 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA single speaker is almost all you need for automatic speech recognition
Mar 29, 2022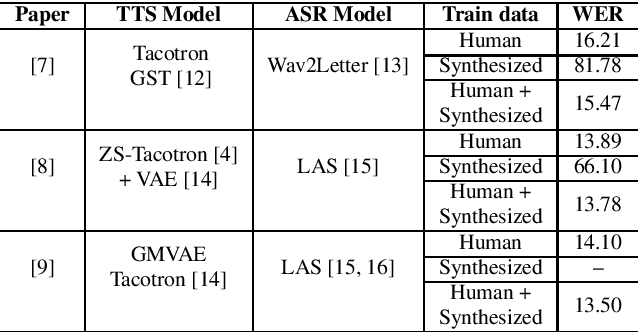
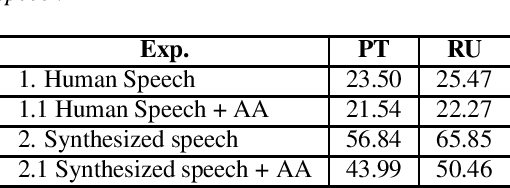

We explore the use of speech synthesis and voice conversion applied to augment datasets for automatic speech recognition (ASR) systems, in scenarios with only one speaker available for the target language. Through extensive experiments, we show that our approach achieves results compared to the state-of-the-art (SOTA) and requires only one speaker in the target language during speech synthesis/voice conversion model training. Finally, we show that it is possible to obtain promising results in the training of an ASR model with our data augmentation method and only a single real speaker in different target languages.
YourTTS: Towards Zero-Shot Multi-Speaker TTS and Zero-Shot Voice Conversion for everyone
Dec 04, 2021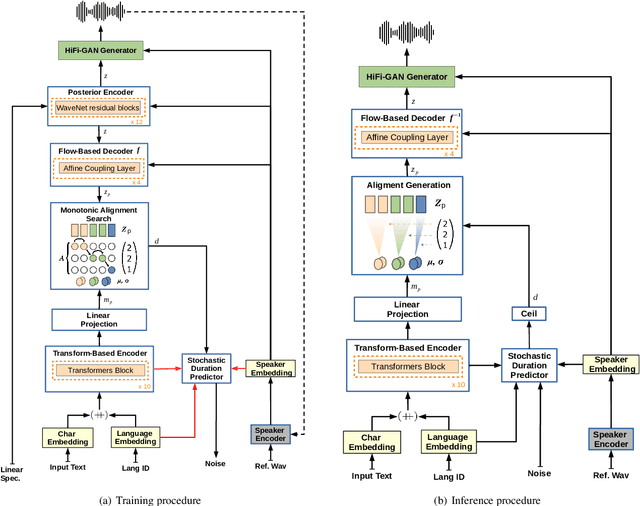
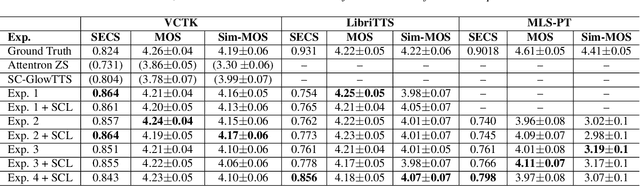

YourTTS brings the power of a multilingual approach to the task of zero-shot multi-speaker TTS. Our method builds upon the VITS model and adds several novel modifications for zero-shot multi-speaker and multilingual training. We achieved state-of-the-art (SOTA) results in zero-shot multi-speaker TTS and results comparable to SOTA in zero-shot voice conversion on the VCTK dataset. Additionally, our approach achieves promising results in a target language with a single-speaker dataset, opening possibilities for zero-shot multi-speaker TTS and zero-shot voice conversion systems in low-resource languages. Finally, it is possible to fine-tune the YourTTS model with less than 1 minute of speech and achieve state-of-the-art results in voice similarity and with reasonable quality. This is important to allow synthesis for speakers with a very different voice or recording characteristics from those seen during training.
