 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSC-GlowTTS: an Efficient Zero-Shot Multi-Speaker Text-To-Speech Model
Apr 02, 2021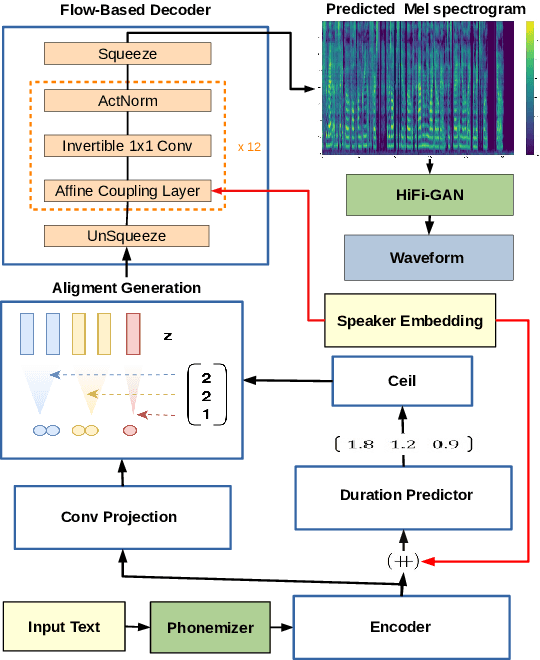
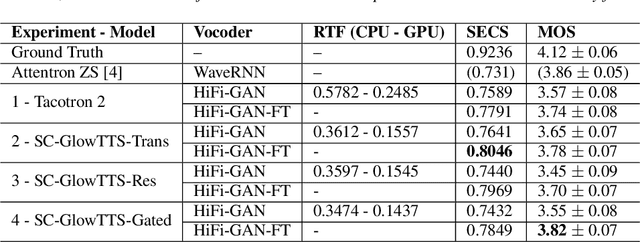
In this paper, we propose SC-GlowTTS: an efficient zero-shot multi-speaker text-to-speech model that improves similarity for speakers unseen in training. We propose a speaker-conditional architecture that explores a flow-based decoder that works in a zero-shot scenario. As text encoders, we explore a dilated residual convolutional-based encoder, gated convolutional-based encoder, and transformer-based encoder. Additionally, we have shown that adjusting a GAN-based vocoder for the spectrograms predicted by the TTS model on the training dataset can significantly improve the similarity and speech quality for new speakers. Our model is able to converge in training, using only 11 speakers, reaching state-of-the-art results for similarity with new speakers, as well as high speech quality.
End-To-End Speech Synthesis Applied to Brazilian Portuguese
May 11, 2020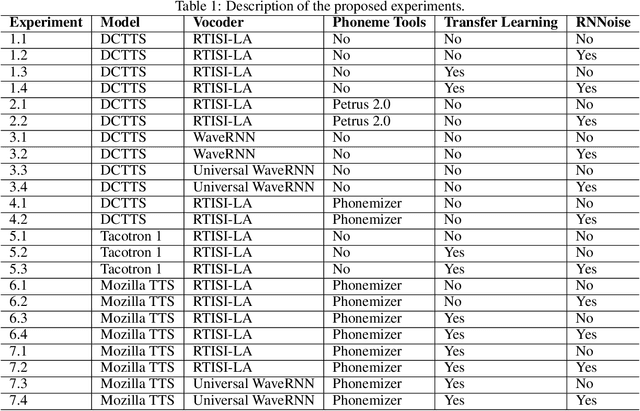
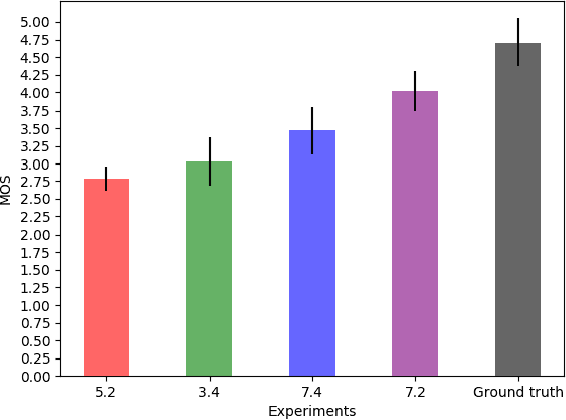

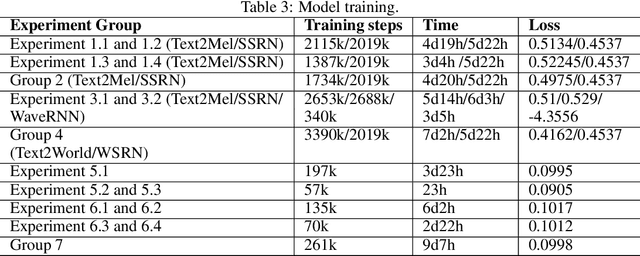
Voice synthesis systems are popular in different applications, such as personal assistants, GPS applications, screen readers and accessibility tools. Voice provides an natural way for human-computer interaction. However, not all languages are in the same level when accounting resources and systems for voice synthesis. This work consists of the creation of publicly available resources for the Brazilian Portuguese language in the form of a dataset and deep learning models for end-to-end voice synthesis. The dataset has 10.5 hours from a single speaker. We investigated three different architectures to perform end-to-end speech synthesis: Tacotron 1, DCTTS and Mozilla TTS. We also analysed the performance of models according to different vocoders (RTISI-LA, WaveRNN and Universal WaveRNN), phonetic transcriptions usage, transfer learning (from English) and denoising. In the proposed scenario, a model based on Mozilla TTS and RTISI-LA vocoder presented the best performance, achieving a 4.03 MOS value. We also verified that transfer learning, phonetic transcriptions and denoising are useful to train the models over the presented dataset. The obtained results are comparable to related works covering English, even using a smaller dataset.
