 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAD: A Scalable Dataset for Language Grounding in Videos from Movie Audio Descriptions
Dec 01, 2021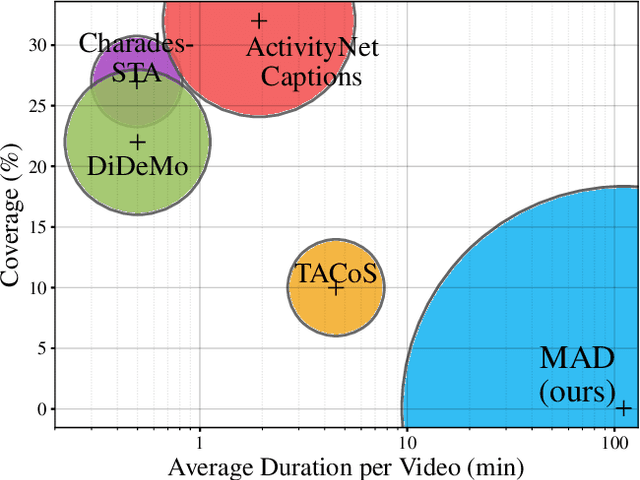
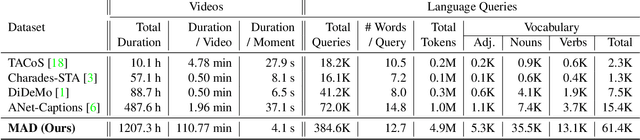


The recent and increasing interest in video-language research has driven the development of large-scale datasets that enable data-intensive machine learning techniques. In comparison, limited effort has been made at assessing the fitness of these datasets for the video-language grounding task. Recent works have begun to discover significant limitations in these datasets, suggesting that state-of-the-art techniques commonly overfit to hidden dataset biases. In this work, we present MAD (Movie Audio Descriptions), a novel benchmark that departs from the paradigm of augmenting existing video datasets with text annotations and focuses on crawling and aligning available audio descriptions of mainstream movies. MAD contains over 384,000 natural language sentences grounded in over 1,200 hours of video and exhibits a significant reduction in the currently diagnosed biases for video-language grounding datasets. MAD's collection strategy enables a novel and more challenging version of video-language grounding, where short temporal moments (typically seconds long) must be accurately grounded in diverse long-form videos that can last up to three hours.
MovieCuts: A New Dataset and Benchmark for Cut Type Recognition
Sep 19, 2021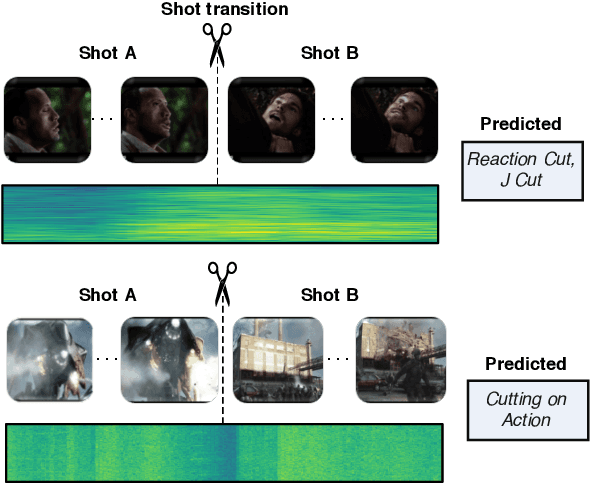
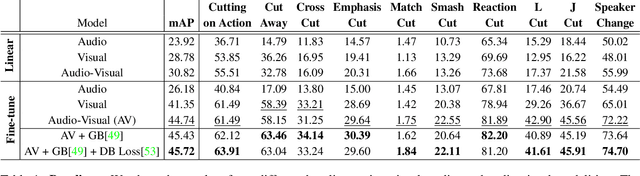
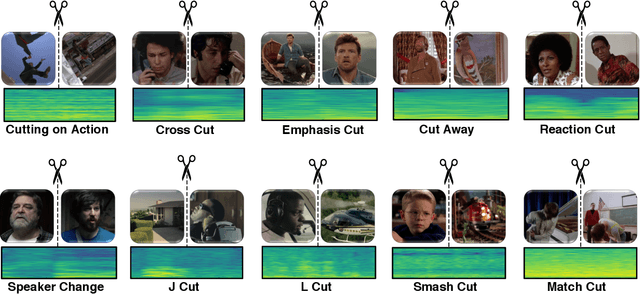
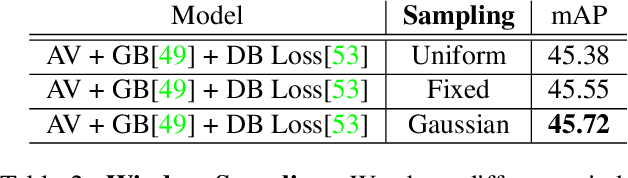
