 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChunkFT: Byte-Streamed Optimization for Memory-Efficient Full Fine-Tuning
May 20, 2026This work presents \textsc{ChunkFT}, a memory-efficient fine-tuning framework that reformulates full-parameter fine-tuning around a dynamically activated working set. \textsc{ChunkFT} enables gradient computation for arbitrary sub-tensors without modifying the network architecture, providing an algorithmic foundation for optimizing arbitrary sub-networks while avoiding standard dense gradient computation. We provide a theoretical convergence analysis of \textsc{ChunkFT} in the deterministic setting. Empirically, we apply \textsc{ChunkFT} to fine-tune Llama 3-8B and Llama 3-70B using a single RTX 4090-24GB GPU and 2$\times$ H800-80GB GPUs, respectively. Full-parameter fine-tuning of a 7B model with a 1K input length requires only 13.72GB of GPU memory. The results demonstrate the effectiveness of \textsc{ChunkFT} in memory usage, running time, and optimization quality. Moreover, downstream evaluations on language understanding, mathematical reasoning, and MT-Bench show that \textsc{ChunkFT} consistently outperforms existing memory-efficient baselines. Notably, \textsc{ChunkFT} achieves performance comparable to, and in some cases exceeding, full-parameter fine-tuning. Our repository is on https://github.com/misonsky/chunk.
SMoA: Spectrum Modulation Adapter for Parameter-Efficient Fine-Tuning
May 20, 2026As the number of model parameters increases, parameter-efficient fine-tuning (PEFT) has become the go-to choice for tailoring pre-trained large language models. Low-rank Adaptation (LoRA) uses a low-rank update method to simulate full parameter fine-tuning, which is widely used to reduce resource requirements. However, decreasing the rank encounters challenges with limited representational capacity. Theory suggests that LoRA fine-tuning with rank r converges toward the top r singular values of the pre-trained weight matrix. As the rank increases, more principal singular directions are preserved, which generally improves the model's performance. However, a larger rank also introduces more trainable parameters, leading to higher computational cost. To overcome this dilemma, we propose SMoA, a \textbf{S}pectrum \textbf{Mo}dulation \textbf{A}dapter that enlarges the accessible family of spectrum-aware updates under a smaller parameter budget. SMoA partitions the layer into multiple aligned spectral blocks and applies one in-block Hadamard-modulated low-rank branch to each diagonal block, yielding broader coverage of pretrained spectral directions. We provide theoretical analysis and empirical results on multiple tasks. In our experiments, SMoA improves average performance in the current lower-budget setting over LoRA and competitive LoRA-style baselines.
High-Rank Structured Modulation for Parameter-Efficient Fine-Tuning
Jan 12, 2026As the number of model parameters increases, parameter-efficient fine-tuning (PEFT) has become the go-to choice for tailoring pre-trained large language models. Low-rank Adaptation (LoRA) uses a low-rank update method to simulate full parameter fine-tuning, which is widely used to reduce resource requirements. However, decreasing the rank encounters challenges with limited representational capacity when compared to full parameter fine-tuning. We present \textbf{SMoA}, a high-rank \textbf{S}tructured \textbf{MO}dulation \textbf{A}dapter that uses fewer trainable parameters while maintaining a higher rank, thereby improving the model's representational capacity and offering improved performance potential. The core idea is to freeze the original pretrained weights and selectively amplify or suppress important features of the original weights across multiple subspaces. The subspace mechanism provides an efficient way to increase the capacity and complexity of a model. We conduct both theoretical analyses and empirical studies on various tasks. Experiment results show that SMoA outperforms LoRA and its variants on 10 tasks, with extensive ablation studies validating its effectiveness.
