 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeparating value functions across time-scales
Feb 08, 2019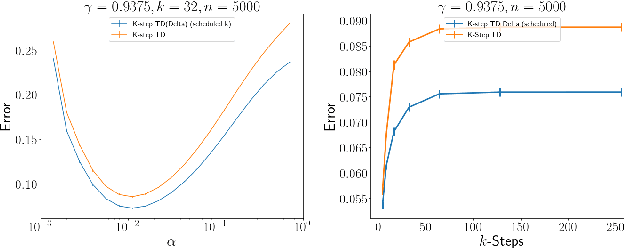

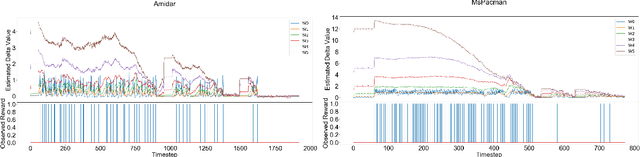
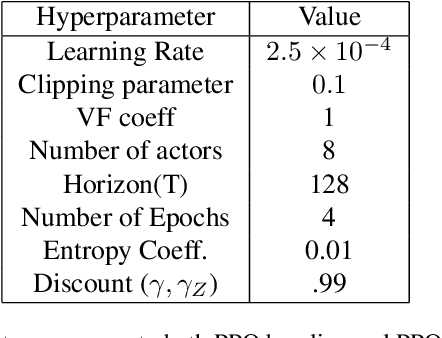
In many finite horizon episodic reinforcement learning (RL) settings, it is desirable to optimize for the undiscounted return - in settings like Atari, for instance, the goal is to collect the most points while staying alive in the long run. Yet, it may be difficult (or even intractable) mathematically to learn with this target. As such, temporal discounting is often applied to optimize over a shorter effective planning horizon. This comes at the cost of potentially biasing the optimization target away from the undiscounted goal. In settings where this bias is unacceptable - where the system must optimize for longer horizons at higher discounts - the target of the value function approximator may increase in variance leading to difficulties in learning. We present an extension of temporal difference (TD) learning, which we call TD($\Delta$), that breaks down a value function into a series of components based on the differences between value functions with smaller discount factors. The separation of a longer horizon value function into these components has useful properties in scalability and performance. We discuss these properties and show theoretic and empirical improvements over standard TD learning in certain settings.
Tighter Problem-Dependent Regret Bounds in Reinforcement Learning without Domain Knowledge using Value Function Bounds
Jan 01, 2019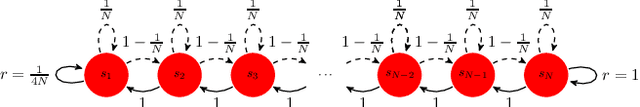
Strong worst-case performance bounds for episodic reinforcement learning exist but fortunately in practice RL algorithms perform much better than such bounds would predict. Algorithms and theory that provide strong problem-dependent bounds could help illuminate the key features of what makes a RL problem hard and reduce the barrier to using RL algorithms in practice. As a step towards this we derive an algorithm for finite horizon discrete MDPs and associated analysis that both yields state-of-the art worst-case regret bounds in the dominant terms and yields substantially tighter bounds if the RL environment has small environmental norm, which is a function of the variance of the next-state value functions. An important benefit of our algorithmic is that it does not require apriori knowledge of a bound on the environmental norm. As a result of our analysis, we also help address an open learning theory question~\cite{jiang2018open} about episodic MDPs with a constant upper-bound on the sum of rewards, providing a regret bound with no $H$-dependence in the leading term that scales a polynomial function of the number of episodes.
Distilling Information from a Flood: A Possibility for the Use of Meta-Analysis and Systematic Review in Machine Learning Research
Dec 03, 2018
The current flood of information in all areas of machine learning research, from computer vision to reinforcement learning, has made it difficult to make aggregate scientific inferences. It can be challenging to distill a myriad of similar papers into a set of useful principles, to determine which new methodologies to use for a particular application, and to be confident that one has compared against all relevant related work when developing new ideas. However, such a rapidly growing body of research literature is a problem that other fields have already faced - in particular, medicine and epidemiology. In those fields, systematic reviews and meta-analyses have been used exactly for dealing with these issues and it is not uncommon for entire journals to be dedicated to such analyses. Here, we suggest the field of machine learning might similarly benefit from meta-analysis and systematic review, and we encourage further discussion and development along this direction.
