 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXTTS: a Massively Multilingual Zero-Shot Text-to-Speech Model
Jun 07, 2024Most Zero-shot Multi-speaker TTS (ZS-TTS) systems support only a single language. Although models like YourTTS, VALL-E X, Mega-TTS 2, and Voicebox explored Multilingual ZS-TTS they are limited to just a few high/medium resource languages, limiting the applications of these models in most of the low/medium resource languages. In this paper, we aim to alleviate this issue by proposing and making publicly available the XTTS system. Our method builds upon the Tortoise model and adds several novel modifications to enable multilingual training, improve voice cloning, and enable faster training and inference. XTTS was trained in 16 languages and achieved state-of-the-art (SOTA) results in most of them.
MLAAD: The Multi-Language Audio Anti-Spoofing Dataset
Jan 17, 2024



Text-to-Speech (TTS) technology brings significant advantages, such as giving a voice to those with speech impairments, but also enables audio deepfakes and spoofs. The former mislead individuals and may propagate misinformation, while the latter undermine voice biometric security systems. AI-based detection can help to address these challenges by automatically differentiating between genuine and fabricated voice recordings. However, these models are only as good as their training data, which currently is severely limited due to an overwhelming concentration on English and Chinese audio in anti-spoofing databases, thus restricting its worldwide effectiveness. In response, this paper presents the Multi-Language Audio Anti-Spoof Dataset (MLAAD), created using 52 TTS models, comprising 19 different architectures, to generate 160.1 hours of synthetic voice in 23 different languages. We train and evaluate three state-of-the-art deepfake detection models with MLAAD, and observe that MLAAD demonstrates superior performance over comparable datasets like InTheWild or FakeOrReal when used as a training resource. Furthermore, in comparison with the renowned ASVspoof 2019 dataset, MLAAD proves to be a complementary resource. In tests across eight datasets, MLAAD and ASVspoof 2019 alternately outperformed each other, both excelling on four datasets. By publishing MLAAD and making trained models accessible via an interactive webserver , we aim to democratize antispoofing technology, making it accessible beyond the realm of specialists, thus contributing to global efforts against audio spoofing and deepfakes.
YourTTS: Towards Zero-Shot Multi-Speaker TTS and Zero-Shot Voice Conversion for everyone
Dec 04, 2021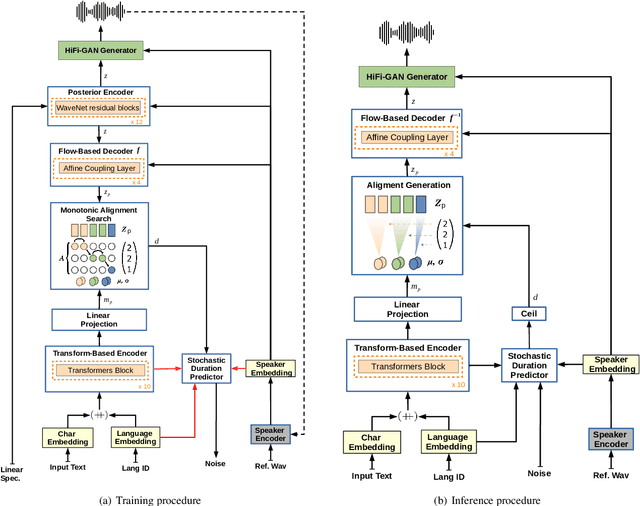
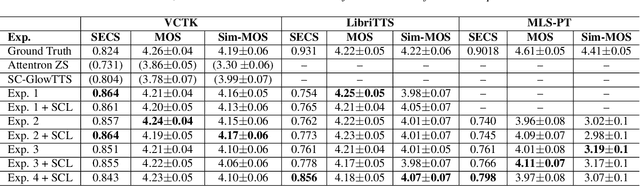

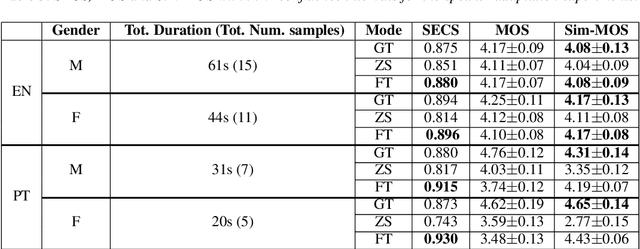
YourTTS brings the power of a multilingual approach to the task of zero-shot multi-speaker TTS. Our method builds upon the VITS model and adds several novel modifications for zero-shot multi-speaker and multilingual training. We achieved state-of-the-art (SOTA) results in zero-shot multi-speaker TTS and results comparable to SOTA in zero-shot voice conversion on the VCTK dataset. Additionally, our approach achieves promising results in a target language with a single-speaker dataset, opening possibilities for zero-shot multi-speaker TTS and zero-shot voice conversion systems in low-resource languages. Finally, it is possible to fine-tune the YourTTS model with less than 1 minute of speech and achieve state-of-the-art results in voice similarity and with reasonable quality. This is important to allow synthesis for speakers with a very different voice or recording characteristics from those seen during training.
SC-GlowTTS: an Efficient Zero-Shot Multi-Speaker Text-To-Speech Model
Apr 02, 2021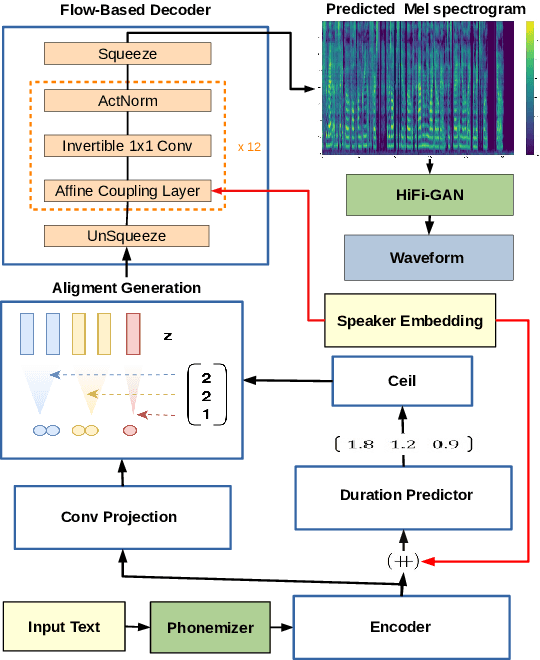
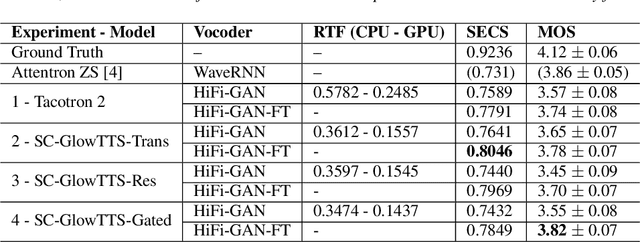
In this paper, we propose SC-GlowTTS: an efficient zero-shot multi-speaker text-to-speech model that improves similarity for speakers unseen in training. We propose a speaker-conditional architecture that explores a flow-based decoder that works in a zero-shot scenario. As text encoders, we explore a dilated residual convolutional-based encoder, gated convolutional-based encoder, and transformer-based encoder. Additionally, we have shown that adjusting a GAN-based vocoder for the spectrograms predicted by the TTS model on the training dataset can significantly improve the similarity and speech quality for new speakers. Our model is able to converge in training, using only 11 speakers, reaching state-of-the-art results for similarity with new speakers, as well as high speech quality.