 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecover-LoRA for Aggressive Quantization: Reclaiming Accuracy in 2-Bit Language Models via Low-Rank Adaptation with Knowledge Distillation on Synthetic Data
Jun 02, 2026Aggressive weight quantization to 2-bit precision offers substantial throughput and memory gains for large language model (LLM) inference, but typically incurs severe accuracy degradation. These gains are particularly relevant for edge and on-device deployment, where memory capacity and bandwidth are primary constraints. In this work, we extend Recover-LoRA -- a lightweight, data-free accuracy recovery method originally developed for general model weight corruption -- to the setting of ultra-low-bit quantization. We propose a selective mixed-precision strategy in which only gate and up projection layers of the MLP are quantized to 2-bit (W2), while all other linear layers remain at higher precision, yielding a mixed-precision GateUp configuration. We demonstrate via roofline analysis across three model families (4B--20B) and two hardware platforms that a W4/W2-GateUp deployment (4-bit base with 2-bit gate/up) delivers 7.5--23.3\% TPS improvement over uniform W4 depending on model and context length, while confining quantization error to a predictable subset of layers. We then apply Recover-LoRA -- training low-rank adapters on the quantized layers via logit distillation with synthetic data -- to recover accuracy lost from 2-bit quantization of the gate and up layers. In a case study on Qwen3-4B, Recover-LoRA achieves 80--95\% accuracy recovery on 9 of 12 benchmarks, using only 10k synthetic training samples and no labeled data. We further demonstrate that synthetic data performs comparably to curated labeled data for distillation-based recovery, and that recovery generalizes to out-of-distribution evaluation tasks. Our results present Recover-LoRA as a practical post-quantization accuracy recovery tool for aggressive weight compression in deployment settings.
Analysis & Computational Complexity Reduction of Monocular and Stereo Depth Estimation Techniques
Jun 18, 2022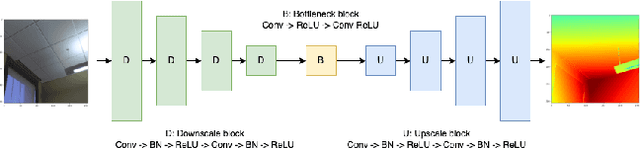



Accurate depth estimation with lowest compute and energy cost is a crucial requirement for unmanned and battery operated autonomous systems. Robotic applications require real time depth estimation for navigation and decision making under rapidly changing 3D surroundings. A high accuracy algorithm may provide the best depth estimation but may consume tremendous compute and energy resources. A general trade-off is to choose less accurate methods for initial depth estimate and a more accurate yet compute intensive method when needed. Previous work has shown this trade-off can be improved by developing a state-of-the-art method (AnyNet) to improve stereo depth estimation. We studied both the monocular and stereo vision depth estimation methods and investigated methods to reduce computational complexity of these methods. This was our baseline. Consequently, our experiments show reduction of monocular depth estimation model size by ~75% reduces accuracy by less than 2% (SSIM metric). Our experiments with the novel stereo vision method (AnyNet) show that accuracy of depth estimation does not degrade more than 3% (three pixel error metric) in spite of reduction in model size by ~20%. We have shown that smaller models can indeed perform competitively.