 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeB$^2$F-Map: Crowd-sourced Mapping with Bayesian B-spline Fusion
Mar 02, 2026Crowd-sourced mapping offers a scalable alternative to creating maps using traditional survey vehicles. Yet, existing methods either rely on prior high-definition (HD) maps or neglect uncertainties in the map fusion. In this work, we present a complete pipeline for HD map generation using production vehicles equipped only with a monocular camera, consumer-grade GNSS, and IMU. Our approach includes on-cloud localization using lightweight standard-definition maps, on-vehicle mapping via an extended object trajectory (EOT) Poisson multi-Bernoulli (PMB) filter with Gibbs sampling, and on-cloud multi-drive optimization and Bayesian map fusion. We represent the lane lines using B-splines, where each B-spline is parameterized by a sequence of Gaussian distributed control points, and propose a novel Bayesian fusion framework for B-spline trajectories with differing density representation, enabling principled handling of uncertainties. We evaluate our proposed approach, B$^2$F-Map, on large-scale real-world datasets collected across diverse driving conditions and demonstrate that our method is able to produce geometrically consistent lane-level maps.
Bayesian Simultaneous Localization and Multi-Lane Tracking Using Onboard Sensors and a SD Map
May 07, 2024
High-definition map with accurate lane-level information is crucial for autonomous driving, but the creation of these maps is a resource-intensive process. To this end, we present a cost-effective solution to create lane-level roadmaps using only the global navigation satellite system (GNSS) and a camera on customer vehicles. Our proposed solution utilizes a prior standard-definition (SD) map, GNSS measurements, visual odometry, and lane marking edge detection points, to simultaneously estimate the vehicle's 6D pose, its position within a SD map, and also the 3D geometry of traffic lines. This is achieved using a Bayesian simultaneous localization and multi-object tracking filter, where the estimation of traffic lines is formulated as a multiple extended object tracking problem, solved using a trajectory Poisson multi-Bernoulli mixture (TPMBM) filter. In TPMBM filtering, traffic lines are modeled using B-spline trajectories, and each trajectory is parameterized by a sequence of control points. The proposed solution has been evaluated using experimental data collected by a test vehicle driving on highway. Preliminary results show that the traffic line estimates, overlaid on the satellite image, generally align with the lane markings up to some lateral offsets.
Localization Is All You Evaluate: Data Leakage in Online Mapping Datasets and How to Fix It
Dec 11, 2023Data leakage is a critical issue when training and evaluating any method based on supervised learning. The state-of-the-art methods for online mapping are based on supervised learning and are trained predominantly using two datasets: nuScenes and Argoverse 2. These datasets revisit the same geographic locations across training, validation, and test sets. Specifically, over $80$% of nuScenes and $40$% of Argoverse 2 validation and test samples are located less than $5$ m from a training sample. This allows methods to localize within a memorized implicit map during testing and leads to inflated performance numbers being reported. To reveal the true performance in unseen environments, we introduce geographical splits of the data. Experimental results show significantly lower performance numbers, for some methods dropping with more than $45$ mAP, when retraining and reevaluating existing online mapping models with the proposed split. Additionally, a reassessment of prior design choices reveals diverging conclusions from those based on the original split. Notably, the impact of the lifting method and the support from auxiliary tasks (e.g., depth supervision) on performance appears less substantial or follows a different trajectory than previously perceived. Geographical splits can be found https://github.com/LiljaAdam/geographical-splits
Fine-Grained Segmentation Networks: Self-Supervised Segmentation for Improved Long-Term Visual Localization
Aug 18, 2019
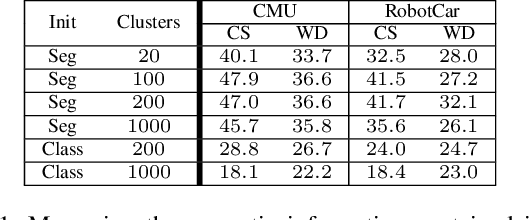
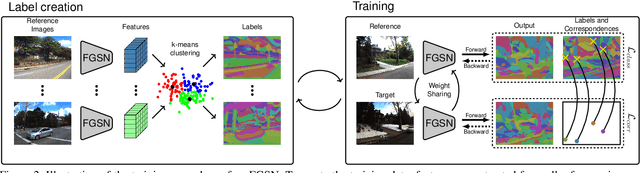
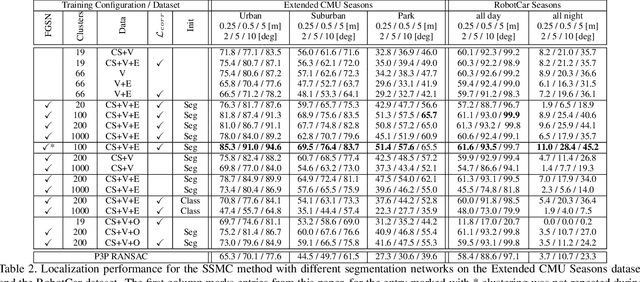
Long-term visual localization is the problem of estimating the camera pose of a given query image in a scene whose appearance changes over time. It is an important problem in practice, for example, encountered in autonomous driving. In order to gain robustness to such changes, long-term localization approaches often use segmantic segmentations as an invariant scene representation, as the semantic meaning of each scene part should not be affected by seasonal and other changes. However, these representations are typically not very discriminative due to the limited number of available classes. In this paper, we propose a new neural network, the Fine-Grained Segmentation Network (FGSN), that can be used to provide image segmentations with a larger number of labels and can be trained in a self-supervised fashion. In addition, we show how FGSNs can be trained to output consistent labels across seasonal changes. We demonstrate through extensive experiments that integrating the fine-grained segmentations produced by our FGSNs into existing localization algorithms leads to substantial improvements in localization performance.
A Cross-Season Correspondence Dataset for Robust Semantic Segmentation
Mar 16, 2019
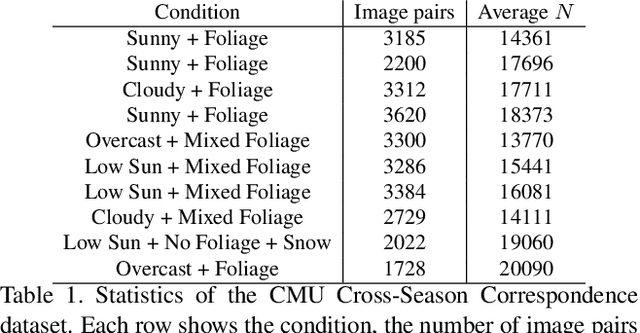

