 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBigFinanceBench: A Workflow-Grounded Benchmark for Financial-Research Agents
Jun 02, 2026Financial-research answers are decision-relevant only when another analyst can audit how they were produced: which source was chosen, which period and accounting definition were used, which assumptions were made, and how the calculation was performed. Existing finance benchmarks largely evaluate isolated subskills or final answers, leaving the auditable derivation itself under-measured. We introduce BigFinanceBench, a 928-item expert-authored benchmark of open-ended financial-research tasks in which each item pairs a ground-truth reference answer with a point-weighted rubric that decomposes the derivation into independently checkable steps. BigFinanceBench is workflow-grounded in that it evaluates the full derivation rather than only the final output. Across 36,241 rubric points, the benchmark supports partial-credit evaluation and localization of failures across the analyst workflow. Evaluating ten current frontier and open-weight agents, we find substantial headroom: the best system reaches only 58.8% rubric score, final-answer accuracy is a useful but lossy proxy for derivation quality, and model capability varies non-uniformly across financial workflows.
As X, Do Y: How Persona and Task Combine in Instruction-Tuned LLMs
May 22, 2026Role prompts of the form As X, do Y admit a clean linear decomposition at one specific site in the residual stream: the prompt-to-answer transition -- the last prompt token together with the first two generated tokens -- in an early/mid layer band. There, persona and task contribute through partially orthogonal additive directions. Forming a pure persona effect $Δ_X$, a pure task effect $Δ_Y$, and substituting $h_{BB} + Δ_X + Δ_Y$ for the clean residual yields downstream output within a small KL of clean on Gemma-2-2B-IT and Qwen-2.5-\{1.5B, 3B\}-Instruct, across a 12-cell short grid and a 48-cell long-persona grid, with persona-specific behavioral markers preserved. The natural inference from this additive structure is that the role prompt can be compressed into a single cached residual vector. \emph{We show it cannot.} Injecting the cached additive prediction -- or even the oracle clean residual $h_{XY}$ -- into a baseline host prompt with the persona text removed does not approach the clean long-persona target, at one site or at many layers. Persona-conditioned multi-token generation flows through attention back to the persona-text positions throughout the prompt, which no residual at one site reproduces. Local additivity in the residual stream does not imply prompt compressibility. The additive structure at the prompt-to-answer transition supports interpretability and fine-grained steering of persona or task contributions; persona-conditioned behavior across the full continuation depends on a distributed prompt/KV mechanism that local activation arithmetic does not displace.
Towards Anytime-Valid Statistical Watermarking
Feb 19, 2026The proliferation of Large Language Models (LLMs) necessitates efficient mechanisms to distinguish machine-generated content from human text. While statistical watermarking has emerged as a promising solution, existing methods suffer from two critical limitations: the lack of a principled approach for selecting sampling distributions and the reliance on fixed-horizon hypothesis testing, which precludes valid early stopping. In this paper, we bridge this gap by developing the first e-value-based watermarking framework, Anchored E-Watermarking, that unifies optimal sampling with anytime-valid inference. Unlike traditional approaches where optional stopping invalidates Type-I error guarantees, our framework enables valid, anytime-inference by constructing a test supermartingale for the detection process. By leveraging an anchor distribution to approximate the target model, we characterize the optimal e-value with respect to the worst-case log-growth rate and derive the optimal expected stopping time. Our theoretical claims are substantiated by simulations and evaluations on established benchmarks, showing that our framework can significantly enhance sample efficiency, reducing the average token budget required for detection by 13-15% relative to state-of-the-art baselines.
SimCE: Simplifying Cross-Entropy Loss for Collaborative Filtering
Jun 23, 2024



The learning objective is integral to collaborative filtering systems, where the Bayesian Personalized Ranking (BPR) loss is widely used for learning informative backbones. However, BPR often experiences slow convergence and suboptimal local optima, partially because it only considers one negative item for each positive item, neglecting the potential impacts of other unobserved items. To address this issue, the recently proposed Sampled Softmax Cross-Entropy (SSM) compares one positive sample with multiple negative samples, leading to better performance. Our comprehensive experiments confirm that recommender systems consistently benefit from multiple negative samples during training. Furthermore, we introduce a \underline{Sim}plified Sampled Softmax \underline{C}ross-\underline{E}ntropy Loss (SimCE), which simplifies the SSM using its upper bound. Our validation on 12 benchmark datasets, using both MF and LightGCN backbones, shows that SimCE significantly outperforms both BPR and SSM.
Differentially private $k$-means clustering via exponential mechanism and max cover
Sep 02, 2020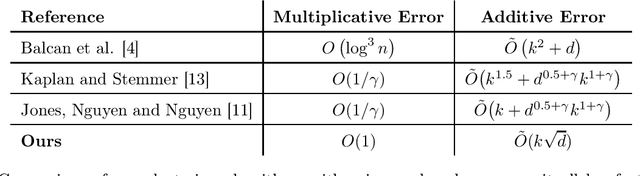
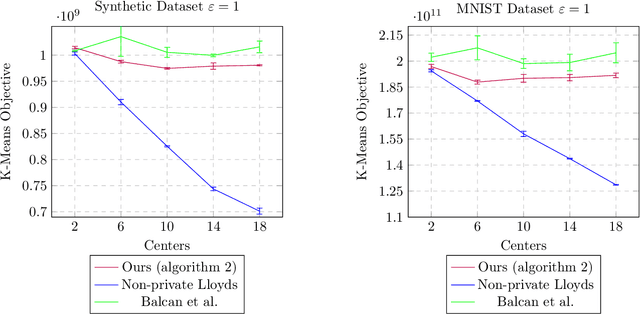
We introduce a new $(\epsilon_p, \delta_p)$-differentially private algorithm for the $k$-means clustering problem. Given a dataset in Euclidean space, the $k$-means clustering problem requires one to find $k$ points in that space such that the sum of squares of Euclidean distances between each data point and its closest respective point among the $k$ returned is minimised. Although there exist privacy-preserving methods with good theoretical guarantees to solve this problem [Balcan et al., 2017; Kaplan and Stemmer, 2018], in practice it is seen that it is the additive error which dictates the practical performance of these methods. By reducing the problem to a sequence of instances of maximum coverage on a grid, we are able to derive a new method that achieves lower additive error then previous works. For input datasets with cardinality $n$ and diameter $\Delta$, our algorithm has an $O(\Delta^2 (k \log^2 n \log(1/\delta_p)/\epsilon_p + k\sqrt{d \log(1/\delta_p)}/\epsilon_p))$ additive error whilst maintaining constant multiplicative error. We conclude with some experiments and find an improvement over previously implemented work for this problem.