 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsistency Matters: Defining Demonstration Data Quality Metrics in Robot Learning from Demonstration
Dec 18, 2024



Learning from Demonstration (LfD) empowers robots to acquire new skills through human demonstrations, making it feasible for everyday users to teach robots. However, the success of learning and generalization heavily depends on the quality of these demonstrations. Consistency is often used to indicate quality in LfD, yet the factors that define this consistency remain underexplored. In this paper, we evaluate a comprehensive set of motion data characteristics to determine which consistency measures best predict learning performance. By ensuring demonstration consistency prior to training, we enhance models' predictive accuracy and generalization to novel scenarios. We validate our approach with two user studies involving participants with diverse levels of robotics expertise. In the first study (N = 24), users taught a PR2 robot to perform a button-pressing task in a constrained environment, while in the second study (N = 30), participants trained a UR5 robot on a pick-and-place task. Results show that demonstration consistency significantly impacts success rates in both learning and generalization, with 70% and 89% of task success rates in the two studies predicted using our consistency metrics. Moreover, our metrics estimate generalized performance success rates with 76% and 91% accuracy. These findings suggest that our proposed measures provide an intuitive, practical way to assess demonstration data quality before training, without requiring expert data or algorithm-specific modifications. Our approach offers a systematic way to evaluate demonstration quality, addressing a critical gap in LfD by formalizing consistency metrics that enhance the reliability of robot learning from human demonstrations.
Demonstration Based Explainable AI for Learning from Demonstration Methods
Oct 10, 2024Learning from Demonstration (LfD) is a powerful type of machine learning that can allow novices to teach and program robots to complete various tasks. However, the learning process for these systems may still be difficult for novices to interpret and understand, making effective teaching challenging. Explainable artificial intelligence (XAI) aims to address this challenge by explaining a system to the user. In this work, we investigate XAI within LfD by implementing an adaptive explanatory feedback system on an inverse reinforcement learning (IRL) algorithm. The feedback is implemented by demonstrating selected learnt trajectories to users. The system adapts to user teaching by categorizing and then selectively sampling trajectories shown to a user, to show a representative sample of both successful and unsuccessful trajectories. The system was evaluated through a user study with 26 participants teaching a robot a navigation task. The results of the user study demonstrated that the proposed explanatory feedback system can improve robot performance, teaching efficiency and user understanding of the robot.
Learning to Communicate Functional States with Nonverbal Expressions for Improved Human-Robot Collaboration
Apr 30, 2024



Collaborative robots must effectively communicate their internal state to humans to enable a smooth interaction. Nonverbal communication is widely used to communicate information during human-robot interaction, however, such methods may also be misunderstood, leading to communication errors. In this work, we explore modulating the acoustic parameter values (pitch bend, beats per minute, beats per loop) of nonverbal auditory expressions to convey functional robot states (accomplished, progressing, stuck). We propose a reinforcement learning (RL) algorithm based on noisy human feedback to produce accurately interpreted nonverbal auditory expressions. The proposed approach was evaluated through a user study with 24 participants. The results demonstrate that: 1. Our proposed RL-based approach is able to learn suitable acoustic parameter values which improve the users' ability to correctly identify the state of the robot. 2. Algorithm initialization informed by previous user data can be used to significantly speed up the learning process. 3. The method used for algorithm initialization strongly influences whether participants converge to similar sounds for each robot state. 4. Modulation of pitch bend has the largest influence on user association between sounds and robotic states.
* 8 Pages, Accepted to RA-L March 2024
How Can Everyday Users Efficiently Teach Robots by Demonstrations?
Oct 19, 2023



