 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Models Help Us Create Better Models? Evaluating LLMs as Data Scientists
Oct 30, 2024



We present a benchmark for large language models designed to tackle one of the most knowledge-intensive tasks in data science: writing feature engineering code, which requires domain knowledge in addition to a deep understanding of the underlying problem and data structure. The model is provided with a dataset description in a prompt and asked to generate code transforming it. The evaluation score is derived from the improvement achieved by an XGBoost model fit on the modified dataset compared to the original data. By an extensive evaluation of state-of-the-art models and comparison to well-established benchmarks, we demonstrate that the FeatEng of our proposal can cheaply and efficiently assess the broad capabilities of LLMs, in contrast to the existing methods.
Arctic-TILT. Business Document Understanding at Sub-Billion Scale
Aug 08, 2024The vast portion of workloads employing LLMs involves answering questions grounded on PDF or scan content. We introduce the Arctic-TILT achieving accuracy on par with models 1000$\times$ its size on these use cases. It can be fine-tuned and deployed on a single 24GB GPU, lowering operational costs while processing Visually Rich Documents with up to 400k tokens. The model establishes state-of-the-art results on seven diverse Document Understanding benchmarks, as well as provides reliable confidence scores and quick inference, which are essential for processing files in large-scale or time-sensitive enterprise environments.
Document Understanding Dataset and Evaluation (DUDE)
May 15, 2023



We call on the Document AI (DocAI) community to reevaluate current methodologies and embrace the challenge of creating more practically-oriented benchmarks. Document Understanding Dataset and Evaluation (DUDE) seeks to remediate the halted research progress in understanding visually-rich documents (VRDs). We present a new dataset with novelties related to types of questions, answers, and document layouts based on multi-industry, multi-domain, and multi-page VRDs of various origins, and dates. Moreover, we are pushing the boundaries of current methods by creating multi-task and multi-domain evaluation setups that more accurately simulate real-world situations where powerful generalization and adaptation under low-resource settings are desired. DUDE aims to set a new standard as a more practical, long-standing benchmark for the community, and we hope that it will lead to future extensions and contributions that address real-world challenges. Finally, our work illustrates the importance of finding more efficient ways to model language, images, and layout in DocAI.
STable: Table Generation Framework for Encoder-Decoder Models
Jun 08, 2022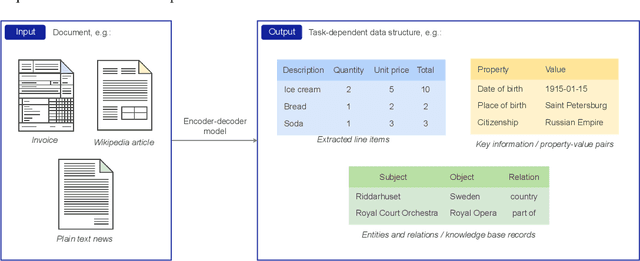
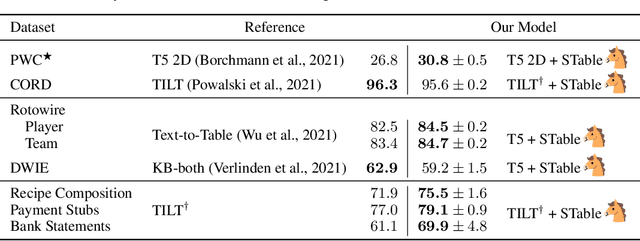
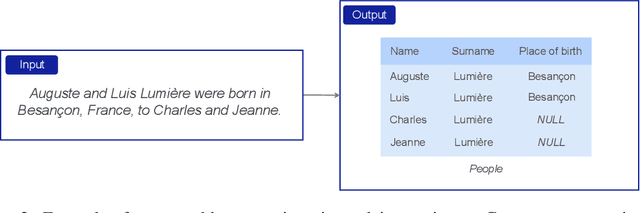
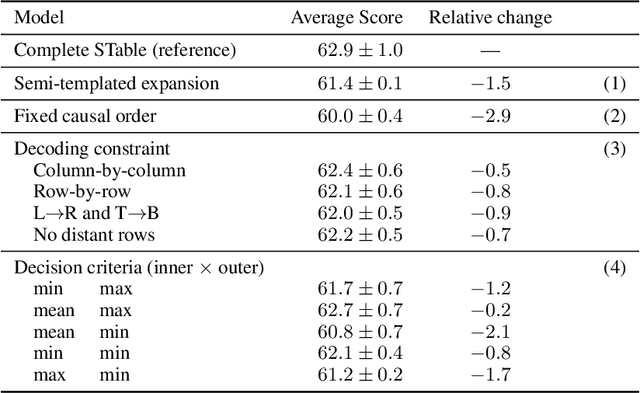
The output structure of database-like tables, consisting of values structured in horizontal rows and vertical columns identifiable by name, can cover a wide range of NLP tasks. Following this constatation, we propose a framework for text-to-table neural models applicable to problems such as extraction of line items, joint entity and relation extraction, or knowledge base population. The permutation-based decoder of our proposal is a generalized sequential method that comprehends information from all cells in the table. The training maximizes the expected log-likelihood for a table's content across all random permutations of the factorization order. During the content inference, we exploit the model's ability to generate cells in any order by searching over possible orderings to maximize the model's confidence and avoid substantial error accumulation, which other sequential models are prone to. Experiments demonstrate a high practical value of the framework, which establishes state-of-the-art results on several challenging datasets, outperforming previous solutions by up to 15%.
