 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTagarela - A Portuguese speech dataset from podcasts
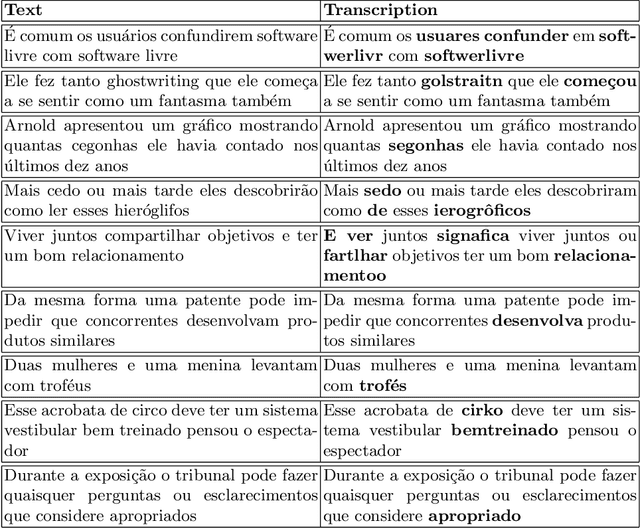
Mar 16, 2026Despite significant advances in speech processing, Portuguese remains under-resourced due to the scarcity of public, large-scale, and high-quality datasets. To address this gap, we present a new dataset, named TAGARELA, composed of over 8,972 hours of podcast audio, specifically curated for training automatic speech recognition (ASR) and text-to-speech (TTS) models. Notably, its scale rivals English's GigaSpeech (10kh), enabling state-of-the-art Portuguese models. To ensure data quality, the corpus was subjected to an audio pre-processing pipeline and subsequently transcribed using a mixed strategy: we applied ASR models that were previously trained on high-fidelity transcriptions generated by proprietary APIs, ensuring a high level of initial accuracy. Finally, to validate the effectiveness of this new resource, we present ASR and TTS models trained exclusively on our dataset and evaluate their performance, demonstrating its potential to drive the development of more robust and natural speech technologies for Portuguese. The dataset is released publicly, available at https://freds0.github.io/TAGARELA/, to foster the development of robust speech technologies.
FreeSVC: Towards Zero-shot Multilingual Singing Voice Conversion
Jan 09, 2025This work presents FreeSVC, a promising multilingual singing voice conversion approach that leverages an enhanced VITS model with Speaker-invariant Clustering (SPIN) for better content representation and the State-of-the-Art (SOTA) speaker encoder ECAPA2. FreeSVC incorporates trainable language embeddings to handle multiple languages and employs an advanced speaker encoder to disentangle speaker characteristics from linguistic content. Designed for zero-shot learning, FreeSVC enables cross-lingual singing voice conversion without extensive language-specific training. We demonstrate that a multilingual content extractor is crucial for optimal cross-language conversion. Our source code and models are publicly available.
No Saved Kaleidosope: an 100% Jitted Neural Network Coding Language with Pythonic Syntax
Sep 17, 2024



We developed a jitted compiler for training Artificial Neural Networks using C++, LLVM and Cuda. It features object-oriented characteristics, strong typing, parallel workers for data pre-processing, pythonic syntax for expressions, PyTorch like model declaration and Automatic Differentiation. We implement the mechanisms of cache and pooling in order to manage VRAM, cuBLAS for high performance matrix multiplication and cuDNN for convolutional layers. Our experiments with Residual Convolutional Neural Networks on ImageNet, we reach similar speed but degraded performance. Also, the GRU network experiments show similar accuracy, but our compiler have degraded speed in that task. However, our compiler demonstrates promising results at the CIFAR-10 benchmark, in which we reach the same performance and about the same speed as PyTorch. We make the code publicly available at: https://github.com/NoSavedDATA/NoSavedKaleidoscope
Deep Learning Brasil at ABSAPT 2022: Portuguese Transformer Ensemble Approaches
Nov 08, 2023



Aspect-based Sentiment Analysis (ABSA) is a task whose objective is to classify the individual sentiment polarity of all entities, called aspects, in a sentence. The task is composed of two subtasks: Aspect Term Extraction (ATE), identify all aspect terms in a sentence; and Sentiment Orientation Extraction (SOE), given a sentence and its aspect terms, the task is to determine the sentiment polarity of each aspect term (positive, negative or neutral). This article presents we present our participation in Aspect-Based Sentiment Analysis in Portuguese (ABSAPT) 2022 at IberLEF 2022. We submitted the best performing systems, achieving new state-of-the-art results on both subtasks.
Yin Yang Convolutional Nets: Image Manifold Extraction by the Analysis of Opposites
Oct 24, 2023



