 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Interventions with User-Defined Goals for Health Behavior Change
Nov 16, 2023


Physical inactivity remains a major public health concern, having associations with adverse health outcomes such as cardiovascular disease and type-2 diabetes. Mobile health applications present a promising avenue for low-cost, scalable physical activity promotion, yet often suffer from small effect sizes and low adherence rates, particularly in comparison to human coaching. Goal-setting is a critical component of health coaching that has been underutilized in adaptive algorithms for mobile health interventions. This paper introduces a modification to the Thompson sampling algorithm that places emphasis on individualized goal-setting by optimizing personalized reward functions. As a step towards supporting goal-setting, this paper offers a balanced approach that can leverage shared structure while optimizing individual preferences and goals. We prove that our modification incurs only a constant penalty on the cumulative regret while preserving the sample complexity benefits of data sharing. In a physical activity simulator, we demonstrate that our algorithm achieves substantial improvements in cumulative regret compared to baselines that do not share data or do not optimize for individualized rewards.
Proportional Response: Contextual Bandits for Simple and Cumulative Regret Minimization
Jul 05, 2023
Simple regret minimization is a critical problem in learning optimal treatment assignment policies across various domains, including healthcare and e-commerce. However, it remains understudied in the contextual bandit setting. We propose a new family of computationally efficient bandit algorithms for the stochastic contextual bandit settings, with the flexibility to be adapted for cumulative regret minimization (with near-optimal minimax guarantees) and simple regret minimization (with SOTA guarantees). Furthermore, our algorithms adapt to model misspecification and extend to the continuous arm settings. These advantages come from constructing and relying on "conformal arm sets" (CASs), which provide a set of arms at every context that encompass the context-specific optimal arm with some probability across the context distribution. Our positive results on simple and cumulative regret guarantees are contrasted by a negative result, which shows that an algorithm can't achieve instance-dependent simple regret guarantees while simultaneously achieving minimax optimal cumulative regret guarantees.
Supervised Pretraining Can Learn In-Context Reinforcement Learning
Jun 26, 2023



Large transformer models trained on diverse datasets have shown a remarkable ability to learn in-context, achieving high few-shot performance on tasks they were not explicitly trained to solve. In this paper, we study the in-context learning capabilities of transformers in decision-making problems, i.e., reinforcement learning (RL) for bandits and Markov decision processes. To do so, we introduce and study Decision-Pretrained Transformer (DPT), a supervised pretraining method where the transformer predicts an optimal action given a query state and an in-context dataset of interactions, across a diverse set of tasks. This procedure, while simple, produces a model with several surprising capabilities. We find that the pretrained transformer can be used to solve a range of RL problems in-context, exhibiting both exploration online and conservatism offline, despite not being explicitly trained to do so. The model also generalizes beyond the pretraining distribution to new tasks and automatically adapts its decision-making strategies to unknown structure. Theoretically, we show DPT can be viewed as an efficient implementation of Bayesian posterior sampling, a provably sample-efficient RL algorithm. We further leverage this connection to provide guarantees on the regret of the in-context algorithm yielded by DPT, and prove that it can learn faster than algorithms used to generate the pretraining data. These results suggest a promising yet simple path towards instilling strong in-context decision-making abilities in transformers.
Waypoint Transformer: Reinforcement Learning via Supervised Learning with Intermediate Targets
Jun 24, 2023



Despite the recent advancements in offline reinforcement learning via supervised learning (RvS) and the success of the decision transformer (DT) architecture in various domains, DTs have fallen short in several challenging benchmarks. The root cause of this underperformance lies in their inability to seamlessly connect segments of suboptimal trajectories. To overcome this limitation, we present a novel approach to enhance RvS methods by integrating intermediate targets. We introduce the Waypoint Transformer (WT), using an architecture that builds upon the DT framework and conditioned on automatically-generated waypoints. The results show a significant increase in the final return compared to existing RvS methods, with performance on par or greater than existing state-of-the-art temporal difference learning-based methods. Additionally, the performance and stability improvements are largest in the most challenging environments and data configurations, including AntMaze Large Play/Diverse and Kitchen Mixed/Partial.
Reinforcement Learning Tutor Better Supported Lower Performers in a Math Task
Apr 13, 2023



