 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini Embedding 2: A Native Multimodal Embedding Model from Gemini
May 26, 2026We introduce Gemini Embedding 2, a native multimodal embedding model that allows embedding video, audio, image, and text modalities in a unified representation space. We leverage the multimodal capabilities of Gemini to produce embeddings for arbitrary combinations of interleaved inputs across all these modalities that generalize well across a wide variety of tasks. Applying large-scale contrastive learning in a multi-task multi-stage training setup, we achieve state-of-the-art performance on key embedding benchmarks including unimodal, cross-modal, and multimodal retrieval spanning a diverse set of tasks. We show that our embedding model demonstrates strong performance (with a score of 62.9 R@1 on MSCOCO, 68.8 NDCG@10 on Vatex, 69.9 on MTEB multilingual and 84.0 on MTEB Code) across a variety of tasks surpassing the performance of specialized models. These unified capabilities make Gemini Embedding 2 a promising candidate for downstream use cases such as RAG, recommendation and search. Furthermore, its robust zero-shot performance across distinct fields - from astronomy and bioscience to fine arts and the culinary arts - establishes it as a highly reliable, out-of-the-box representation even for specialized domains.
Using AI to Optimize Patient Transfer and Resource Utilization During Mass-Casualty Incidents: A Simulation Platform
Sep 10, 2025Mass casualty incidents (MCIs) overwhelm healthcare systems and demand rapid, accurate patient-hospital allocation decisions under extreme pressure. Here, we developed and validated a deep reinforcement learning-based decision-support AI agent to optimize patient transfer decisions during simulated MCIs by balancing patient acuity levels, specialized care requirements, hospital capacities, and transport logistics. To integrate this AI agent, we developed MasTER, a web-accessible command dashboard for MCI management simulations. Through a controlled user study with 30 participants (6 trauma experts and 24 non-experts), we evaluated three interaction approaches with the AI agent (human-only, human-AI collaboration, and AI-only) across 20- and 60-patient MCI scenarios in the Greater Toronto Area. Results demonstrate that increasing AI involvement significantly improves decision quality and consistency. The AI agent outperforms trauma surgeons (p < 0.001) and enables non-experts to achieve expert-level performance when assisted, contrasting sharply with their significantly inferior unassisted performance (p < 0.001). These findings establish the potential for our AI-driven decision support to enhance both MCI preparedness training and real-world emergency response management.
Gemini Embedding: Generalizable Embeddings from Gemini
Mar 10, 2025In this report, we introduce Gemini Embedding, a state-of-the-art embedding model leveraging the power of Gemini, Google's most capable large language model. Capitalizing on Gemini's inherent multilingual and code understanding capabilities, Gemini Embedding produces highly generalizable embeddings for text spanning numerous languages and textual modalities. The representations generated by Gemini Embedding can be precomputed and applied to a variety of downstream tasks including classification, similarity, clustering, ranking, and retrieval. Evaluated on the Massive Multilingual Text Embedding Benchmark (MMTEB), which includes over one hundred tasks across 250+ languages, Gemini Embedding substantially outperforms prior state-of-the-art models, demonstrating considerable improvements in embedding quality. Achieving state-of-the-art performance across MMTEB's multilingual, English, and code benchmarks, our unified model demonstrates strong capabilities across a broad selection of tasks and surpasses specialized domain-specific models.
Adapting Decoder-Based Language Models for Diverse Encoder Downstream Tasks
Mar 04, 2025



Decoder-based transformers, while revolutionizing language modeling and scaling to immense sizes, have not completely overtaken encoder-heavy architectures in natural language processing. Specifically, encoder-only models remain dominant in tasks like classification, regression, and ranking. This is primarily due to the inherent structure of decoder-based models, which limits their direct applicability to these tasks. In this paper, we introduce Gemma Encoder, adapting the powerful Gemma decoder model to an encoder architecture, thereby unlocking its potential for a wider range of non-generative applications. To optimize the adaptation from decoder to encoder, we systematically analyze various pooling strategies, attention mechanisms, and hyperparameters (e.g., dropout rate). Furthermore, we benchmark Gemma Encoder against established approaches on the GLUE benchmarks, and MS MARCO ranking benchmark, demonstrating its effectiveness and versatility.
WikiReading: A Novel Large-scale Language Understanding Task over Wikipedia
Mar 15, 2017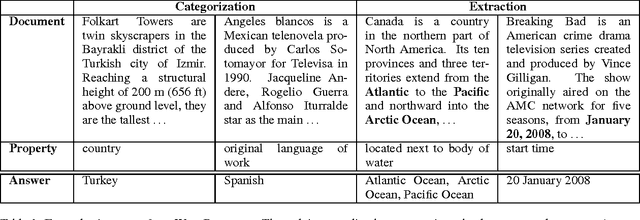
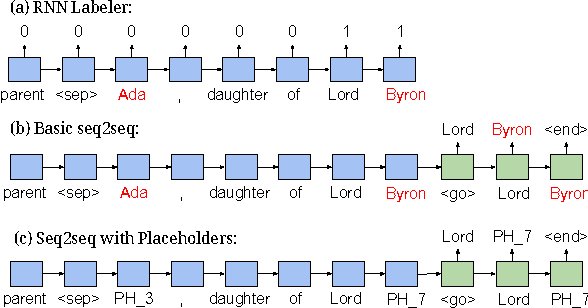
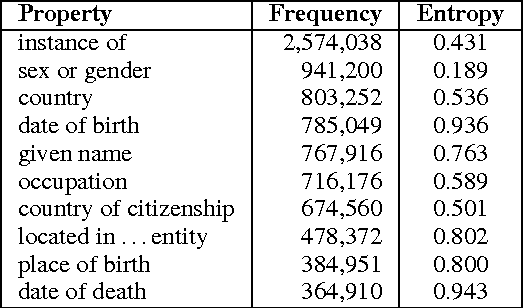
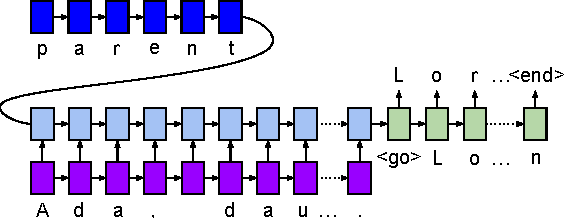
We present WikiReading, a large-scale natural language understanding task and publicly-available dataset with 18 million instances. The task is to predict textual values from the structured knowledge base Wikidata by reading the text of the corresponding Wikipedia articles. The task contains a rich variety of challenging classification and extraction sub-tasks, making it well-suited for end-to-end models such as deep neural networks (DNNs). We compare various state-of-the-art DNN-based architectures for document classification, information extraction, and question answering. We find that models supporting a rich answer space, such as word or character sequences, perform best. Our best-performing model, a word-level sequence to sequence model with a mechanism to copy out-of-vocabulary words, obtains an accuracy of 71.8%.