 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the Factuality of Zero-shot Summarizers Across Varied Domains
Feb 05, 2024



Recent work has shown that large language models (LLMs) are capable of generating summaries zero-shot (i.e., without explicit supervision) that, under human assessment, are often comparable or even preferred to manually composed reference summaries. However, this prior work has focussed almost exclusively on evaluating news article summarization. How do zero-shot summarizers perform in other (potentially more specialized) domains? In this work we evaluate zero-shot generated summaries across specialized domains including biomedical articles, and legal bills (in addition to standard news benchmarks for reference). We focus especially on the factuality of outputs. We acquire annotations from domain experts to identify inconsistencies in summaries and systematically categorize these errors. We analyze whether the prevalence of a given domain in the pretraining corpus affects extractiveness and faithfulness of generated summaries of articles in this domain. We release all collected annotations to facilitate additional research toward measuring and realizing factually accurate summarization, beyond news articles. The dataset can be downloaded from https://github.com/sanjanaramprasad/zero_shot_faceval_domains
Perspectives on the State and Future of Deep Learning - 2023
Dec 19, 2023The goal of this series is to chronicle opinions and issues in the field of machine learning as they stand today and as they change over time. The plan is to host this survey periodically until the AI singularity paperclip-frenzy-driven doomsday, keeping an updated list of topical questions and interviewing new community members for each edition. In this issue, we probed people's opinions on interpretable AI, the value of benchmarking in modern NLP, the state of progress towards understanding deep learning, and the future of academia.
AmazonQA: A Review-Based Question Answering Task
Aug 20, 2019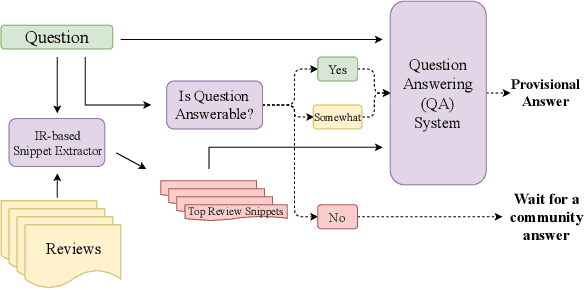
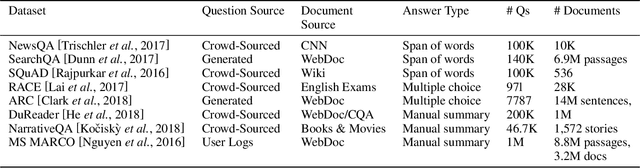
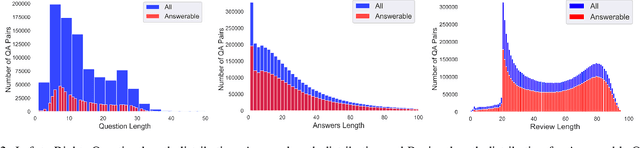
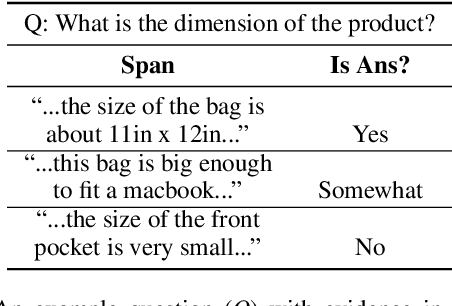
Every day, thousands of customers post questions on Amazon product pages. After some time, if they are fortunate, a knowledgeable customer might answer their question. Observing that many questions can be answered based upon the available product reviews, we propose the task of review-based QA. Given a corpus of reviews and a question, the QA system synthesizes an answer. To this end, we introduce a new dataset and propose a method that combines information retrieval techniques for selecting relevant reviews (given a question) and "reading comprehension" models for synthesizing an answer (given a question and review). Our dataset consists of 923k questions, 3.6M answers and 14M reviews across 156k products. Building on the well-known Amazon dataset, we collect additional annotations, marking each question as either answerable or unanswerable based on the available reviews. A deployed system could first classify a question as answerable and then attempt to generate an answer. Notably, unlike many popular QA datasets, here, the questions, passages, and answers are all extracted from real human interactions. We evaluate numerous models for answer generation and propose strong baselines, demonstrating the challenging nature of this new task.