SC-GlowTTS: an Efficient Zero-Shot Multi-Speaker Text-To-Speech Model
Apr 02, 2021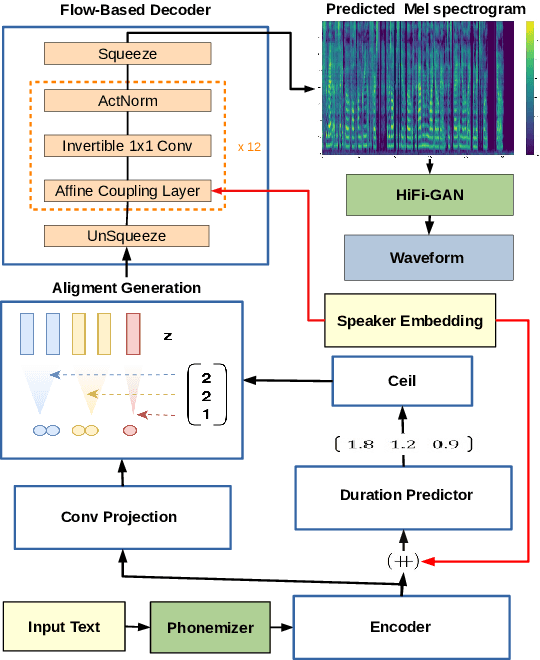
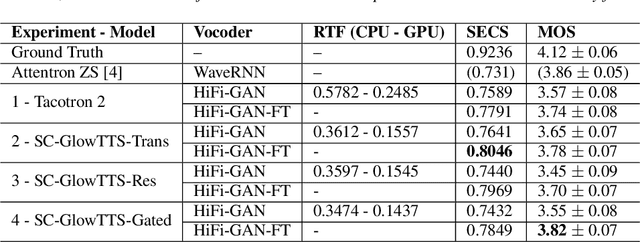
In this paper, we propose SC-GlowTTS: an efficient zero-shot multi-speaker text-to-speech model that improves similarity for speakers unseen in training. We propose a speaker-conditional architecture that explores a flow-based decoder that works in a zero-shot scenario. As text encoders, we explore a dilated residual convolutional-based encoder, gated convolutional-based encoder, and transformer-based encoder. Additionally, we have shown that adjusting a GAN-based vocoder for the spectrograms predicted by the TTS model on the training dataset can significantly improve the similarity and speech quality for new speakers. Our model is able to converge in training, using only 11 speakers, reaching state-of-the-art results for similarity with new speakers, as well as high speech quality.
End-To-End Speech Synthesis Applied to Brazilian Portuguese
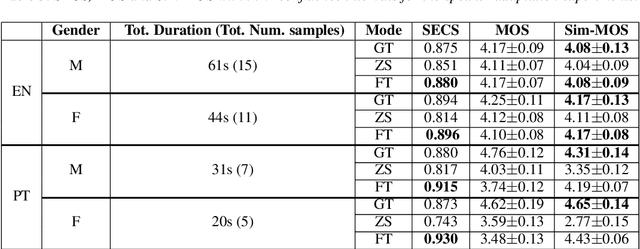
May 11, 2020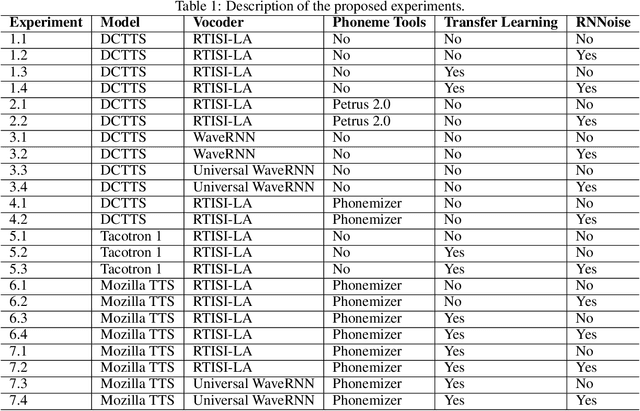
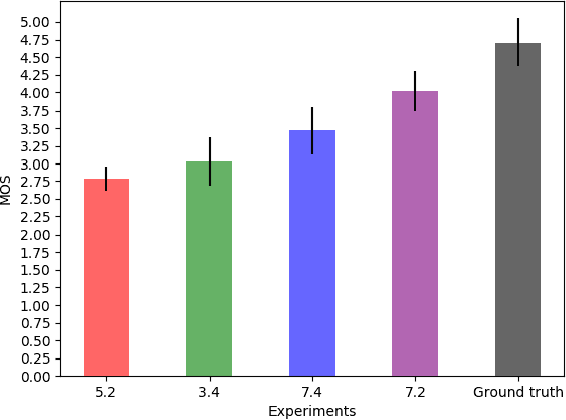

Voice synthesis systems are popular in different applications, such as personal assistants, GPS applications, screen readers and accessibility tools. Voice provides an natural way for human-computer interaction. However, not all languages are in the same level when accounting resources and systems for voice synthesis. This work consists of the creation of publicly available resources for the Brazilian Portuguese language in the form of a dataset and deep learning models for end-to-end voice synthesis. The dataset has 10.5 hours from a single speaker. We investigated three different architectures to perform end-to-end speech synthesis: Tacotron 1, DCTTS and Mozilla TTS. We also analysed the performance of models according to different vocoders (RTISI-LA, WaveRNN and Universal WaveRNN), phonetic transcriptions usage, transfer learning (from English) and denoising. In the proposed scenario, a model based on Mozilla TTS and RTISI-LA vocoder presented the best performance, achieving a 4.03 MOS value. We also verified that transfer learning, phonetic transcriptions and denoising are useful to train the models over the presented dataset. The obtained results are comparable to related works covering English, even using a smaller dataset.
