 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-end Multichannel Speaker-Attributed ASR: Speaker Guided Decoder and Input Feature Analysis
Oct 16, 2023We present an end-to-end multichannel speaker-attributed automatic speech recognition (MC-SA-ASR) system that combines a Conformer-based encoder with multi-frame crosschannel attention and a speaker-attributed Transformer-based decoder. To the best of our knowledge, this is the first model that efficiently integrates ASR and speaker identification modules in a multichannel setting. On simulated mixtures of LibriSpeech data, our system reduces the word error rate (WER) by up to 12% and 16% relative compared to previously proposed single-channel and multichannel approaches, respectively. Furthermore, we investigate the impact of different input features, including multichannel magnitude and phase information, on the ASR performance. Finally, our experiments on the AMI corpus confirm the effectiveness of our system for real-world multichannel meeting transcription.
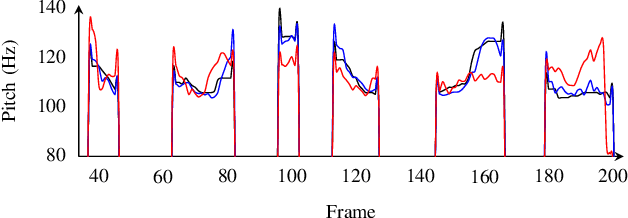
Stochastic Pitch Prediction Improves the Diversity and Naturalness of Speech in Glow-TTS
May 28, 2023Flow-based generative models are widely used in text-to-speech (TTS) systems to learn the distribution of audio features (e.g., Mel-spectrograms) given the input tokens and to sample from this distribution to generate diverse utterances. However, in the zero-shot multi-speaker TTS scenario, the generated utterances lack diversity and naturalness. In this paper, we propose to improve the diversity of utterances by explicitly learning the distribution of fundamental frequency sequences (pitch contours) of each speaker during training using a stochastic flow-based pitch predictor, then conditioning the model on generated pitch contours during inference. The experimental results demonstrate that the proposed method yields a significant improvement in the naturalness and diversity of speech generated by a Glow-TTS model that uses explicit stochastic pitch prediction, over a Glow-TTS baseline and an improved Glow-TTS model that uses a stochastic duration predictor.
How to train your sound source localizer
Nov 30, 2022

Learning-based methods have become ubiquitous in sound source localization (SSL). Existing systems rely on simulated training sets for the lack of sufficiently large, diverse and annotated real datasets. Most room acoustic simulators used for this purpose rely on the image source method (ISM) because of its computational efficiency. This paper argues that carefully extending the ISM to incorporate more realistic surface, source and microphone responses into training sets can significantly boost the real-world performance of SSL systems. It is shown that increasing the training-set realism of a state-of-the-art direction-of-arrival estimator yields consistent improvements across three different real test sets featuring human speakers in a variety of rooms and various microphone arrays. An ablation study further reveals that every added layer of realism contributes positively to these improvements.
Can we use Common Voice to train a Multi-Speaker TTS system?