Policy Certificates: Towards Accountable Reinforcement Learning
Nov 07, 2018
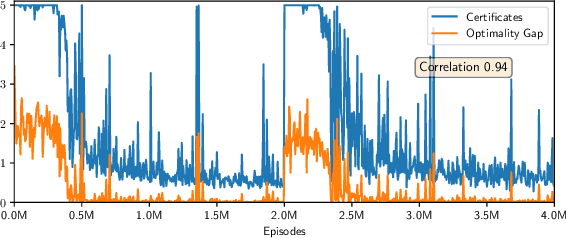
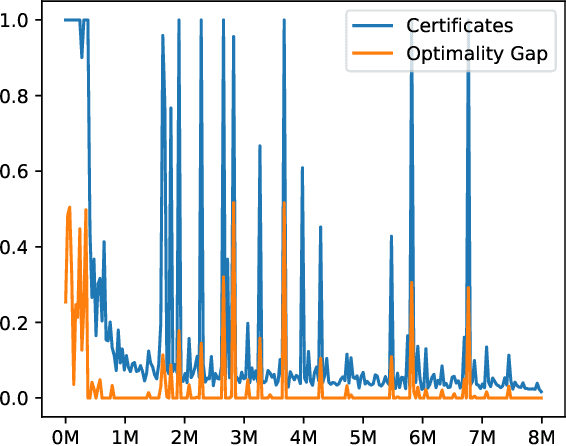
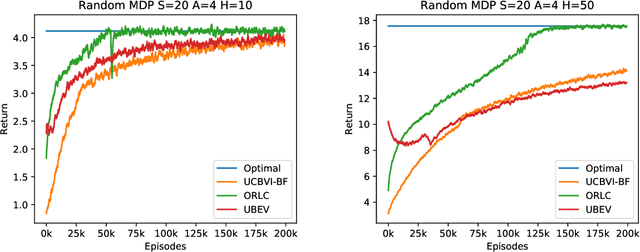
The performance of a reinforcement learning algorithm can vary drastically during learning because of exploration. Existing algorithms provide little information about their current policy's quality before executing it, and thus have limited use in high-stakes applications like healthcare. In this paper, we address such a lack of accountability by proposing that algorithms output policy certificates, which upper bound the suboptimality in the next episode, allowing humans to intervene when the certified quality is not satisfactory. We further present a new learning framework (IPOC) for finite-sample analysis with policy certificates, and develop two IPOC algorithms that enjoy guarantees for the quality of both their policies and certificates.
Representation Balancing MDPs for Off-Policy Policy Evaluation
Oct 31, 2018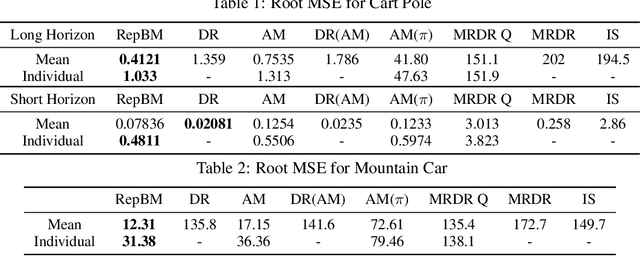

We study the problem of off-policy policy evaluation (OPPE) in RL. In contrast to prior work, we consider how to estimate both the individual policy value and average policy value accurately. We draw inspiration from recent work in causal reasoning, and propose a new finite sample generalization error bound for value estimates from MDP models. Using this upper bound as an objective, we develop a learning algorithm of an MDP model with a balanced representation, and show that our approach can yield substantially lower MSE in common synthetic benchmarks and a HIV treatment simulation domain.
