 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Cardiac MRI Segmentation via Classifier-Guided Two-Stage Network and All-Slice Information Fusion Transformer
Sep 02, 2023Cardiac Magnetic Resonance imaging (CMR) is the gold standard for assessing cardiac function. Segmenting the left ventricle (LV), right ventricle (RV), and LV myocardium (MYO) in CMR images is crucial but time-consuming. Deep learning-based segmentation methods have emerged as effective tools for automating this process. However, CMR images present additional challenges due to irregular and varying heart shapes, particularly in basal and apical slices. In this study, we propose a classifier-guided two-stage network with an all-slice fusion transformer to enhance CMR segmentation accuracy, particularly in basal and apical slices. Our method was evaluated on extensive clinical datasets and demonstrated better performance in terms of Dice score compared to previous CNN-based and transformer-based models. Moreover, our method produces visually appealing segmentation shapes resembling human annotations and avoids common issues like holes or fragments in other models' segmentations.
An Unsupervised Framework for Joint MRI Super Resolution and Gibbs Artifact Removal
Feb 06, 2023The k-space data generated from magnetic resonance imaging (MRI) is only a finite sampling of underlying signals. Therefore, MRI images often suffer from low spatial resolution and Gibbs ringing artifacts. Previous studies tackled these two problems separately, where super resolution methods tend to enhance Gibbs artifacts, whereas Gibbs ringing removal methods tend to blur the images. It is also a challenge that high resolution ground truth is hard to obtain in clinical MRI. In this paper, we propose an unsupervised learning framework for both MRI super resolution and Gibbs artifacts removal without using high resolution ground truth. Furthermore, we propose regularization methods to improve the model's generalizability across out-of-distribution MRI images. We evaluated our proposed methods with other state-of-the-art methods on eight MRI datasets with various contrasts and anatomical structures. Our method not only achieves the best SR performance but also significantly reduces the Gibbs artifacts. Our method also demonstrates good generalizability across different datasets, which is beneficial to clinical applications where training data are usually scarce and biased.
Dynamic MLP for MRI Reconstruction
Jan 21, 2023As convolutional neural networks (CNN) become the most successful reconstruction technique for accelerated Magnetic Resonance Imaging (MRI), CNN reaches its limit on image quality especially in sharpness. Further improvement on image quality often comes at massive computational costs, hindering their practicability in the clinic setting. MRI reconstruction is essentially a deconvolution problem, which demands long-distance information that is difficult to be captured by CNNs with small convolution kernels. The multi-layer perceptron (MLP) is able to model such long-distance information, but it restricts a fixed input size while the reconstruction of images in flexible resolutions is required in the clinic setting. In this paper, we proposed a hybrid CNN and MLP reconstruction strategy, featured by dynamic MLP (dMLP) that accepts arbitrary image sizes. Experiments were conducted using 3D multi-coil MRI. Our results suggested the proposed dMLP can improve image sharpness compared to its pure CNN counterpart, while costing minor additional GPU memory and computation time. We further compared the proposed dMLP with CNNs using large kernels and studied pure MLP-based reconstruction using a stack of 1D dMLPs, as well as its CNN counterpart using only 1D convolutions. We observed the enlarged receptive field has noticeably improved image quality, while simply using CNN with a large kernel leads to difficulties in training. Noticeably, the pure MLP-based method has been outperformed by CNN-involved methods, which matches the observations in other computer vision tasks for natural images.
Holistic Multi-Slice Framework for Dynamic Simultaneous Multi-Slice MRI Reconstruction
Jan 03, 2023Dynamic Magnetic Resonance Imaging (dMRI) is widely used to assess various cardiac conditions such as cardiac motion and blood flow. To accelerate MR acquisition, techniques such as undersampling and Simultaneous Multi-Slice (SMS) are often used. Special reconstruction algorithms are needed to reconstruct multiple SMS image slices from the entangled information. Deep learning (DL)-based methods have shown promising results for single-slice MR reconstruction, but the addition of SMS acceleration raises unique challenges due to the composite k-space signals and the resulting images with strong inter-slice artifacts. Furthermore, many dMRI applications lack sufficient data for training reconstruction neural networks. In this study, we propose a novel DL-based framework for dynamic SMS reconstruction. Our main contributions are 1) a combination of data transformation steps and network design that effectively leverages the unique characteristics of undersampled dynamic SMS data, and 2) an MR physics-guided transfer learning strategy that addresses the data scarcity issue. Thorough comparisons with multiple baseline methods illustrate the strengths of our proposed methods.