Oct 12, 2022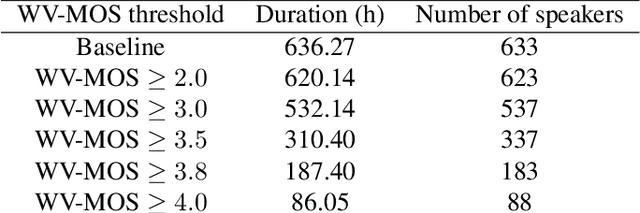
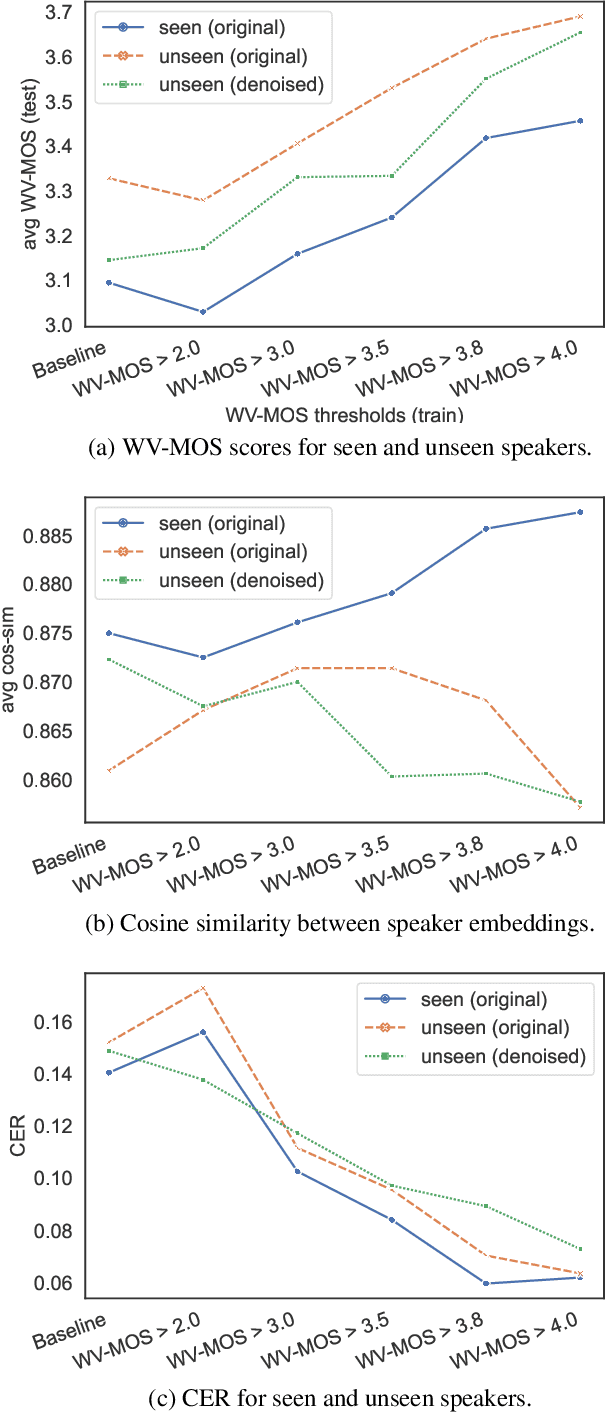
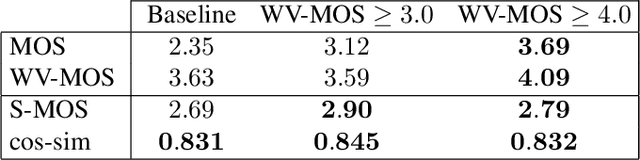
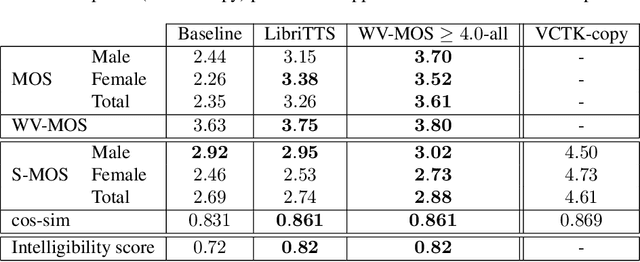
Training of multi-speaker text-to-speech (TTS) systems relies on curated datasets based on high-quality recordings or audiobooks. Such datasets often lack speaker diversity and are expensive to collect. As an alternative, recent studies have leveraged the availability of large, crowdsourced automatic speech recognition (ASR) datasets. A major problem with such datasets is the presence of noisy and/or distorted samples, which degrade TTS quality. In this paper, we propose to automatically select high-quality training samples using a non-intrusive mean opinion score (MOS) estimator, WV-MOS. We show the viability of this approach for training a multi-speaker GlowTTS model on the Common Voice English dataset. Our approach improves the overall quality of generated utterances by 1.26 MOS point with respect to training on all the samples and by 0.35 MOS point with respect to training on the LibriTTS dataset. This opens the door to automatic TTS dataset curation for a wider range of languages.