Going Full-TILT Boogie on Document Understanding with Text-Image-Layout Transformer
Mar 02, 2021We address the challenging problem of Natural Language Comprehension beyond plain-text documents by introducing the TILT neural network architecture which simultaneously learns layout information, visual features, and textual semantics. Contrary to previous approaches, we rely on a decoder capable of unifying a variety of problems involving natural language. The layout is represented as an attention bias and complemented with contextualized visual information, while the core of our model is a pretrained encoder-decoder Transformer. Our novel approach achieves state-of-the-art results in extracting information from documents and answering questions which demand layout understanding (DocVQA, CORD, WikiOps, SROIE). At the same time, we simplify the process by employing an end-to-end model.
From Dataset Recycling to Multi-Property Extraction and Beyond
Nov 06, 2020
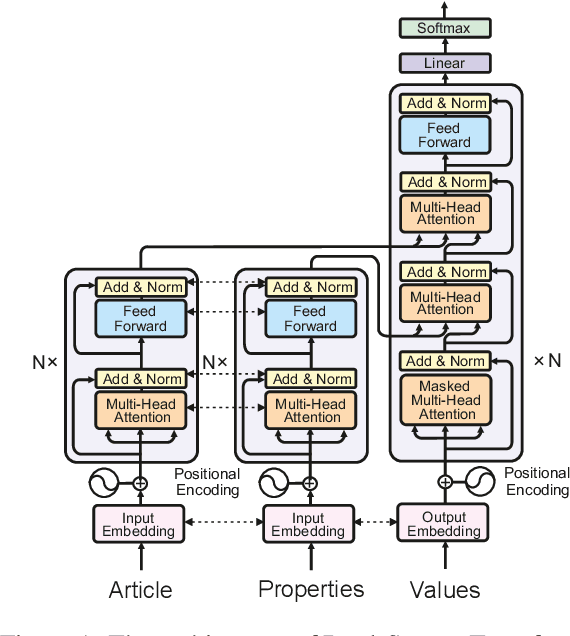
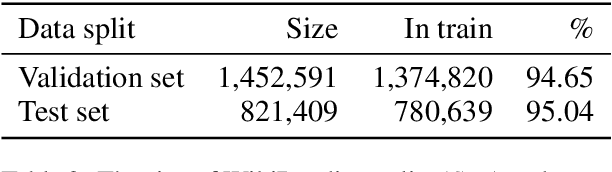
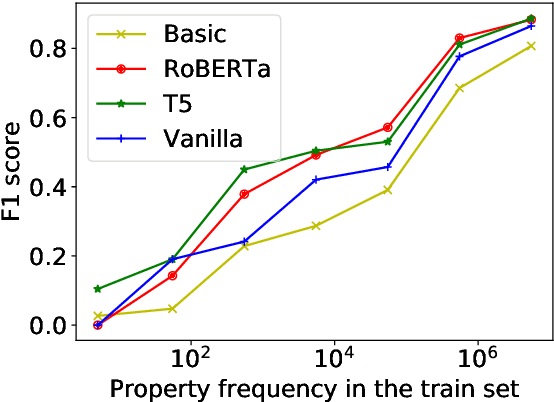
This paper investigates various Transformer architectures on the WikiReading Information Extraction and Machine Reading Comprehension dataset. The proposed dual-source model outperforms the current state-of-the-art by a large margin. Next, we introduce WikiReading Recycled-a newly developed public dataset and the task of multiple property extraction. It uses the same data as WikiReading but does not inherit its predecessor's identified disadvantages. In addition, we provide a human-annotated test set with diagnostic subsets for a detailed analysis of model performance.