Speech2Phone: A Multilingual and Text Independent Speaker Identification Model
Feb 25, 2020
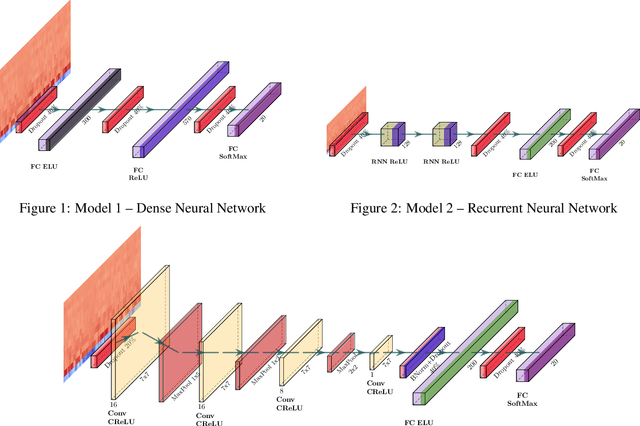
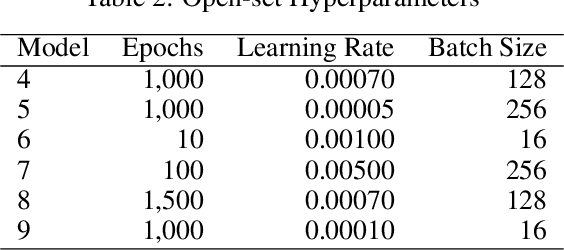
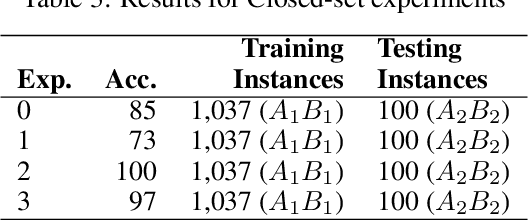
Voice recognition is an area with a wide application potential. Speaker identification is useful in several voice recognition tasks, as seen in voice-based authentication, transcription systems and intelligent personal assistants. Some tasks benefit from open-set models which can handle new speakers without the need of retraining. Audio embeddings for speaker identification is a proposal to solve this issue. However, choosing a suitable model is a difficult task, especially when the training resources are scarce. Besides, it is not always clear whether embeddings are as good as more traditional methods. In this work, we propose the Speech2Phone and compare several embedding models for open-set speaker identification, as well as traditional closed-set models. The models were investigated in the scenario of small datasets, which makes them more applicable to languages in which data scarceness is an issue. The results show that embeddings generated by artificial neural networks are competitive when compared to classical approaches for the task. Considering a testing dataset composed of 20 speakers, the best models reach accuracies of 100% and 76.96% for closed an open set scenarios, respectively. Results suggest that the models can perform language independent speaker identification. Among the tested models, a fully connected one, here presented as Speech2Phone, led to the higher accuracy. Furthermore, the models were tested for different languages showing that the knowledge learned was successfully transferred for close and distant languages to Portuguese (in terms of vocabulary). Finally, the models can scale and can handle more speakers than they were trained for, identifying 150% more speakers while still maintaining 55% accuracy.