Understanding movies and their structural patterns is a crucial task to decode the craft of video editing. While previous works have developed tools for general analysis such as detecting characters or recognizing cinematography properties at the shot level, less effort has been devoted to understanding the most basic video edit, the Cut. This paper introduces the cut type recognition task, which requires modeling of multi-modal information. To ignite research in the new task, we construct a large-scale dataset called MovieCuts, which contains more than 170K videoclips labeled among ten cut types. We benchmark a series of audio-visual approaches, including some that deal with the problem's multi-modal and multi-label nature. Our best model achieves 45.7% mAP, which suggests that the task is challenging and that attaining highly accurate cut type recognition is an open research problem.
Learning to Cut by Watching Movies
Aug 09, 2021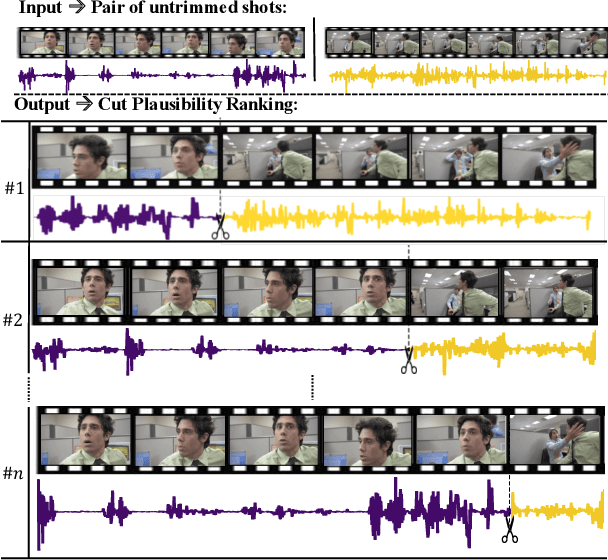
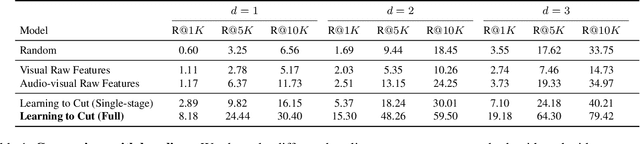


Video content creation keeps growing at an incredible pace; yet, creating engaging stories remains challenging and requires non-trivial video editing expertise. Many video editing components are astonishingly hard to automate primarily due to the lack of raw video materials. This paper focuses on a new task for computational video editing, namely the task of raking cut plausibility. Our key idea is to leverage content that has already been edited to learn fine-grained audiovisual patterns that trigger cuts. To do this, we first collected a data source of more than 10K videos, from which we extract more than 255K cuts. We devise a model that learns to discriminate between real and artificial cuts via contrastive learning. We set up a new task and a set of baselines to benchmark video cut generation. We observe that our proposed model outperforms the baselines by large margins. To demonstrate our model in real-world applications, we conduct human studies in a collection of unedited videos. The results show that our model does a better job at cutting than random and alternative baselines.
