 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayeredDoc: Domain Adaptive Document Restoration with a Layer Separation Approach
Jun 12, 2024



The rapid evolution of intelligent document processing systems demands robust solutions that adapt to diverse domains without extensive retraining. Traditional methods often falter with variable document types, leading to poor performance. To overcome these limitations, this paper introduces a text-graphic layer separation approach that enhances domain adaptability in document image restoration (DIR) systems. We propose LayeredDoc, which utilizes two layers of information: the first targets coarse-grained graphic components, while the second refines machine-printed textual content. This hierarchical DIR framework dynamically adjusts to the characteristics of the input document, facilitating effective domain adaptation. We evaluated our approach both qualitatively and quantitatively using a new real-world dataset, LayeredDocDB, developed for this study. Initially trained on a synthetically generated dataset, our model demonstrates strong generalization capabilities for the DIR task, offering a promising solution for handling variability in real-world data. Our code is accessible on GitHub.
Multi-Page Document Visual Question Answering using Self-Attention Scoring Mechanism
Apr 29, 2024



Documents are 2-dimensional carriers of written communication, and as such their interpretation requires a multi-modal approach where textual and visual information are efficiently combined. Document Visual Question Answering (Document VQA), due to this multi-modal nature, has garnered significant interest from both the document understanding and natural language processing communities. The state-of-the-art single-page Document VQA methods show impressive performance, yet in multi-page scenarios, these methods struggle. They have to concatenate all pages into one large page for processing, demanding substantial GPU resources, even for evaluation. In this work, we propose a novel method and efficient training strategy for multi-page Document VQA tasks. In particular, we employ a visual-only document representation, leveraging the encoder from a document understanding model, Pix2Struct. Our approach utilizes a self-attention scoring mechanism to generate relevance scores for each document page, enabling the retrieval of pertinent pages. This adaptation allows us to extend single-page Document VQA models to multi-page scenarios without constraints on the number of pages during evaluation, all with minimal demand for GPU resources. Our extensive experiments demonstrate not only achieving state-of-the-art performance without the need for Optical Character Recognition (OCR), but also sustained performance in scenarios extending to documents of nearly 800 pages compared to a maximum of 20 pages in the MP-DocVQA dataset. Our code is publicly available at \url{https://github.com/leitro/SelfAttnScoring-MPDocVQA}.
Machine Unlearning for Document Classification
Apr 29, 2024



Document understanding models have recently demonstrated remarkable performance by leveraging extensive collections of user documents. However, since documents often contain large amounts of personal data, their usage can pose a threat to user privacy and weaken the bonds of trust between humans and AI services. In response to these concerns, legislation advocating ``the right to be forgotten" has recently been proposed, allowing users to request the removal of private information from computer systems and neural network models. A novel approach, known as machine unlearning, has emerged to make AI models forget about a particular class of data. In our research, we explore machine unlearning for document classification problems, representing, to the best of our knowledge, the first investigation into this area. Specifically, we consider a realistic scenario where a remote server houses a well-trained model and possesses only a small portion of training data. This setup is designed for efficient forgetting manipulation. This work represents a pioneering step towards the development of machine unlearning methods aimed at addressing privacy concerns in document analysis applications. Our code is publicly available at \url{https://github.com/leitro/MachineUnlearning-DocClassification}.
Privacy-Aware Document Visual Question Answering
Dec 15, 2023



Document Visual Question Answering (DocVQA) is a fast growing branch of document understanding. Despite the fact that documents contain sensitive or copyrighted information, none of the current DocVQA methods offers strong privacy guarantees. In this work, we explore privacy in the domain of DocVQA for the first time. We highlight privacy issues in state of the art multi-modal LLM models used for DocVQA, and explore possible solutions. Specifically, we focus on the invoice processing use case as a realistic, widely used scenario for document understanding, and propose a large scale DocVQA dataset comprising invoice documents and associated questions and answers. We employ a federated learning scheme, that reflects the real-life distribution of documents in different businesses, and we explore the use case where the ID of the invoice issuer is the sensitive information to be protected. We demonstrate that non-private models tend to memorise, behaviour that can lead to exposing private information. We then evaluate baseline training schemes employing federated learning and differential privacy in this multi-modal scenario, where the sensitive information might be exposed through any of the two input modalities: vision (document image) or language (OCR tokens). Finally, we design an attack exploiting the memorisation effect of the model, and demonstrate its effectiveness in probing different DocVQA models.
Document Understanding Dataset and Evaluation (DUDE)
May 15, 2023