Learning from Demonstration (LfD) is a framework that allows lay users to easily program robots. However, the efficiency of robot learning and the robot's ability to generalize to task variations hinges upon the quality and quantity of the provided demonstrations. Our objective is to guide human teachers to furnish more effective demonstrations, thus facilitating efficient robot learning. To achieve this, we propose to use a measure of uncertainty, namely task-related information entropy, as a criterion for suggesting informative demonstration examples to human teachers to improve their teaching skills. In a conducted experiment (N=24), an augmented reality (AR)-based guidance system was employed to train novice users to produce additional demonstrations from areas with the highest entropy within the workspace. These novice users were trained for a few trials to teach the robot a generalizable task using a limited number of demonstrations. Subsequently, the users' performance after training was assessed first on the same task (retention) and then on a novel task (transfer) without guidance. The results indicated a substantial improvement in robot learning efficiency from the teacher's demonstrations, with an improvement of up to 198% observed on the novel task. Furthermore, the proposed approach was compared to a state-of-the-art heuristic rule and found to improve robot learning efficiency by 210% compared to the heuristic rule.
Comparing Subjective Perceptions of Robot-to-Human Handover Trajectories
Nov 16, 2022



Robots must move legibly around people for safety reasons, especially for tasks where physical contact is possible. One such task is handovers, which requires implicit communication on where and when physical contact (object transfer) occurs. In this work, we study whether the trajectory model used by a robot during the reaching phase affects the subjective perceptions of receivers for robot-to-human handovers. We conducted a user study where 32 participants were handed over three objects with four trajectory models: three were versions of a minimum jerk trajectory, and one was an ellipse-fitting-based trajectory. The start position of the handover was fixed for all trajectories, and the end position was allowed to vary randomly around a fixed position by $\pm$3 cm in all axis. The user study found no significant differences among the handover trajectories in survey questions relating to safety, predictability, naturalness, and other subjective metrics. While these results seemingly reject the hypothesis that the trajectory affects human perceptions of a handover, it prompts future research to investigate the effect of other variables, such as robot speed, object transfer position, object orientation at the transfer point, and explicit communication signals such as gaze and speech.
Autonomous social robot navigation in unknown urban environments using semantic segmentation
Aug 25, 2022


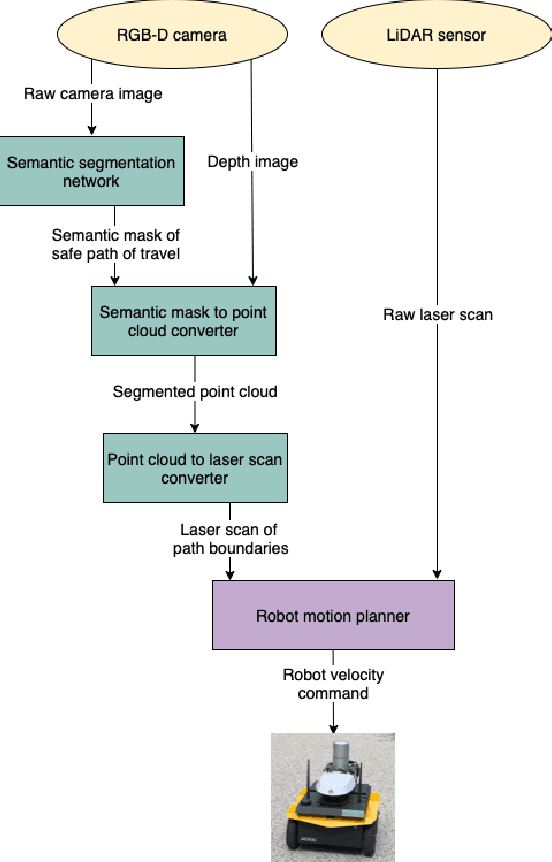
For autonomous robots navigating in urban environments, it is important for the robot to stay on the designated path of travel (i.e., the footpath), and avoid areas such as grass and garden beds, for safety and social conformity considerations. This paper presents an autonomous navigation approach for unknown urban environments that combines the use of semantic segmentation and LiDAR data. The proposed approach uses the segmented image mask to create a 3D obstacle map of the environment, from which, the boundaries of the footpath is computed. Compared to existing methods, our approach does not require a pre-built map and provides a 3D understanding of the safe region of travel, enabling the robot to plan any path through the footpath. Experiments comparing our method with two alternatives using only LiDAR or only semantic segmentation show that overall our proposed approach performs significantly better with greater than 91% success rate outdoors, and greater than 66% indoors. Our method enabled the robot to remain on the safe path of travel at all times, and reduced the number of collisions.
Design and Implementation of a Human-Robot Joint Action Framework using Augmented Reality and Eye Gaze
Aug 25, 2022