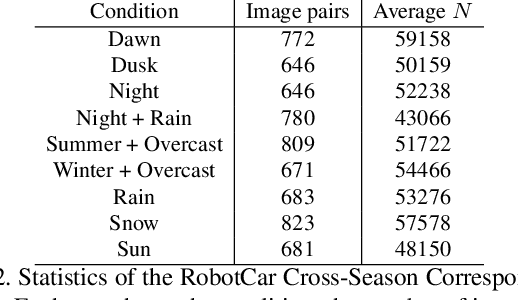
In this paper, we present a method to utilize 2D-2D point matches between images taken during different image conditions to train a convolutional neural network for semantic segmentation. Enforcing label consistency across the matches makes the final segmentation algorithm robust to seasonal changes. We describe how these 2D-2D matches can be generated with little human interaction by geometrically matching points from 3D models built from images. Two cross-season correspondence datasets are created providing 2D-2D matches across seasonal changes as well as from day to night. The datasets are made publicly available to facilitate further research. We show that adding the correspondences as extra supervision during training improves the segmentation performance of the convolutional neural network, making it more robust to seasonal changes and weather conditions.
Benchmarking 6DOF Outdoor Visual Localization in Changing Conditions
Apr 04, 2018
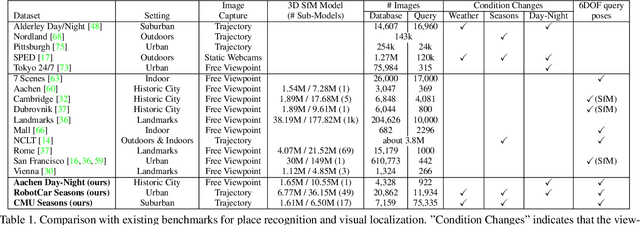


Visual localization enables autonomous vehicles to navigate in their surroundings and augmented reality applications to link virtual to real worlds. Practical visual localization approaches need to be robust to a wide variety of viewing condition, including day-night changes, as well as weather and seasonal variations, while providing highly accurate 6 degree-of-freedom (6DOF) camera pose estimates. In this paper, we introduce the first benchmark datasets specifically designed for analyzing the impact of such factors on visual localization. Using carefully created ground truth poses for query images taken under a wide variety of conditions, we evaluate the impact of various factors on 6DOF camera pose estimation accuracy through extensive experiments with state-of-the-art localization approaches. Based on our results, we draw conclusions about the difficulty of different conditions, showing that long-term localization is far from solved, and propose promising avenues for future work, including sequence-based localization approaches and the need for better local features. Our benchmark is available at visuallocalization.net.
Long-term Visual Localization using Semantically Segmented Images
Mar 02, 2018

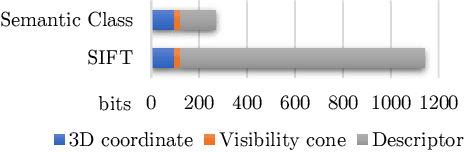
Robust cross-seasonal localization is one of the major challenges in long-term visual navigation of autonomous vehicles. In this paper, we exploit recent advances in semantic segmentation of images, i.e., where each pixel is assigned a label related to the type of object it represents, to attack the problem of long-term visual localization. We show that semantically labeled 3-D point maps of the environment, together with semantically segmented images, can be efficiently used for vehicle localization without the need for detailed feature descriptors (SIFT, SURF, etc.). Thus, instead of depending on hand-crafted feature descriptors, we rely on the training of an image segmenter. The resulting map takes up much less storage space compared to a traditional descriptor based map. A particle filter based semantic localization solution is compared to one based on SIFT-features, and even with large seasonal variations over the year we perform on par with the larger and more descriptive SIFT-features, and are able to localize with an error below 1 m most of the time.