Sample-Efficient Deep RL with Generative Adversarial Tree Search
Jun 15, 2018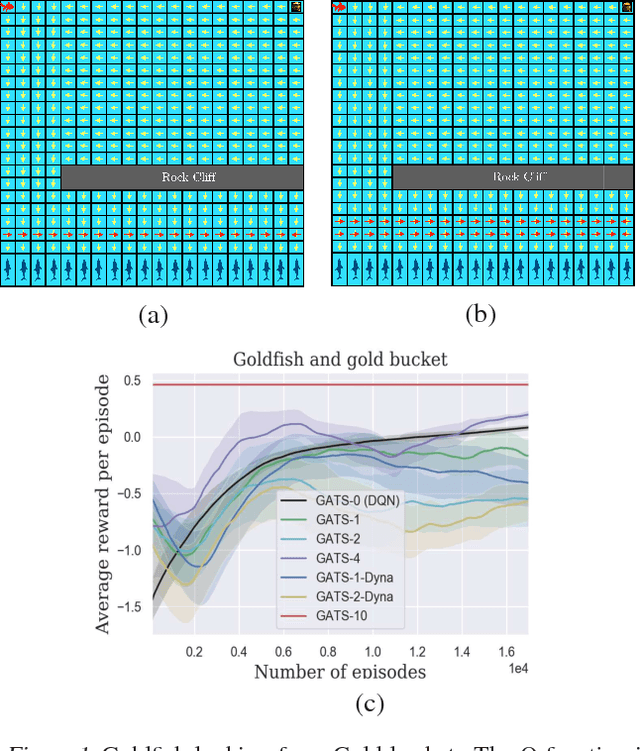



We propose Generative Adversarial Tree Search (GATS), a sample-efficient Deep Reinforcement Learning (DRL) algorithm. While Monte Carlo Tree Search (MCTS) is known to be effective for search and planning in RL, it is often sample-inefficient and therefore expensive to apply in practice. In this work, we develop a Generative Adversarial Network (GAN) architecture to model an environment's dynamics and a predictor model for the reward function. We exploit collected data from interaction with the environment to learn these models, which we then use for model-based planning. During planning, we deploy a finite depth MCTS, using the learned model for tree search and a learned Q-value for the leaves, to find the best action. We theoretically show that GATS improves the bias-variance trade-off in value-based DRL. Moreover, we show that the generative model learns the model dynamics using orders of magnitude fewer samples than the Q-learner. In non-stationary settings where the environment model changes, we find the generative model adapts significantly faster than the Q-learner to the new environment.