Successive Halving Top-k Operator
Oct 08, 2020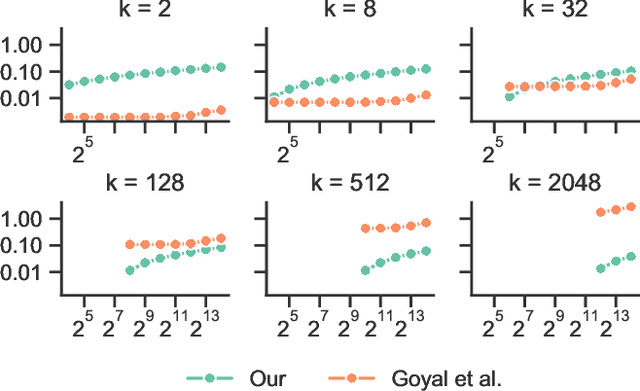
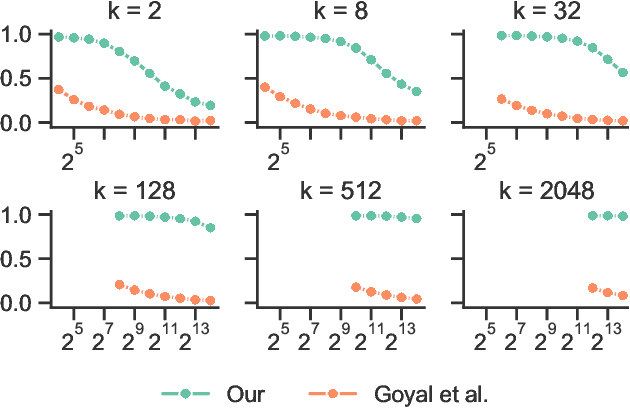
We propose a differentiable successive halving method of relaxing the top-k operator, rendering gradient-based optimization possible. The need to perform softmax iteratively on the entire vector of scores is avoided by using a tournament-style selection. As a result, a much better approximation of top-k with lower computational cost is achieved compared to the previous approach.
Sparsifying Transformer Models with Differentiable Representation Pooling
Sep 10, 2020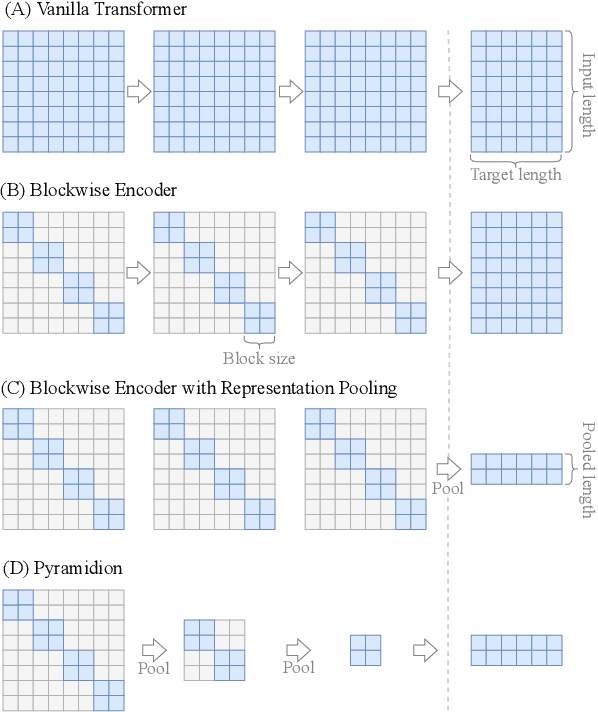
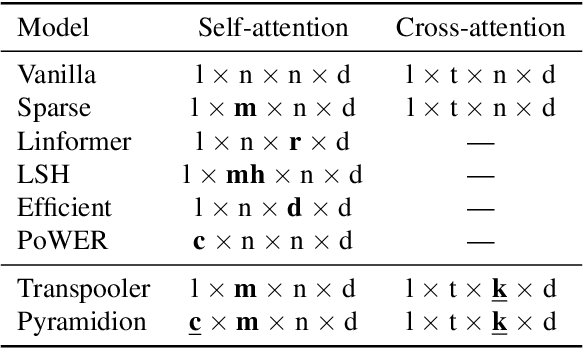
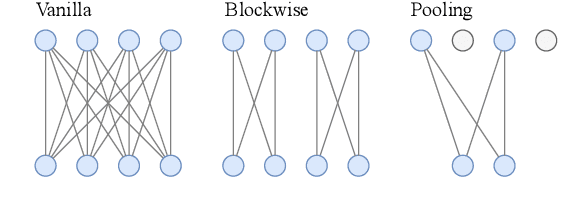
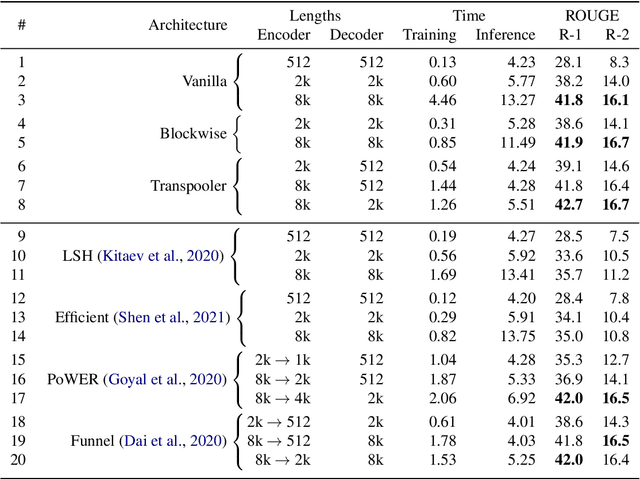
We propose a novel method to sparsify attention in the Transformer model by learning to select the most-informative token representations, thus leveraging the model's information bottleneck with