We call on the Document AI (DocAI) community to reevaluate current methodologies and embrace the challenge of creating more practically-oriented benchmarks. Document Understanding Dataset and Evaluation (DUDE) seeks to remediate the halted research progress in understanding visually-rich documents (VRDs). We present a new dataset with novelties related to types of questions, answers, and document layouts based on multi-industry, multi-domain, and multi-page VRDs of various origins, and dates. Moreover, we are pushing the boundaries of current methods by creating multi-task and multi-domain evaluation setups that more accurately simulate real-world situations where powerful generalization and adaptation under low-resource settings are desired. DUDE aims to set a new standard as a more practical, long-standing benchmark for the community, and we hope that it will lead to future extensions and contributions that address real-world challenges. Finally, our work illustrates the importance of finding more efficient ways to model language, images, and layout in DocAI.
Hierarchical multimodal transformers for Multi-Page DocVQA
Dec 07, 2022



Document Visual Question Answering (DocVQA) refers to the task of answering questions from document images. Existing work on DocVQA only considers single-page documents. However, in real scenarios documents are mostly composed of multiple pages that should be processed altogether. In this work we extend DocVQA to the multi-page scenario. For that, we first create a new dataset, MP-DocVQA, where questions are posed over multi-page documents instead of single pages. Second, we propose a new hierarchical method, Hi-VT5, based on the T5 architecture, that overcomes the limitations of current methods to process long multi-page documents. The proposed method is based on a hierarchical transformer architecture where the encoder summarizes the most relevant information of every page and then, the decoder takes this summarized information to generate the final answer. Through extensive experimentation, we demonstrate that our method is able, in a single stage, to answer the questions and provide the page that contains the relevant information to find the answer, which can be used as a kind of explainability measure.
OCR-IDL: OCR Annotations for Industry Document Library Dataset
Feb 25, 2022