JoJoNet: Joint-contrast and Joint-sampling-and-reconstruction Network for Multi-contrast MRI
Oct 27, 2022Multi-contrast Magnetic Resonance Imaging (MRI) generates multiple medical images with rich and complementary information for routine clinical use; however, it suffers from a long acquisition time. Recent works for accelerating MRI, mainly designed for single contrast, may not be optimal for multi-contrast scenario since the inherent correlations among the multi-contrast images are not exploited. In addition, independent reconstruction of each contrast usually does not translate to optimal performance of downstream tasks. Motivated by these aspects, in this paper we design an end-to-end framework for accelerating multi-contrast MRI which simultaneously optimizes the entire MR imaging workflow including sampling, reconstruction and downstream tasks to achieve the best overall outcomes. The proposed framework consists of a sampling mask generator for each image contrast and a reconstructor exploiting the inter-contrast correlations with a recurrent structure which enables the information sharing in a holistic way. The sampling mask generator and the reconstructor are trained jointly across the multiple image contrasts. The acceleration ratio of each image contrast is also learnable and can be driven by a downstream task performance. We validate our approach on a multi-contrast brain dataset and a multi-contrast knee dataset. Experiments show that (1) our framework consistently outperforms the baselines designed for single contrast on both datasets; (2) our newly designed recurrent reconstruction network effectively improves the reconstruction quality for multi-contrast images; (3) the learnable acceleration ratio improves the downstream task performance significantly. Overall, this work has potentials to open up new avenues for optimizing the entire multi-contrast MR imaging workflow.
Robust Landmark-based Stent Tracking in X-ray Fluoroscopy
Jul 22, 2022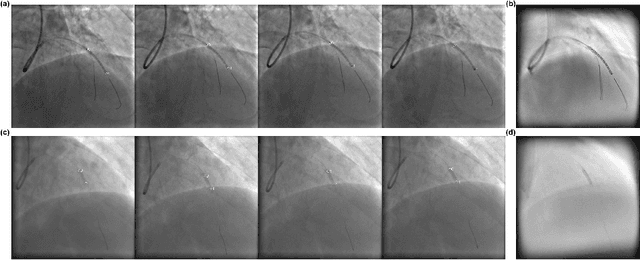
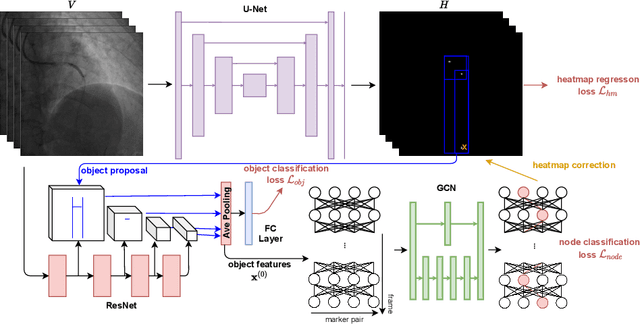
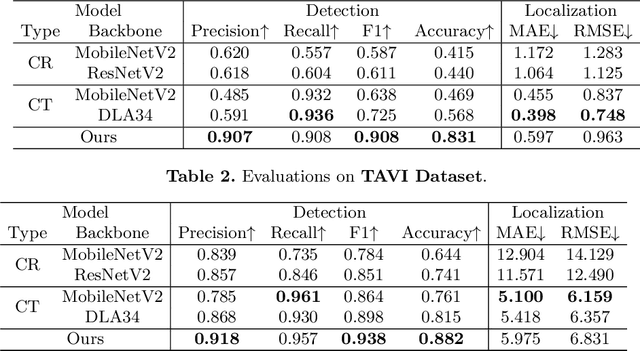
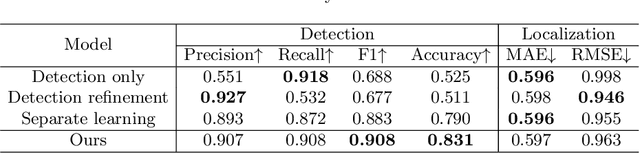
In clinical procedures of angioplasty (i.e., open clogged coronary arteries), devices such as balloons and stents need to be placed and expanded in arteries under the guidance of X-ray fluoroscopy. Due to the limitation of X-ray dose, the resulting images are often noisy. To check the correct placement of these devices, typically multiple motion-compensated frames are averaged to enhance the view. Therefore, device tracking is a necessary procedure for this purpose. Even though angioplasty devices are designed to have radiopaque markers for the ease of tracking, current methods struggle to deliver satisfactory results due to the small marker size and complex scenes in angioplasty. In this paper, we propose an end-to-end deep learning framework for single stent tracking, which consists of three hierarchical modules: U-Net based landmark detection, ResNet based stent proposal and feature extraction, and graph convolutional neural network (GCN) based stent tracking that temporally aggregates both spatial information and appearance features. The experiments show that our method performs significantly better in detection compared with the state-of-the-art point-based tracking models. In addition, its fast inference speed satisfies clinical requirements.