Transcript to Video: Efficient Clip Sequencing from Texts
Jul 25, 2021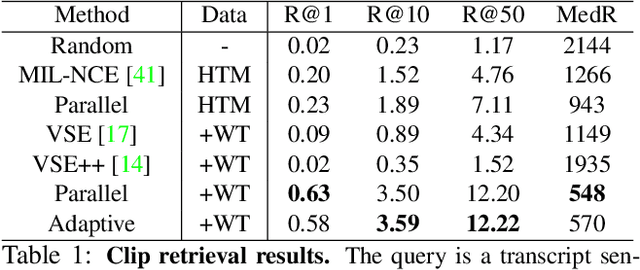

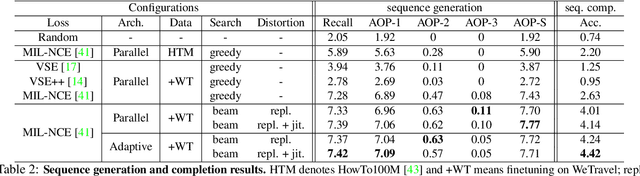
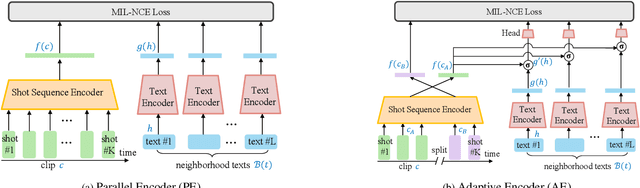
Among numerous videos shared on the web, well-edited ones always attract more attention. However, it is difficult for inexperienced users to make well-edited videos because it requires professional expertise and immense manual labor. To meet the demands for non-experts, we present Transcript-to-Video -- a weakly-supervised framework that uses texts as input to automatically create video sequences from an extensive collection of shots. Specifically, we propose a Content Retrieval Module and a Temporal Coherent Module to learn visual-language representations and model shot sequencing styles, respectively. For fast inference, we introduce an efficient search strategy for real-time video clip sequencing. Quantitative results and user studies demonstrate empirically that the proposed learning framework can retrieve content-relevant shots while creating plausible video sequences in terms of style. Besides, the run-time performance analysis shows that our framework can support real-world applications.
APES: Audiovisual Person Search in Untrimmed Video
Jun 03, 2021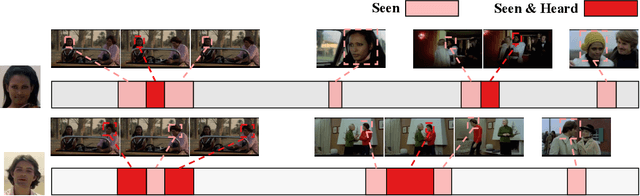
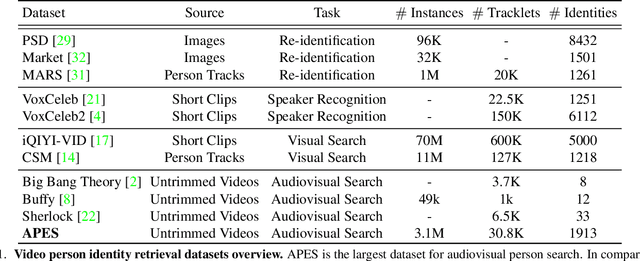


Humans are arguably one of the most important subjects in video streams, many real-world applications such as video summarization or video editing workflows often require the automatic search and retrieval of a person of interest. Despite tremendous efforts in the person reidentification and retrieval domains, few works have developed audiovisual search strategies. In this paper, we present the Audiovisual Person Search dataset (APES), a new dataset composed of untrimmed videos whose audio (voices) and visual (faces) streams are densely annotated. APES contains over 1.9K identities labeled along 36 hours of video, making it the largest dataset available for untrimmed audiovisual person search. A key property of APES is that it includes dense temporal annotations that link faces to