 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData and its contents: A survey of dataset development and use in machine learning research
Dec 09, 2020Datasets have played a foundational role in the advancement of machine learning research. They form the basis for the models we design and deploy, as well as our primary medium for benchmarking and evaluation. Furthermore, the ways in which we collect, construct and share these datasets inform the kinds of problems the field pursues and the methods explored in algorithm development. However, recent work from a breadth of perspectives has revealed the limitations of predominant practices in dataset collection and use. In this paper, we survey the many concerns raised about the way we collect and use data in machine learning and advocate that a more cautious and thorough understanding of data is necessary to address several of the practical and ethical issues of the field.
Towards Accountability for Machine Learning Datasets: Practices from Software Engineering and Infrastructure
Oct 23, 2020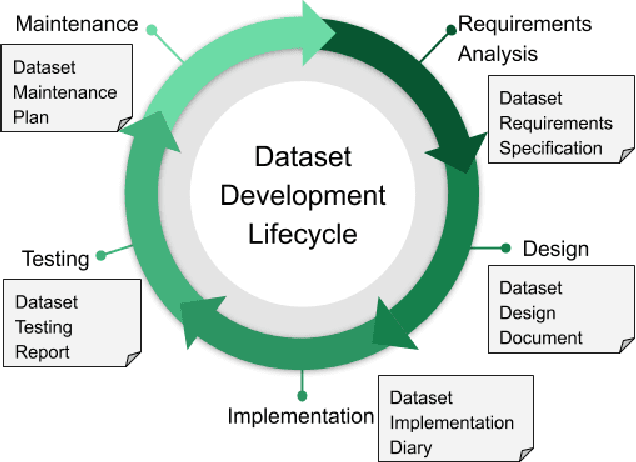

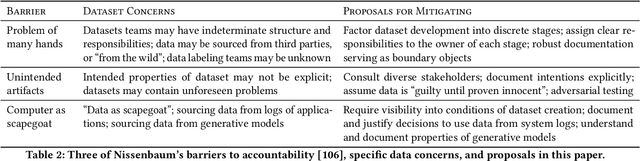
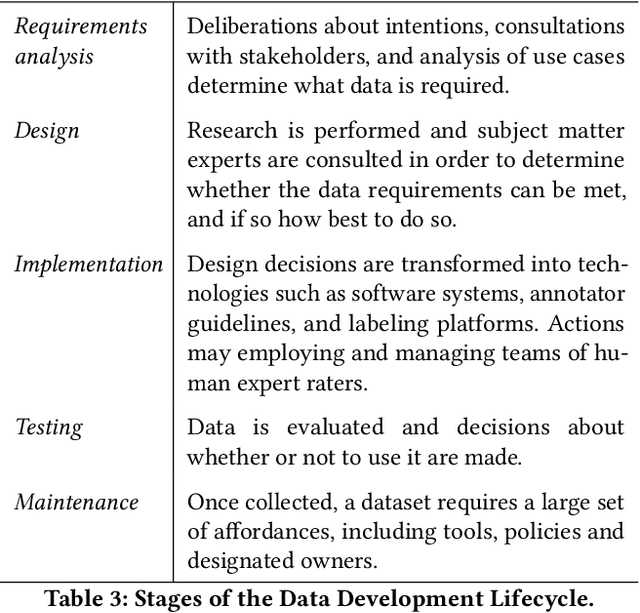
Rising concern for the societal implications of artificial intelligence systems has inspired demands for greater transparency and accountability. However the datasets which empower machine learning are often used, shared and re-used with little visibility into the processes of deliberation which led to their creation. Which stakeholder groups had their perspectives included when the dataset was conceived? Which domain experts were consulted regarding how to model subgroups and other phenomena? How were questions of representational biases measured and addressed? Who labeled the data? In this paper, we introduce a rigorous framework for dataset development transparency which supports decision-making and accountability. The framework uses the cyclical, infrastructural and engineering nature of dataset development to draw on best practices from the software development lifecycle. Each stage of the data development lifecycle yields a set of documents that facilitate improved communication and decision-making, as well as drawing attention the value and necessity of careful data work. The proposed framework is intended to contribute to closing the accountability gap in artificial intelligence systems, by making visible the often overlooked work that goes into dataset creation.
