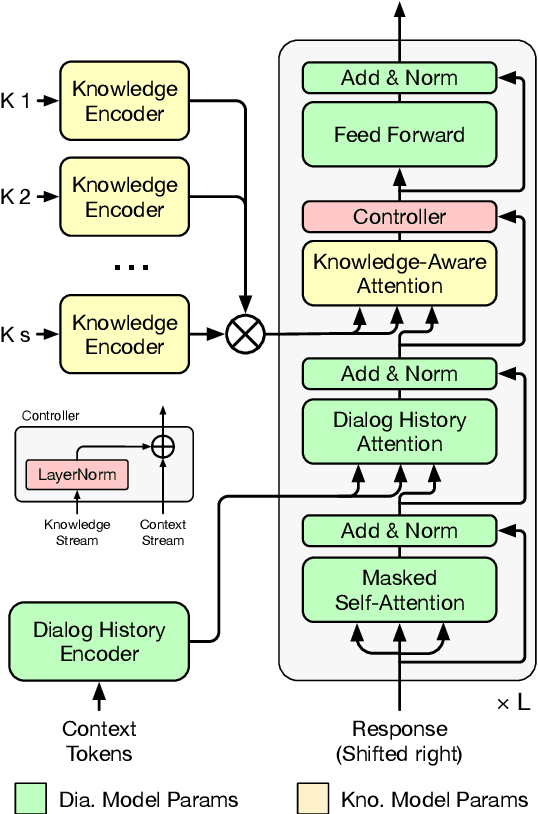
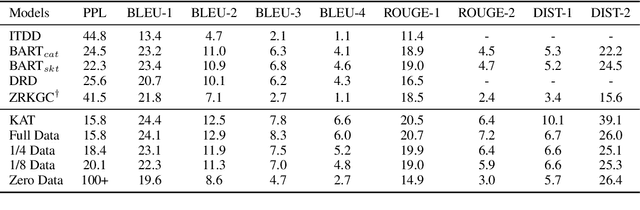
Neural conversation models have shown great potentials towards generating fluent and informative responses by introducing external background knowledge. Nevertheless, it is laborious to construct such knowledge-grounded dialogues, and existing models usually perform poorly when transfer to new domains with limited training samples. Therefore, building a knowledge-grounded dialogue system under the low-resource setting is a still crucial issue. In this paper, we propose a novel three-stage learning framework based on weakly supervised learning which benefits from large scale ungrounded dialogues and unstructured knowledge base. To better cooperate with this framework, we devise a variant of Transformer with decoupled decoder which facilitates the disentangled learning of response generation and knowledge incorporation. Evaluation results on two benchmarks indicate that our approach can outperform other state-of-the-art methods with less training data, and even in zero-resource scenario, our approach still performs well.
Knowledge-Grounded Dialogue with Reward-Driven Knowledge Selection
Aug 31, 2021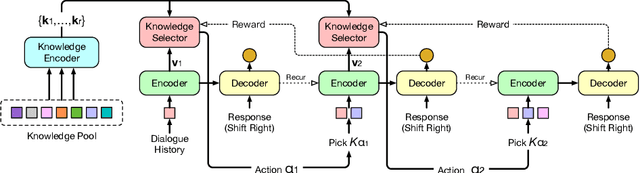

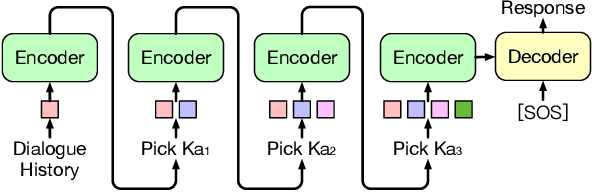
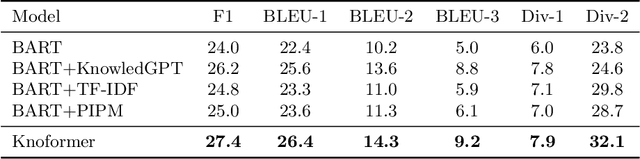
Knowledge-grounded dialogue is a task of generating a fluent and informative response based on both conversation context and a collection of external knowledge, in which knowledge selection plays an important role and attracts more and more research interest. However, most existing models either select only one knowledge or use all knowledge for responses generation. The former may lose valuable information in discarded knowledge, while the latter may bring a lot of noise. At the same time, many approaches need to train the knowledge selector with knowledge labels that indicate ground-truth knowledge, but these labels are difficult to obtain and require a large number of manual annotations. Motivated by these issues, we propose Knoformer, a dialogue response generation model based on reinforcement learning, which can automatically select one or more related knowledge from the knowledge pool and does not need knowledge labels during training. Knoformer is evaluated on two knowledge-guided conversation datasets, and achieves state-of-the-art performance.