Deep Statistic Shape Model for Myocardium Segmentation
Jul 21, 2022
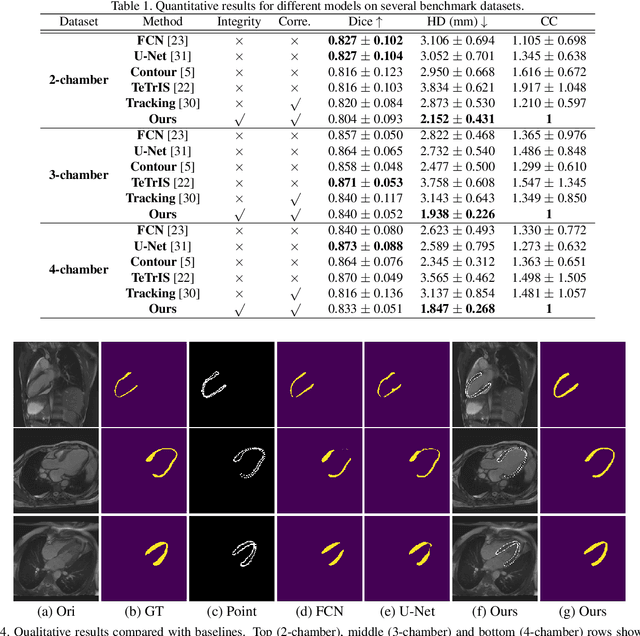
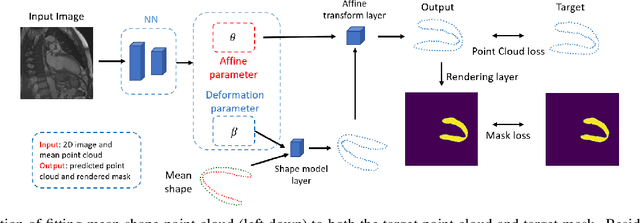
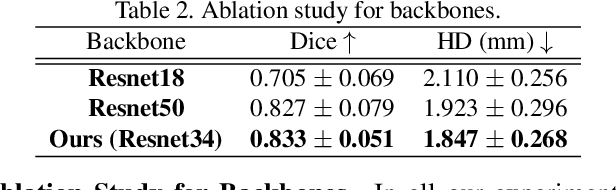
Accurate segmentation and motion estimation of myocardium have always been important in clinic field, which essentially contribute to the downstream diagnosis. However, existing methods cannot always guarantee the shape integrity for myocardium segmentation. In addition, motion estimation requires point correspondence on the myocardium region across different frames. In this paper, we propose a novel end-to-end deep statistic shape model to focus on myocardium segmentation with both shape integrity and boundary correspondence preserving. Specifically, myocardium shapes are represented by a fixed number of points, whose variations are extracted by Principal Component Analysis (PCA). Deep neural network is used to predict the transformation parameters (both affine and deformation), which are then used to warp the mean point cloud to the image domain. Furthermore, a differentiable rendering layer is introduced to incorporate mask supervision into the framework to learn more accurate point clouds. In this way, the proposed method is able to consistently produce anatomically reasonable segmentation mask without post processing. Additionally, the predicted point cloud guarantees boundary correspondence for sequential images, which contributes to the downstream tasks, such as the motion estimation of myocardium. We conduct several experiments to demonstrate the effectiveness of the proposed method on several benchmark datasets.