LTA-thinker: Latent Thought-Augmented Training Framework for Large Language Models on Complex Reasoning
Sep 16, 2025



Complex Reasoning in Large Language Models can be dynamically optimized using Test-Time Scaling (TTS) to mitigate Overthinking. Methods such as Coconut, SoftCoT and its variant are effective in continuous latent space inference, the core bottleneck still lies in the efficient generation and utilization of high-quality Latent Thought. Drawing from the theory of SoftCoT++ that a larger variance in the generated Latent Thought distribution more closely approximates the golden truth distribution, we propose a Latent Thought-Augmented Training Framework--LTA-Thinker, which improves distributional variance and enhances reasoning performance from two perspectives. First, LTA-Thinker constructs a Latent Thought generation architecture based on a learnable prior. This architecture aims to increase the variance distribution of generated Latent Thought Vectors in order to simplify the overall structure and raise the performance ceiling. Second, LTA-Thinker introduces a distribution-based directional optimization paradigm that jointly constrains both distribution locality and distribution scale. This mechanism improves information efficiency and computational cost through a multi-objective co-training strategy, which combines standard Supervised Fine-Tuning (SFT) loss with two novel losses: Semantic Alignment Loss, which utilizes KL divergence to ensure that the Latent Thought is highly relevant to the semantics of the question; Reasoning Focus Loss, which utilizes a contrastive learning mechanism to guide the model to focus on the most critical reasoning steps. Experiments show that LTA-thinker achieves state-of-the-art (SOTA) performance among various baselines and demonstrates a higher performance ceiling and better scaling effects.
ConvergeWriter: Data-Driven Bottom-Up Article Construction
Sep 16, 2025Large Language Models (LLMs) have shown remarkable prowess in text generation, yet producing long-form, factual documents grounded in extensive external knowledge bases remains a significant challenge. Existing "top-down" methods, which first generate a hypothesis or outline and then retrieve evidence, often suffer from a disconnect between the model's plan and the available knowledge, leading to content fragmentation and factual inaccuracies. To address these limitations, we propose a novel "bottom-up," data-driven framework that inverts the conventional generation pipeline. Our approach is predicated on a "Retrieval-First for Knowledge, Clustering for Structure" strategy, which first establishes the "knowledge boundaries" of the source corpus before any generative planning occurs. Specifically, we perform exhaustive iterative retrieval from the knowledge base and then employ an unsupervised clustering algorithm to organize the retrieved documents into distinct "knowledge clusters." These clusters form an objective, data-driven foundation that directly guides the subsequent generation of a hierarchical outline and the final document content. This bottom-up process ensures that the generated text is strictly constrained by and fully traceable to the source material, proactively adapting to the finite scope of the knowledge base and fundamentally mitigating the risk of hallucination. Experimental results on both 14B and 32B parameter models demonstrate that our method achieves performance comparable to or exceeding state-of-the-art baselines, and is expected to demonstrate unique advantages in knowledge-constrained scenarios that demand high fidelity and structural coherence. Our work presents an effective paradigm for generating reliable, structured, long-form documents, paving the way for more robust LLM applications in high-stakes, knowledge-intensive domains.
CogDual: Enhancing Dual Cognition of LLMs via Reinforcement Learning with Implicit Rule-Based Rewards
Jul 23, 2025



Role-Playing Language Agents (RPLAs) have emerged as a significant application direction for Large Language Models (LLMs). Existing approaches typically rely on prompt engineering or supervised fine-tuning to enable models to imitate character behaviors in specific scenarios, but often neglect the underlying \emph{cognitive} mechanisms driving these behaviors. Inspired by cognitive psychology, we introduce \textbf{CogDual}, a novel RPLA adopting a \textit{cognize-then-respond } reasoning paradigm. By jointly modeling external situational awareness and internal self-awareness, CogDual generates responses with improved character consistency and contextual alignment. To further optimize the performance, we employ reinforcement learning with two general-purpose reward schemes designed for open-domain text generation. Extensive experiments on the CoSER benchmark, as well as Cross-MR and LifeChoice, demonstrate that CogDual consistently outperforms existing baselines and generalizes effectively across diverse role-playing tasks.