A Conditional Cascade Model for Relational Triple Extraction
Aug 20, 2021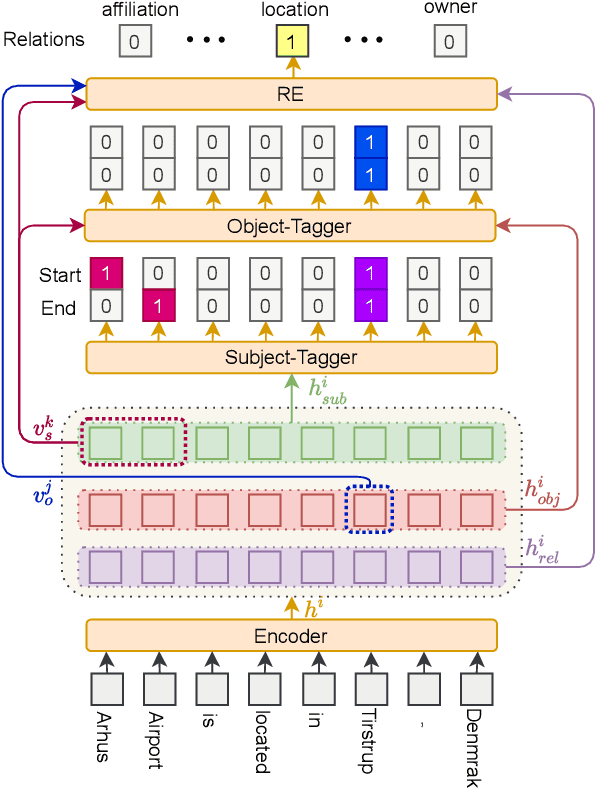
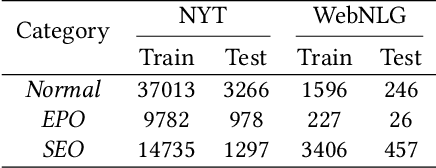
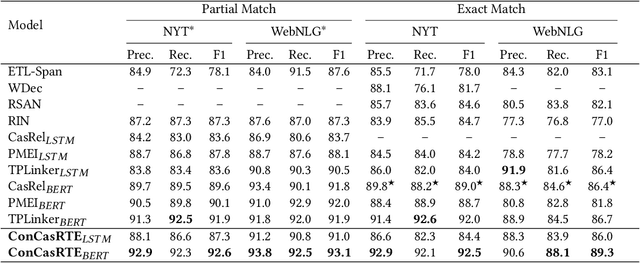

Tagging based methods are one of the mainstream methods in relational triple extraction. However, most of them suffer from the class imbalance issue greatly. Here we propose a novel tagging based model that addresses this issue from following two aspects. First, at the model level, we propose a three-step extraction framework that can reduce the total number of samples greatly, which implicitly decreases the severity of the mentioned issue. Second, at the intra-model level, we propose a confidence threshold based cross entropy loss that can directly neglect some samples in the major classes. We evaluate the proposed model on NYT and WebNLG. Extensive experiments show that it can address the mentioned issue effectively and achieves state-of-the-art results on both datasets. The source code of our model is available at: https://github.com/neukg/ConCasRTE.