Characterising Bias in Compressed Models
Oct 06, 2020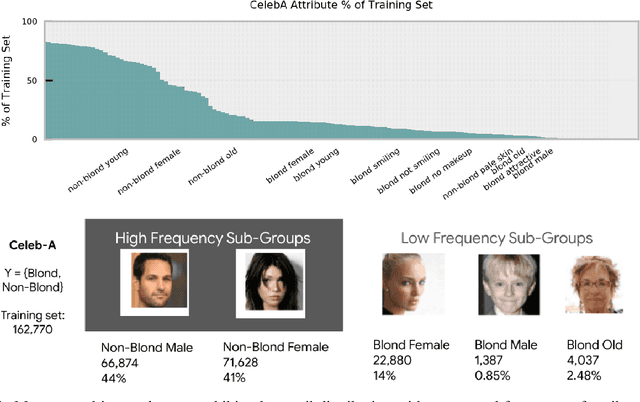
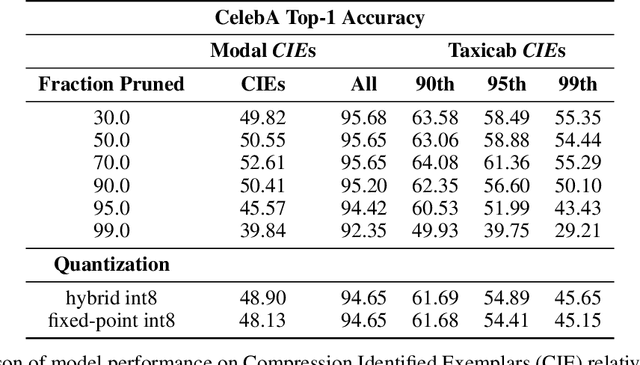
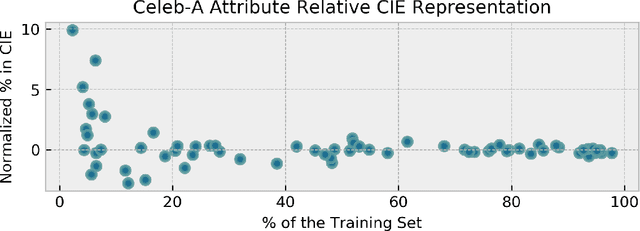
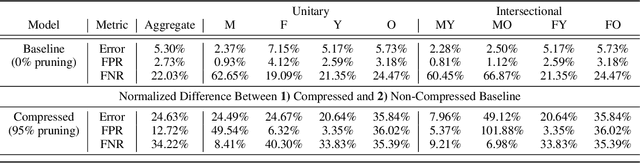
The popularity and widespread use of pruning and quantization is driven by the severe resource constraints of deploying deep neural networks to environments with strict latency, memory and energy requirements. These techniques achieve high levels of compression with negligible impact on top-line metrics (top-1 and top-5 accuracy). However, overall accuracy hides disproportionately high errors on a small subset of examples; we call this subset Compression Identified Exemplars (CIE). We further establish that for CIE examples, compression amplifies existing algorithmic bias. Pruning disproportionately impacts performance on underrepresented features, which often coincides with considerations of fairness. Given that CIE is a relatively small subset but a great contributor of error in the model, we propose its use as a human-in-the-loop auditing tool to surface a tractable subset of the dataset for further inspection or annotation by a domain expert. We provide qualitative and quantitative support that CIE surfaces the most challenging examples in the data distribution for human-in-the-loop auditing.