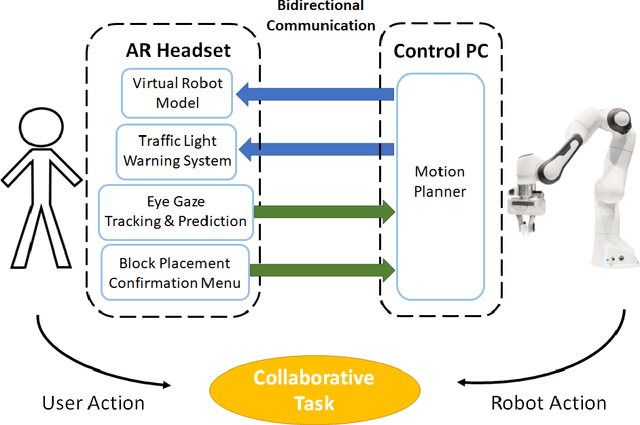

When humans work together to complete a joint task, each person builds an internal model of the situation and how it will evolve. Efficient collaboration is dependent on how these individual models overlap to form a shared mental model among team members, which is important for collaborative processes in human-robot teams. The development and maintenance of an accurate shared mental model requires bidirectional communication of individual intent and the ability to interpret the intent of other team members. To enable effective human-robot collaboration, this paper presents a design and implementation of a novel joint action framework in human-robot team collaboration, utilizing augmented reality (AR) technology and user eye gaze to enable bidirectional communication of intent. We tested our new framework through a user study with 37 participants, and found that our system improves task efficiency, trust, as well as task fluency. Therefore, using AR and eye gaze to enable bidirectional communication is a promising mean to improve core components that influence collaboration between humans and robots.
AR Point&Click: An Interface for Setting Robot Navigation Goals
Mar 29, 2022


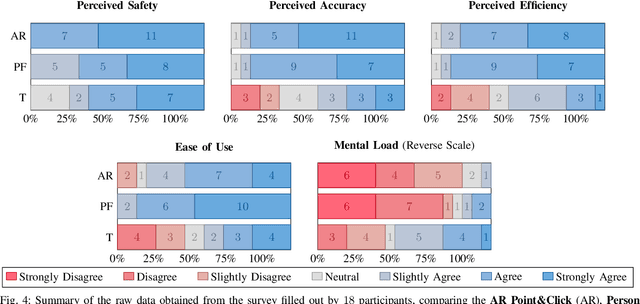
This paper considers the problem of designating navigation goal locations for interactive mobile robots. We propose a point-and-click interface, implemented with an Augmented Reality (AR) headset. The cameras on the AR headset are used to detect natural pointing gestures performed by the user. The selected goal is visualized through the AR headset, allowing the users to adjust the goal location if desired. We conduct a user study in which participants set consecutive navigation goals for the robot using three different interfaces: AR Point & Click, Person Following and Tablet (birdeye map view). Results show that the proposed AR Point&Click interface improved the perceived accuracy, efficiency and reduced mental load compared to the baseline tablet interface, and it performed on-par to the Person Following method. These results show that the AR Point\&Click is a feasible interaction model for setting navigation goals.
On-The-Go Robot-to-Human Handovers with a Mobile Manipulator
Mar 16, 2022
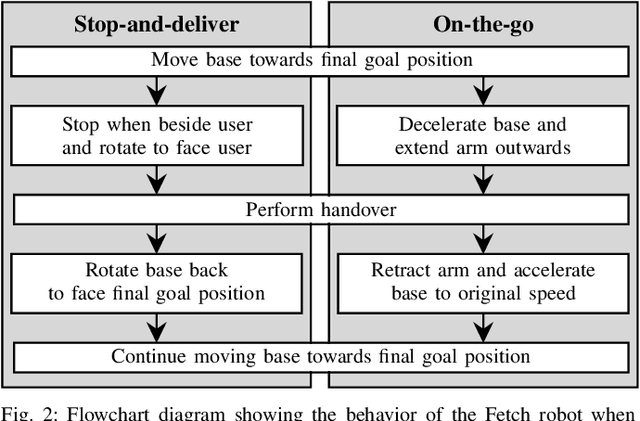