An Effective System for Multi-format Information Extraction
Aug 16, 2021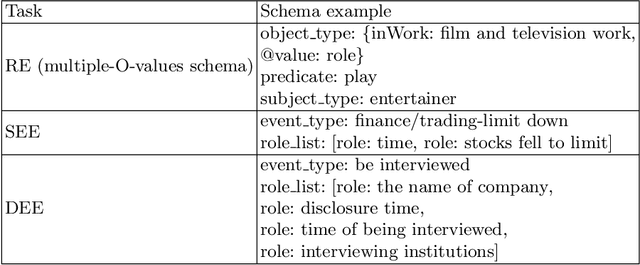
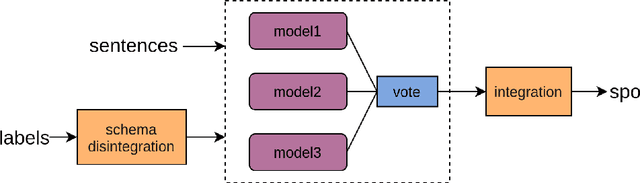

The multi-format information extraction task in the 2021 Language and Intelligence Challenge is designed to comprehensively evaluate information extraction from different dimensions. It consists of an multiple slots relation extraction subtask and two event extraction subtasks that extract events from both sentence-level and document-level. Here we describe our system for this multi-format information extraction competition task. Specifically, for the relation extraction subtask, we convert it to a traditional triple extraction task and design a voting based method that makes full use of existing models. For the sentence-level event extraction subtask, we convert it to a NER task and use a pointer labeling based method for extraction. Furthermore, considering the annotated trigger information may be helpful for event extraction, we design an auxiliary trigger recognition model and use the multi-task learning mechanism to integrate the trigger features into the event extraction model. For the document-level event extraction subtask, we design an Encoder-Decoder based method and propose a Transformer-alike decoder. Finally,our system ranks No.4 on the test set leader-board of this multi-format information extraction task, and its F1 scores for the subtasks of relation extraction, event extractions of sentence-level and document-level are 79.887%, 85.179%, and 70.828% respectively. The codes of our model are available at {https://github.com/neukg/MultiIE}.