twofold strength. A careful analysis shows that the contextualization of encoded representations in our model is significantly more effective than in the original Transformer. We achieve a notable reduction in memory usage due to an improved differentiable top-k operator, making the model suitable to process long documents, as shown on an example of a summarization task.
On the Multi-Property Extraction and Beyond
Jun 15, 2020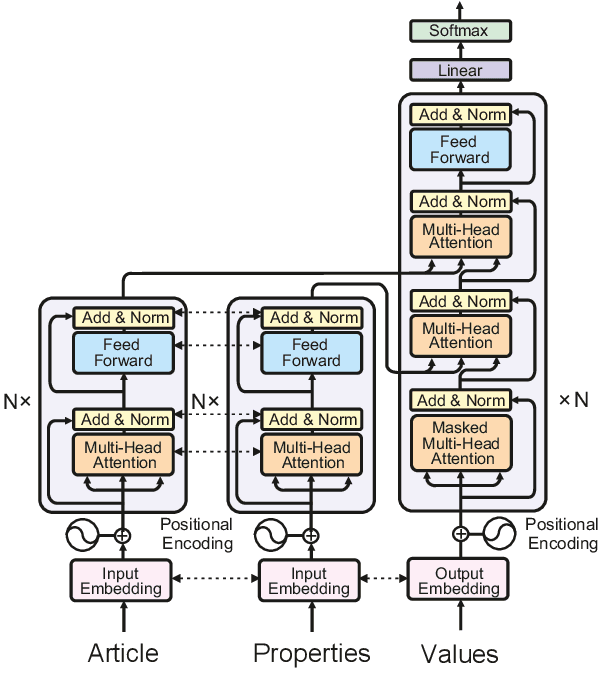


In this paper, we investigate the Dual-source Transformer architecture on the WikiReading information extraction and machine reading comprehension dataset. The proposed model outperforms the current state-of-the-art by a large margin. Next, we introduce WikiReading Recycled - a newly developed public dataset, supporting the task of multiple property extraction. It keeps the spirit of the original WikiReading but does not inherit the identified disadvantages of its predecessor.