Resource limitations make it hard to provide all students with one of the most effective educational interventions: personalized instruction. Reinforcement learning could be a key tool to reduce the development cost and improve the effectiveness of intelligent tutoring software that aims to provide the right support, at the right time, to a student. Here we illustrate that deep reinforcement learning can be used to provide adaptive pedagogical support to students learning about the concept of volume in a narrative storyline software. Using explainable artificial intelligence tools, we extracted interpretable insights about the pedagogical policy learned and demonstrated that the resulting policy had similar performance in a different student population. Most importantly, in both studies, the reinforcement-learning narrative system had the largest benefit for those students with the lowest initial pretest scores, suggesting the opportunity for AI to adapt and provide support for those most in need.
Estimating Optimal Policy Value in General Linear Contextual Bandits
Feb 19, 2023


In many bandit problems, the maximal reward achievable by a policy is often unknown in advance. We consider the problem of estimating the optimal policy value in the sublinear data regime before the optimal policy is even learnable. We refer to this as $V^*$ estimation. It was recently shown that fast $V^*$ estimation is possible but only in disjoint linear bandits with Gaussian covariates. Whether this is possible for more realistic context distributions has remained an open and important question for tasks such as model selection. In this paper, we first provide lower bounds showing that this general problem is hard. However, under stronger assumptions, we give an algorithm and analysis proving that $\widetilde{\mathcal{O}}(\sqrt{d})$ sublinear estimation of $V^*$ is indeed information-theoretically possible, where $d$ is the dimension. We then present a more practical, computationally efficient algorithm that estimates a problem-dependent upper bound on $V^*$ that holds for general distributions and is tight when the context distribution is Gaussian. We prove our algorithm requires only $\widetilde{\mathcal{O}}(\sqrt{d})$ samples to estimate the upper bound. We use this upper bound and the estimator to obtain novel and improved guarantees for several applications in bandit model selection and testing for treatment effects.
Model-based Offline Reinforcement Learning with Local Misspecification
Jan 26, 2023We present a model-based offline reinforcement learning policy performance lower bound that explicitly captures dynamics model misspecification and distribution mismatch and we propose an empirical algorithm for optimal offline policy selection. Theoretically, we prove a novel safe policy improvement theorem by establishing pessimism approximations to the value function. Our key insight is to jointly consider selecting over dynamics models and policies: as long as a dynamics model can accurately represent the dynamics of the state-action pairs visited by a given policy, it is possible to approximate the value of that particular policy. We analyze our lower bound in the LQR setting and also show competitive performance to previous lower bounds on policy selection across a set of D4RL tasks.
Giving Feedback on Interactive Student Programs with Meta-Exploration
Nov 16, 2022



