 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo-FocalNets: Spatio-Temporal Focal Modulation for Video Action Recognition
Jul 16, 2023



Recent video recognition models utilize Transformer models for long-range spatio-temporal context modeling. Video transformer designs are based on self-attention that can model global context at a high computational cost. In comparison, convolutional designs for videos offer an efficient alternative but lack long-range dependency modeling. Towards achieving the best of both designs, this work proposes Video-FocalNet, an effective and efficient architecture for video recognition that models both local and global contexts. Video-FocalNet is based on a spatio-temporal focal modulation architecture that reverses the interaction and aggregation steps of self-attention for better efficiency. Further, the aggregation step and the interaction step are both implemented using efficient convolution and element-wise multiplication operations that are computationally less expensive than their self-attention counterparts on video representations. We extensively explore the design space of focal modulation-based spatio-temporal context modeling and demonstrate our parallel spatial and temporal encoding design to be the optimal choice. Video-FocalNets perform favorably well against the state-of-the-art transformer-based models for video recognition on three large-scale datasets (Kinetics-400, Kinetics-600, and SS-v2) at a lower computational cost. Our code/models are released at https://github.com/TalalWasim/Video-FocalNets.
Self-regulating Prompts: Foundational Model Adaptation without Forgetting
Jul 13, 2023



Prompt learning has emerged as an efficient alternative for fine-tuning foundational models, such as CLIP, for various downstream tasks. Conventionally trained using the task-specific objective, i.e., cross-entropy loss, prompts tend to overfit downstream data distributions and find it challenging to capture task-agnostic general features from the frozen CLIP. This leads to the loss of the model's original generalization capability. To address this issue, our work introduces a self-regularization framework for prompting called PromptSRC (Prompting with Self-regulating Constraints). PromptSRC guides the prompts to optimize for both task-specific and task-agnostic general representations using a three-pronged approach by: (a) regulating {prompted} representations via mutual agreement maximization with the frozen model, (b) regulating with self-ensemble of prompts over the training trajectory to encode their complementary strengths, and (c) regulating with textual diversity to mitigate sample diversity imbalance with the visual branch. To the best of our knowledge, this is the first regularization framework for prompt learning that avoids overfitting by jointly attending to pre-trained model features, the training trajectory during prompting, and the textual diversity. PromptSRC explicitly steers the prompts to learn a representation space that maximizes performance on downstream tasks without compromising CLIP generalization. We perform extensive experiments on 4 benchmarks where PromptSRC overall performs favorably well compared to the existing methods. Our code and pre-trained models are publicly available at: https://github.com/muzairkhattak/PromptSRC.
Learnable Weight Initialization for Volumetric Medical Image Segmentation
Jun 28, 2023



Hybrid volumetric medical image segmentation models, combining the advantages of local convolution and global attention, have recently received considerable attention. While mainly focusing on architectural modifications, most existing hybrid approaches still use conventional data-independent weight initialization schemes which restrict their performance due to ignoring the inherent volumetric nature of the medical data. To address this issue, we propose a learnable weight initialization approach that utilizes the available medical training data to effectively learn the contextual and structural cues via the proposed self-supervised objectives. Our approach is easy to integrate into any hybrid model and requires no external training data. Experiments on multi-organ and lung cancer segmentation tasks demonstrate the effectiveness of our approach, leading to state-of-the-art segmentation performance. Our proposed data-dependent initialization approach performs favorably as compared to the Swin-UNETR model pretrained using large-scale datasets on multi-organ segmentation task. Our source code and models are available at: https://github.com/ShahinaKK/LWI-VMS.
PromptIR: Prompting for All-in-One Blind Image Restoration
Jun 22, 2023Image restoration involves recovering a high-quality clean image from its degraded version. Deep learning-based methods have significantly improved image restoration performance, however, they have limited generalization ability to different degradation types and levels. This restricts their real-world application since it requires training individual models for each specific degradation and knowing the input degradation type to apply the relevant model. We present a prompt-based learning approach, PromptIR, for All-In-One image restoration that can effectively restore images from various types and levels of degradation. In particular, our method uses prompts to encode degradation-specific information, which is then used to dynamically guide the restoration network. This allows our method to generalize to different degradation types and levels, while still achieving state-of-the-art results on image denoising, deraining, and dehazing. Overall, PromptIR offers a generic and efficient plugin module with few lightweight prompts that can be used to restore images of various types and levels of degradation with no prior information on the corruptions present in the image. Our code and pretrained models are available here: https://github.com/va1shn9v/PromptIR
Self-Distilled Masked Auto-Encoders are Efficient Video Anomaly Detectors
Jun 21, 2023