Flow-based Visual Quality Enhancer for Super-resolution Magnetic Resonance Spectroscopic Imaging
Jul 20, 2022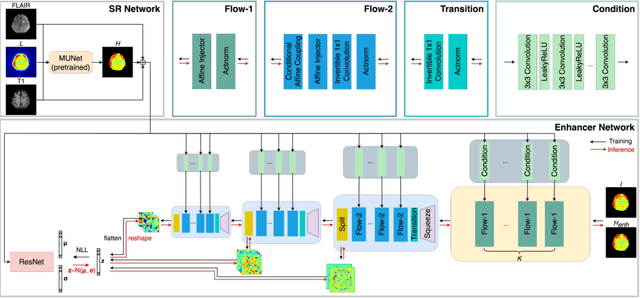
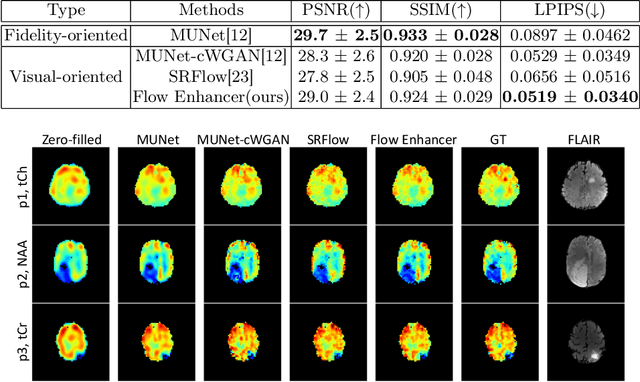
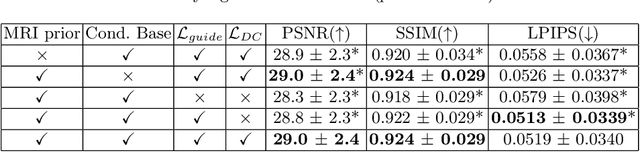
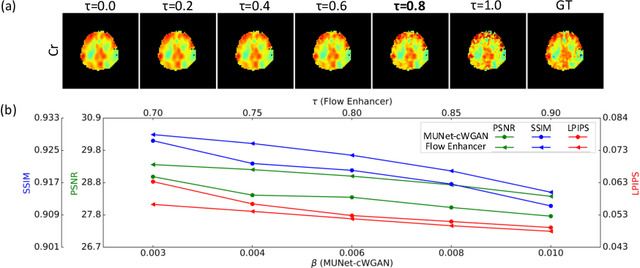
Magnetic Resonance Spectroscopic Imaging (MRSI) is an essential tool for quantifying metabolites in the body, but the low spatial resolution limits its clinical applications. Deep learning-based super-resolution methods provided promising results for improving the spatial resolution of MRSI, but the super-resolved images are often blurry compared to the experimentally-acquired high-resolution images. Attempts have been made with the generative adversarial networks to improve the image visual quality. In this work, we consider another type of generative model, the flow-based model, of which the training is more stable and interpretable compared to the adversarial networks. Specifically, we propose a flow-based enhancer network to improve the visual quality of super-resolution MRSI. Different from previous flow-based models, our enhancer network incorporates anatomical information from additional image modalities (MRI) and uses a learnable base distribution. In addition, we impose a guide loss and a data-consistency loss to encourage the network to generate images with high visual quality while maintaining high fidelity. Experiments on a 1H-MRSI dataset acquired from 25 high-grade glioma patients indicate that our enhancer network outperforms the adversarial networks and the baseline flow-based methods. Our method also allows visual quality adjustment and uncertainty estimation.
Invertible Sharpening Network for MRI Reconstruction Enhancement
Jun 06, 2022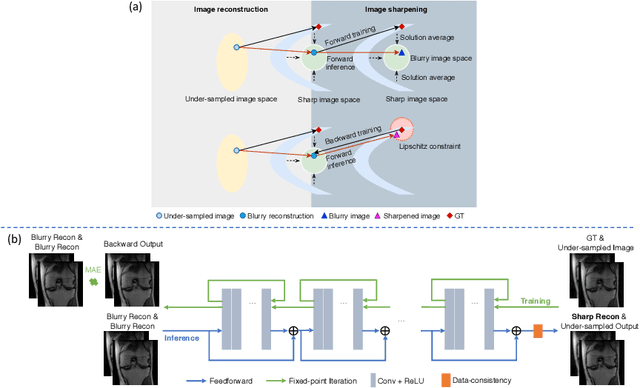

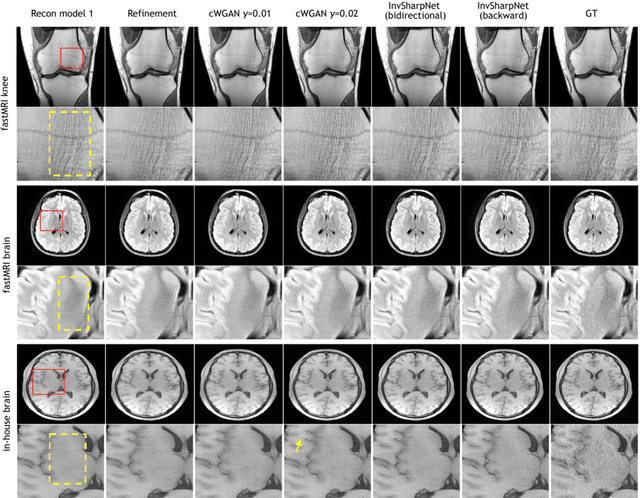

High-quality MRI reconstruction plays a critical role in clinical applications. Deep learning-based methods have achieved promising results on MRI reconstruction. However, most state-of-the-art methods were designed to optimize the evaluation metrics commonly used for natural images, such as PSNR and SSIM, whereas the visual quality is not primarily pursued. Compared to the fully-sampled