A Graph Reasoning Network for Multi-turn Response Selection via Customized Pre-training
Jan 15, 2021
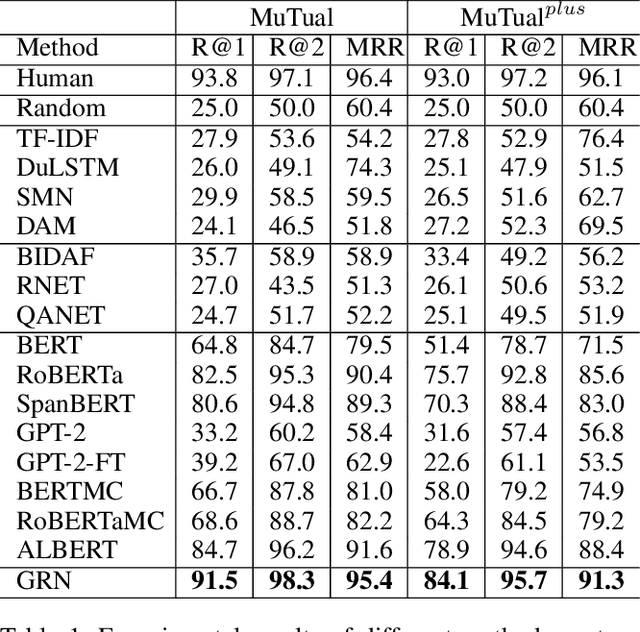
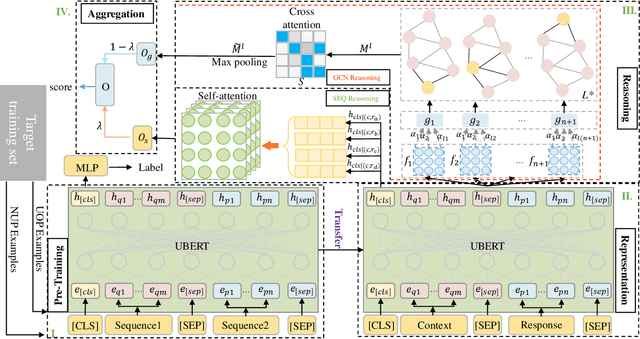
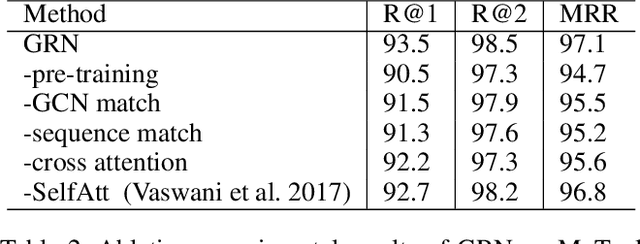
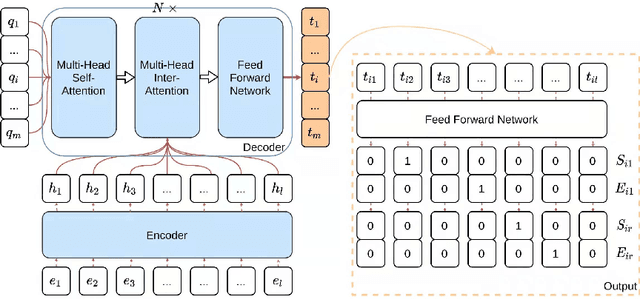
We investigate response selection for multi-turn conversation in retrieval-based chatbots. Existing studies pay more attention to the matching between utterances and responses by calculating the matching score based on learned features, leading to insufficient model reasoning ability. In this paper, we propose a graph-reasoning network (GRN) to address the problem. GRN first conducts pre-training based on ALBERT using next utterance prediction and utterance order prediction tasks specifically devised for response selection. These two customized pre-training tasks can endow our model with the ability of capturing semantical and chronological dependency between utterances. We then fine-tune the model on an integrated network with sequence reasoning and graph reasoning structures. The sequence reasoning module conducts inference based on the highly summarized context vector of utterance-response pairs from the global perspective. The graph reasoning module conducts the reasoning on the utterance-level graph neural network from the local perspective. Experiments on two conversational reasoning datasets show that our model can dramatically outperform the strong baseline methods and can achieve performance which is close to human-level.