Realistic sources, receivers and walls improve the generalisability of virtually-supervised blind acoustic parameter estimators
Jul 19, 2022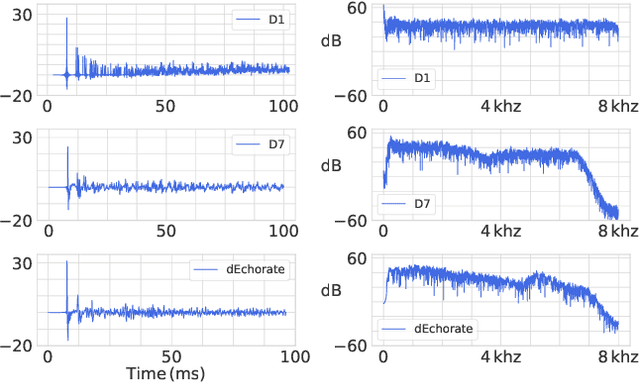

Blind acoustic parameter estimation consists in inferring the acoustic properties of an environment from recordings of unknown sound sources. Recent works in this area have utilized deep neural networks trained either partially or exclusively on simulated data, due to the limited availability of real annotated measurements. In this paper, we study whether a model purely trained using a fast image-source room impulse response simulator can generalize to real data. We present an ablation study on carefully crafted simulated training sets that account for different levels of realism in source, receiver and wall responses. The extent of realism is controlled by the sampling of wall absorption coefficients and by applying measured directivity patterns to microphones and sources. A state-of-the-art model trained on these datasets is evaluated on the task of jointly estimating the room's volume, total surface area, and octave-band reverberation times from multiple, multichannel speech recordings. Results reveal that every added layer of simulation realism at train time significantly improves the estimation of all quantities on real signals.
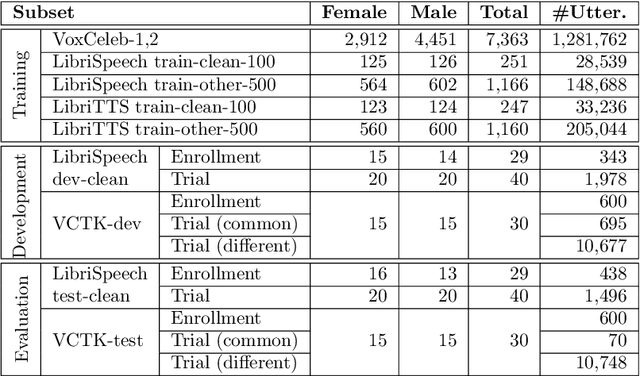
The VoicePrivacy 2020 Challenge Evaluation Plan
May 14, 2022
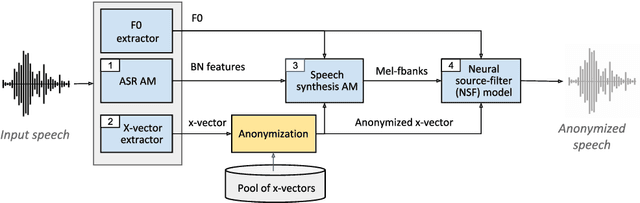
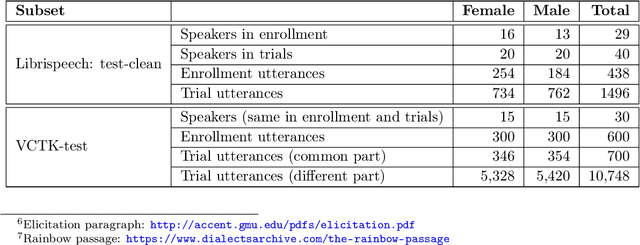
The VoicePrivacy Challenge aims to promote the development of privacy preservation tools for speech technology by gathering a new community to define the tasks of interest and the evaluation methodology, and benchmarking solutions through a series of challenges. In this document, we formulate the voice anonymization task selected for the VoicePrivacy 2020 Challenge and describe the datasets used for system development and evaluation. We also present the attack models and the associated objective and subjective evaluation metrics. We introduce two anonymization baselines and report objective evaluation results.