Predicting Surgery Duration with Neural Heteroscedastic Regression
Jul 13, 2017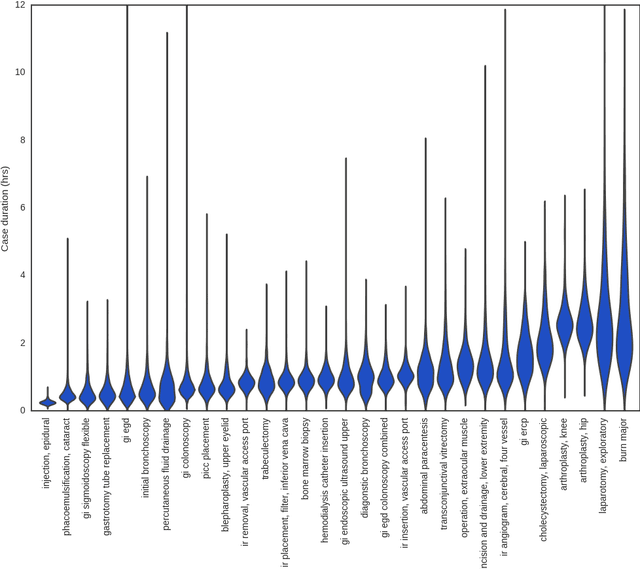
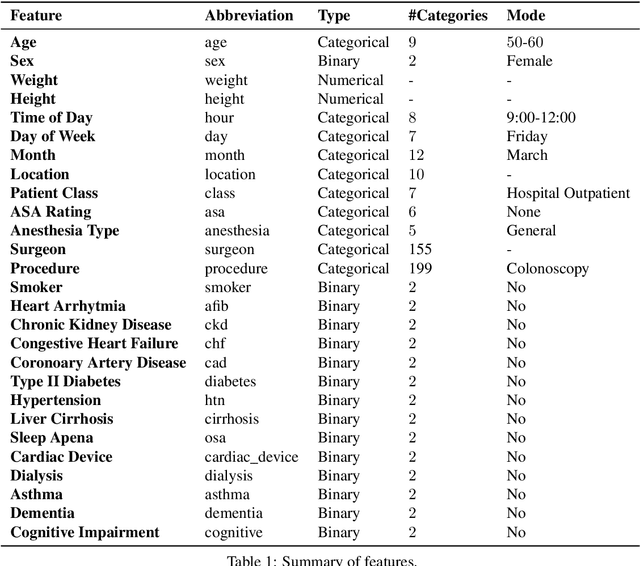
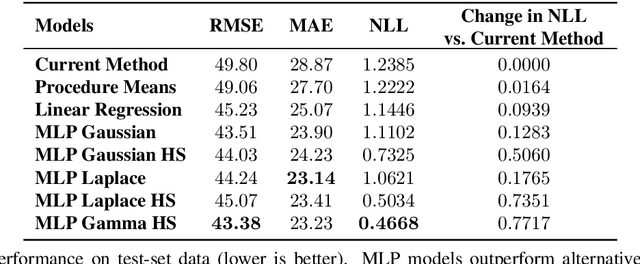
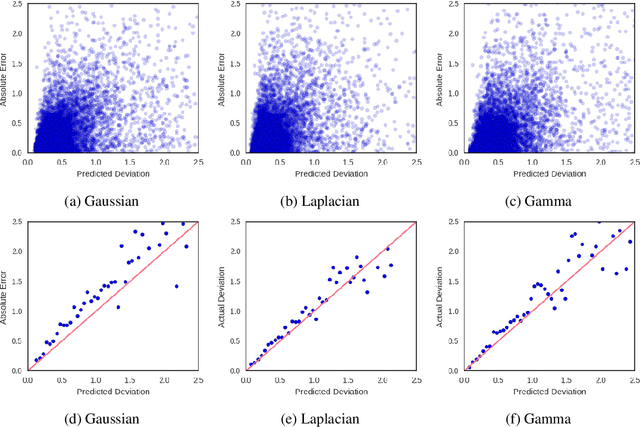
Scheduling surgeries is a challenging task due to the fundamental uncertainty of the clinical environment, as well as the risks and costs associated with under- and over-booking. We investigate neural regression algorithms to estimate the parameters of surgery case durations, focusing on the issue of heteroscedasticity. We seek to simultaneously estimate the duration of each surgery, as well as a surgery-specific notion of our uncertainty about its duration. Estimating this uncertainty can lead to more nuanced and effective scheduling strategies, as we are able to schedule surgeries more efficiently while allowing an informed and case-specific margin of error. Using surgery records %from the UC San Diego Health System, from a large United States health system we demonstrate potential improvements on the order of 20% (in terms of minutes overbooked) compared to current scheduling techniques. Moreover, we demonstrate that surgery durations are indeed heteroscedastic. We show that models that estimate case-specific uncertainty better fit the data (log likelihood). Additionally, we show that the heteroscedastic predictions can more optimally trade off between over and under-booking minutes, especially when idle minutes and scheduling collisions confer disparate costs.