Multimodal Relational Triple Extraction with Query-based Entity Object Transformer
Aug 16, 2024Multimodal Relation Extraction is crucial for constructing flexible and realistic knowledge graphs. Recent studies focus on extracting the relation type with entity pairs present in different modalities, such as one entity in the text and another in the image. However, existing approaches require entities and objects given beforehand, which is costly and impractical. To address the limitation, we propose a novel task, Multimodal Entity-Object Relational Triple Extraction, which aims to extract all triples (entity span, relation, object region) from image-text pairs. To facilitate this study, we modified a multimodal relation extraction dataset MORE, which includes 21 relation types, to create a new dataset containing 20,264 triples, averaging 5.75 triples per image-text pair. Moreover, we propose QEOT, a query-based model with a selective attention mechanism, to dynamically explore the interaction and fusion of textual and visual information. In particular, the proposed method can simultaneously accomplish entity extraction, relation classification, and object detection with a set of queries. Our method is suitable for downstream applications and reduces error accumulation due to the pipeline-style approaches. Extensive experimental results demonstrate that our proposed method outperforms the existing baselines by 8.06% and achieves state-of-the-art performance.
RTF: Region-based Table Filling Method for Relational Triple Extraction
Apr 29, 2024



Relational triple extraction is crucial work for the automatic construction of knowledge graphs. Existing methods only construct shallow representations from a token or token pair-level. However, previous works ignore local spatial dependencies of relational triples, resulting in a weakness of entity pair boundary detection. To tackle this problem, we propose a novel Region-based Table Filling method (RTF). We devise a novel region-based tagging scheme and bi-directional decoding strategy, which regard each relational triple as a region on the relation-specific table, and identifies triples by determining two endpoints of each region. We also introduce convolution to construct region-level table representations from a spatial perspective which makes triples easier to be captured. In addition, we share partial tagging scores among different relations to improve learning efficiency of relation classifier. Experimental results show that our method achieves state-of-the-art with better generalization capability on three variants of two widely used benchmark datasets.
TechGPT-2.0: A large language model project to solve the task of knowledge graph construction