When Simple Exploration is Sample Efficient: Identifying Sufficient Conditions for Random Exploration to Yield PAC RL Algorithms
Aug 04, 2018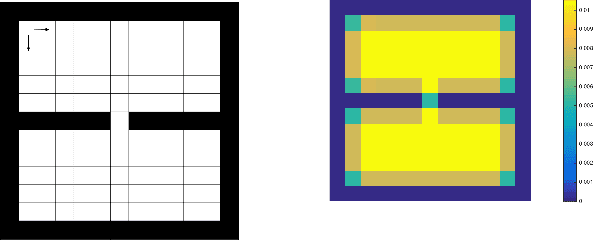
Efficient exploration is one of the key challenges for reinforcement learning (RL) algorithms. Most traditional sample efficiency bounds require strategic exploration. Recently many deep RL algorithms with simple heuristic exploration strategies that have few formal guarantees, achieve surprising success in many domains. These results pose an important question about understanding these exploration strategies such as $e$-greedy, as well as understanding what characterize the difficulty of exploration in MDPs. In this work we propose problem specific sample complexity bounds of $Q$ learning with random walk exploration that rely on several structural properties. We also link our theoretical results to some empirical benchmark domains, to illustrate if our bound gives polynomial sample complexity in these domains and how that is related with the empirical performance.
Behaviour Policy Estimation in Off-Policy Policy Evaluation: Calibration Matters
Jul 10, 2018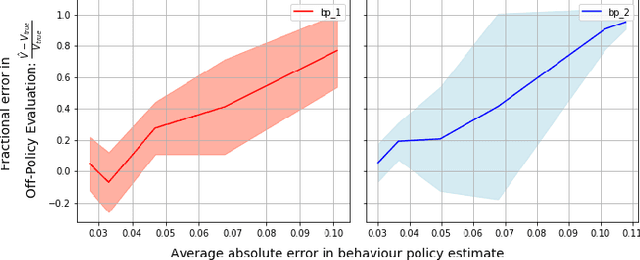
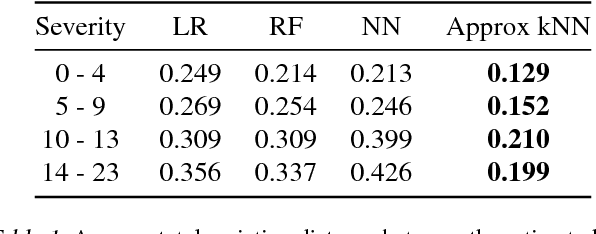
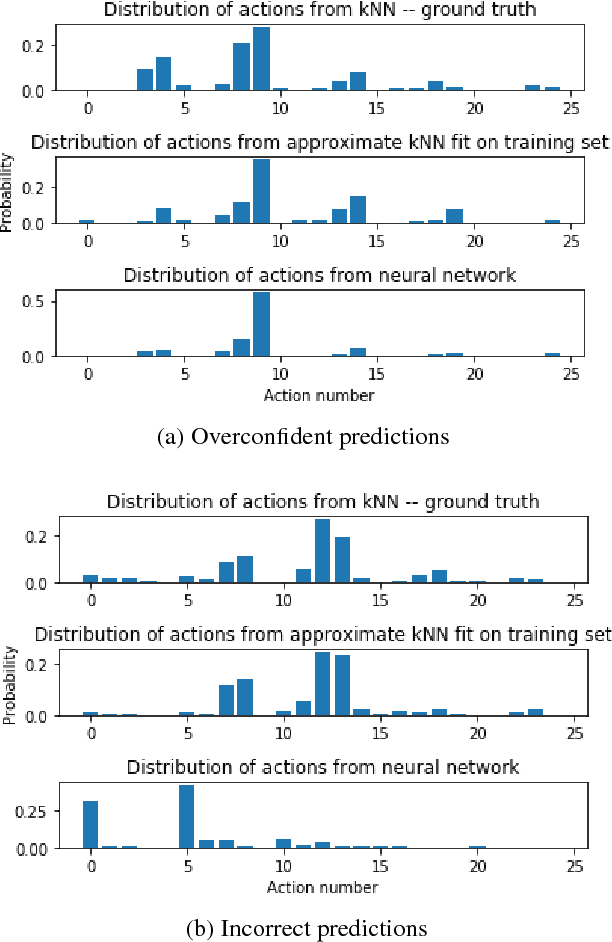

In this work, we consider the problem of estimating a behaviour policy for use in Off-Policy Policy Evaluation (OPE) when the true behaviour policy is unknown. Via a series of empirical studies, we demonstrate how accurate OPE is strongly dependent on the calibration of estimated behaviour policy models: how precisely the behaviour policy is estimated from data. We show how powerful parametric models such as neural networks can result in highly uncalibrated behaviour policy models on a real-world medical dataset, and illustrate how a simple, non-parametric, k-nearest neighbours model produces better calibrated behaviour policy estimates and can be used to obtain superior importance sampling-based OPE estimates.