Existing approaches to direct robot-to-human handovers are typically implemented on fixed-base robot arms, or on mobile manipulators that come to a full stop before performing the handover. We propose "on-the-go" handovers which permit a moving mobile manipulator to hand over an object to a human without stopping. The on-the-go handover motion is generated with a reactive controller that allows simultaneous control of the base and the arm. In a user study, human receivers subjectively assessed on-the-go handovers to be more efficient, predictable, natural, better timed and safer than handovers that implemented a "stop-and-deliver" behavior.
Design and Evaluation of an Augmented Reality Head-Mounted Display Interface for Human Robot Teams Collaborating in Physically Shared Manufacturing Tasks
Mar 16, 2022
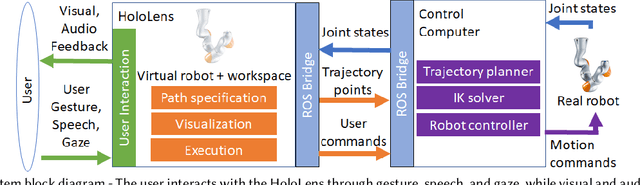
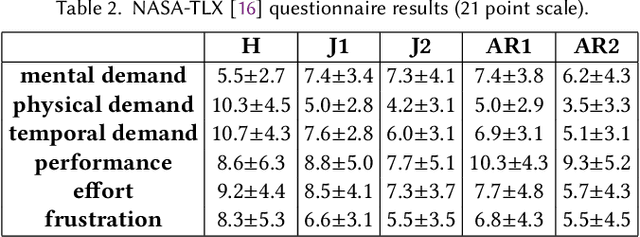

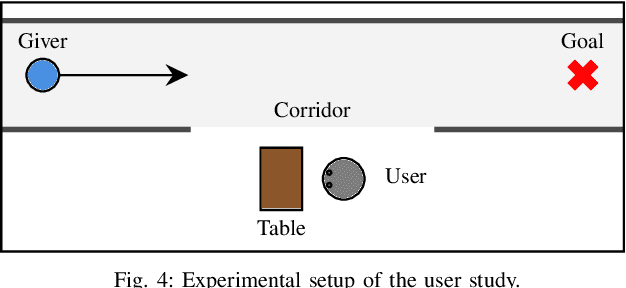
We provide an experimental evaluation of a wearable augmented reality (AR) system we have developed for human-robot teams working on tasks requiring collaboration in shared physical workspace. Recent advances in AR technology have facilitated the development of more intuitive user interfaces for many human-robot interaction applications. While it has been anticipated that AR can provided a more intuitive interface to robot assistants helping human workers in various manufacturing scenarios, existing studies in robotics have been largely limited to teleoperation and programming. Industry 5.0 envisions cooperation between human and robot working in teams. Indeed, there exist many industrial task that can benefit from human-robot collaboration. A prime example is high-value composite manufacturing. Working with our industry partner towards this example application, we evaluated our AR interface design for shared physical workspace collaboration in human-robot teams. We conducted a multi-dimensional analysis of our interface using establish metrics. Results from our user study (n=26) show that subjectively, the AR interface feels more novel and a standard joystick interface feels more dependable to users. However, the AR interface was found to reduce physical demand and task completion time, while increasing robot utilization. Furthermore, user's freedom of choice to collaborate with the robot may also affect the perceived usability of the system.