Social Biases in NLP Models as Barriers for Persons with Disabilities
May 02, 2020
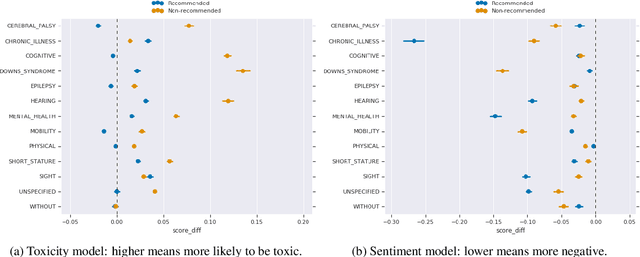
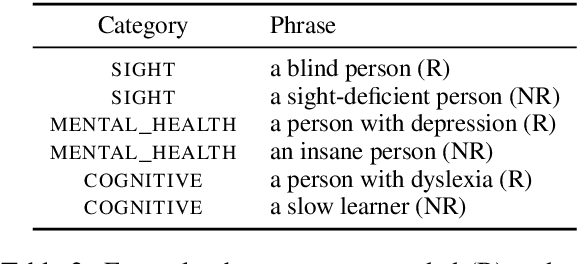
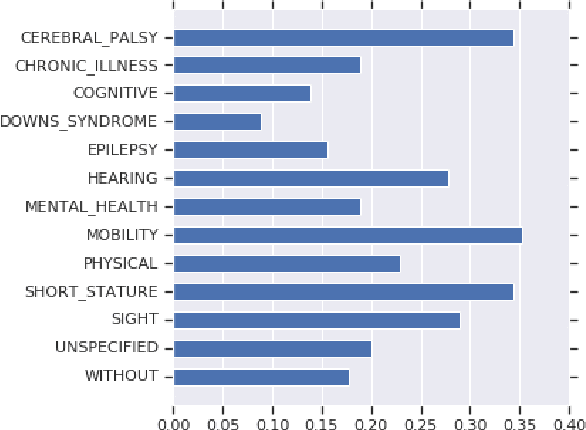
Building equitable and inclusive NLP technologies demands consideration of whether and how social attitudes are represented in ML models. In particular, representations encoded in models often inadvertently perpetuate undesirable social biases from the data on which they are trained. In this paper, we present evidence of such undesirable biases towards mentions of disability in two different English language models: toxicity prediction and sentiment analysis. Next, we demonstrate that the neural embeddings that are the critical first step in most NLP pipelines similarly contain undesirable biases towards mentions of disability. We end by highlighting topical biases in the discourse about disability which may contribute to the observed model biases; for instance, gun violence, homelessness, and drug addiction are over-represented in texts discussing mental illness.
* ACL 2020 short paper. 5 pages
Diversity and Inclusion Metrics in Subset Selection
Feb 09, 2020


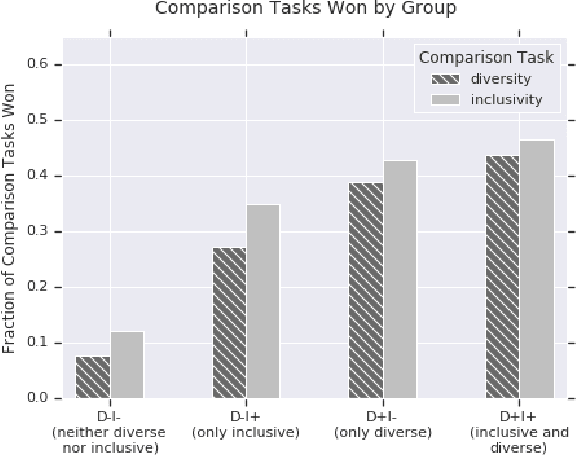
The ethical concept of fairness has recently been applied in machine learning (ML) settings to describe a wide range of constraints and objectives. When considering the relevance of ethical concepts to subset selection problems, the concepts of diversity and inclusion are additionally applicable in order to create outputs that account for social power and access differentials. We introduce metrics based on these concepts, which can be applied together, separately, and in tandem with additional fairness constraints. Results from human subject experiments lend support to the proposed criteria. Social choice methods can additionally be leveraged to aggregate and choose preferable sets, and we detail how these may be applied.