images, the reconstructed images are often blurry, where high-frequency features might not be sharp enough for confident clinical diagnosis. To this end, we propose an invertible sharpening network (InvSharpNet) to improve the visual quality of MRI reconstructions. During training, unlike the traditional methods that learn to map the input data to the ground truth, InvSharpNet adapts a backward training strategy that learns a blurring transform from the ground truth (fully-sampled image) to the input data (blurry reconstruction). During inference, the learned blurring transform can be inverted to a sharpening transform leveraging the network's invertibility. The experiments on various MRI datasets demonstrate that InvSharpNet can improve reconstruction sharpness with few artifacts. The results were also evaluated by radiologists, indicating better visual quality and diagnostic confidence of our proposed method.
Multi-scale Neural ODEs for 3D Medical Image Registration
Jun 17, 2021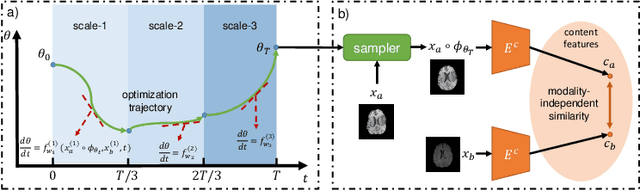
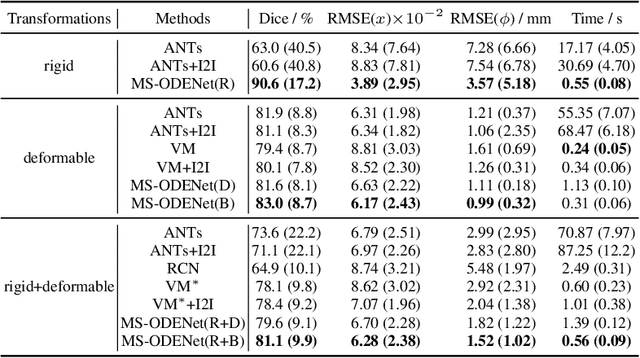
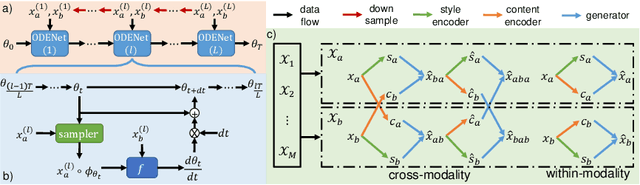
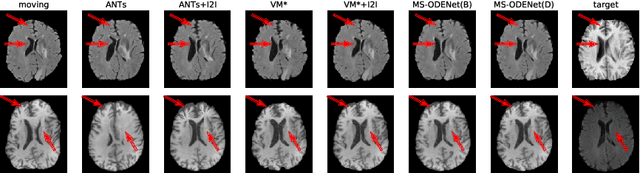
Image registration plays an important role in medical image analysis. Conventional optimization based methods provide an accurate estimation due to the iterative process at the cost of expensive computation. Deep learning methods such as learn-to-map are much faster but either iterative or coarse-to-fine approach is required to improve accuracy for handling large motions. In this work, we proposed to learn a registration optimizer via a multi-scale neural ODE model. The inference consists of iterative gradient updates similar to a conventional gradient descent optimizer but in a much faster way, because the neural ODE learns from the training data to adapt the gradient efficiently at each iteration. Furthermore, we proposed to learn a modal-independent similarity metric to address image appearance variations across different image contrasts. We performed evaluations through extensive experiments in the context of multi-contrast 3D MR images from both public and private data sources and demonstrate the superior performance of our proposed methods.