Knowledge Graph Embedding with Atrous Convolution and Residual Learning
Oct 30, 2020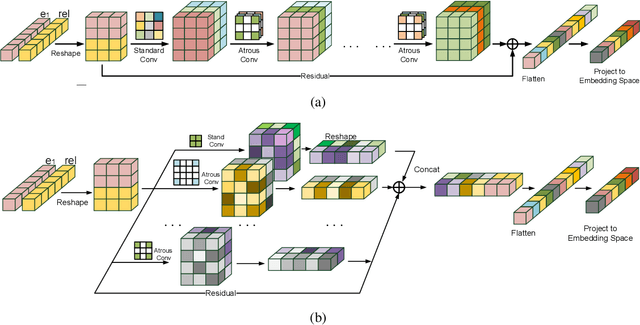
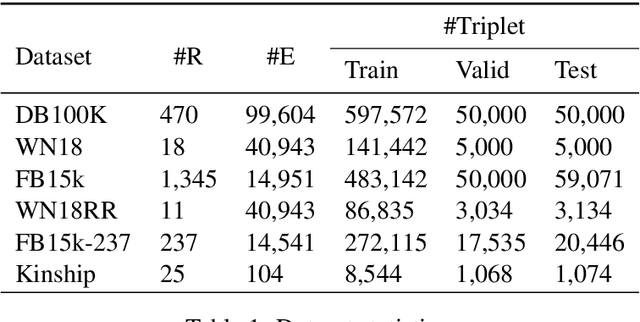
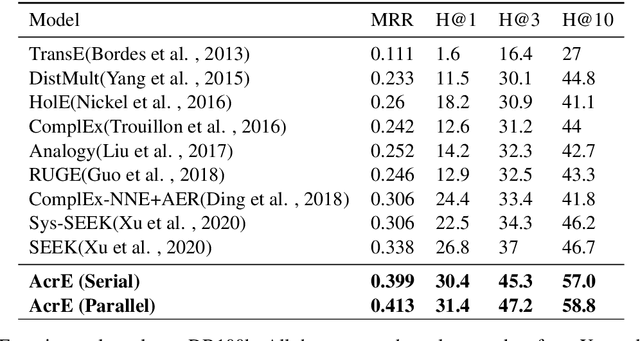
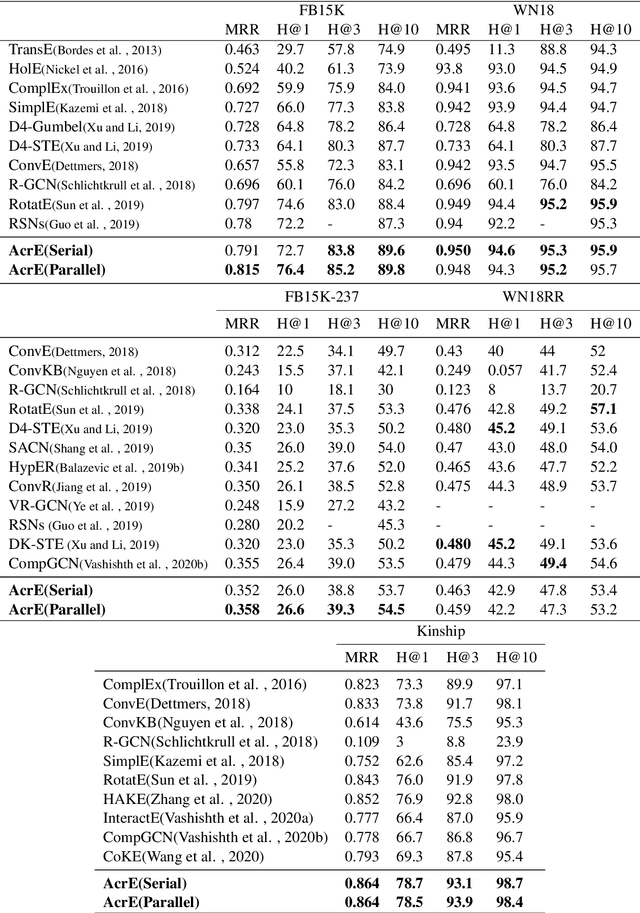
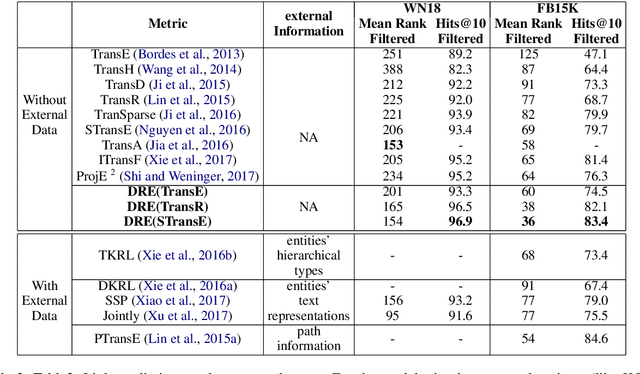
Knowledge graph embedding is an important task and it will benefit lots of downstream applications. Currently, deep neural networks based methods achieve state-of-the-art performance. However, most of these existing methods are very complex and need much time for training and inference. To address this issue, we propose a simple but effective atrous convolution based knowledge graph embedding method. Compared with existing state-of-the-art methods, our method has following main characteristics. First, it effectively increases feature interactions by using atrous convolutions. Second, to address the original information forgotten issue and vanishing/exploding gradient issue, it uses the residual learning method. Third, it has simpler structure but much higher parameter efficiency. We evaluate our method on six benchmark datasets with different evaluation metrics. Extensive experiments show that our model is very effective. On these diverse datasets, it achieves better results than the compared state-of-the-art methods on most of evaluation metrics. The source codes of our model could be found at https://github.com/neukg/AcrE.