Portuguese Word Embeddings: Evaluating on Word Analogies and Natural Language Tasks
Aug 20, 2017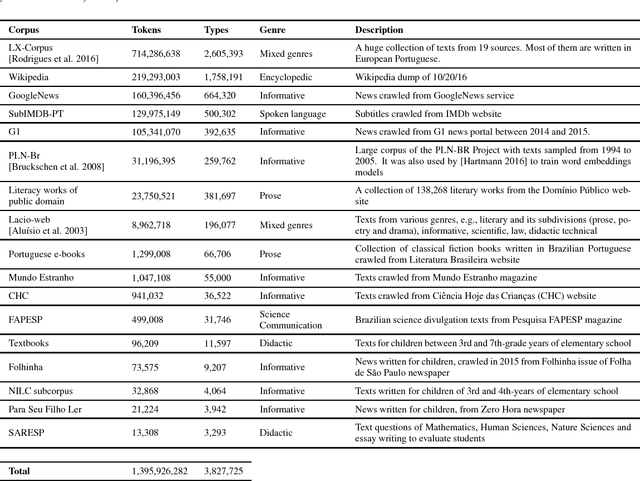
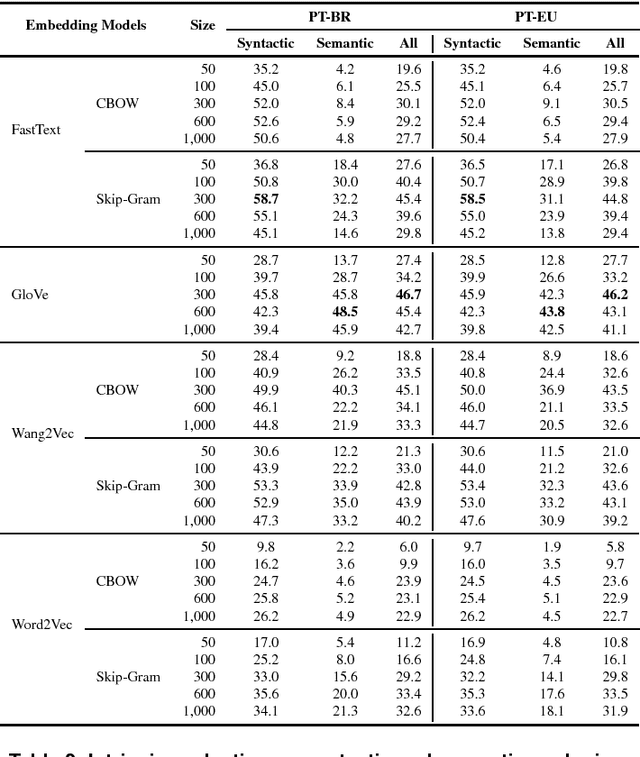
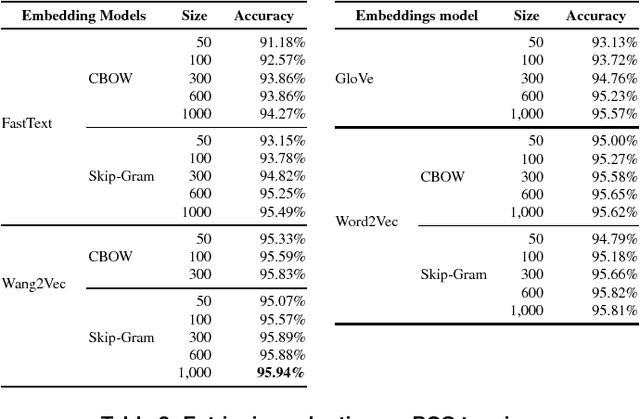
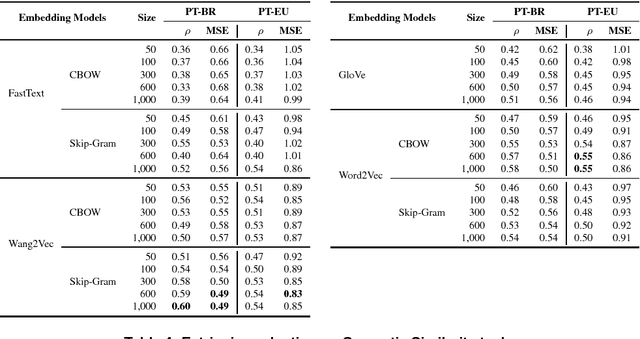
Word embeddings have been found to provide meaningful representations for words in an efficient way; therefore, they have become common in Natural Language Processing sys- tems. In this paper, we evaluated different word embedding models trained on a large Portuguese corpus, including both Brazilian and European variants. We trained 31 word embedding models using FastText, GloVe, Wang2Vec and Word2Vec. We evaluated them intrinsically on syntactic and semantic analogies and extrinsically on POS tagging and sentence semantic similarity tasks. The obtained results suggest that word analogies are not appropriate for word embedding evaluation; task-specific evaluations appear to be a better option.