Detecting Bias with Generative Counterfactual Face Attribute Augmentation
Jun 18, 2019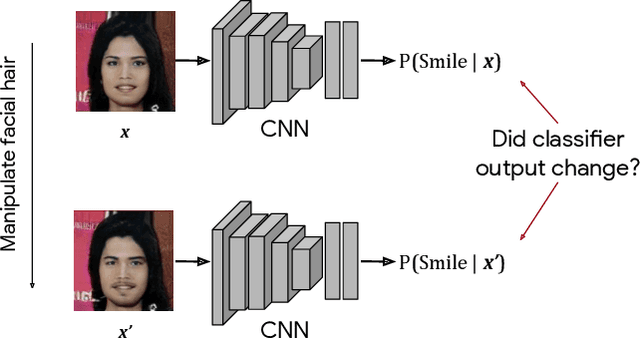

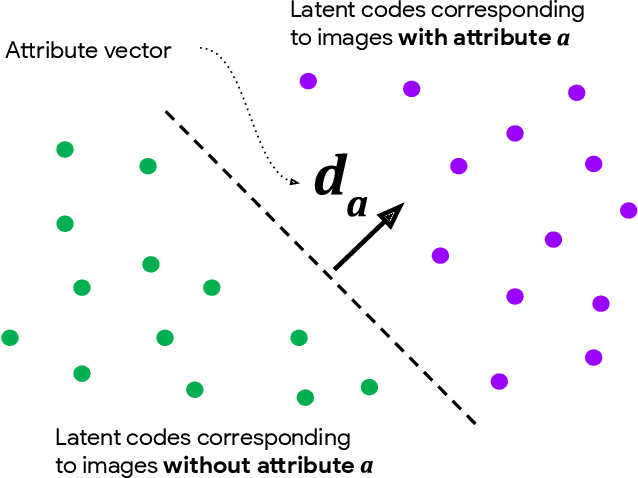
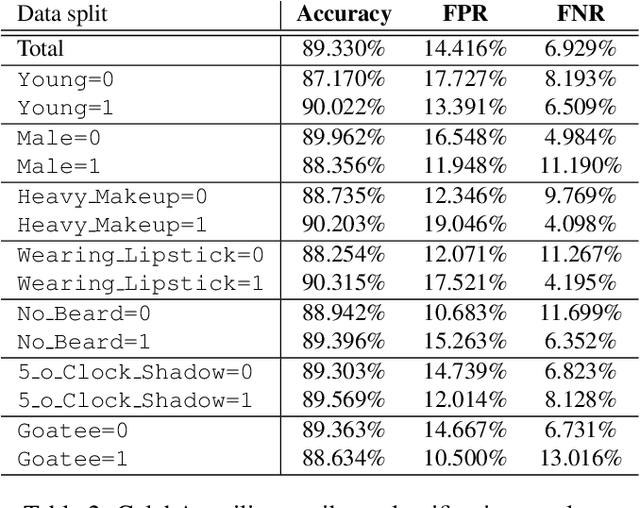
We introduce a simple framework for identifying biases of a smiling attribute classifier. Our method poses counterfactual questions of the form: how would the prediction change if this face characteristic had been different? We leverage recent advances in generative adversarial networks to build a realistic generative model of face images that affords controlled manipulation of specific image characteristics. We introduce a set of metrics that measure the effect of manipulating a specific property of an image on the output of a trained classifier. Empirically, we identify several different factors of variation that affect the predictions of a smiling classifier trained on CelebA.
Learning Goal Embeddings via Self-Play for Hierarchical Reinforcement Learning
Nov 22, 2018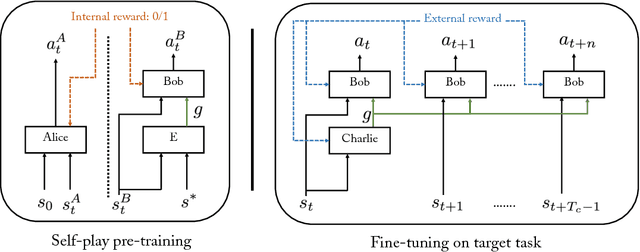
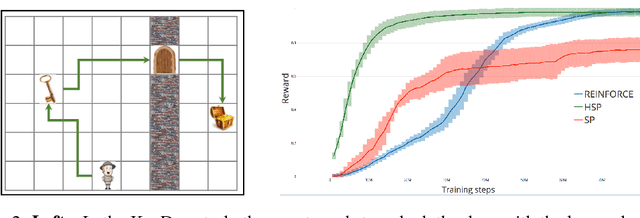
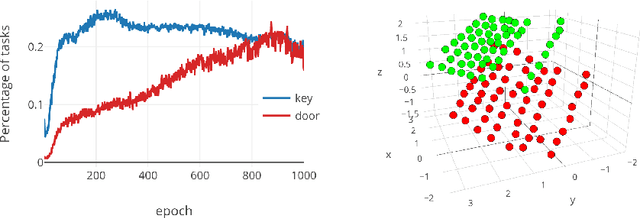
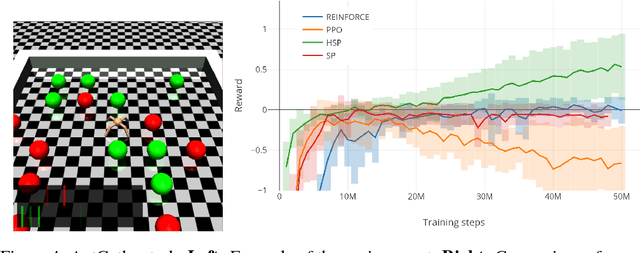
In hierarchical reinforcement learning a major challenge is determining appropriate low-level policies. We propose an unsupervised learning scheme, based on asymmetric self-play from Sukhbaatar et al. (2018), that automatically learns a good representation of sub-goals in the environment and a low-level policy that can execute them. A high-level policy can then direct the lower one by generating a sequence of continuous sub-goal vectors. We evaluate our model using Mazebase and Mujoco environments, including the challenging AntGather task. Visualizations of the sub-goal embeddings reveal a logical decomposition of tasks within the environment. Quantitatively, our approach obtains compelling performance gains over non-hierarchical approaches.