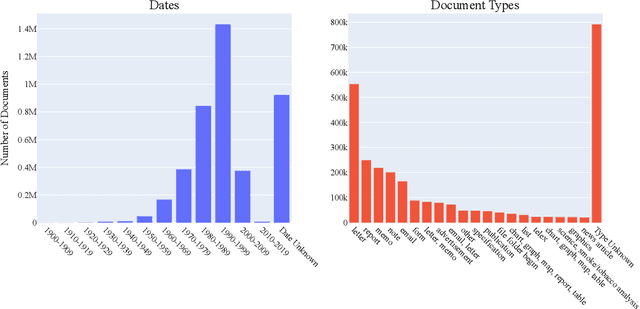
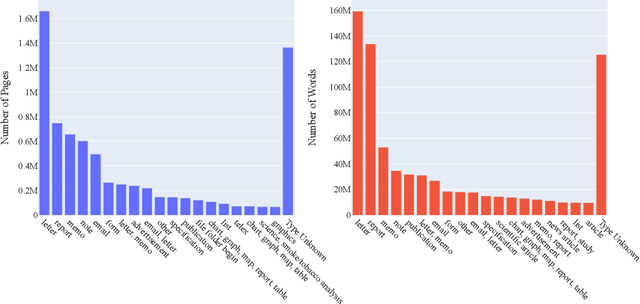
Pretraining has proven successful in Document Intelligence tasks where deluge of documents are used to pretrain the models only later to be finetuned on downstream tasks. One of the problems of the pretraining approaches is the inconsistent usage of pretraining data with different OCR engines leading to incomparable results between models. In other words, it is not obvious whether the performance gain is coming from diverse usage of amount of data and distinct OCR engines or from the proposed models. To remedy the problem, we make public the OCR annotations for IDL documents using commercial OCR engine given their superior performance over open source OCR models. The contributed dataset (OCR-IDL) has an estimated monetary value over 20K US$. It is our hope that OCR-IDL can be a starting point for future works on Document Intelligence. All of our data and its collection process with the annotations can be found in https://github.com/furkanbiten/idl_data.
ICDAR 2021 Competition on Document VisualQuestion Answering
Nov 10, 2021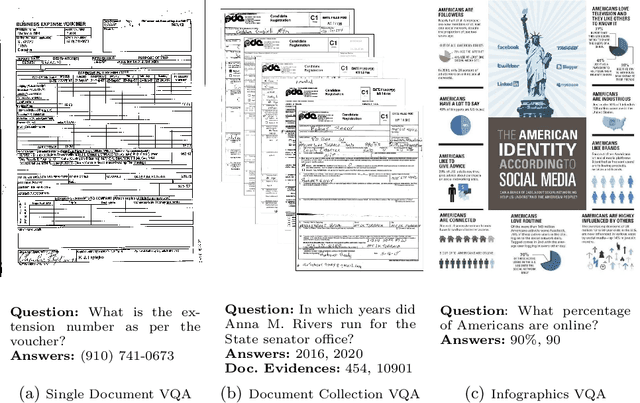
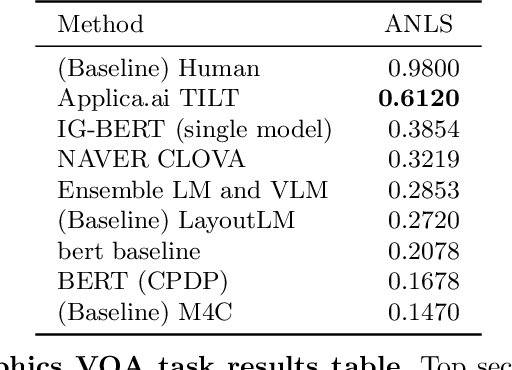
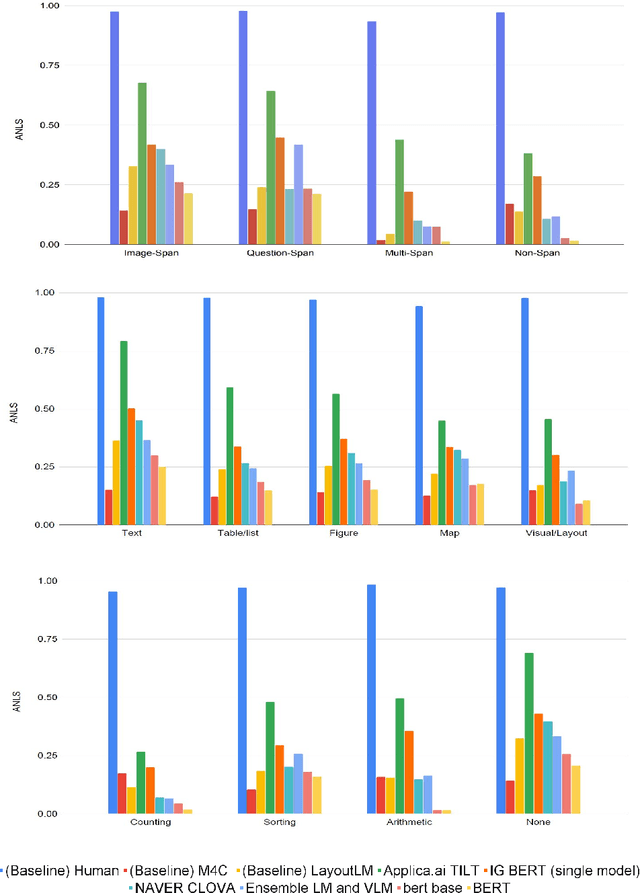
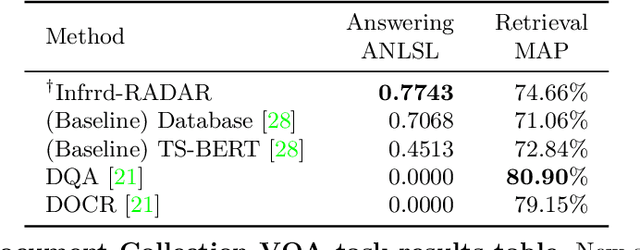
In this report we present results of the ICDAR 2021 edition of the Document Visual Question Challenges. This edition complements the previous tasks on Single Document VQA and Document Collection VQA with a newly introduced on Infographics VQA. Infographics VQA is based on a new dataset of more than 5,000 infographics images and 30,000 question-answer pairs. The winner methods have scored 0.6120 ANLS in Infographics VQA task, 0.7743 ANLSL in Document Collection VQA task and 0.8705 ANLS in Single Document VQA. We present a summary of the datasets used for each task, description of each of the submitted methods and the results and analysis of their performance. A summary of the progress made on Single Document VQA since the first edition of the DocVQA 2020 challenge is also presented.