LMVE at SemEval-2020 Task 4: Commonsense Validation and Explanation using Pretraining Language Model
Jul 06, 2020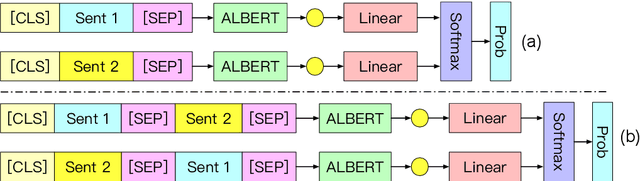
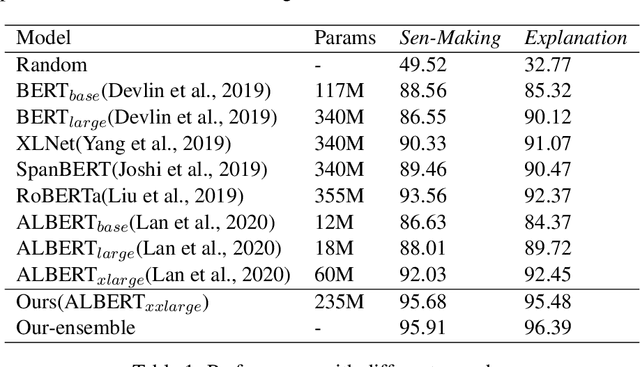
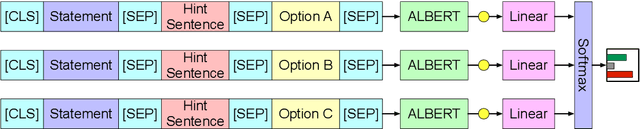
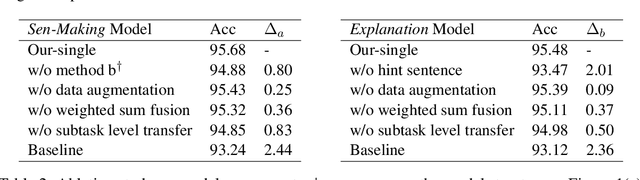
This paper describes our submission to subtask a and b of SemEval-2020 Task 4. For subtask a, we use a ALBERT based model with improved input form to pick out the common sense statement from two statement candidates. For subtask b, we use a multiple choice model enhanced by hint sentence mechanism to select the reason from given options about why a statement is against common sense. Besides, we propose a novel transfer learning strategy between subtasks which help improve the performance. The accuracy scores of our system are 95.6 / 94.9 on official test set and rank 7$^{th}$ / 2$^{nd}$ on Post-Evaluation leaderboard.
Domain Representation for Knowledge Graph Embedding
Apr 09, 2019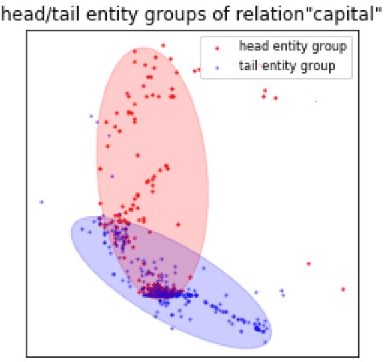

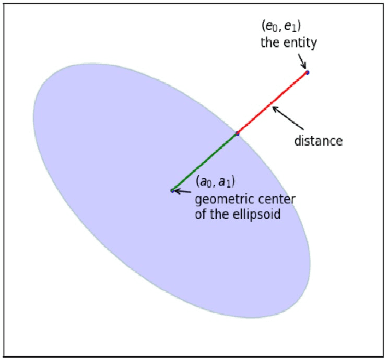
Embedding entities and relations into a continuous multi-dimensional vector space have become the dominant method for knowledge graph embedding in representation learning. However, most existing models ignore to represent hierarchical knowledge, such as the similarities and dissimilarities of entities in one domain. We proposed to learn a Domain Representations over existing knowledge graph embedding models, such that entities that have similar attributes are organized into the same domain. Such hierarchical knowledge of domains can give further evidence in link prediction. Experimental results show that domain embeddings give a significant improvement over the most recent state-of-art baseline knowledge graph embedding models.