Modeling Others using Oneself in Multi-Agent Reinforcement Learning
Mar 23, 2018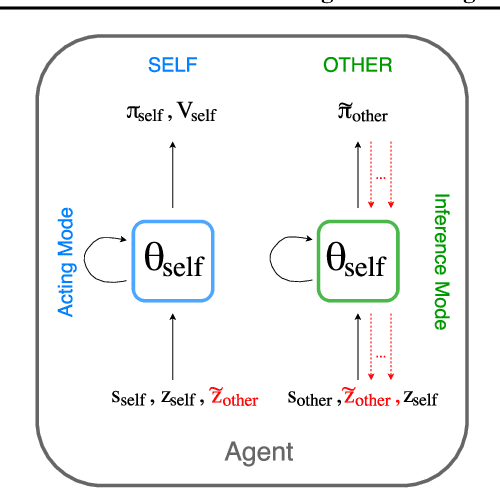
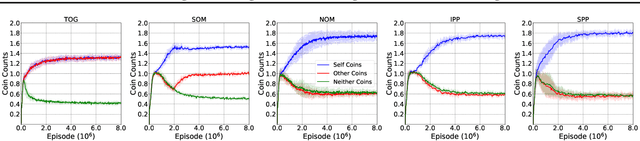
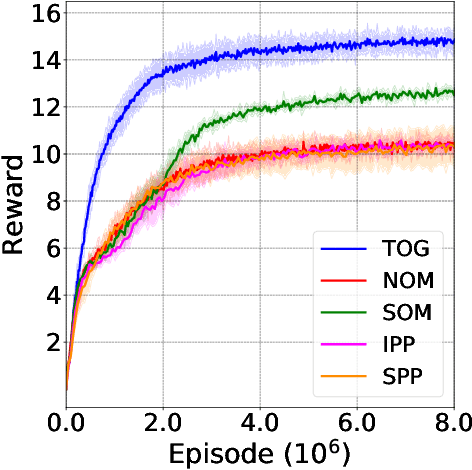
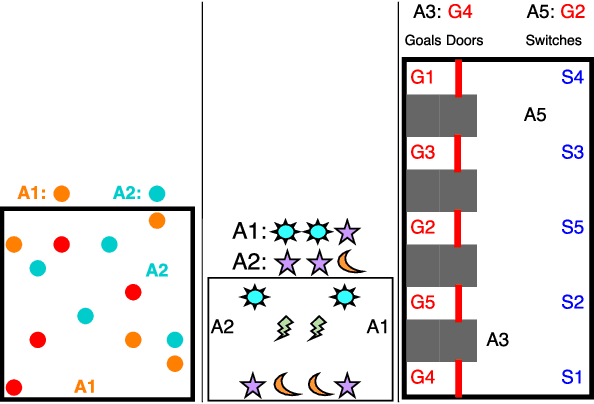
We consider the multi-agent reinforcement learning setting with imperfect information in which each agent is trying to maximize its own utility. The reward function depends on the hidden state (or goal) of both agents, so the agents must infer the other players' hidden goals from their observed behavior in order to solve the tasks. We propose a new approach for learning in these domains: Self Other-Modeling (SOM), in which an agent uses its own policy to predict the other agent's actions and update its belief of their hidden state in an online manner. We evaluate this approach on three different tasks and show that the agents are able to learn better policies using their estimate of the other players' hidden states, in both cooperative and adversarial settings.