We propose an efficient abnormal event detection model based on a lightweight masked auto-encoder (AE) applied at the video frame level. The novelty of the proposed model is threefold. First, we introduce an approach to weight tokens based on motion gradients, thus avoiding learning to reconstruct the static background scene. Second, we integrate a teacher decoder and a student decoder into our architecture, leveraging the discrepancy between the outputs given by the two decoders to improve anomaly detection. Third, we generate synthetic abnormal events to augment the training videos, and task the masked AE model to jointly reconstruct the original frames (without anomalies) and the corresponding pixel-level anomaly maps. Our design leads to an efficient and effective model, as demonstrated by the extensive experiments carried out on three benchmarks: Avenue, ShanghaiTech and UCSD Ped2. The empirical results show that our model achieves an excellent trade-off between speed and accuracy, obtaining competitive AUC scores, while processing 1670 FPS. Hence, our model is between 8 and 70 times faster than competing methods. We also conduct an ablation study to justify our design.
XrayGPT: Chest Radiographs Summarization using Medical Vision-Language Models
Jun 13, 2023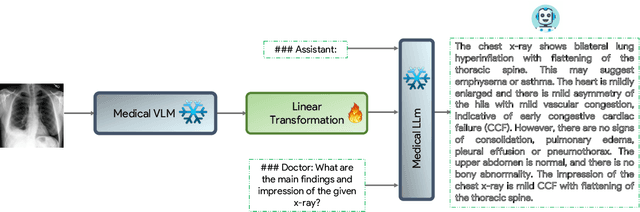
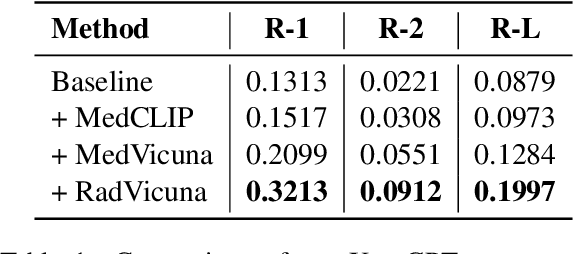


The latest breakthroughs in large vision-language models, such as Bard and GPT-4, have showcased extraordinary abilities in performing a wide range of tasks. Such models are trained on massive datasets comprising billions of public image-text pairs with diverse tasks. However, their performance on task-specific domains, such as radiology, is still under-investigated and potentially limited due to a lack of sophistication in understanding biomedical images. On the other hand, conversational medical models have exhibited remarkable success but have mainly focused on text-based analysis. In this paper, we introduce XrayGPT, a novel conversational medical vision-language model that can analyze and answer open-ended questions about chest radiographs. Specifically, we align both medical visual encoder (MedClip) with a fine-tuned large language model (Vicuna), using a simple linear transformation. This alignment enables our model to possess exceptional visual conversation abilities, grounded in a deep understanding of radiographs and medical domain knowledge. To enhance the performance of LLMs in the medical context, we generate ~217k interactive and high-quality summaries from free-text radiology reports. These summaries serve to enhance the performance of LLMs through the fine-tuning process. Our approach opens up new avenues the research for advancing the automated analysis of chest radiographs. Our open-source demos, models, and instruction sets are available at: https://github.com/mbzuai-oryx/XrayGPT.
Video-ChatGPT: Towards Detailed Video Understanding via Large Vision and Language Models
Jun 08, 2023