speech segments of the same identity. To showcase the potential of our new dataset, we propose an audiovisual baseline and benchmark for person retrieval. Our study shows that modeling audiovisual cues benefits the recognition of people's identities. To enable reproducibility and promote future research, the dataset annotations and baseline code are available at: https://github.com/fuankarion/audiovisual-person-search
MAAS: Multi-modal Assignation for Active Speaker Detection
Jan 11, 2021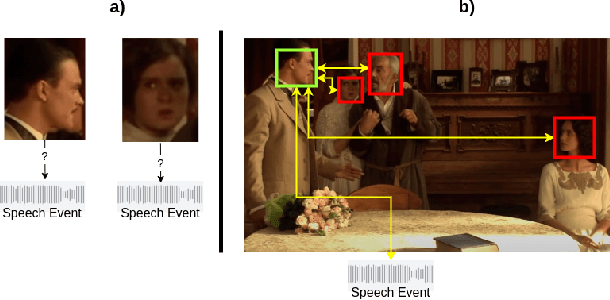

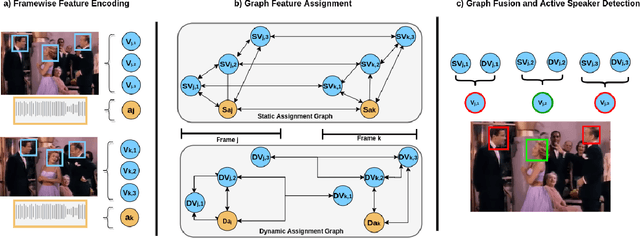

Active speaker detection requires a solid integration of multi-modal cues. While individual modalities can approximate a solution, accurate predictions can only be achieved by explicitly fusing the audio and visual features and modeling their temporal progression. Despite its inherent muti-modal nature, current methods still focus on modeling and fusing short-term audiovisual features for individual speakers, often at frame level. In this paper we present a novel approach to active speaker detection that directly addresses the multi-modal nature of the problem, and provides a straightforward strategy where independent visual features from potential speakers in the scene are assigned to a previously detected speech event. Our experiments show that, an small graph data structure built from a single frame, allows to approximate an instantaneous audio-visual assignment problem. Moreover, the temporal extension of this initial graph achieves a new state-of-the-art on the AVA-ActiveSpeaker dataset with a mAP of 88.8\%.
Real-time Semantic Segmentation with Fast Attention
Jul 09, 2020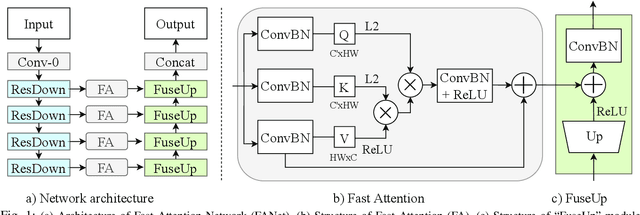
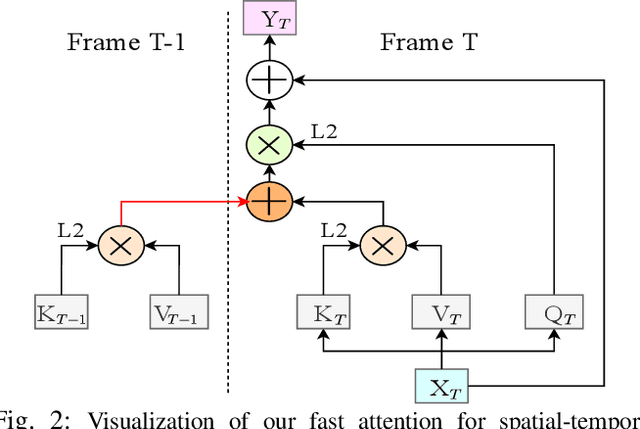
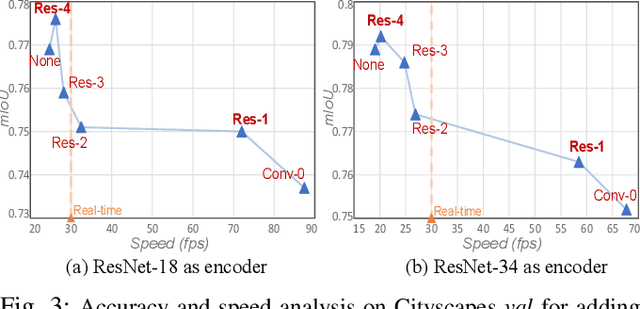

In deep CNN based models for semantic segmentation, high accuracy relies on rich spatial context (large receptive fields) and fine spatial details (high resolution), both of which incur high computational costs. In this paper, we propose a novel architecture that addresses both challenges and achieves state-of-the-art performance for semantic