Computer vision in general presented several advances such as training optimizations, new architectures (pure attention, efficient block, vision language models, generative models, among others). This have improved performance in several tasks such as classification, and others. However, the majority of these models focus on modifications that are taking distance from realistic neuroscientific approaches related to the brain. In this work, we adopt a more bio-inspired approach and present the Yin Yang Convolutional Network, an architecture that extracts visual manifold, its blocks are intended to separate analysis of colors and forms at its initial layers, simulating occipital lobe's operations. Our results shows that our architecture provides State-of-the-Art efficiency among low parameter architectures in the dataset CIFAR-10. Our first model reached 93.32\% test accuracy, 0.8\% more than the older SOTA in this category, while having 150k less parameters (726k in total). Our second model uses 52k parameters, losing only 3.86\% test accuracy. We also performed an analysis on ImageNet, where we reached 66.49\% validation accuracy with 1.6M parameters. We make the code publicly available at: https://github.com/NoSavedDATA/YinYang_CNN.
A single speaker is almost all you need for automatic speech recognition
Mar 29, 2022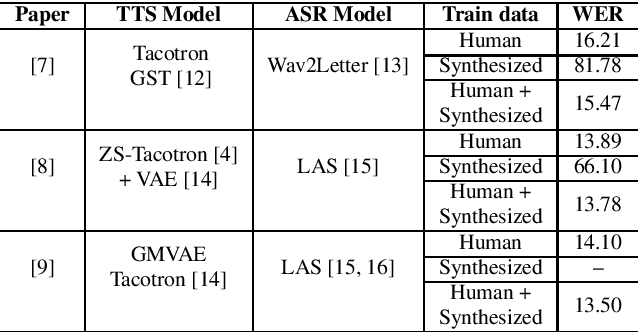
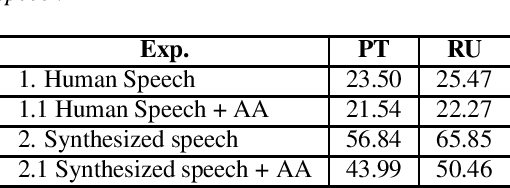

We explore the use of speech synthesis and voice conversion applied to augment datasets for automatic speech recognition (ASR) systems, in scenarios with only one speaker available for the target language. Through extensive experiments, we show that our approach achieves results compared to the state-of-the-art (SOTA) and requires only one speaker in the target language during speech synthesis/voice conversion model training. Finally, we show that it is possible to obtain promising results in the training of an ASR model with our data augmentation method and only a single real speaker in different target languages.
Brazilian Portuguese Speech Recognition Using Wav2vec 2.0
Jul 23, 2021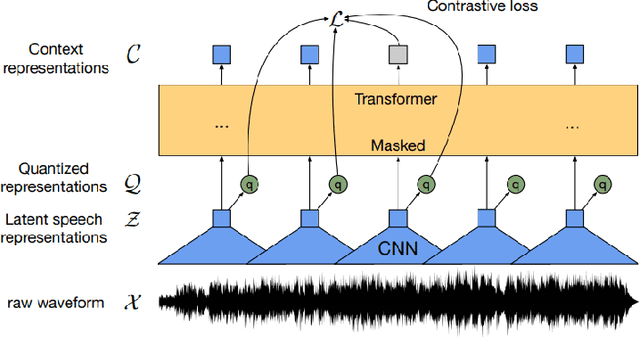