Speech2Phone: A Multilingual and Text Independent Speaker Identification Model
Feb 25, 2020
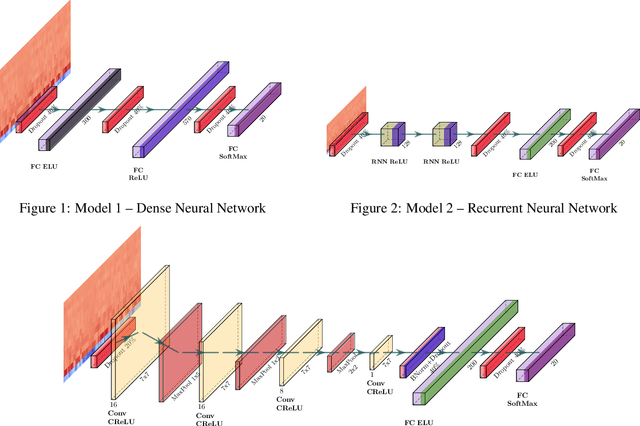
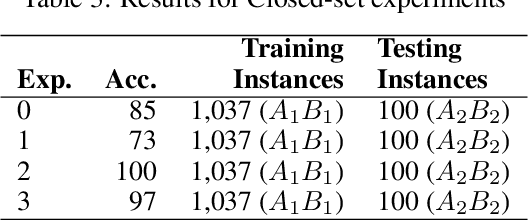
Voice recognition is an area with a wide application potential. Speaker identification is useful in several voice recognition tasks, as seen in voice-based authentication, transcription systems and intelligent personal assistants. Some tasks benefit from open-set models which can handle new speakers without the need of retraining. Audio embeddings for speaker identification is a proposal to solve this issue. However, choosing a suitable model is a difficult task, especially when the training resources are scarce. Besides, it is not always clear whether embeddings are as good as more traditional methods. In this work, we propose the Speech2Phone and compare several embedding models for open-set speaker identification, as well as traditional closed-set models. The models were investigated in the scenario of small datasets, which makes them more applicable to languages in which data scarceness is an issue. The results show that embeddings generated by artificial neural networks are competitive when compared to classical approaches for the task. Considering a testing dataset composed of 20 speakers, the best models reach accuracies of 100% and 76.96% for closed an open set scenarios, respectively. Results suggest that the models can perform language independent speaker identification. Among the tested models, a fully connected one, here presented as Speech2Phone, led to the higher accuracy. Furthermore, the models were tested for different languages showing that the knowledge learned was successfully transferred for close and distant languages to Portuguese (in terms of vocabulary). Finally, the models can scale and can handle more speakers than they were trained for, identifying 150% more speakers while still maintaining 55% accuracy.
Acoustic Modeling Using a Shallow CNN-HTSVM Architecture
Jun 27, 2017
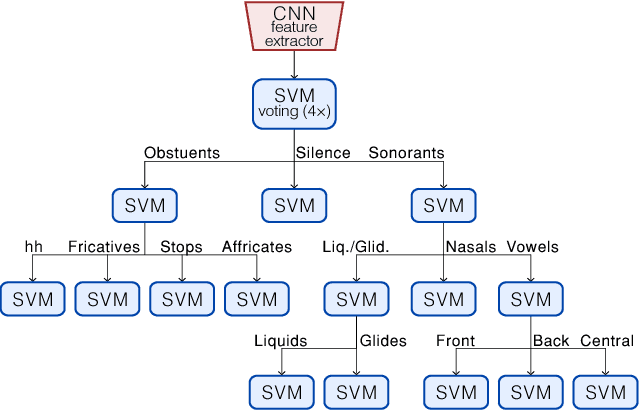
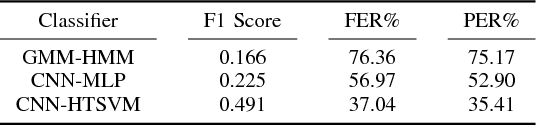
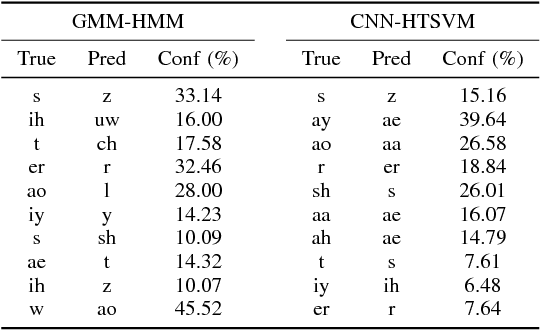
High-accuracy speech recognition is especially challenging when large datasets are not available. It is possible to bridge this gap with careful and knowledge-driven parsing combined with the biologically inspired CNN and the learning guarantees of the Vapnik Chervonenkis (VC) theory. This work presents a Shallow-CNN-HTSVM (Hierarchical Tree Support Vector Machine classifier) architecture which uses a predefined knowledge-based set of rules with statistical machine learning techniques. Here we show that gross errors present even in state-of-the-art systems can be avoided and that an accurate acoustic model can be built in a hierarchical fashion. The CNN-HTSVM acoustic model outperforms traditional GMM-HMM models and the HTSVM structure outperforms a MLP multi-class classifier. More importantly we isolate the performance of the acoustic model and provide results on both the frame and phoneme level considering the true robustness of the model. We show that even with a small amount of data accurate and robust recognition rates can be obtained.