segmentation of high-resolution images and videos in real-time. The proposed architecture relies on our fast spatial attention, which is a simple yet efficient modification of the popular self-attention mechanism and captures the same rich spatial context at a small fraction of the computational cost, by changing the order of operations. Moreover, to efficiently process high-resolution input, we apply an additional spatial reduction to intermediate feature stages of the network with minimal loss in accuracy thanks to the use of the fast attention module to fuse features. We validate our method with a series of experiments, and show that results on multiple datasets demonstrate superior performance with better accuracy and speed compared to existing approaches for real-time semantic segmentation. On Cityscapes, our network achieves 74.4$\%$ mIoU at 72 FPS and 75.5$\%$ mIoU at 58 FPS on a single Titan X GPU, which is~$\sim$50$\%$ faster than the state-of-the-art while retaining the same accuracy.
Active Speakers in Context
May 20, 2020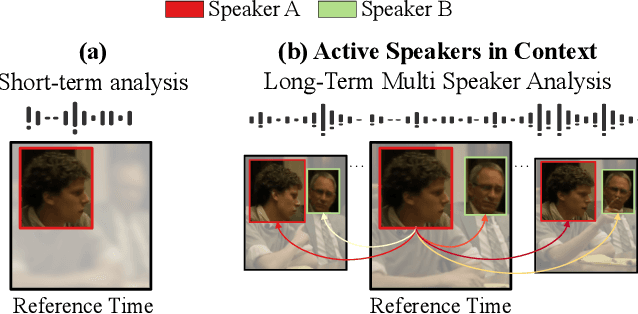
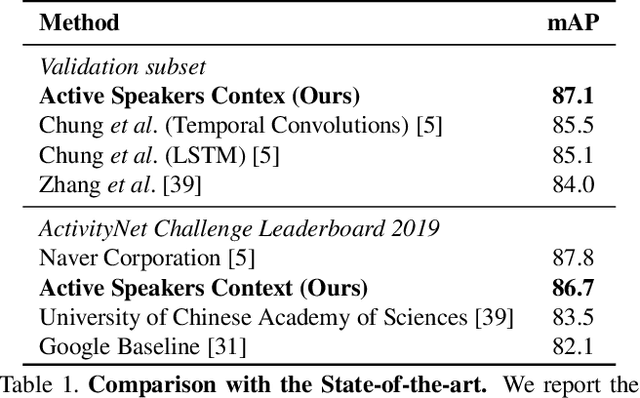
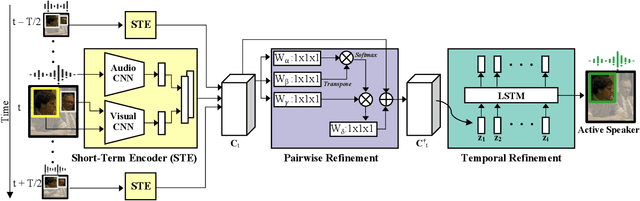

Current methods for active speak er detection focus on modeling short-term audiovisual information from a single speaker. Although this strategy can be enough for addressing single-speaker scenarios, it prevents accurate detection when the task is to identify who of many candidate speakers are talking. This paper introduces the Active Speaker Context, a novel representation that models relationships between multiple speakers over long time horizons. Our Active Speaker Context is designed to learn pairwise and temporal relations from an structured ensemble of audio-visual observations. Our experiments show that a structured feature ensemble already benefits the active speaker detection performance. Moreover, we find that the proposed Active Speaker Context improves the state-of-the-art on the AVA-ActiveSpeaker dataset achieving a mAP of 87.1%. We present ablation studies that verify that this result is a direct consequence of our long-term multi-speaker analysis.