Jan 09, 2024Large language models have exhibited robust performance across diverse natural language processing tasks. This report introduces TechGPT-2.0, a project designed to enhance the capabilities of large language models specifically in knowledge graph construction tasks, including named entity recognition (NER) and relationship triple extraction (RTE) tasks in NLP applications. Additionally, it serves as a LLM accessible for research within the Chinese open-source model community. We offer two 7B large language model weights and a QLoRA weight specialized for processing lengthy texts.Notably, TechGPT-2.0 is trained on Huawei's Ascend server. Inheriting all functionalities from TechGPT-1.0, it exhibits robust text processing capabilities, particularly in the domains of medicine and law. Furthermore, we introduce new capabilities to the model, enabling it to process texts in various domains such as geographical areas, transportation, organizations, literary works, biology, natural sciences, astronomical objects, and architecture. These enhancements also fortified the model's adeptness in handling hallucinations, unanswerable queries, and lengthy texts. This report provides a comprehensive and detailed introduction to the full fine-tuning process on Huawei's Ascend servers, encompassing experiences in Ascend server debugging, instruction fine-tuning data processing, and model training. Our code is available at https://github.com/neukg/TechGPT-2.0
An Understanding-Oriented Robust Machine Reading Comprehension Model
Jul 01, 2022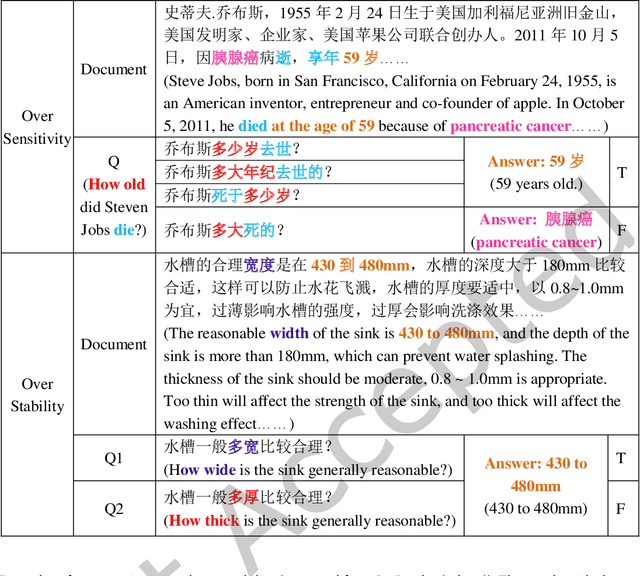
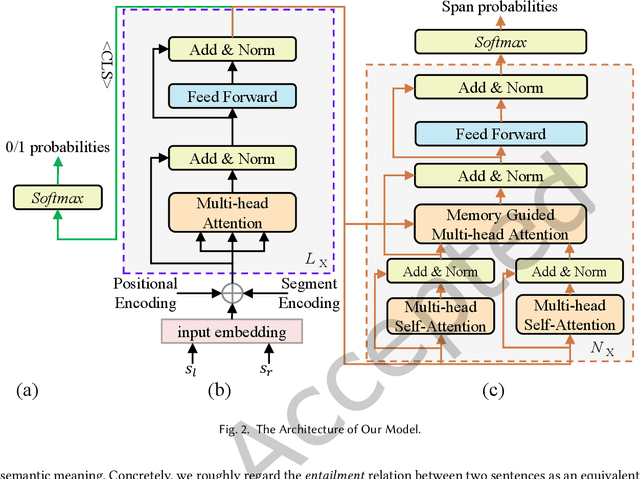
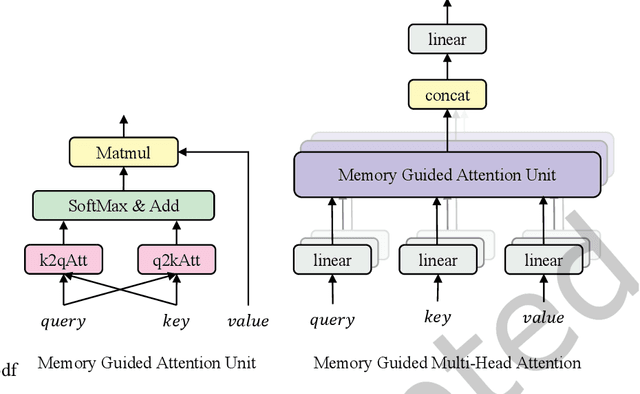
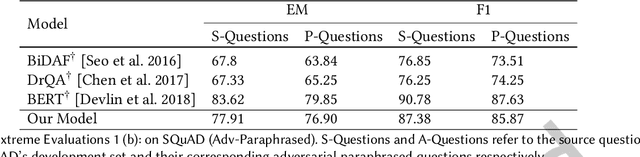
Although existing machine reading comprehension models are making rapid progress on many datasets, they are far from robust. In this paper, we propose an understanding-oriented machine reading comprehension model to address three kinds of robustness issues, which are over sensitivity, over stability and generalization. Specifically, we first use a natural language inference module to help the model understand the accurate semantic meanings of input questions so as to address the issues of over sensitivity and over stability. Then in the machine reading comprehension module, we propose a memory-guided multi-head attention method that can further well understand the semantic meanings of input questions and passages. Third, we propose a multilanguage learning mechanism to address the issue of generalization. Finally, these modules are integrated with a multi-task learning based method. We evaluate our model on three benchmark datasets that are designed to measure models robustness, including DuReader (robust) and two SQuAD-related datasets. Extensive experiments show that our model can well address the mentioned three kinds of robustness issues. And it achieves much better results than the compared state-of-the-art models on all these datasets under different evaluation metrics, even under some extreme and unfair evaluations. The source code of our work is available at: https://github.com/neukg/RobustMRC.