Sample-Efficient Deep RL with Generative Adversarial Tree Search
Jun 15, 2018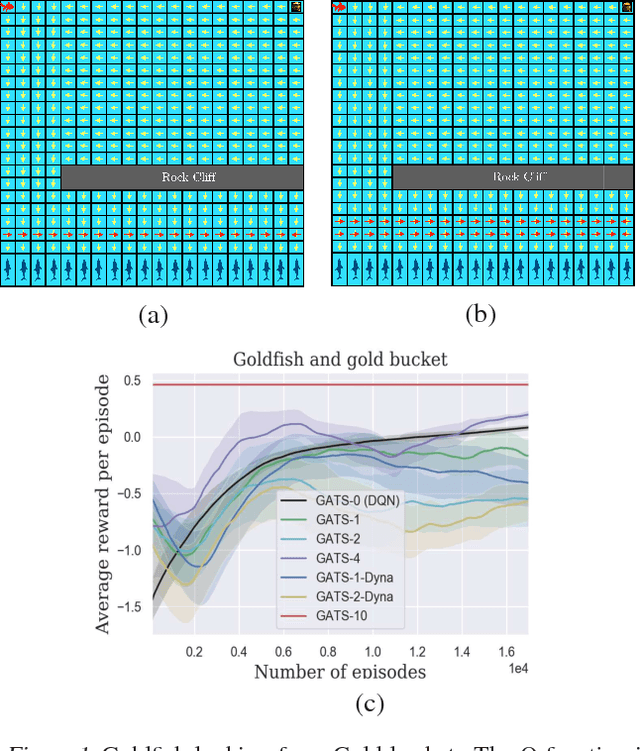



We propose Generative Adversarial Tree Search (GATS), a sample-efficient Deep Reinforcement Learning (DRL) algorithm. While Monte Carlo Tree Search (MCTS) is known to be effective for search and planning in RL, it is often sample-inefficient and therefore expensive to apply in practice. In this work, we develop a Generative Adversarial Network (GAN) architecture to model an environment's dynamics and a predictor model for the reward function. We exploit collected data from interaction with the environment to learn these models, which we then use for model-based planning. During planning, we deploy a finite depth MCTS, using the learned model for tree search and a learned Q-value for the leaves, to find the best action. We theoretically show that GATS improves the bias-variance trade-off in value-based DRL. Moreover, we show that the generative model learns the model dynamics using orders of magnitude fewer samples than the Q-learner. In non-stationary settings where the environment model changes, we find the generative model adapts significantly faster than the Q-learner to the new environment.