Temporally Distributed Networks for Fast Video Semantic Segmentation
Apr 07, 2020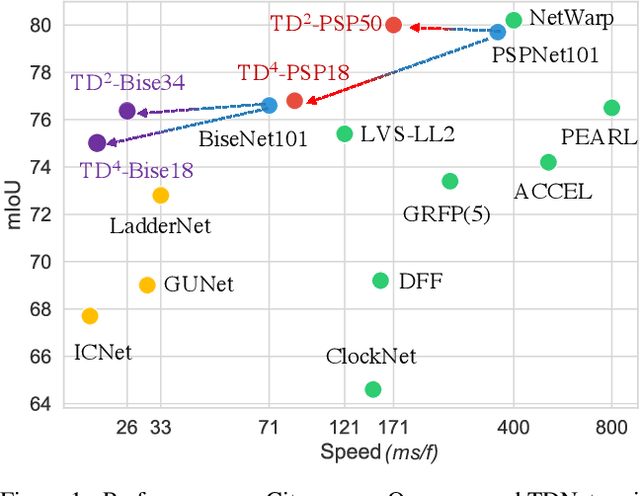
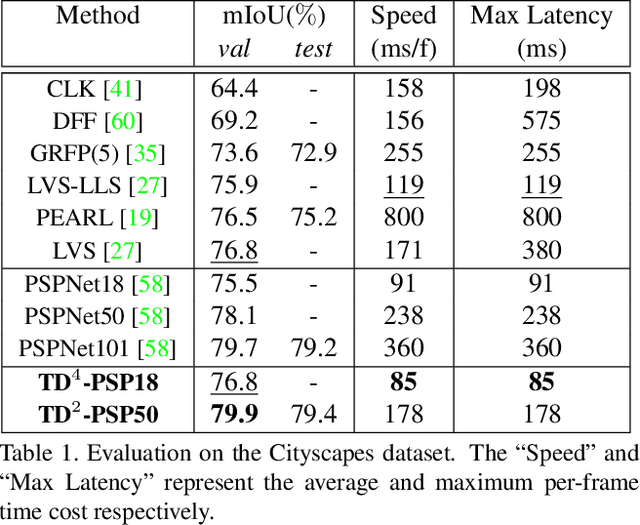
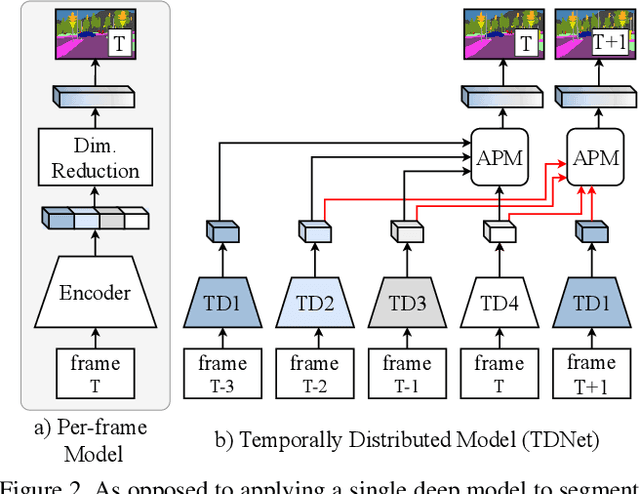
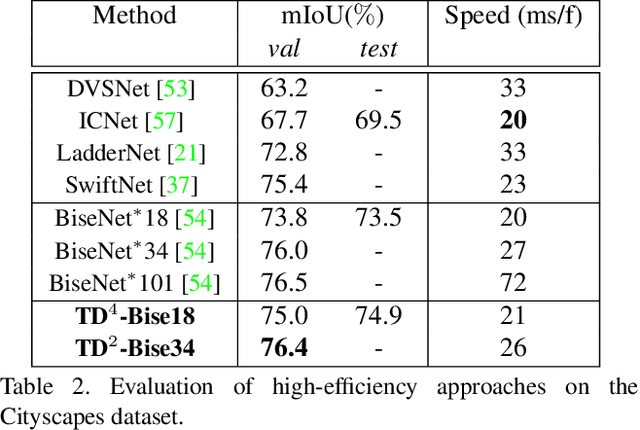
We present TDNet, a temporally distributed network designed for fast and accurate video semantic segmentation. We observe that features extracted from a certain high-level layer of a deep CNN can be approximated by composing features extracted from several shallower sub-networks. Leveraging the inherent temporal continuity in videos, we distribute these sub-networks over sequential frames. Therefore, at each time step, we only need to perform a lightweight computation to extract a sub-features group from a single sub-network. The full features used for segmentation are then recomposed by application of a novel attention propagation module that compensates for geometry deformation between frames. A grouped knowledge distillation loss is also introduced to further improve the representation power at both full and sub-feature levels. Experiments on Cityscapes, CamVid, and NYUD-v2 demonstrate that our method achieves state-of-the-art accuracy with significantly faster speed and lower latency.