Developing interactive software, such as websites or games, is a particularly engaging way to learn computer science. However, teaching and giving feedback on such software is time-consuming -- standard approaches require instructors to manually grade student-implemented interactive programs. As a result, online platforms that serve millions, like Code.org, are unable to provide any feedback on assignments for implementing interactive programs, which critically hinders students' ability to learn. One approach toward automatic grading is to learn an agent that interacts with a student's program and explores states indicative of errors via reinforcement learning. However, existing work on this approach only provides binary feedback of whether a program is correct or not, while students require finer-grained feedback on the specific errors in their programs to understand their mistakes. In this work, we show that exploring to discover errors can be cast as a meta-exploration problem. This enables us to construct a principled objective for discovering errors and an algorithm for optimizing this objective, which provides fine-grained feedback. We evaluate our approach on a set of over 700K real anonymized student programs from a Code.org interactive assignment. Our approach provides feedback with 94.3% accuracy, improving over existing approaches by 17.7% and coming within 1.5% of human-level accuracy. Project web page: https://ezliu.github.io/dreamgrader.
Oracle Inequalities for Model Selection in Offline Reinforcement Learning
Nov 03, 2022
In offline reinforcement learning (RL), a learner leverages prior logged data to learn a good policy without interacting with the environment. A major challenge in applying such methods in practice is the lack of both theoretically principled and practical tools for model selection and evaluation. To address this, we study the problem of model selection in offline RL with value function approximation. The learner is given a nested sequence of model classes to minimize squared Bellman error and must select among these to achieve a balance between approximation and estimation error of the classes. We propose the first model selection algorithm for offline RL that achieves minimax rate-optimal oracle inequalities up to logarithmic factors. The algorithm, ModBE, takes as input a collection of candidate model classes and a generic base offline RL algorithm. By successively eliminating model classes using a novel one-sided generalization test, ModBE returns a policy with regret scaling with the complexity of the minimally complete model class. In addition to its theoretical guarantees, it is conceptually simple and computationally efficient, amounting to solving a series of square loss regression problems and then comparing relative square loss between classes. We conclude with several numerical simulations showing it is capable of reliably selecting a good model class.
Data-Efficient Pipeline for Offline Reinforcement Learning with Limited Data
Oct 16, 2022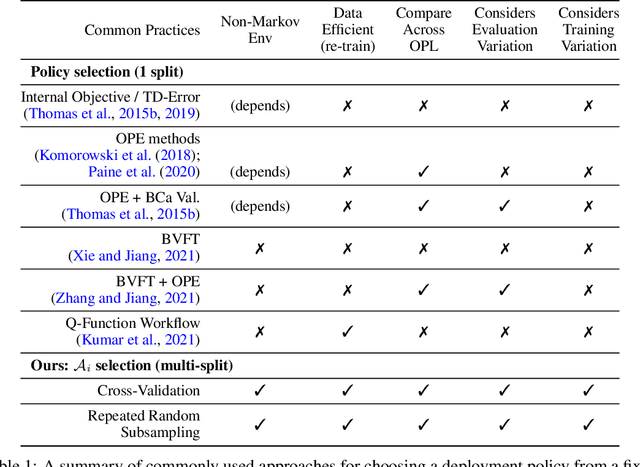
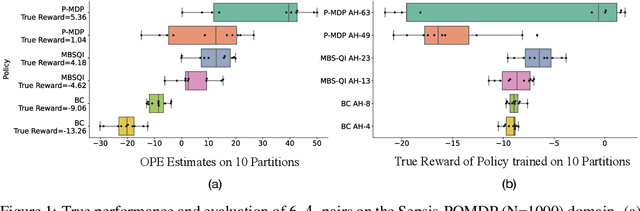

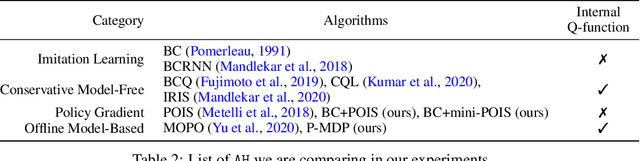
Offline reinforcement learning (RL) can be used to improve future performance by leveraging historical data. There exist many different algorithms for offline RL, and it is well recognized that these algorithms, and their hyperparameter settings, can lead to decision policies with substantially differing performance. This prompts the need for pipelines that allow practitioners to systematically perform algorithm-hyperparameter selection for their setting. Critically, in most real-world settings, this pipeline must only involve the use of historical data. Inspired by statistical model selection methods for supervised learning, we introduce a task- and method-agnostic pipeline for automatically training, comparing, selecting, and deploying the best policy when the provided dataset is limited in size. In particular, our work highlights the importance of performing multiple data splits to produce more reliable algorithm-hyperparameter selection. While this is a common approach in supervised learning, to our knowledge, this has not been discussed in detail in the offline RL setting. We show it can have substantial impacts when the dataset is small. Compared to alternate approaches, our proposed pipeline outputs higher-performing deployed policies from a broad range of offline policy learning algorithms and across various simulation domains in healthcare, education, and robotics. This work contributes toward the development of a general-purpose meta-algorithm for automatic algorithm-hyperparameter selection for offline RL.