Strategic Object Oriented Reinforcement Learning
Jun 01, 2018
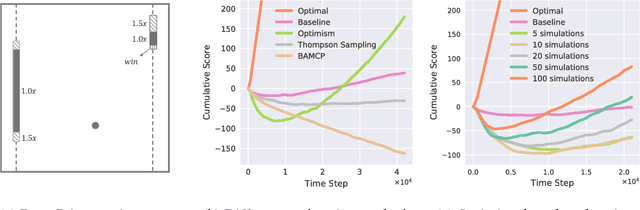
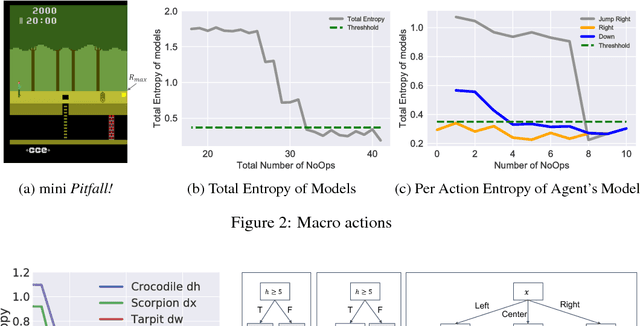
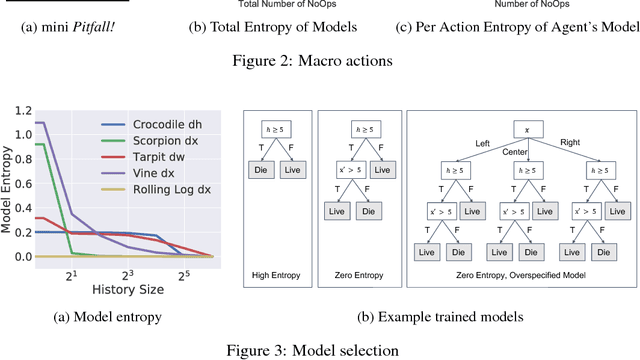
Humans learn to play video games significantly faster than state-of-the-art reinforcement learning (RL) algorithms. Inspired by this, we introduce strategic object oriented reinforcement learning (SOORL) to learn simple dynamics model through automatic model selection and perform efficient planning with strategic exploration. We compare different exploration strategies in a model-based setting in which exact planning is impossible. Additionally, we test our approach on perhaps the hardest Atari game Pitfall! and achieve significantly improved exploration and performance over prior methods.
Efficient Exploration through Bayesian Deep Q-Networks
Feb 13, 2018
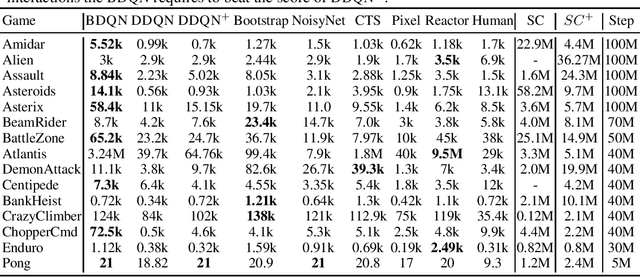
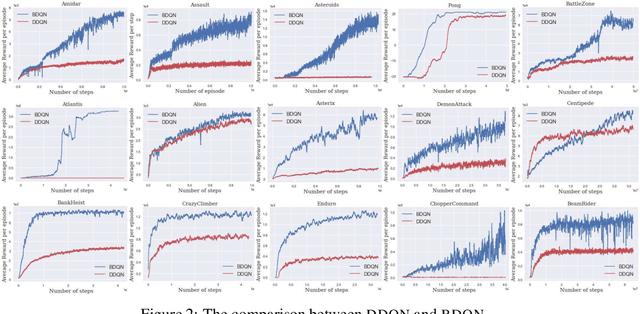
We propose Bayesian Deep Q-Network (BDQN), a practical Thompson sampling based Reinforcement Learning (RL) Algorithm. Thompson sampling allows for targeted exploration in high dimensions through posterior sampling but is usually computationally expensive. We address this limitation by introducing uncertainty only at the output layer of the network through a Bayesian Linear Regression (BLR) model. This layer can be trained with fast closed-form updates and its samples can be drawn efficiently through the Gaussian distribution. We apply our method to a wide range of Atari games in Arcade Learning Environments. Since BDQN carries out more efficient exploration, it is able to reach higher rewards substantially faster than a key baseline, the double deep Q network (DDQN).