 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMJ1: Multimodal Judgment via Grounded Verification
Mar 09, 2026Multimodal judges struggle to ground decisions in visual evidence. We present MJ1, a multimodal judge trained with reinforcement learning that enforces visual grounding through a structured grounded verification chain (observations $\rightarrow$ claims $\rightarrow$ verification $\rightarrow$ evaluation $\rightarrow$ scoring) and a counterfactual consistency reward that penalizes position bias. Even without training, our mechanism improves base-model accuracy on MMRB2 by +3.8 points on Image Editing and +1.7 on Multimodal Reasoning. After training, MJ1, with only 3B active parameters, achieves 77.0% accuracy on MMRB2 and surpasses orders-of-magnitude larger models like Gemini-3-Pro. These results show that grounded verification and consistency-based training substantially improve multimodal judgment without increasing model scale.
CurvaDion: Curvature-Adaptive Distributed Orthonormalization
Dec 13, 2025As language models scale to trillions of parameters, distributed training across many GPUs becomes essential, yet gradient synchronization over high-bandwidth, low-latency networks remains a critical bottleneck. While recent methods like Dion reduce per-step communication through low-rank updates, they synchronize at every step regardless of the optimization landscape. We observe that synchronization requirements vary dramatically throughout training: workers naturally compute similar gradients in flat regions, making frequent synchronization redundant, while high-curvature regions require coordination to prevent divergence. We introduce CurvaDion, which uses Relative Maximum Momentum Change (RMMC) to detect high-curvature regions requiring synchronization. RMMC leverages momentum dynamics which are already computed during optimization as a computationally tractable proxy for directional curvature, adding only $\mathcal{O}(d)$ operations per layer. We establish theoretical connections between RMMC and loss curvature and demonstrate that CurvaDion achieves 99\% communication reduction while matching baseline convergence across models from 160M to 1.3B parameters.
Generative Visual Question Answering
Jul 18, 2023Multi-modal tasks involving vision and language in deep learning continue to rise in popularity and are leading to the development of newer models that can generalize beyond the extent of their training data. The current models lack temporal generalization which enables models to adapt to changes in future data. This paper discusses a viable approach to creating an advanced Visual Question Answering (VQA) model which can produce successful results on temporal generalization. We propose a new data set, GenVQA, utilizing images and captions from the VQAv2 and MS-COCO dataset to generate new images through stable diffusion. This augmented dataset is then used to test a combination of seven baseline and cutting edge VQA models. Performance evaluation focuses on questions mirroring the original VQAv2 dataset, with the answers having been adjusted to the new images. This paper's purpose is to investigate the robustness of several successful VQA models to assess their performance on future data distributions. Model architectures are analyzed to identify common stylistic choices that improve generalization under temporal distribution shifts. This research highlights the importance of creating a large-scale future shifted dataset. This data can enhance the robustness of VQA models, allowing their future peers to have improved ability to adapt to temporal distribution shifts.
ViT Cane: Visual Assistant for the Visually Impaired
Sep 26, 2021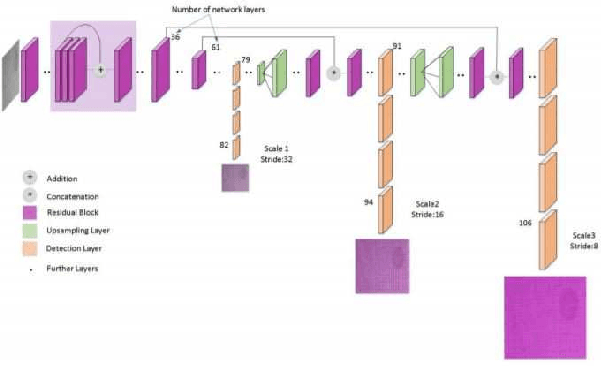
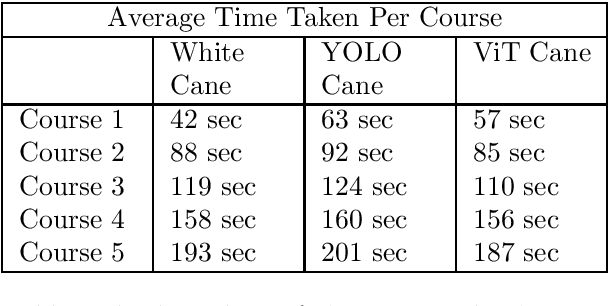
Blind and visually challenged face multiple issues with navigating the world independently. Some of these challenges include finding the shortest path to a destination and detecting obstacles from a distance. To tackle this issue, this paper proposes ViT Cane, which leverages a vision transformer model in order to detect obstacles in real-time. Our entire system consists of a Pi Camera Module v2, Raspberry Pi 4B with 8GB Ram and 4 motors. Based on tactile input using the 4 motors, the obstacle detection model is highly efficient in helping visually impaired navigate unknown terrain and is designed to be easily reproduced. The paper discusses the utility of a Visual Transformer model in comparison to other CNN based models for this specific application. Through rigorous testing, the proposed obstacle detection model has achieved higher performance on the Common Object in Context (COCO) data set than its CNN counterpart. Comprehensive field tests were conducted to verify the effectiveness of our system for holistic indoor understanding and obstacle avoidance.