Stochastic Video Generation with a Learned Prior
Mar 02, 2018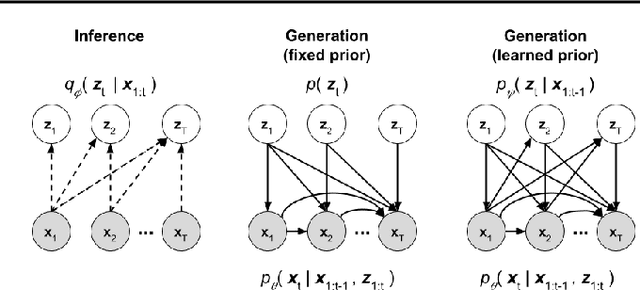
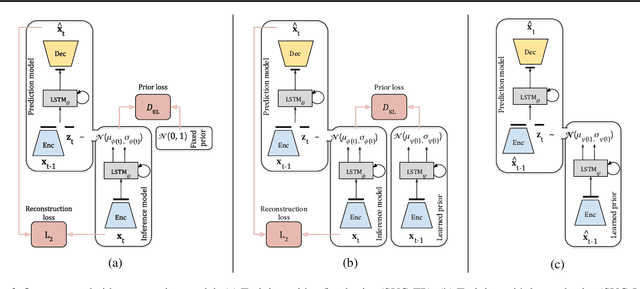


Generating video frames that accurately predict future world states is challenging. Existing approaches either fail to capture the full distribution of outcomes, or yield blurry generations, or both. In this paper we introduce an unsupervised video generation model that learns a prior model of uncertainty in a given environment. Video frames are generated by drawing samples from this prior and combining them with a deterministic estimate of the future frame. The approach is simple and easily trained end-to-end on a variety of datasets. Sample generations are both varied and sharp, even many frames into the future, and compare favorably to those from existing approaches.
Unsupervised Learning of Disentangled Representations from Video
May 31, 2017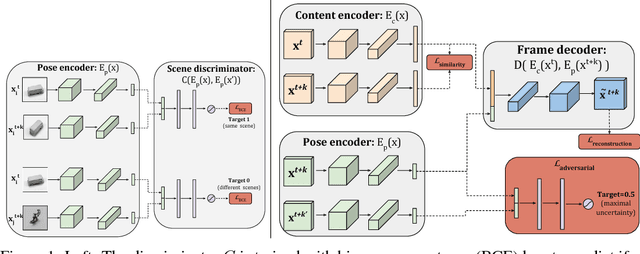
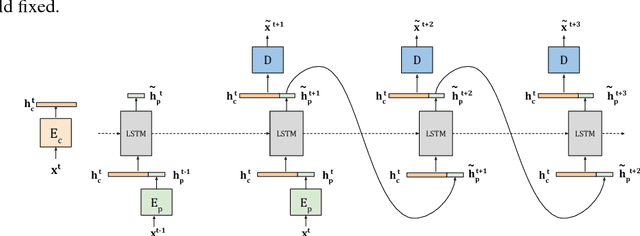
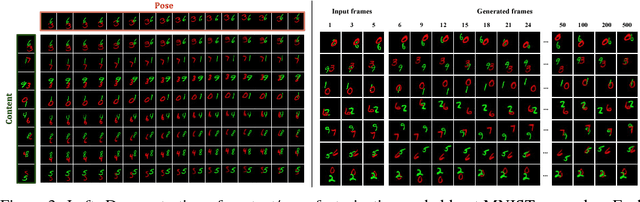

We present a new model DrNET that learns disentangled image representations from video. Our approach leverages the temporal coherence of video and a novel adversarial loss to learn a representation that factorizes each frame into a stationary part and a temporally varying component. The disentangled representation can be used for a range of tasks. For example, applying a standard LSTM to the time-vary components enables prediction of future frames. We evaluate our approach on a range of synthetic and real videos, demonstrating the ability to coherently generate hundreds of steps into the future.