Sentence Segmentation in Narrative Transcripts from Neuropsychological Tests using Recurrent Convolutional Neural Networks
Aug 15, 2017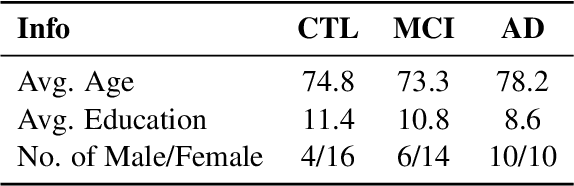
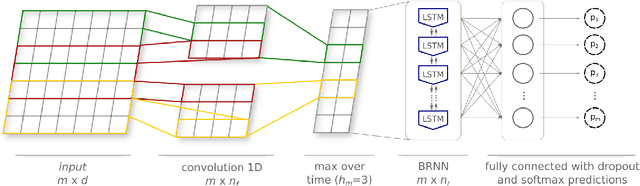
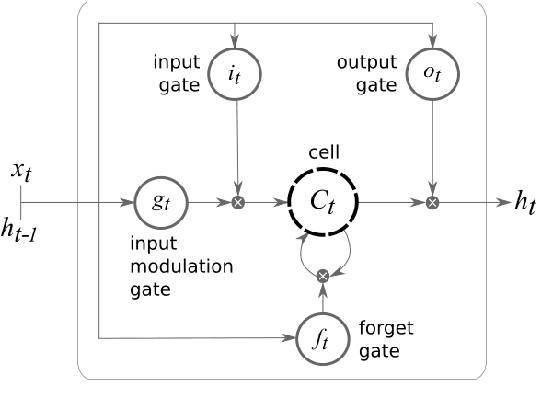
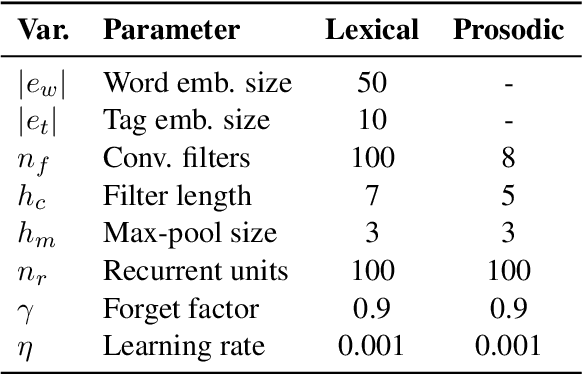
Automated discourse analysis tools based on Natural Language Processing (NLP) aiming at the diagnosis of language-impairing dementias generally extract several textual metrics of narrative transcripts. However, the absence of sentence boundary segmentation in the transcripts prevents the direct application of NLP methods which rely on these marks to function properly, such as taggers and parsers. We present the first steps taken towards automatic neuropsychological evaluation based on narrative discourse analysis, presenting a new automatic sentence segmentation method for impaired speech. Our model uses recurrent convolutional neural networks with prosodic, Part of Speech (PoS) features, and word embeddings. It was evaluated intrinsically on impaired, spontaneous speech, as well as, normal, prepared speech, and presents better results for healthy elderly (CTL) (F1 = 0.74) and Mild Cognitive Impairment (MCI) patients (F1 = 0.70) than the Conditional Random Fields method (F1 = 0.55 and 0.53, respectively) used in the same context of our study. The results suggest that our model is robust for impaired speech and can be used in automated discourse analysis tools to differentiate narratives produced by MCI and CTL.