External Knowledge Augmented Text Visual Question Answering
Aug 22, 2021
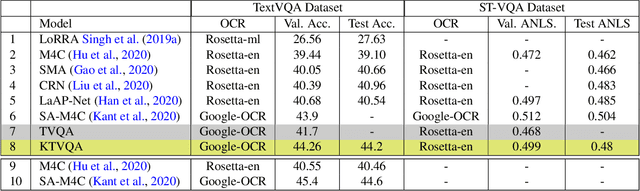
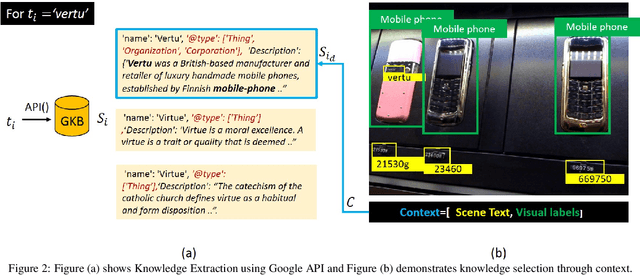
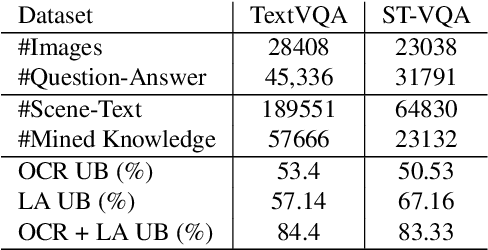
The open-ended question answering task of Text-VQA requires reading and reasoning about local, often previously unseen, scene-text content of an image to generate answers. In this work, we propose the generalized use of external knowledge to augment our understanding of the said scene-text. We design a framework to extract, filter, and encode knowledge atop a standard multimodal transformer for vision language understanding tasks. Through empirical evidence, we demonstrate how knowledge can highlight instance-only cues and thus help deal with training data bias, improve answer entity type correctness, and detect multiword named entities. We generate results comparable to the state-of-the-art on two publicly available datasets, under the constraints of similar upstream OCR systems and training data.
Document Collection Visual Question Answering
Apr 27, 2021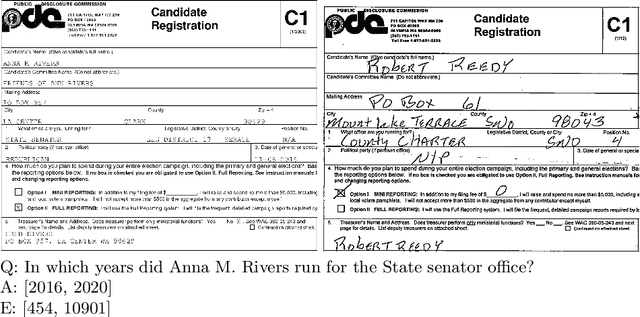
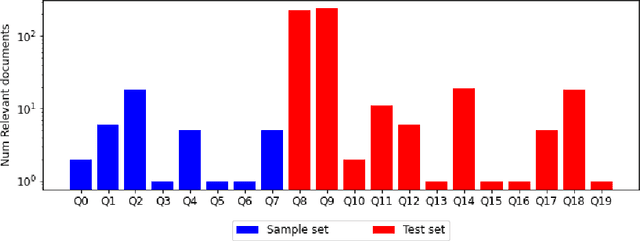


Current tasks and methods in Document Understanding aims to process documents as single elements. However, documents are usually organized in collections (historical records, purchase invoices), that provide context useful for their interpretation. To address this problem, we introduce Document Collection Visual Question Answering (DocCVQA) a new dataset and related task, where questions are posed over a whole collection of document images and the goal is not only to provide the answer to the given question, but also to retrieve the set of documents that contain the information needed to infer the answer. Along with the dataset we propose a new evaluation metric and baselines which provide further insights to the new dataset and task.