The VoicePrivacy 2022 Challenge Evaluation Plan
Mar 27, 2022For new participants - Executive summary: (1) The task is to develop a voice anonymization system for speech data which conceals the speaker's voice identity while protecting linguistic content, paralinguistic attributes, intelligibility and naturalness. (2) Training, development and evaluation datasets are provided in addition to 3 different baseline anonymization systems, evaluation scripts, and metrics. Participants apply their developed anonymization systems, run evaluation scripts and submit objective evaluation results and anonymized speech data to the organizers. (3) Results will be presented at a workshop held in conjunction with INTERSPEECH 2022 to which all participants are invited to present their challenge systems and to submit additional workshop papers. For readers familiar with the VoicePrivacy Challenge - Changes w.r.t. 2020: (1) A stronger, semi-informed attack model in the form of an automatic speaker verification (ASV) system trained on anonymized (per-utterance) speech data. (2) Complementary metrics comprising the equal error rate (EER) as a privacy metric, the word error rate (WER) as a primary utility metric, and the pitch correlation and gain of voice distinctiveness as secondary utility metrics. (3) A new ranking policy based upon a set of minimum target privacy requirements.
Differentially Private Speaker Anonymization
Feb 23, 2022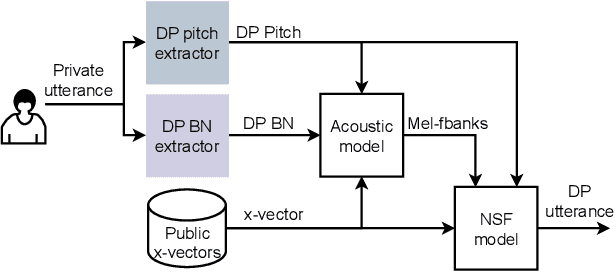
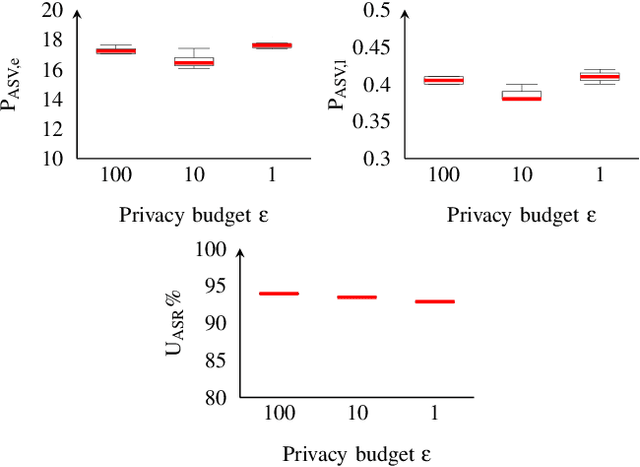
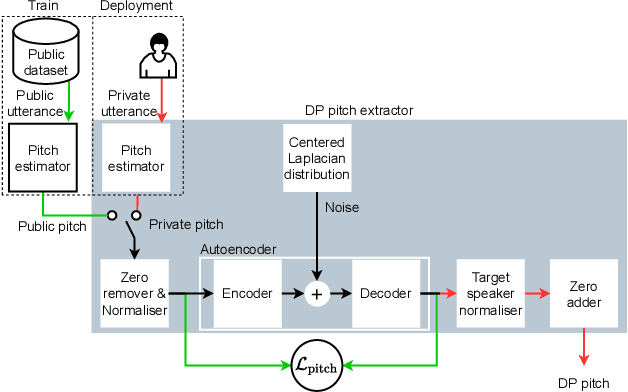
Sharing real-world speech utterances is key to the training and deployment of voice-based services. However, it also raises privacy risks as speech contains a wealth of personal data. Speaker anonymization aims to remove speaker information from a speech utterance while leaving its linguistic and prosodic attributes intact. State-of-the-art techniques operate by disentangling the speaker information (represented via a speaker embedding) from these attributes and re-synthesizing speech based on the speaker embedding of another speaker. Prior research in the privacy community has shown that anonymization often provides brittle privacy protection, even less so any provable guarantee. In this work, we show that disentanglement is indeed not perfect: linguistic and prosodic attributes still contain speaker information. We remove speaker information from these attributes by introducing differentially private feature extractors based on an autoencoder and an automatic speech recognizer, respectively, trained using noise layers. We plug these extractors in the state-of-the-art anonymization pipeline and generate, for the first time, differentially private utterances with a provable upper bound on the speaker information they contain. We evaluate empirically the privacy and utility resulting from our differentially private speaker anonymization approach on the LibriSpeech data set. Experimental results show that the generated utterances retain very high utility for automatic speech recognition training and inference, while being much better protected against strong adversaries who leverage the full knowledge of the anonymization process to try to infer the speaker identity.