Conversation agents fueled by Large Language Models (LLMs) are providing a new way to interact with visual data. While there have been initial attempts for image-based conversation models, this work addresses the underexplored field of video-based conversation by introducing Video-ChatGPT. It is a multimodal model that merges a video-adapted visual encoder with a LLM. The model is capable of understanding and generating human-like conversations about videos. We introduce a new dataset of 100,000 video-instruction pairs used to train Video-ChatGPT acquired via manual and semi-automated pipeline that is easily scalable and robust to label noise. We also develop a quantiative evaluation framework for video-based dialogue models to objectively analyse the strengths and weaknesses of proposed models. Our code, models, instruction-sets and demo are released at https://github.com/mbzuai-oryx/Video-ChatGPT.
DFormer: Diffusion-guided Transformer for Universal Image Segmentation
Jun 08, 2023



This paper introduces an approach, named DFormer, for universal image segmentation. The proposed DFormer views universal image segmentation task as a denoising process using a diffusion model. DFormer first adds various levels of Gaussian noise to ground-truth masks, and then learns a model to predict denoising masks from corrupted masks. Specifically, we take deep pixel-level features along with the noisy masks as inputs to generate mask features and attention masks, employing diffusion-based decoder to perform mask prediction gradually. At inference, our DFormer directly predicts the masks and corresponding categories from a set of randomly-generated masks. Extensive experiments reveal the merits of our proposed contributions on different image segmentation tasks: panoptic segmentation, instance segmentation, and semantic segmentation. Our DFormer outperforms the recent diffusion-based panoptic segmentation method Pix2Seq-D with a gain of 3.6% on MS COCO val2017 set. Further, DFormer achieves promising semantic segmentation performance outperforming the recent diffusion-based method by 2.2% on ADE20K val set. Our source code and models will be publicly on https://github.com/cp3wan/DFormer
Modulate Your Spectrum in Self-Supervised Learning
May 26, 2023



Whitening loss provides theoretical guarantee in avoiding feature collapse for self-supervised learning (SSL) using joint embedding architectures. One typical implementation of whitening loss is hard whitening that designs whitening transformation over embedding and imposes the loss on the whitened output. In this paper, we propose spectral transformation (ST) framework to map the spectrum of embedding to a desired distribution during forward pass, and to modulate the spectrum of embedding by implicit gradient update during backward pass. We show that whitening transformation is a special instance of ST by definition, and there exist other instances that can avoid collapse by our empirical investigation. Furthermore, we propose a new instance of ST, called IterNorm with trace loss (INTL). We theoretically prove that INTL can avoid collapse and modulate the spectrum of embedding towards an equal-eigenvalue distribution during the course of optimization. Moreover, INTL achieves 76.6% top-1 accuracy in linear evaluation on ImageNet using ResNet-50, which exceeds the performance of the supervised baseline, and this result is obtained by using a batch size of only 256. Comprehensive experiments show that INTL is a promising SSL method in practice. The code is available at https://github.com/winci-ai/intl.
Salient Mask-Guided Vision Transformer for Fine-Grained Classification
May 11, 2023



Fine-grained visual classification (FGVC) is a challenging computer vision problem, where the task is to automatically recognise objects from subordinate categories. One of its main difficulties is capturing the most discriminative inter-class variances among visually similar classes. Recently, methods with Vision Transformer (ViT) have demonstrated noticeable achievements in FGVC, generally by employing the self-attention mechanism with additional resource-consuming techniques to distinguish potentially discriminative regions while disregarding the rest. However, such approaches may struggle to effectively focus on truly discriminative regions due to only relying on the inherent self-attention mechanism, resulting in the classification token likely aggregating global information from less-important background patches. Moreover, due to the immense lack of the datapoints, classifiers may fail to find the most helpful inter-class distinguishing features, since other unrelated but distinctive background regions may be falsely recognised as being valuable. To this end, we introduce a simple yet effective Salient Mask-Guided Vision Transformer (SM-ViT), where the discriminability of the standard ViT`s attention maps is boosted through salient masking of potentially discriminative foreground regions. Extensive experiments demonstrate that with the standard training procedure our SM-ViT achieves state-of-the-art performance on popular FGVC benchmarks among existing ViT-based approaches while requiring fewer resources and lower input image resolution.
* Accepted by VISAPP 2023 (Best Student Paper Award)