Deep learning techniques have been shown to be efficient in various tasks, especially in the development of speech recognition systems, that is, systems that aim to transcribe a sentence in audio in a sequence of words. Despite the progress in the area, speech recognition can still be considered difficult, especially for languages lacking available data, as Brazilian Portuguese. In this sense, this work presents the development of an public Automatic Speech Recognition system using only open available audio data, from the fine-tuning of the Wav2vec 2.0 XLSR-53 model pre-trained in many languages over Brazilian Portuguese data. The final model presents a Word Error Rate of 11.95% (Common Voice Dataset). This corresponds to 13% less than the best open Automatic Speech Recognition model for Brazilian Portuguese available according to our best knowledge, which is a promising result for the language. In general, this work validates the use of self-supervising learning techniques, in special, the use of the Wav2vec 2.0 architecture in the development of robust systems, even for languages having few available data.
SC-GlowTTS: an Efficient Zero-Shot Multi-Speaker Text-To-Speech Model
Apr 02, 2021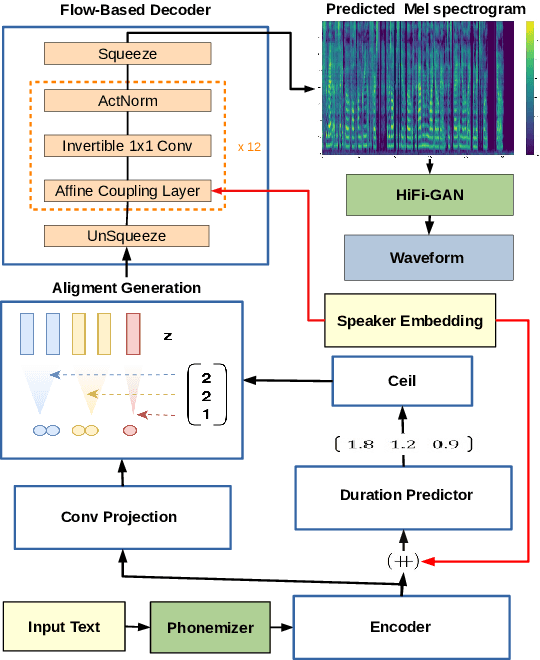
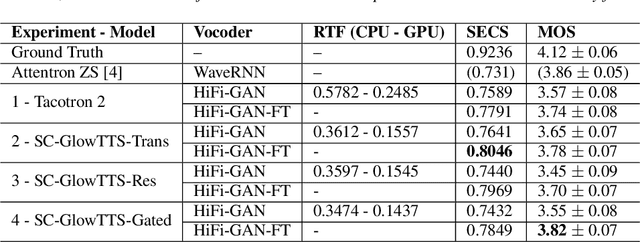
In this paper, we propose SC-GlowTTS: an efficient zero-shot multi-speaker text-to-speech model that improves similarity for speakers unseen in training. We propose a speaker-conditional architecture that explores a flow-based decoder that works in a zero-shot scenario. As text encoders, we explore a dilated residual convolutional-based encoder, gated convolutional-based encoder, and transformer-based encoder. Additionally, we have shown that adjusting a GAN-based vocoder for the spectrograms predicted by the TTS model on the training dataset can significantly improve the similarity and speech quality for new speakers. Our model is able to converge in training, using only 11 speakers, reaching state-of-the-art results for similarity with new speakers, as well as high speech quality.
Deep Learning Brasil -- NLP at SemEval-2020 Task 9: Overview of Sentiment Analysis of Code-Mixed Tweets
Jul 28, 2020

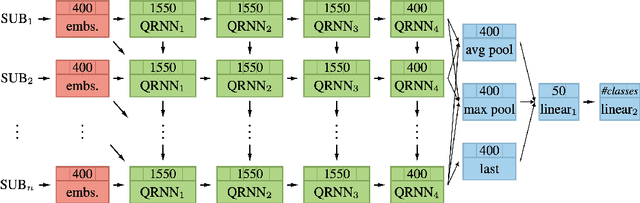
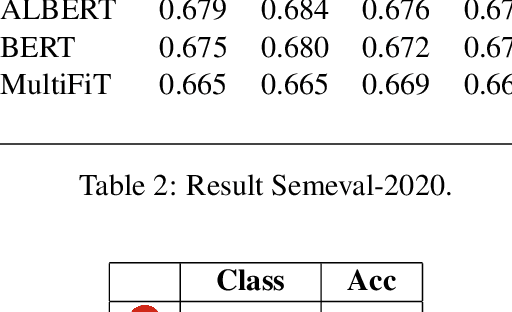
In this paper, we describe a methodology to predict sentiment in code-mixed tweets (hindi-english). Our team called verissimo.manoel in CodaLab developed an approach based on an ensemble of four models (MultiFiT, BERT, ALBERT, and XLNET). The final classification algorithm was an ensemble of some predictions of all softmax values from these four models. This architecture was used and evaluated in the context of the SemEval 2020 challenge (task 9), and our system got 72.7% on the F1 score.