The VoicePrivacy 2020 Challenge: Results and findings
Sep 01, 2021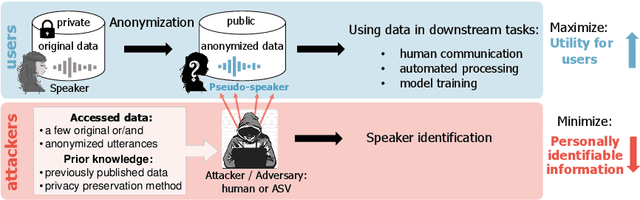
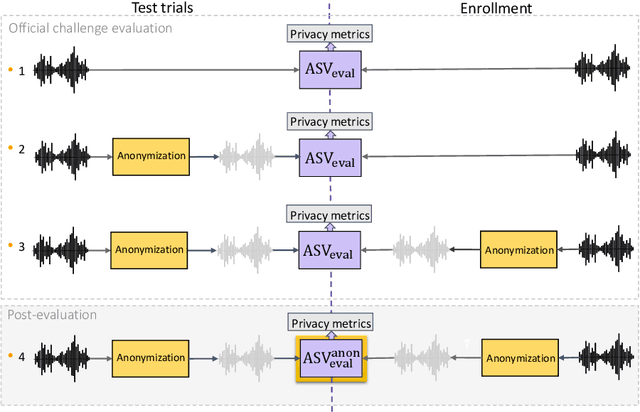
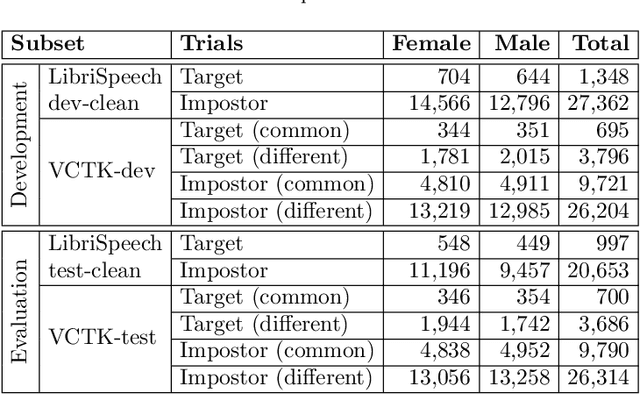
This paper presents the results and analyses stemming from the first VoicePrivacy 2020 Challenge which focuses on developing anonymization solutions for speech technology. We provide a systematic overview of the challenge design with an analysis of submitted systems and evaluation results. In particular, we describe the voice anonymization task and datasets used for system development and evaluation. Also, we present different attack models and the associated objective and subjective evaluation metrics. We introduce two anonymization baselines and provide a summary description of the anonymization systems developed by the challenge participants. We report objective and subjective evaluation results for baseline and submitted systems. In addition, we present experimental results for alternative privacy metrics and attack models developed as a part of the post-evaluation analysis. Finally, we summarize our insights and observations that will influence the design of the next VoicePrivacy challenge edition and some directions for future voice anonymization research.