TechKG: A Large-Scale Chinese Technology-Oriented Knowledge Graph
Dec 17, 2018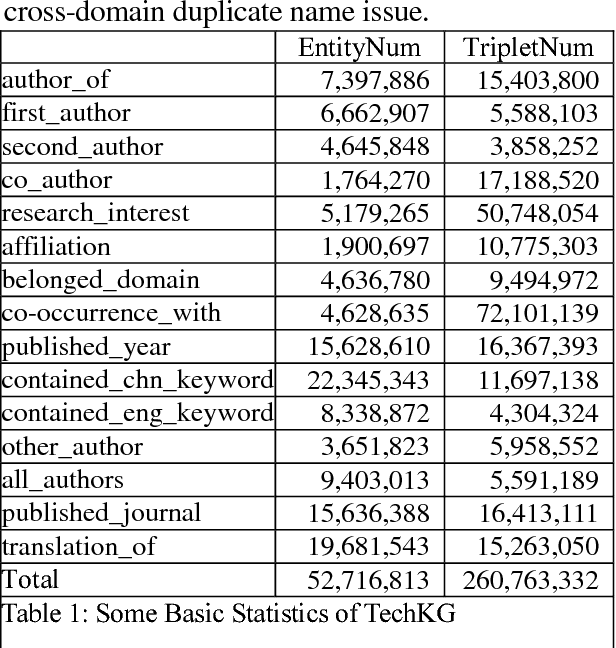
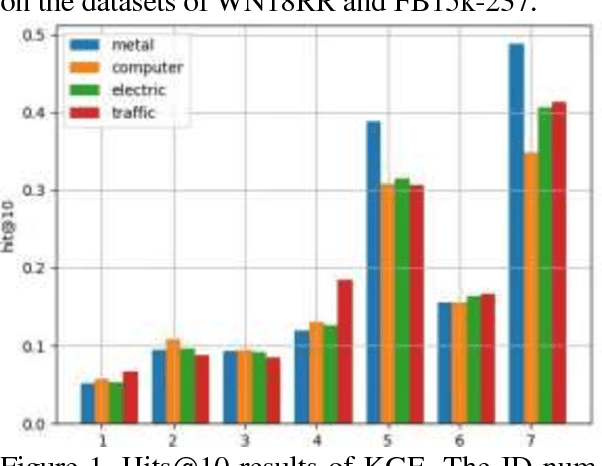
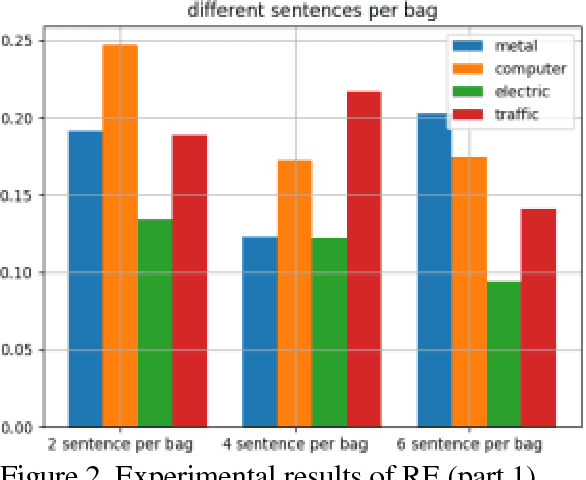
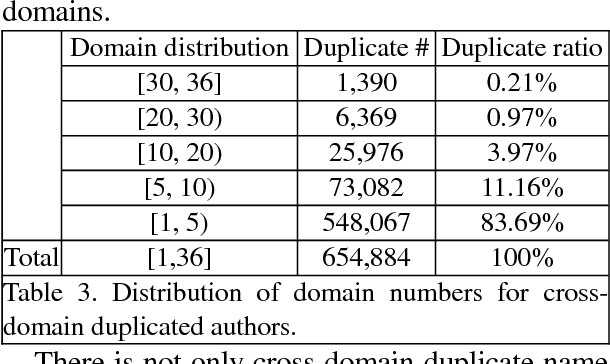
Knowledge graph is a kind of valuable knowledge base which would benefit lots of AI-related applications. Up to now, lots of large-scale knowledge graphs have been built. However, most of them are non-Chinese and designed for general purpose. In this work, we introduce TechKG, a large scale Chinese knowledge graph that is technology-oriented. It is built automatically from massive technical papers that are published in Chinese academic journals of different research domains. Some carefully designed heuristic rules are used to extract high quality entities and relations. Totally, it comprises of over 260 million triplets that are built upon more than 52 million entities which come from 38 research domains. Our preliminary ex-periments indicate that TechKG has high adaptability and can be used as a dataset for many diverse AI-related applications. We released TechKG at: http://www.techkg.cn.