Rethinking Online Action Detection in Untrimmed Videos: A Novel Online Evaluation Protocol
Mar 26, 2020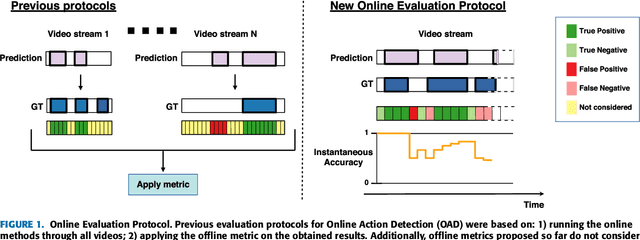
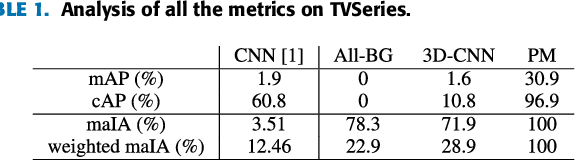
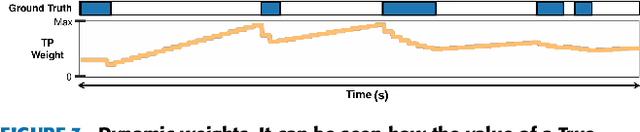
The Online Action Detection (OAD) problem needs to be revisited. Unlike traditional offline action detection approaches, where the evaluation metrics are clear and well established, in the OAD setting we find very few works and no consensus on the evaluation protocols to be used. In this work we propose to rethink the OAD scenario, clearly defining the problem itself and the main characteristics that the models which are considered online must comply with. We also introduce a novel metric: the Instantaneous Accuracy ($IA$). This new metric exhibits an \emph{online} nature and solves most of the limitations of the previous metrics. We conduct a thorough experimental evaluation on 3 challenging datasets, where the performance of various baseline methods is compared to that of the state-of-the-art. Our results confirm the problems of the previous evaluation protocols, and suggest that an IA-based protocol is more adequate to the online scenario. The baselines models and a development kit with the novel evaluation protocol are publicly available: https://github.com/gramuah/ia.