Benchmarking and challenges in security and privacy for voice biometrics
Sep 01, 2021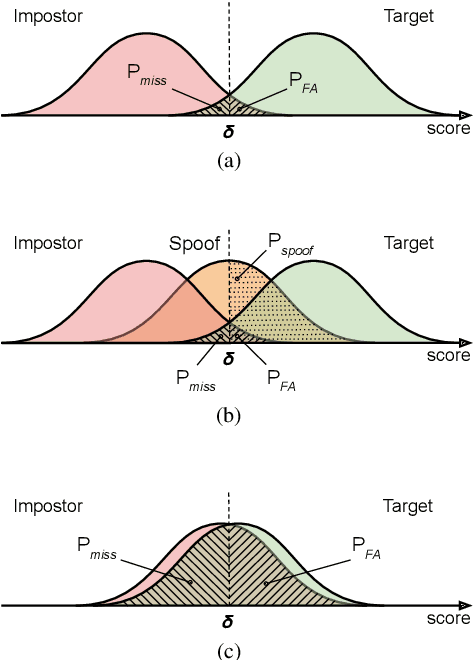
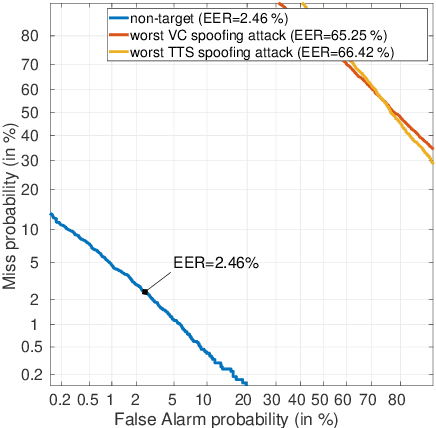
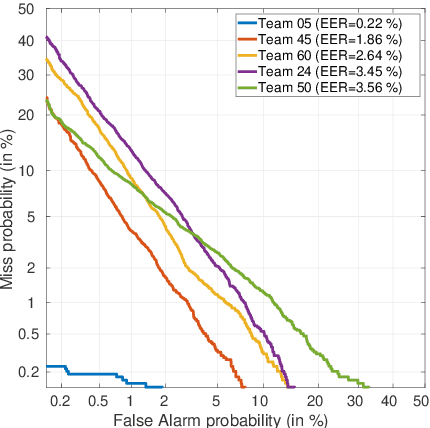
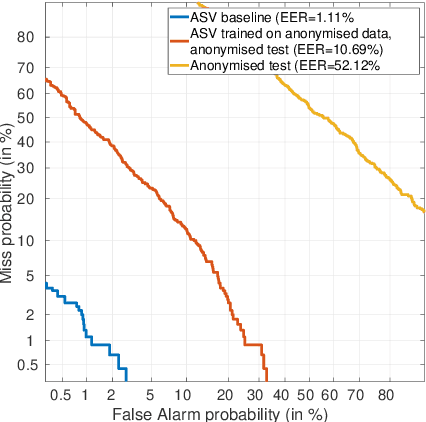
For many decades, research in speech technologies has focused upon improving reliability. With this now meeting user expectations for a range of diverse applications, speech technology is today omni-present. As result, a focus on security and privacy has now come to the fore. Here, the research effort is in its relative infancy and progress calls for greater, multidisciplinary collaboration with security, privacy, legal and ethical experts among others. Such collaboration is now underway. To help catalyse the efforts, this paper provides a high-level overview of some related research. It targets the non-speech audience and describes the benchmarking methodology that has spearheaded progress in traditional research and which now drives recent security and privacy initiatives related to voice biometrics. We describe: the ASVspoof challenge relating to the development of spoofing countermeasures; the VoicePrivacy initiative which promotes research in anonymisation for privacy preservation.